Huan Wang, Shelby Heinecke, Juan Carlos Niebles, Caiming Xiong

TL;DR: Lanzamos xLAM, una serie de LLMs optimizados para la llamada a funciones y Agentes AI. Ofrece varias variantes diseñadas para servir a diferentes dominios de aplicación, desde el uso móvil hasta contextos de rendimiento de alta demanda. Muestran un rendimiento competitivo en varias pruebas de agentes clave.
Los modelos de lenguaje de gran tamaño en el entorno de agentes
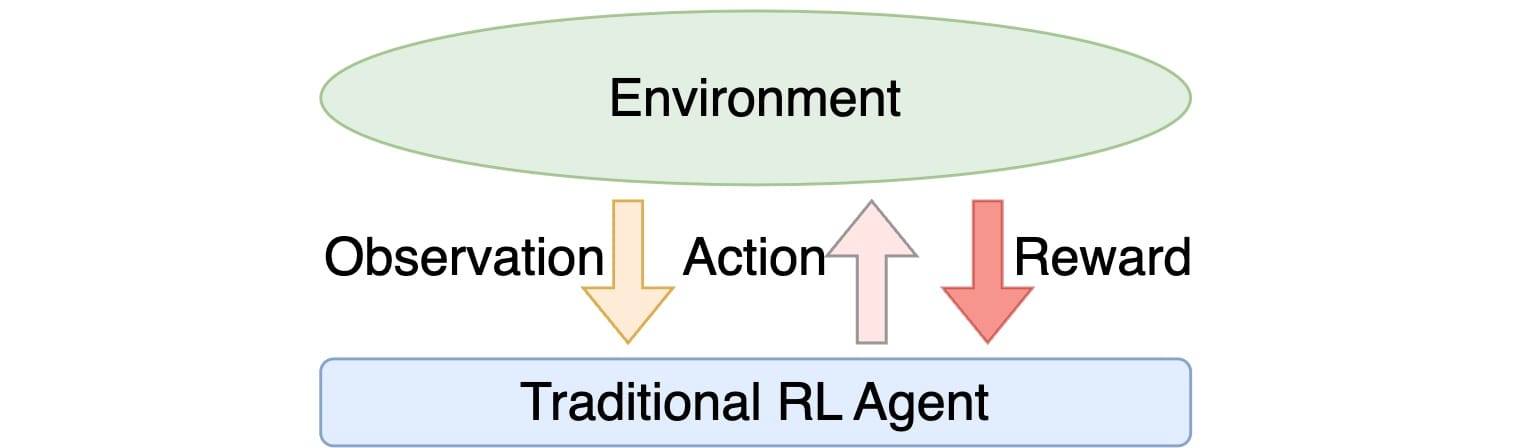
En un marco tradicional de aprendizaje por refuerzo (RL), la noción de «agente» desempeña un papel clave. Este marco comprende conceptos fundamentales como:
- Entorno: Acepta una secuencia de acciones de los agentes como entrada y, a su vez, les proporciona recompensas y observaciones. Numerosos entornos constan de estados y ejecutan transiciones de estado en función de las acciones ejecutadas por los agentes.
- Agentes: Estas entidades reciben recompensas y observaciones de los entornos y posteriormente producen acciones. La mayoría de los agentes también incorporan estados y facilitan transiciones de estado basadas en las acciones que realizan.
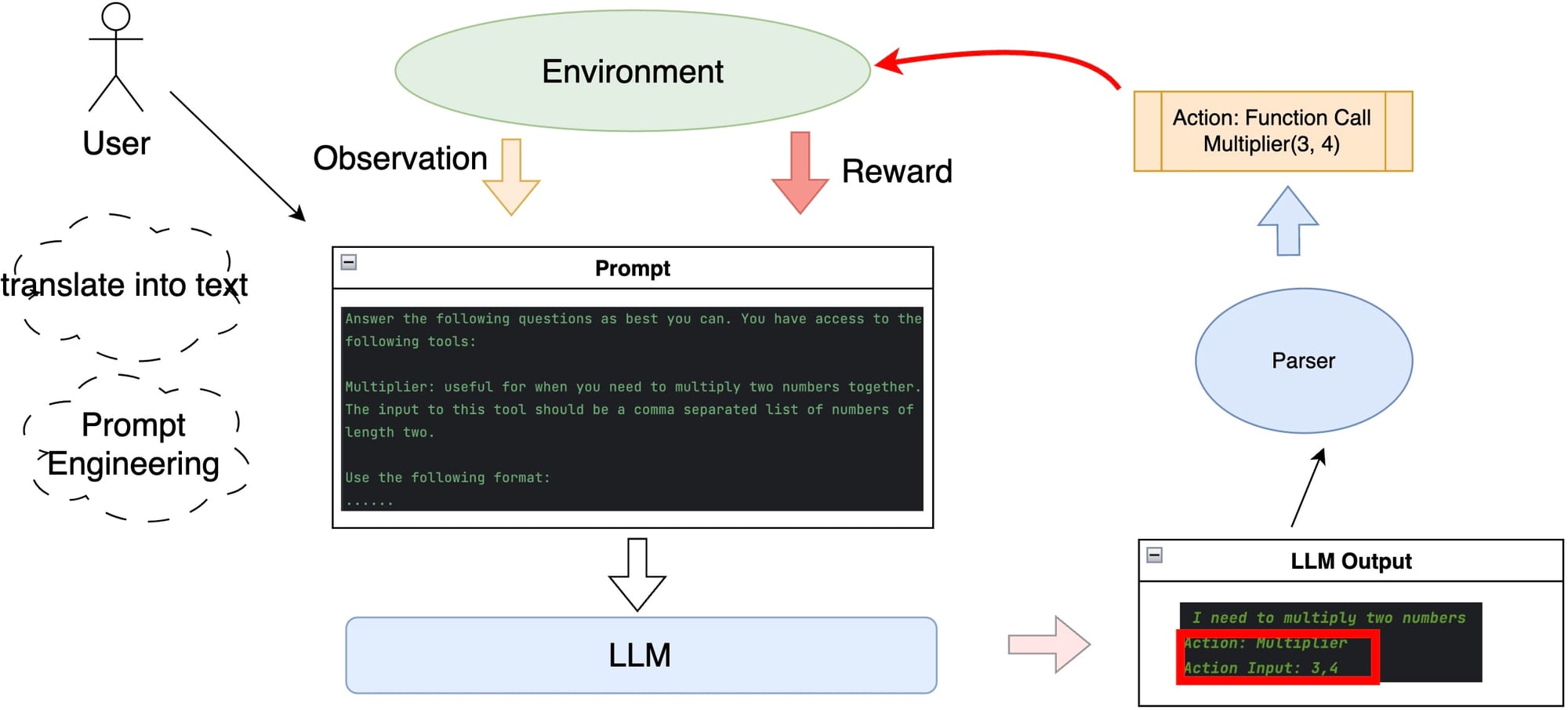
La aparición de los modelos de lenguaje de gran tamaño (LLM) pronto condujo a su aplicación en escenarios relacionados con agentes. Se descubrió que, con el estímulo adecuado, un LLM podía generar texto estructurado con una alta probabilidad. Dado que la salida está estructurada, puede analizarse fácilmente en funciones/acciones invocables. En particular, si el entorno puede representarse mediante texto, todas las observaciones y recompensas pueden encapsularse en el mensaje. En lugar del agente de RL convencional que modela las distribuciones de acción condicionales, podría emplearse un LLM genérico combinado con un analizador de salida para determinar la siguiente acción.
Modelos de lenguaje de gran tamaño optimizados para la llamada a funciones
La llamada a funciones plantea una de las aplicaciones de agente más solicitadas, en la que el agente tiene la tarea de completar las órdenes del usuario mediante una serie de llamadas a funciones. Normalmente, éstas pueden incluir una amplia gama de funciones/API potenciales que podrían utilizarse para ayudar a cumplir los requisitos del usuario. Cada una de estas funciones/API posee descripciones, argumentos y retornos distintos. Las funciones aplicables se presentan a los LLMs en el prompt, y los LLMs eligen entonces las funciones apropiadas basándose en el contexto y el objetivo específico, eligen los argumentos correspondientes y obtienen la salida de las funciones elegidas.
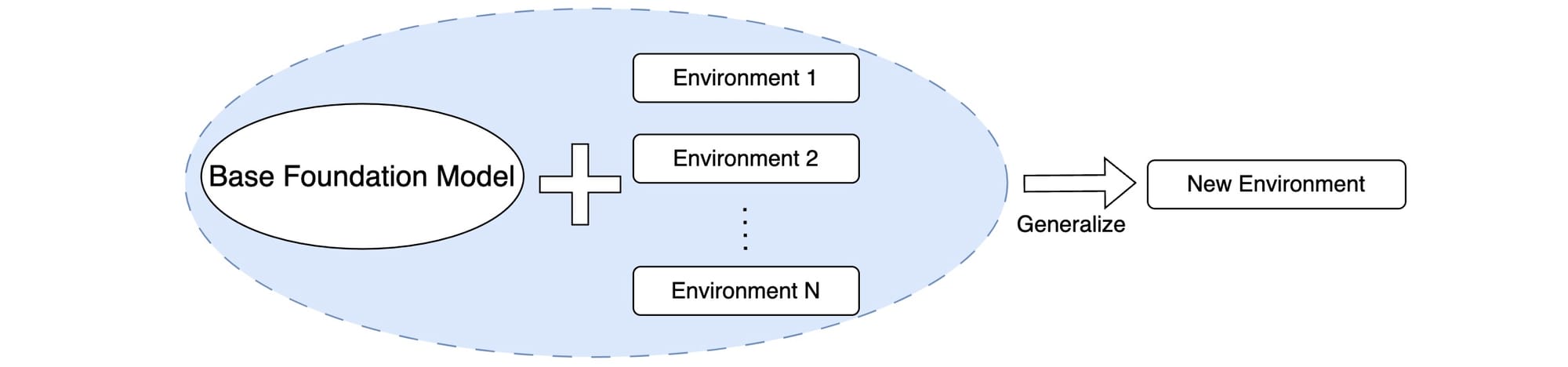
El atractivo generalizado de las aplicaciones de llamada a funciones requiere LLMs mejorados. Sin embargo, el inconveniente es que los LLM genéricos no están adaptados específicamente a los contextos de llamada a funciones. Para solucionar este problema, hemos compilado una de las colecciones más extensas de entornos y datos de llamada de funciones, garantizando un formato uniforme en todos los conjuntos de datos. La idea es que, a medida que se utilicen más datos de distintos entornos de llamada de funciones para entrenar cualquier modelo básico, el modelo debería, en teoría, ser capaz de adaptarse a entornos de llamada de funciones desconocidos.
xLAM: Una solución para todos
Estamos lanzando tres variantes de xLAM para atender diferentes escenarios:
- xLAM-7b-r: Un modelo 7b diseñado para la exploración académica rápida con recursos limitados de GPU.
- xLAM-8x7b-r: Un modelo de mezcla de expertos de 8x7b, ideal para aplicaciones industriales que buscan una combinación equilibrada de latencia, consumo de recursos y rendimiento.
- xLAM-8x22b-r: se trata de un modelo de mezcla de expertos de gran tamaño si se dispone de grandes recursos computacionales y se desea perseguir el máximo rendimiento.
Estas tres variantes de modelos xLAM están diseñadas para escenarios de aplicación de una y varias vueltas en diversos entornos y pruebas de rendimiento. Anteriormente lanzamos dos versiones de nuestros modelos xLAM entrenados específicamente para las tareas de llamada de funciones de una sola vuelta: xLAM-1b-fc-r y xLAM-7b-fc-r. En particular, xLAM-7b-fc-r ocupó el segundo lugar en la anterior Berkely Function Calling Leaderboard V1. Actualmente ocupa el puesto 16 en la Berkeley Function Calling Leaderboard V2 Live. Su homólogo compacto, xLAM-1b-fc-r, apodado el «Gigante diminuto», cuenta con sólo mil millones de parámetros, lo que lo hace ideal para aplicaciones móviles.
Resultados
Nuestros modelos de la serie xLAM obtienen resultados consistentes en varios entornos de evaluación comparativa clave, incluidos ToolBench, Berkeley Function Calling Leaderboard, Webshop y AgentBoard. A continuación se muestra un resumen de los resultados:
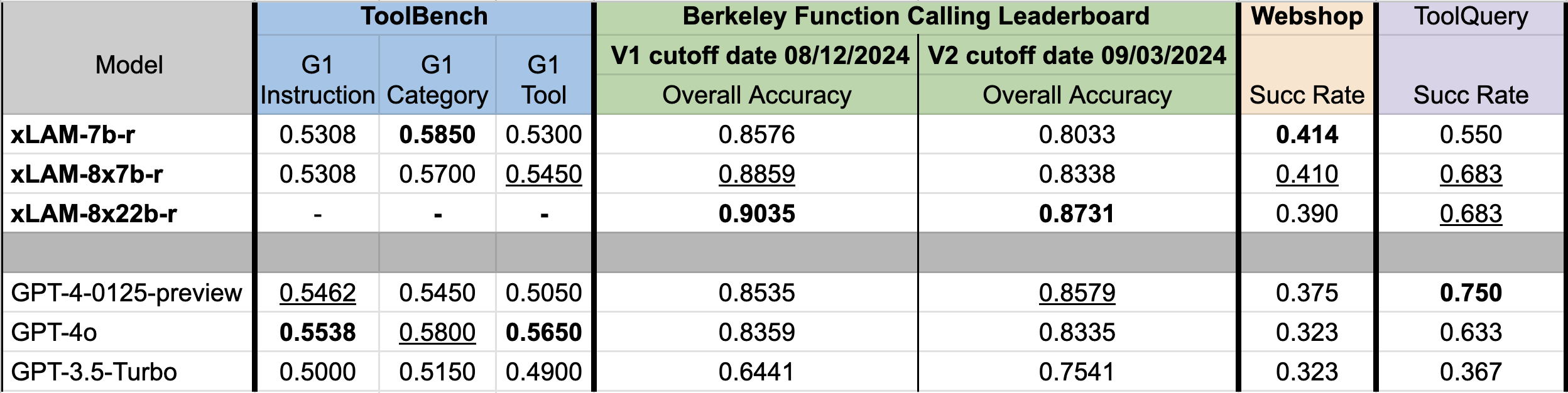
Debido a la reciente interrupción del servicio de ToolBench, los resultados de xLAM-8x22b-r en ToolBench aún no están disponibles. Aun así, está claro que la serie de modelos xLAM ofrece un rendimiento bastante comparable al de los modelos GPT de OpenAI con un tamaño de modelo mucho menor. En particular, el modelo xLAM-8x22b-r encabeza la clasificación de llamadas a funciones de Berkeley en nuestra evaluación.
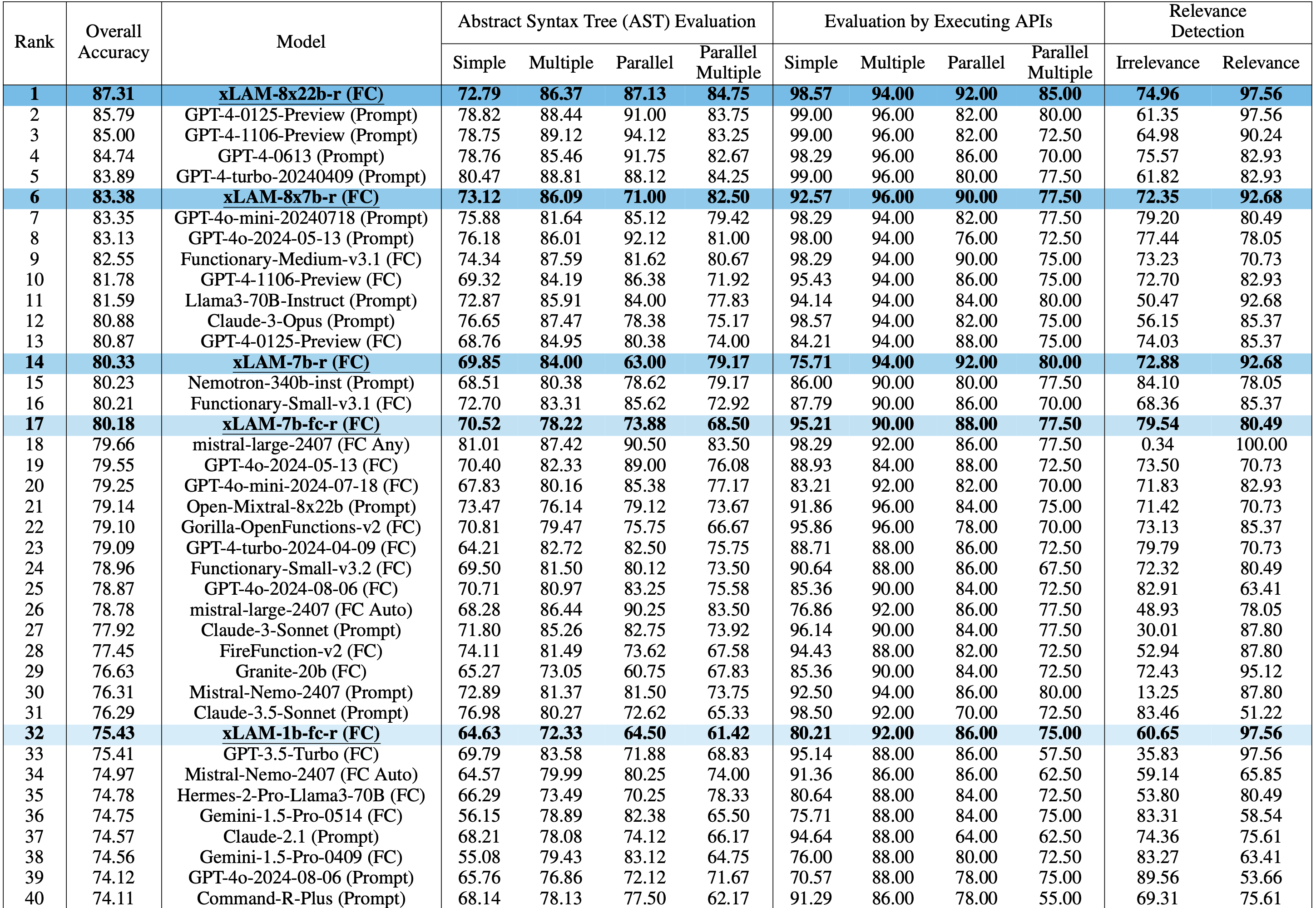
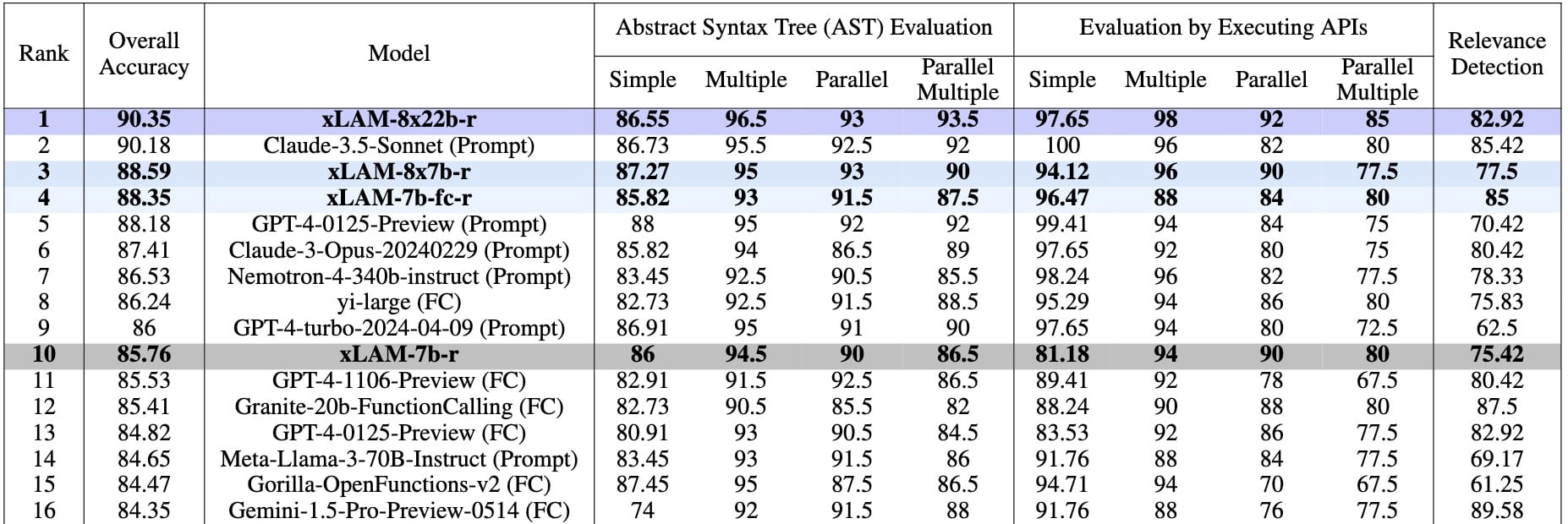
Model Performance vs. Size on the Berkeley Function Calling Leaderboard
Aunque los modelos más pequeños pueden funcionar adecuadamente en situaciones específicas, hemos observado que los modelos más grandes suelen lograr una mayor precisión general. Sin embargo, este mayor rendimiento se consigue a costa de un aumento de los recursos informáticos y de la latencia. Encontrará resultados detallados en nuestro artículo arXiv.
Technology
Datos y entornos
Nuestra investigación sobre llamadas a funciones reunió un conjunto diverso de conjuntos de datos, incluidos algunos notables como ToolBench, Webshop, ToolApaca, HotpotQA, AlfWorld, APIBank, Mind2Web, AgentBoard y AgentBench. Además de estos conjuntos de datos de llamadas a funciones existentes, hemos enriquecido nuestra base de datos con datos sintéticos como API-GEN, SpecTools (próximamente) y un entorno propio de simulación de modelos de acción de gran tamaño (LAM Simulator).
Formato unificado
Todos los conjuntos de datos se combinan y se unifican utilizando un formato coherente para el ajuste del modelo. Para obtener un rendimiento más coherente, propusimos un formato unificado y procesamos todos los datos en el formato propuesto antes del entrenamiento del modelo.
Aumento y purga de datos
El formato de datos unificado es fundamental para el aumento y la purificación sistemáticos de nuestro conjunto de datos a gran escala. Mediante un proceso de aumento meticulosamente diseñado, mejoramos nuestros datos brutos a través de varias técnicas, entre las que se incluyen la diversificación de instrucciones y formatos, el aumento de tokens especiales, el barajado de órdenes/secuencias y la síntesis de datos a partir del análisis de casos de fallo.
A través de nuestra experimentación, hemos discernido que el mero volumen de datos no garantiza un rendimiento superior del modelo. Por el contrario, la calidad de los datos es un factor fundamental. Los conjuntos de datos como ToolBench, a pesar de su gran cantidad, suelen ser ruidosos. La integración indiscriminada de estos conjuntos de datos ruidosos en la fase de entrenamiento puede disminuir significativamente la calidad de los datos. Para mantener una integridad y un control superiores de los datos, empleamos los modelos GPT de OpenAI para purgar las muestras de los conjuntos de datos con problemas potenciales de calidad de datos.
Síntesis de datos
Además de los entornos y conjuntos de datos existentes, construimos varias canalizaciones y entornos para generar datos sintéticos, que luego se utilizan para enriquecer aún más el conjunto de entrenamiento de llamada de funciones. En esta línea de trabajo, hemos publicado varios artículos/informes, entre los que se incluyen
- APIGEN: un proceso automatizado de generación de datos diseñado para producir conjuntos de datos verificables de alta calidad para aplicaciones de llamada de funciones.
- xLAM-Simulator [próximamente]: nuestro simulador para agentes lingüísticos centrado en el uso de herramientas que pueden proporcionar información a los planes/acciones.
- SpecTool [próximamente]: un benchmark a pequeña escala para identificar patrones de error en la salida LLM en tareas de uso de herramientas.
Conclusión
Nos complace presentar una colección de grandes modelos de acción, denominados xLAM, diseñados para satisfacer una amplia gama de escenarios de aplicación, que abarcan desde dispositivos móviles hasta aplicaciones de rendimiento extremo. Nuestros modelos muestran un rendimiento competitivo en varios de los principales puntos de referencia de agentes. Además de estos modelos, ofrecemos informes técnicos completos sobre el entrenamiento, la evaluación y la generación de datos sintéticos del modelo, así como información detallada sobre nuestros nuevos entornos y simulaciones.
Agradecimientos
Lista completa de autores: Jianguo Zhang∗, Tian Lan∗, Ming Zhu∗, Zuxin Liu∗, Thai Hoang∗, Shirley Kokane†, Weiran Yao†, Juntao Tan, Akshara Prabhakar, Zhiwei Liu, Haolin Chen, Yihao Feng,Tulika Awalgaonkar, Rithesh Murthy, Eric Hu, Zeyuan Chen, Ran Xu, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Silvio Savarese, Caiming Xiong