HIVE ha sido aceptado en CVPR 2024.
Otros autores son: Chia-Chih Chen, Ning Yu, Zeyuan Chen, Huan Wang, Silvio Savarese, Stefano Ermon, Caiming Xiong
Hemos visto el éxito de ChatGPT, que incorpora la retroalimentación humana para alinear el texto generado por grandes modelos lingüísticos con las preferencias humanas. ¿Es posible alinear los comentarios humanos con modelos de edición de imágenes instructivas de última generación? Ahora, los investigadores de Salesforce han desarrollado HIVE, uno de los primeros trabajos para ajustar los modelos generativos basados en difusión con la opinión humana.

Antecedentes
Gracias a las impresionantes capacidades de generación de los modelos generativos de texto a imagen (por ejemplo, Stable Diffusion), la edición de imágenes didácticas (por ejemplo, InstructPix2Pix) se ha convertido en uno de los escenarios de aplicación más prometedores. A diferencia de la edición tradicional de imágenes, en la que se necesitan tanto la entrada como la leyenda editada, la edición instructiva de imágenes sólo requiere instrucciones legibles por el ser humano. Por ejemplo, los métodos clásicos de edición de imágenes requieren una leyenda de entrada «un perro está jugando a la pelota» y una leyenda editada «un gato está jugando a la pelota». En cambio, la edición instructiva de imágenes sólo necesita instrucciones como «cambia el perro por un gato». Esta experiencia imita la forma en que los humanos realizan la edición de imágenes de forma natural.
InstructPix2Pix afina una difusión estable preentrenada curando un triplete de la imagen original, la instrucción y la imagen editada, con la ayuda de la edición de imágenes GPT-3 y Prompt-to-Prompt.
Aunque se obtienen resultados prometedores, el proceso de generación de datos de entrenamiento de InstructPix2Pix carece de alineación explícita entre las instrucciones de edición y las imágenes editadas.
Motivación
Hay una necesidad apremiante de desarrollar un modelo que alinee la retroalimentación humana con modelos basados en difusión para el problema de edición de imágenes instructivas. Para grandes modelos de lenguaje como InstructGPT y ChatGPT, a menudo aprendemos primero una función de recompensa para reflejar lo que a los humanos les importa o prefieren en la salida de texto generada, y luego aprovechamos algoritmos de aprendizaje de refuerzo (RL) como la optimización de política proximal (PPO) para afinar los modelos. Este proceso suele denominarse aprendizaje por refuerzo con retroalimentación humana (RLHF, por sus siglas en inglés).
El principal reto es cómo aprovechar el RLHF para afinar los modelos generativos basados en la difusión. Esto se debe a que aplicar PPO para maximizar las recompensas durante el proceso de ajuste puede resultar prohibitivamente caro debido a los cientos o miles de pasos de eliminación de ruido necesarios para cada imagen muestreada. Además, incluso con métodos de muestreo rápido, sigue siendo difícil propagar la señal de gradiente a los parámetros de la U-Net.
Método

La propuesta HIVE consta de tres pasos.
- Entrenamiento supervisado instructivo. Seguimos el método de InstructPix2Pix para recopilar los datos de entrenamiento y afinar el modelo de difusión. Específicamente, realizamos el ajuste fino supervisado instruccional en el conjunto de datos que combina nuestros datos de entrenamiento 1.1M recién recogidos y los datos de InstructPix2Pix. Se adopta un método de coherencia de ciclo propuesto para mejorar la escala del conjunto de datos.
- Para cada par de imagen de entrada e instrucción de edición, pedimos a los anotadores humanos que clasifiquen las salidas variantes del modelo de ajuste fino del paso 1, lo que nos proporciona un conjunto de datos de aprendizaje de recompensa. Utilizando el conjunto de datos recopilados, entrenamos un modelo de recompensa basado en BLIP (RM) que refleja las preferencias humanas.
- Estimamos la recompensa para cada dato de entrenamiento utilizado en el paso 1, e integramos la recompensa para realizar el ajuste fino del modelo de difusión de retroalimentación humana utilizando nuestros objetivos propuestos. El enfoque de ajuste fino propuesto es eficiente desde el punto de vista computacional y ofrece costes similares en comparación con el ajuste fino supervisado.
Experimentos
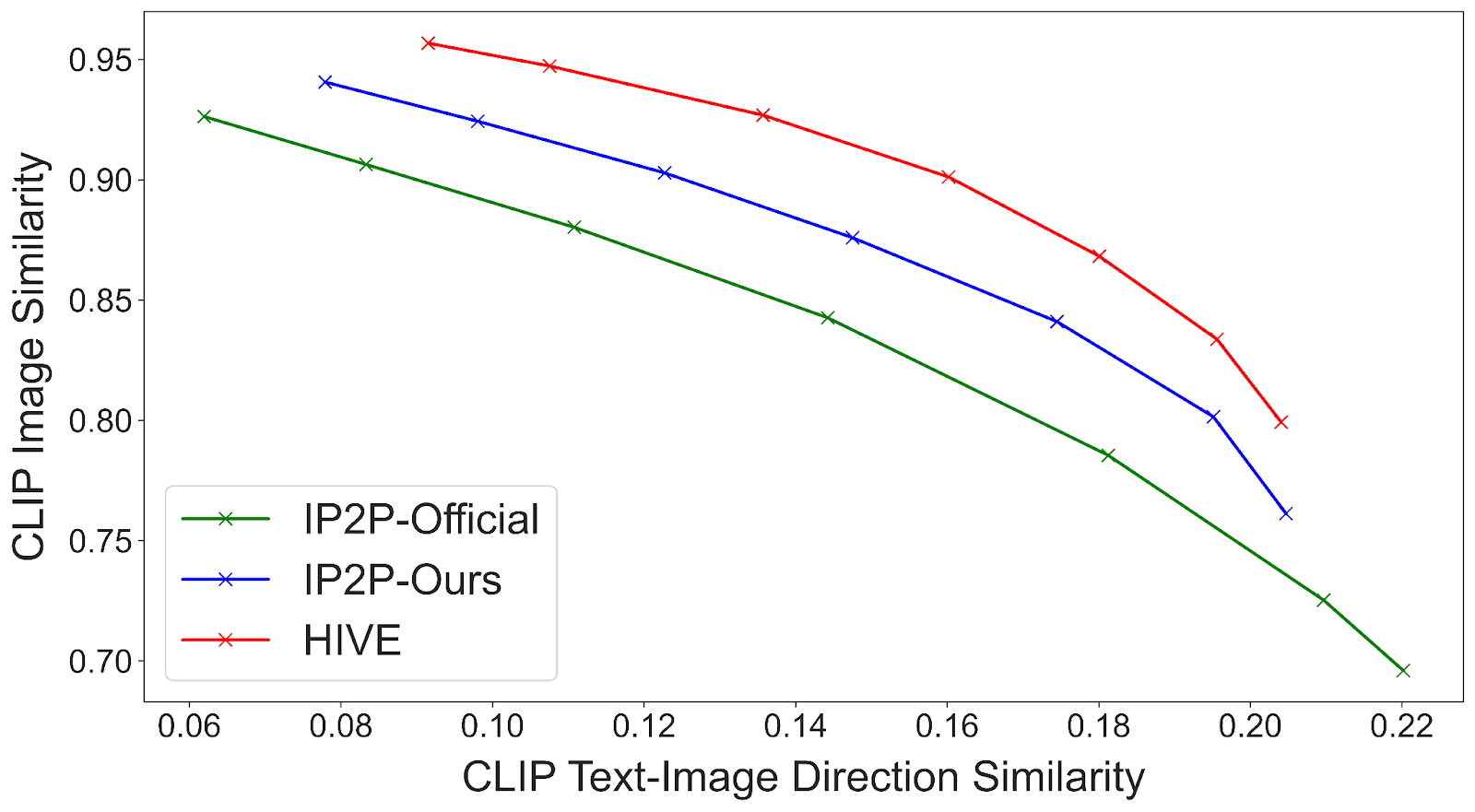
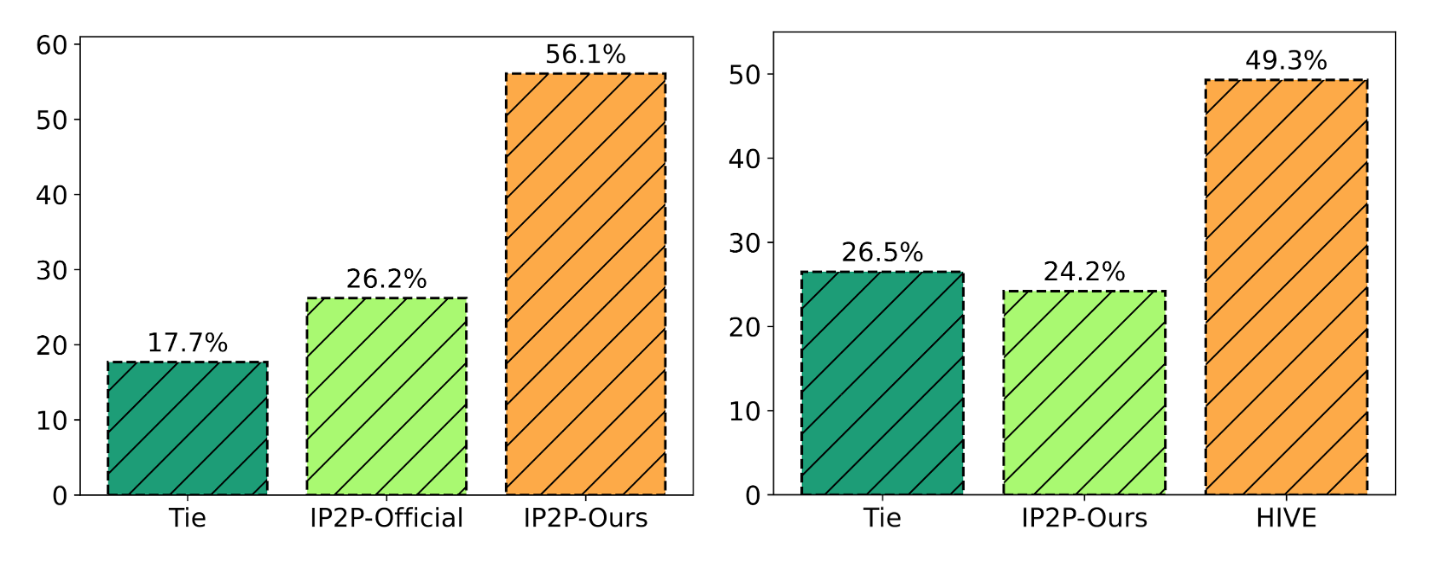
Al poner a disposición pública todos los datos de entrenamiento y evaluación, evaluamos nuestro método utilizando dos conjuntos de datos: un conjunto de datos sintético con 15K pares de imágenes de InstrcutPix2Pix y un conjunto de datos de 1K auto-recolectados con pares de imágenes-instrucciones reales. En el caso del conjunto de datos sintético, seguimos el ejemplo de InstructPix2Pix y trazamos las compensaciones entre la similitud de imagen CLIP y la similitud CLIP direccional. Para el conjunto de datos 1K, llevamos a cabo un estudio de usuarios determinado por los principales votos.
Resultados clave:
Demostramos que HIVE supera sistemáticamente a InstructPix2Pix tanto con el modelo oficial como con nuestro modelo replicado utilizando nuestro conjunto de datos de entrenamiento ampliado.
Modelo replicado utilizando nuestro conjunto de datos de entrenamiento ampliado.

Explore More
arxiv: https://arxiv.org/abs/2303.09618
Código y datos: https://github.com/salesforce/HIVE
Web: https://shugerdou.github.io/hive
Contacto: [email protected], [email protected], [email protected].