La Generación Aumentada por Recuperación (RAG) no sólo ha ganado fuerza como una de las áreas de investigación con mayor inversión en IA generativa, sino que también ha adquirido una popularidad y unas oportunidades de comercialización considerables. La RAG se aplica normalmente a problemas de respuesta de preguntas, en los que se proporciona cierta información contextual externa recuperada de una fuente de datos (potencialmente privada) como parte de la pregunta y se espera que la respuesta generada esté basada en hechos en las pistas contextuales. RAG cuenta con un recuperador, que recupera el conocimiento relevante, y un gran modelo de lenguaje (LLM) que genera una respuesta fiel o reconoce si el contenido contextual es irrelevante o contradictorio.

En Salesforce AI Research, comprendemos la importancia de la fidelidad y la precisión a la hora de crear sistemas GAR que dependen en gran medida del rendimiento del LLM. Por lo tanto, presentamos SFR-RAG, un modelo de lenguaje de 9.000 millones de parámetros entrenado con un énfasis significativo en las capacidades de generación contextual fiables, precisas y fieles específicas de los casos de uso de GAR del mundo real y las tareas agenticas relevantes. Entre ellas se incluyen la extracción precisa de conocimientos fácticos, la distinción entre contextos relevantes y de distracción, la cita de fuentes apropiadas junto con las respuestas, la producción de razonamientos complejos y multisalto en múltiples contextos, el seguimiento coherente de formatos, así como la abstención de alucinaciones sobre consultas sin respuesta.
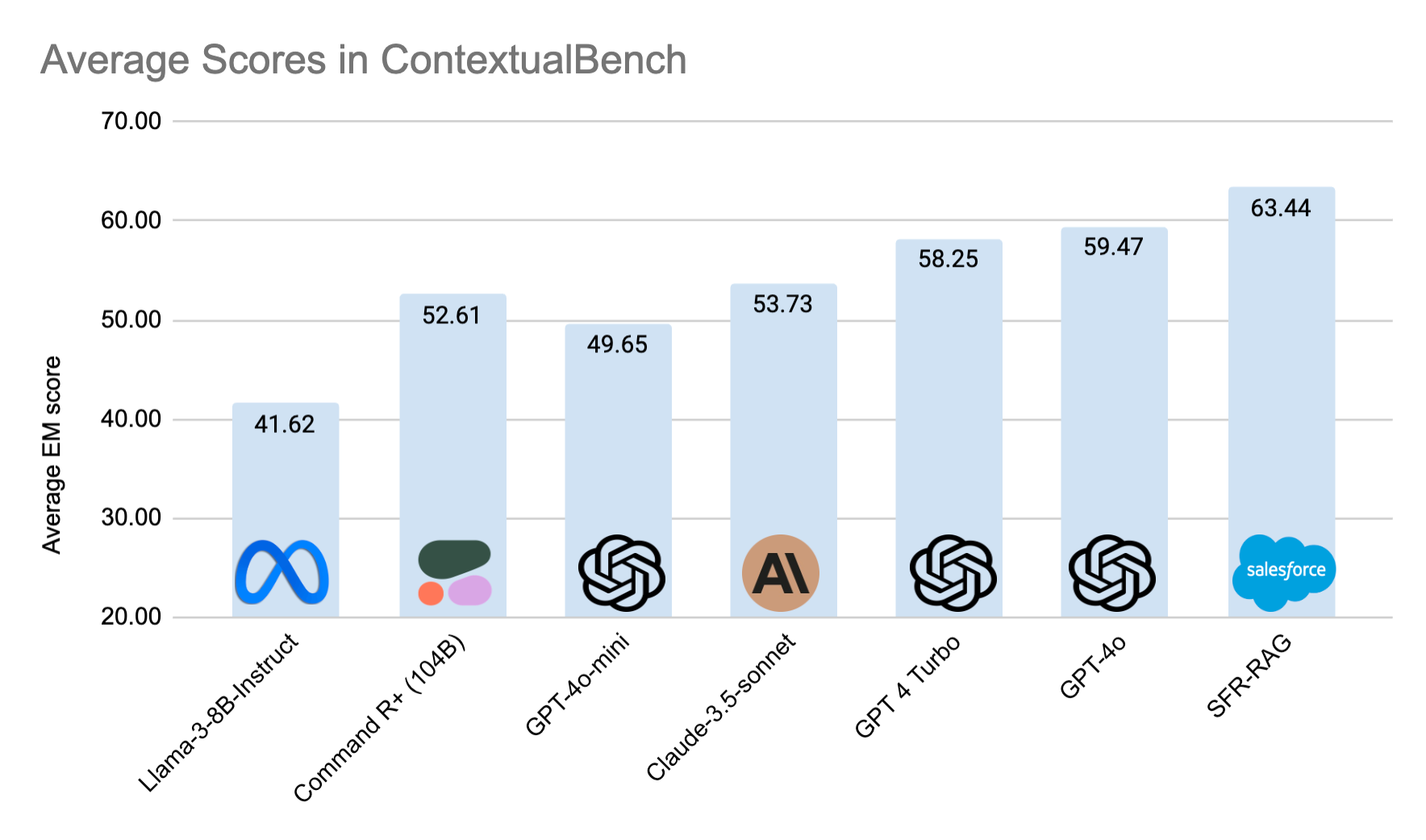
Para evaluar de forma fiable los LLM en tareas contextuales de respuesta a preguntas relevantes para la GAR, también publicamos ContextualBench, un conjunto de evaluación formado por 7 pruebas contextuales, como HotpotQA y 2WikiHopQA, que se miden con configuraciones coherentes.
SFR-RAG supera a GPT-4o y alcanza el estado del arte en 3 de los 7 puntos de referencia de ContextualBench, y supera abrumadoramente a Command-R+ con 10 veces menos parámetros. También se demuestra que SFR-RAG eclipsa ampliamente las líneas de base notables al respetar la información contextual de forma sólida y fiel, incluso cuando los hechos contextuales se fabrican, alteran, eliminan o contradicen.
Aplicación RAG fiable con una nueva plantilla de chat
La mayoría de los modelos lingüísticos vienen con una plantilla de chat estándar con 3 roles conversacionales: Sistema, Usuario y Asistente. Sin embargo, a medida que los LLMs asumen casos de uso más complejos como el RAG, donde los modelos tienen que realizar múltiples pasos de razonamiento y usos de herramientas antes de llegar a la respuesta final. Las implementaciones comunes suelen colocar estos pasos no conversacionales dentro del turno del Asistente. Este diseño tiene varias desventajas:
- Pueden surgir problemas de seguridad y privacidad si dichos pasos internos de procesamiento de datos implican información sensible, ya que los pasos pueden mostrarse a los usuarios.
- La fiabilidad de la aplicación es incierta, ya que esos pasos de razonamiento y los resultados del uso de herramientas deben analizarse utilizando palabras clave producidas en el turno del Asistente, que el modelo puede no generar.
- Entrenar LLMs para tareas RAG complejas no es sencillo porque necesitamos realizar un enmascaramiento de tokens personalizado en partes del turno del Asistente. También es difícil ajustar la seguridad de los LLM cuando se pueden inyectar instrucciones maliciosas como parte del contenido contextual.

Para resolver estos problemas, proponemos una sencilla modificación de la plantilla de chat mediante la introducción de 2 roles opcionales: Pensamiento y Observación.
- Pensamiento es donde el LLM puede hablar libremente consigo mismo, realizar acciones o razonar.
- Observación es donde se aloja la información contextual externa.
La separación de los pensamientos intermedios y los resultados devueltos por la función del turno Asistente nos permite ajustar fácilmente el LLM sin una tediosa lógica de enmascaramiento o un analizador de palabras clave. También ayuda a los desarrolladores a crear aplicaciones RAG con facilidad, ya que pueden mostrar u ocultar los pensamientos y los documentos recuperados al usuario según sus casos de uso, y extraer contenidos sin un analizador sintáctico engorroso y poco fiable. Y lo que es más importante, el asistente de turno se ve ahora liberado de responsabilidades adicionales y puede centrarse en ofrecer respuestas fáciles de usar.
SFR-RAG Contextual Performances
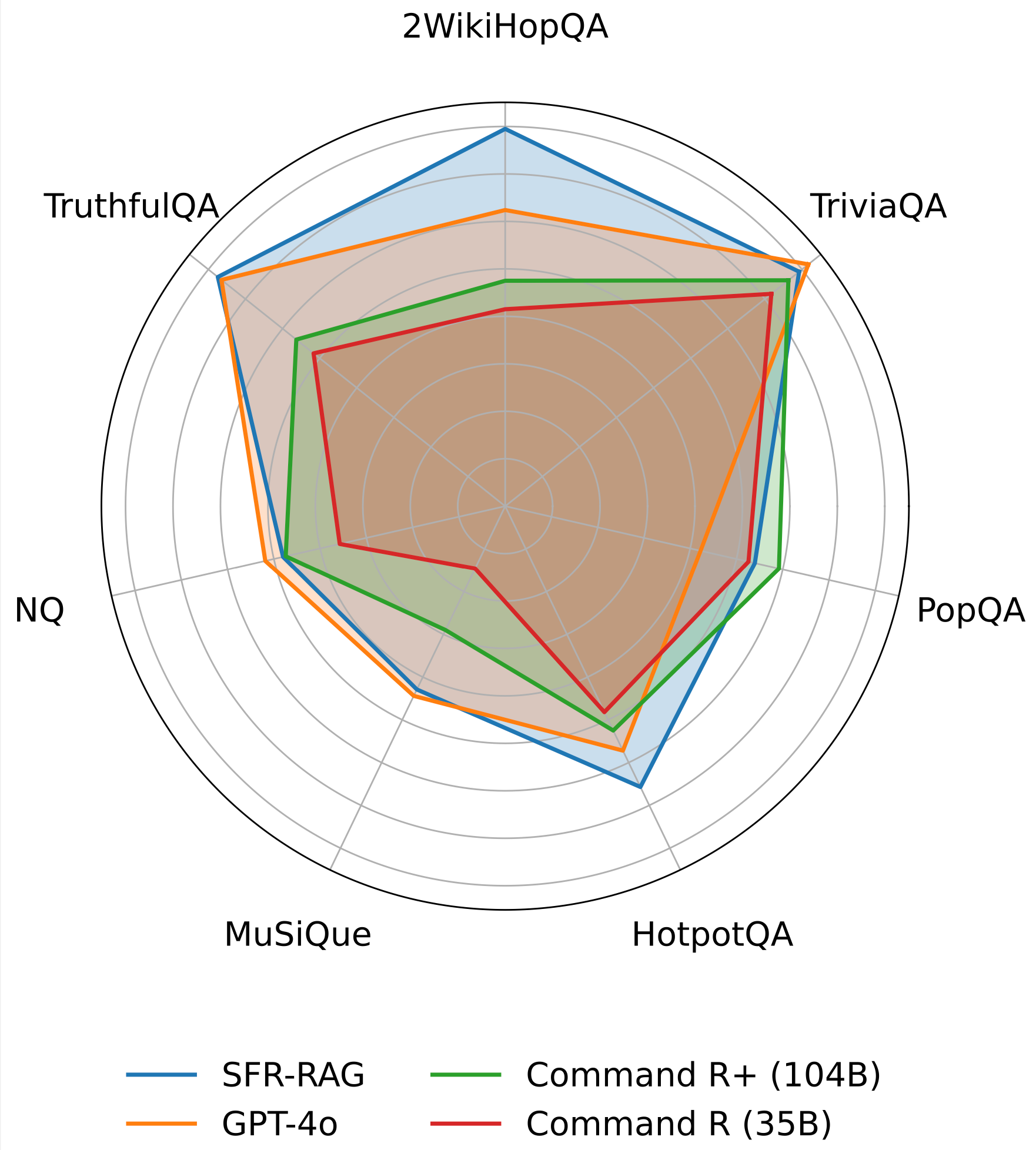
SFR-RAG alcanza el estado del arte en 3 de los 7 benchmarks de la suite ContextualBench, con la puntuación media más alta. SFR-RAG tiene el mayor margen en 2WikiHopQA. Supera a Command-R+ en casi todas las pruebas, con 10 veces menos parámetros.
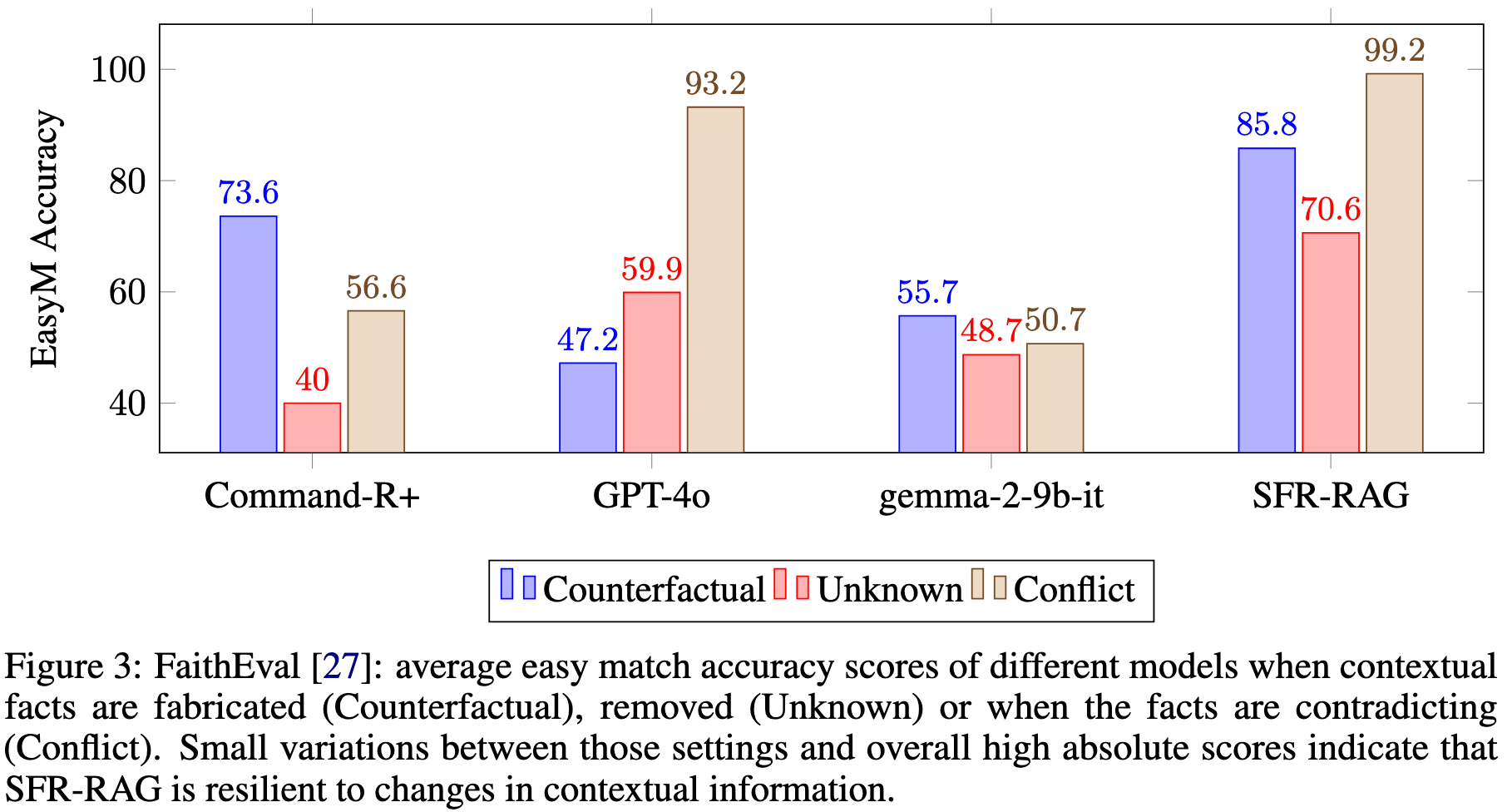
SFR-RAG es robusto y resistente a nuevos cambios en los documentos de contexto, tal y como evalúa la suite FaithEval, que mide el grado de fidelidad al contexto de un modelo lingüístico. Como muestra la Figura 3, SFR-RAG obtiene puntuaciones más altas en todas las categorías, a saber, Contrafactual, Desconocido y Conflicto. Esto significa que el modelo es fiel al contexto aunque los hechos cambien o se vuelvan contraintuitivos (Contrafáctico). El modelo también puede reconocer si el contexto no contiene la respuesta (Desconocido) y si contiene información contradictoria (Conflicto). Los resultados indican que SFR-RAG es menos propenso a la alucinación que las alternativas, que es el criterio más importante para la construcción de una aplicación GAR fiable.
SFR-RAG estará disponible a través de API en breve. Todos los servicios o funciones a los que se hace referencia aquí no están disponibles actualmente y es posible que no se ofrezcan a tiempo o no se ofrezcan en absoluto. Los clientes deben tomar sus decisiones de compra basándose en las funciones que están disponibles actualmente.
Más información:
Perfleto: https://arxiv.org/pdf/2409.09916
Marco de evaluación de ContextualBench: https://huggingface.co/datasets/Salesforce/ContextualBench

ContextualBench-leaderboard: https://huggingface.co/spaces/Salesforce/ContextualBench-Leaderboard