A medida que se acelera el desarrollo y la implantación de grandes modelos lingüísticos (LLM), la evaluación de los resultados de los modelos adquiere cada vez más importancia. El método establecido para evaluar las respuestas suele consistir en contratar y formar a evaluadores humanos, hacer que evalúen las respuestas del modelo y, a continuación, auditar la calidad de las evaluaciones. Desgraciadamente, este proceso no se adapta al ritmo frenético de publicación de nuevos LLM. Por ello, los profesionales han empezado a utilizar los propios LLM como evaluadores. En este caso, un LLM (también denominado modelo juez) recibe las entradas y salidas de un modelo de un usuario. A continuación, se pide al modelo juez que califique los resultados basándose en ciertos criterios de evaluación.
Presentamos SFR-Judge, una familia de tres modelos juez de 8 mil millones de parámetros de tamaño 8B, 12B y 70B, construidos con Meta Llama 3 y Mistral NeMO. Estos modelos de jueces están entrenados para realizar tres tipos diferentes de tareas de evaluación: comparaciones por pares («¿Es la salida A mejor que la salida B?»), valoraciones individuales («Valore la salida en una escala Likert de 1-5») y clasificación binaria («¿Cumple la salida los criterios especificados?»). En Salesforce AI Research entendemos que la confianza es un pilar fundamental de la evaluación. Por lo tanto, nuestros jueces no sólo son capaces de producir juicios, sino que están específicamente entrenados para producir explicaciones para sus juicios, evitando la naturaleza de caja negra de otros tipos de modelos de jueces.
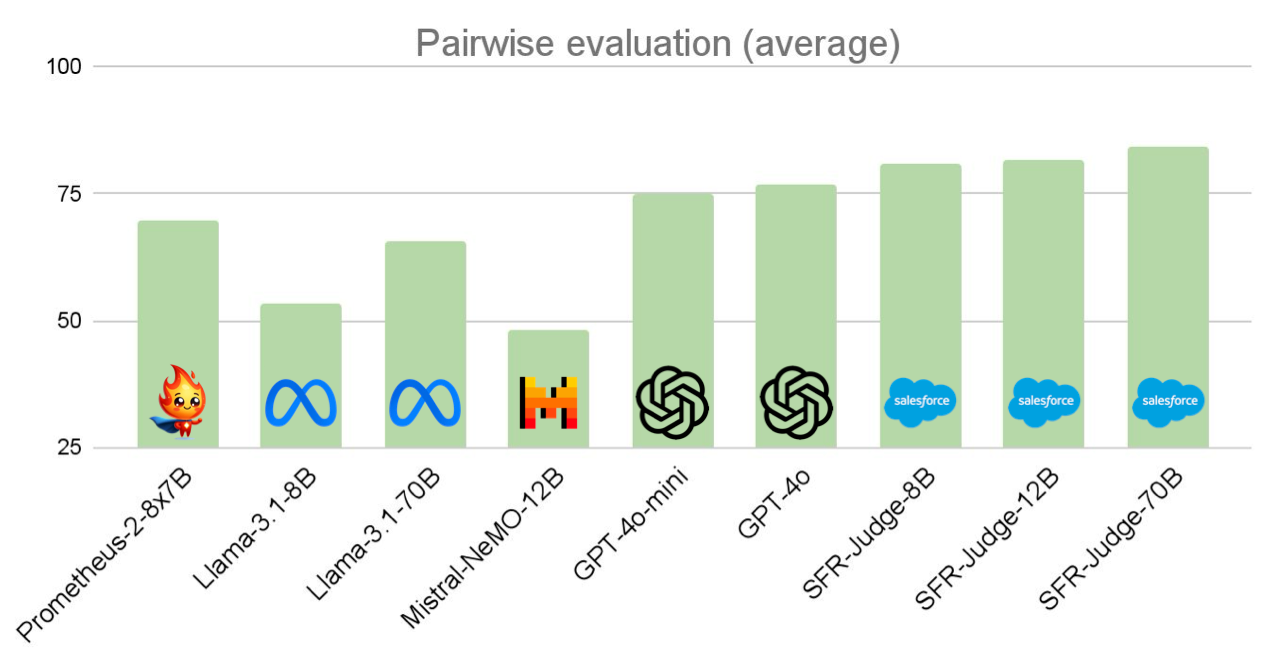
Para evaluar SFR-Judge, realizamos experimentos exhaustivos en trece puntos de referencia de las tres tareas de evaluación. Este conjunto de experimentos evaluó la capacidad de nuestro modelo para realizar diferentes tareas que se le pueden pedir a un modelo de juez: modelado de recompensas, determinación de la seguridad de los resultados, evaluación de las capacidades de seguimiento de instrucciones de otros modelos, o incluso evaluación de resultados basada en rúbricas precisas. Nuestros modelos superaron sistemáticamente a otros modelos de juez de código abierto, así como a potentes modelos patentados, como GPT-4o, logrando el mejor rendimiento en 10/13 pruebas de referencia.
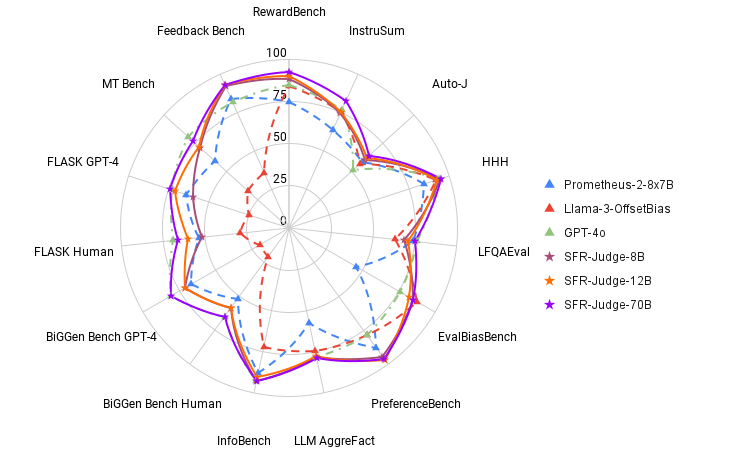
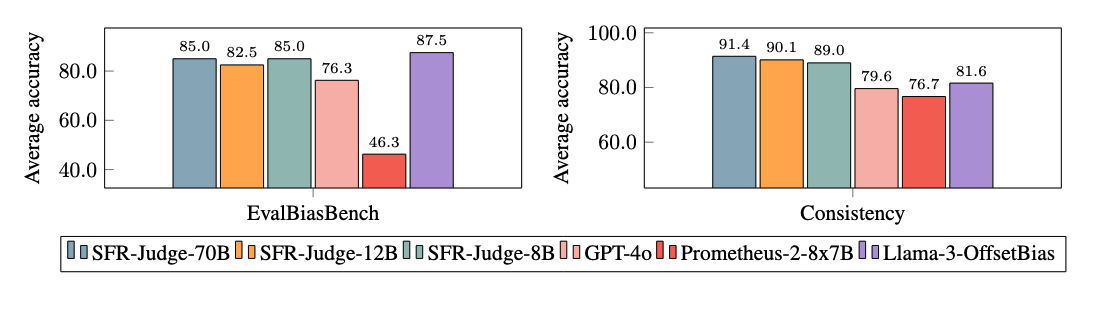
Aunque los modelos de juez ofrecen una alternativa flexible a las evaluaciones humanas, también pueden ser sensibles a ciertos sesgos de evaluación. Al responder a las comparaciones por pares, algunos modelos de juez son sensibles al orden en que se presentan las respuestas, con el juez cambiando su respuesta en función de si la respuesta A y la respuesta B se intercambian. Además, los modelos de juez pueden preferir respuestas más largas y agradables que no satisfacen la petición del usuario a respuestas concisas que satisfacen con precisión la petición del usuario. Para detectar sesgos, (a) evaluamos nuestros modelos en EvalBiasBench [https://github.com/ncsoft/offsetbias], que evalúa modelos de jueces en 6 tipos diferentes de sesgo (por ejemplo, longitud, conocimiento familiar, etc.) y (b) registramos la consistencia del orden de los pares (¿responde el modelo con el mismo juicio si intercambiamos el orden de las respuestas?) de nuestros modelos a través de 7 puntos de referencia de comparación de pares. Nuestros modelos demuestran ser menos sesgados en EvalBiasBench, a la vez que muestran niveles de consistencia mucho más altos que muchos modelos de jueces de la competencia.
Los modelos de jueces no sólo se utilizan para la autoevaluación, sino también para mejorar otros LLMs mediante la evaluación de sus resultados para el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). Aquí, el modelo a mejorar (el modelo descendente) produce salidas, y se utiliza un modelo juez para puntuar cada respuesta. A partir de ahí, el modelo descendente se entrena aún más para fomentar las respuestas mejor valoradas y desalentar las respuestas peor valoradas. En este contexto, el modelo de juez suele denominarse modelo de recompensa.
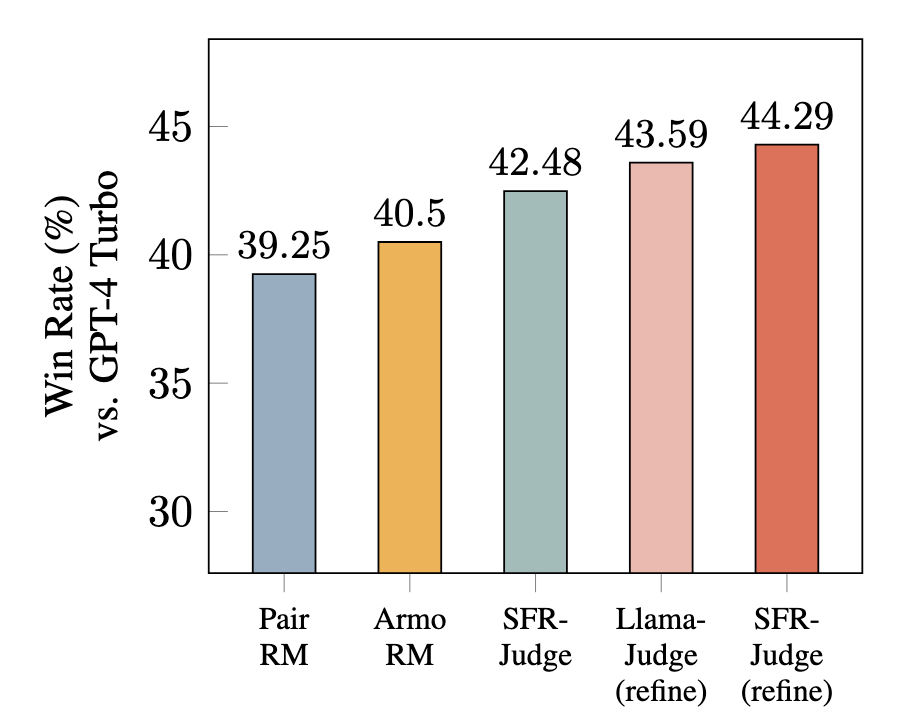
En particular, nuestros modelos ocupan el primer, segundo y cuarto puesto en la clasificación de RewardBench para modelos de juez generativos a fecha de 20 de septiembre de 2024. RewardBench es un punto de referencia para evaluar las capacidades de modelado de recompensas de los modelos de jueces. Nuestros modelos fueron la primera y la segunda vez que un juez generativo superó el umbral del 90% de precisión en RewardBench. También pusimos nuestros modelos a prueba, demostrando que SFR-Judge no sólo actúa como potentes modelos de recompensa, sino que las explicaciones generadas a partir de nuestros modelos de juez pueden utilizarse para mejorar los resultados de los modelos descendentes. Comparamos nuestros modelos con dos clasificadores de caja negra (es decir, (es decir, no se generan explicaciones) basados en clasificadores de recompensa y demostramos que los modelos descendentes mejorados con SFR-Judge muestran un mejor rendimiento en AlpacaEval-2, una prueba comparativa de seguimiento de instrucciones.
SFR-Judges marca un paso emocionante en la autoevaluación y el modelado de recompensas. Para más información, consulte nuestro artículo.
Partículo: https://arxiv.org/abs/2409.14664
Código (próximamente): https://github.com/SalesforceAIResearch/SFRJudge