Por Shafiq Rayhan Joty y Scott Nyberg
Desarrollando el nuevo XGen
En nuestra serie de preguntas y respuestas «Engineering Energizers», examinamos las trayectorias profesionales que han formado a los líderes de ingeniería de Salesforce. Conozca a Shafiq Rayhan Joty, Director de Salesforce AI Research. Shafiq codirige el desarrollo de XGen, una serie de innovadores modelos de lenguaje de gran tamaño (LLMs) de diferentes tamaños.
Al proporcionar un conocimiento general crítico, XGen sirve como modelo fundacional inicial que utilizan los equipos de IA de Salesforce, adaptando el modelo mediante un ajuste fino o un preentrenamiento continuado para crear modelos seguros, fiables y personalizados para distintos dominios y casos de uso, apoyando las ventas, el servicio, etc.
>
–>
Shafiq profundiza en el papel de XGen como modelo fundacional.
Siga leyendo para descubrir cómo el equipo XGen de Shafiq supera los límites de los LLM para impulsar la innovación de la IA y satisfacer las necesidades cambiantes de los clientes de Salesforce.
¿Qué retos técnicos encontró el equipo de desarrollo de XGen?
Desde la recopilación masiva de datos hasta el entrenamiento del colosal modelo y su puesta a punto para satisfacer las impredecibles necesidades de los usuarios, el desarrollo de XGen planteó múltiples retos
- Recopilación de datos: Para entrenar el modelo de forma eficaz y a gran escala, el equipo necesitaba un gran volumen de datos de alta calidad. Aprovechando su amplia experiencia en la mezcla de datos, el equipo reunió un conjunto de datos masivo y diverso, procedente de fuentes públicas como Common Crawl y dominios de código como GitHub. Esto les permitió ampliar los datos de formación, alcanzando la asombrosa cifra de más de 2 billones de tokens, a la vez que reunían un conjunto de datos seguro, imparcial, completo y conforme a la ley, procedente de diversos dominios de conocimiento
- Limpieza de datos de preentrenamiento: La limpieza de los datos a una escala tremenda presenta un obstáculo sustancial, ya que el equipo necesitaba eliminar la toxicidad, gestionar los problemas de derechos de autor y garantizar la calidad de los datos. Para ello, el equipo colaboró estrechamente con los expertos legales y éticos de Salesforce para establecer un proceso sólido de limpieza de datos, integrando métodos basados en modelos y en palabras clave para obtener una gran precisión.
- Limpieza de datos de preentrenamiento: la limpieza de datos a gran escala presenta un gran obstáculo, ya que el equipo necesitaba eliminar la toxicidad, gestionar los problemas de derechos de autor y garantizar la calidad de los datos
- Modelación: El equipo superó las complejidades de entrenar su LLM a gran escala en las TPU de Google integrando tecnologías como Flash Attention y Sliding Window Attention. Esto ayudó a impulsar el proceso de modelado rápido y eficiente, garantizando que el modelo pudiera gestionar las complejidades de varias tareas.
- Los TPUs de Google se han convertido en un elemento clave en la creación de modelos
- Ajuste del modelo: El equipo se enfrentó al reto de ajustar su modelo para satisfacer las necesidades de los usuarios que no se habían previsto durante la formación inicial. Esto implicaba interpretar diversas tareas e instrucciones, lo que se complicaba por las formas aleatorias en que los usuarios interactuaban con el modelo. El ajuste fue una fase clave para alinear el modelo con los requisitos y valores de los usuarios del mundo real. El equipo utilizó tanto el ajuste fino supervisado estándar como métodos de aprendizaje a partir de la retroalimentación humana/AI.
¿Cómo se entrenó el modelo XGen?
El proceso de entrenamiento de XGen se desarrolló en múltiples etapas. En la etapa de preentrenamiento, el modelo estableció sus conocimientos fundamentales sobre el mundo y el lenguaje para dar soporte a diversas aplicaciones y dominios. En esta etapa no se utilizó ninguna anotación humana y el modelo se entrenó simplemente para predecir el siguiente token dado un contexto de tokens anteriores, a partir de datos de texto sin procesar a una escala colosal, normalmente utilizando billones de tokens.
El modelo se entrenó para predecir el siguiente token dado un contexto de tokens anteriores
A continuación, durante la etapa de ajuste fino, el modelo se entrenó para interactuar con los usuarios como lo haría un humano. Los humanos supervisaron esta etapa, en la que se incorporaron técnicas como el ajuste fino supervisado y aprendizaje de refuerzo a partir de comentarios humanos para ayudar al modelo a comprender y ofrecer lo que los usuarios necesitan, aprendiendo su intención a través de numerosas instrucciones de tareas y el correspondiente resultado o comentarios sobre los resultados generados por el modelo. También en esta fase, el equipo se aseguró de que el modelo tuviera en cuenta consideraciones éticas, garantizando la seguridad y el cumplimiento de la legislación
Por último, la etapa de evaluación midió la capacidad del modelo para realizar tareas no vistas durante el entrenamiento, confirmando su sólida generalización a través de un conjunto diverso de tareas. El equipo también comparó el rendimiento del modelo con el de sus homólogos de código abierto y cerrado, garantizando así su precisión
>
Shafiq comparte más información sobre el proceso de formación.
¿Cómo se distingue XGen de los LLM externos de propósito general?
El modelo se separa de los LLM de propósito general de tres formas principales:
- Soporta necesidades únicas de los clientes.
- Asegura la privacidad de los datos. A diferencia de las fuentes externas basadas en API, XGen impulsa estrictos controles de privacidad de datos. Esto cumple con las restricciones de Salesforce de mantener los datos de los clientes dentro de su propia plataforma segura. En consecuencia, el modelo sigue siendo la única solución viable para sectores altamente sensibles como el bancario, donde no resulta práctico compartir la información de los clientes con LLM de terceros y la privacidad de los datos sigue siendo primordial
- Costes de servicio reducidos. Al centrarse en los casos de uso de los clientes de Salesforce, XGen es un modelo a menor escala que se personaliza para dominios particulares (casos de uso). Como resultado, su tamaño reducido disminuye su coste de inferencia debido a las menores necesidades computacionales
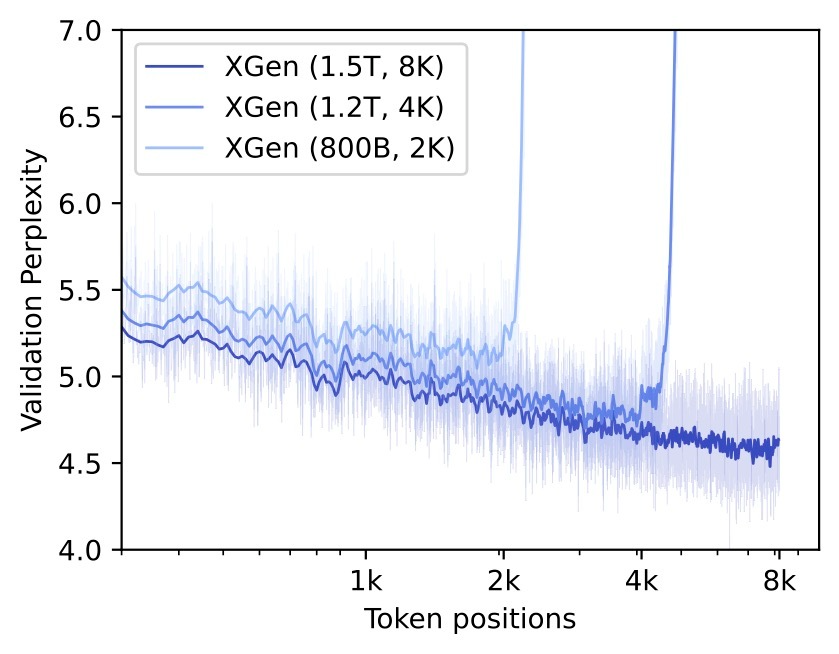
Un vistazo a la perplejidad del conjunto de validación para modelos XGen preentrenados con diferentes tamaños de contexto.
¿Cuáles son las novedades más significativas de XGen?
El modelo de 7.000 millones de parámetros de XGen pronto evolucionará hacia modelos mucho más grandes, superando a otros modelos de código abierto a las mismas escalas y aprovechando posteriormente una arquitectura de Mezcla de Expertos (MoE). Para construir este modelo más potente se ha aprovechado la experiencia del modelo de 7.000 millones de parámetros, lo que ha permitido mantener unos costes de desarrollo razonables porque el equipo no partía de cero.
Evolución de la mezcla de expertos
Este nuevo modelo puede servir de maestro, impulsando la destilación de conocimientos hacia modelos más pequeños y rentables que, a su vez, sirvan de apoyo a dominios únicos.
De cara al futuro, el equipo está desarrollando XGen Mobile, una versión de XGen con 4.000 millones de parámetros. Esta innovación permite a los clientes instalar XGen directamente en sus teléfonos, sin necesidad de conexión a Internet. De este modo, los usuarios pueden acceder a XGen sobre la marcha, en cualquier lugar. Por ejemplo, con XGen Mobile, los agentes de servicios de campo pueden extraer información de sus documentos sin conexión a Internet, lo que les permite realizar eficazmente trabajos como la reparación de electrodomésticos sobre la marcha
Más información