Este trabajo se realizó en colaboración con muchos otros grandes coautores: Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, Yejin Choi y Ludwig Schmidt.
Estamos encantados de abrir 🍃MINT-1T, el primer conjunto de datos intercalados multimodales de un billón de tokens y un valioso recurso para que la comunidad estudie y construya grandes modelos multimodales.
Background
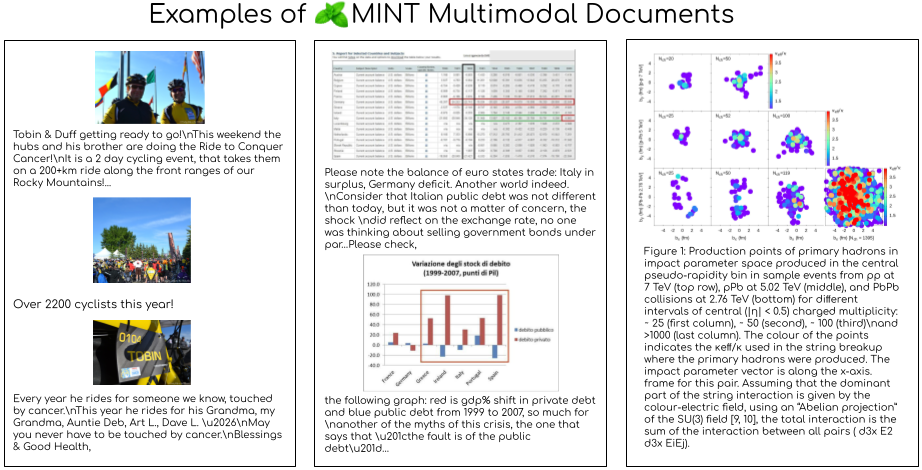
Los documentos multimodales intercalados son secuencias de imágenes intercaladas en texto. Esta estructura nos permite entrenar grandes modelos multimodales capaces de razonar entre modalidades de imagen y texto. Algunos de los modelos multimodales más capaces, como MM1, Chameleon e Idefics2, han demostrado la importancia de entrenar con datos intercalados para obtener el mejor rendimiento.
Building MINT-1T

Nuestros principios fundamentales para la conservación de 🍃MINT-1T son la escala y la diversidad. Mientras que los anteriores conjuntos de datos de código abierto, como OBELICS y MMC4, contaban con un máximo de 115.000 millones de tokens, en 🍃MINT-1T recopilamos 1 billón de tokens, lo que permite a los profesionales entrenar modelos multimodales mucho mayores. Para mejorar la diversidad de 🍃MINT-1T, vamos más allá de los documentos HTML e incluimos PDF a escala web y artículos de ArXiv. Encontramos que estas fuentes adicionales mejoran la cobertura del dominio particularmente en documentos científicos.
Experimentos de modelos
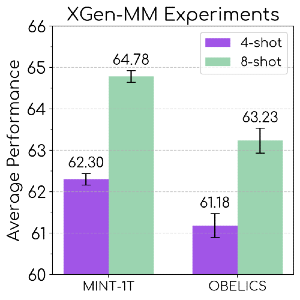
Validamos 🍃MINT-1T preentrenando modelos multimodales XGen-MM (muestreando el 50% de los tokens de documentos HTML y el resto de PDFs/ArXiv). Evaluamos nuestros modelos en pruebas de subtitulado y respuesta a preguntas visuales. Descubrimos que 🍃MINT-1T supera al anterior conjunto de datos multimodal intercalado líder, OBELICS.
Trabajo futuro
Ya estamos entrenando nuestra nueva iteración de modelos XGen-MM en 🍃MINT-1T y estamos deseando seguir compartiendo algunos de los mejores conjuntos de datos y modelos de código abierto con la comunidad.
Explore más
Salesforce AI le invita a profundizar en los conceptos tratados en esta entrada de blog (enlaces más abajo). Conéctese con nosotros en las redes sociales y en nuestro sitio web para obtener actualizaciones periódicas sobre éste y otros proyectos de investigación.
Ackledgments
Un gran agradecimiento al equipo de infraestructura, Srinath Reddy Meadusani y Lavanya Karanam, por su enorme trabajo y a Paul Josel por ayudarnos con el diseño de figuras.
Por favor, no dude en ponerse en contacto con nosotros