Como parte de nuestro compromiso con la innovación en GAR empresarial e IA de confianza, nos complace presentar SFR LlamaRank, un reranker de última generación de Salesforce AI Research. LlamaRank es un modelo lingüístico especializado en la clasificación de relevancia de documentos. LlamaRank consigue un rendimiento al menos comparable al de las principales API en la clasificación general de documentos, al tiempo que demuestra una notable mejora en la búsqueda de código. El rendimiento de LlamaRank se debe en gran medida a las múltiples rondas de comentarios iterativos sobre políticas proporcionados por el equipo de anotación de datos RLHF de Salesforce.
Pruébelo ahora mismo en Together.ai!

¿Qué es un Reranker?
En el contexto de los sistemas de Generación Mejorada de Recuperación (RAG), un reranker desempeña un papel crucial en la mejora de la calidad y relevancia de la información recuperada de grandes repositorios de documentos. Así es como se integra en el proceso de RAG:
- Recuperación inicial: Cuando un usuario plantea una consulta, el sistema utiliza primero métodos rápidos, aunque a veces menos precisos, como la búsqueda semántica con incrustaciones para recuperar un conjunto de documentos o pasajes potencialmente relevantes.
- Reranking: Aquí es donde entra en juego el reranker. Toma el conjunto de documentos recuperados inicialmente y realiza un análisis más sofisticado para determinar cuáles son realmente los más relevantes para la consulta. El reordenador tiene en cuenta varios factores y matices que la recuperación inicial podría haber pasado por alto.
- Selección final: los documentos mejor clasificados en la fase de reordenación se utilizan como contexto para que el modelo lingüístico genere una respuesta.
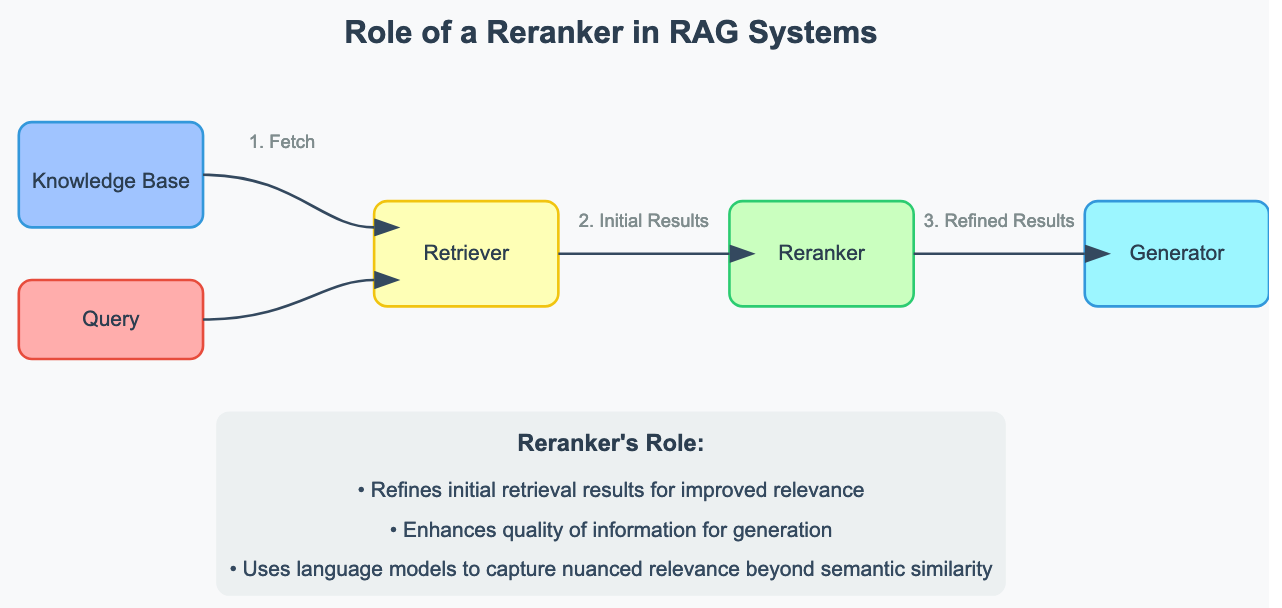
El reranker es esencial porque mejora significativamente la calidad de la información introducida en el modelo lingüístico al tiempo que optimiza la relevancia de los documentos pasados al contexto de los modelos de respuesta generativa. De este modo, se obtienen respuestas más precisas, pertinentes y coherentes en aplicaciones empresariales como los sistemas de atención al cliente, las bases de conocimiento internas o las herramientas de búsqueda de código. Al garantizar que sólo se utiliza la información más pertinente, los rerankers ayudan a reducir las alucinaciones y mejoran la fiabilidad general de los sistemas RAG.
Esencialmente, los rerankers cubren el vacío existente entre la búsqueda (rápida, barata, ruidosa) y los grandes modelos lingüísticos (más lentos, costosos, inteligentes) para los sistemas RAG.
Detalles técnicos
LlamaRank es un ajuste fino de Llama3-8B-Instruct. Los datos de entrenamiento incluyen datos sintetizados de Llama3-70B y Llama3-405B y datos etiquetados por humanos de nuestro equipo interno de anotación de datos. Los datos incluyen búsquedas por temas, control de calidad de documentos y noticias, control de calidad de códigos y otros tipos de datos de recuperación relevantes para la empresa. El modelo se sometió a múltiples iteraciones de comentarios sobre la política de nuestro equipo de anotación de datos. Estos anotadores, altamente cualificados en la puntuación de relevancia de pares documento-consulta, identificaron y corrigieron errores cometidos por versiones anteriores del modelo. Este proceso iterativo mejoró significativamente el rendimiento de LlamaRank. En el momento de la inferencia, LlamaRank utiliza una plantilla fija para los pares (documento, consulta). Se calcula una puntuación numérica de relevancia basada en las probabilidades de token predichas por el modelo. La inferencia es rápida porque sólo es necesario predecir un único token para cada documento.
Evaluación del rendimiento
Evaluamos LlamaRank en cuatro conjuntos de datos públicos:
- SQuAD: un conjunto de datos de respuesta a preguntas basado en Wikipedia
- TriviaQA: Un conjunto de datos de respuesta a preguntas centrado en preguntas de tipo trivial a partir de datos web generales
- Neural Code Search (NCS): Un conjunto de datos de búsqueda de código comisariado por Facebook
- TrailheadQA: Una colección de documentos Trailhead disponibles públicamente y preguntas de los concursos correspondientes
Para los rerankers, las elecciones de N (número de documentos introducidos en el reranker) y K (número de documentos devueltos por el reranker) son fundamentales en la compensación precisión-recuerdo del sistema de recuperación y el rendimiento general del sistema RAG.
Para simplificar, para todos los conjuntos de datos, mantenemos K (el número de documentos devueltos por el reranker en el contexto de la respuesta LM) fijo en 8. Encontramos que este es un buen punto de equilibrio. Con K=8, observamos una recuperación de documentos razonablemente alta. Aumentar K más llevaría a un aumento de los costes y, en algunos casos, puede aumentar la tasa de error del modelo de respuesta debido a la inclusión de contexto espurio que actúa como una distracción.
El número de documentos de entrada en el reranker (N) se fijó en 64 para todos los conjuntos de datos de documentos generales y 256 para el conjunto de datos de código. En producción, hemos observado que una elección óptima para N podría estar entre 32 y 1024, dependiendo de las características del conjunto de datos. Si N es demasiado bajo, la recuperación del sistema de recuperación en el mejor de los casos será escasa. Aumentar N generalmente no afecta a la recuperación, pero, por supuesto, supone un coste adicional de inferencia o latencia en el sistema.
En todas las pruebas utilizamos las incrustaciones text-embedding-3-large de OpenAI para la búsqueda semántica. Como línea de base, incluimos el método de probabilidad de consulta (QLM) propuesto en [Zhuang et al.].
Resultados: Tasa de aciertos @ K = 8
| Modelo | Avg | SQuAD | TriviaQA | NCS | TrailheadQA |
| SFR LlamaRank | 92,9% | 99,3% | 92,0% | 81,8% | 98,6% |
| Cohere Rerank V3 | 91,2% | 98,6% | 92,6% | 74,9% | 98,6% |
| Mistral-7B QLM | 83,3% | 87,3% | 88,0% | 60,1% | 97,7% |
| Sólo bodas | 73,2% | 93,2% | 88,3% | 18,2% | 93,2% |
Ventajas clave de LlamaRank
- Escalabilidad horizontal / Baja latencia: LlamaRank puede clasificar 4 documentos en un único H100 en 200 ms con vLLM. Con dos nodos de servicio, podemos clasificar todos los N=64 documentos en <200ms, en comparación con ~3,13 segundos con la API sin servidor de Cohere.
- Rendimiento superior en el dominio del código: LlamaRank muestra una marcada mejora para la búsqueda de código en comparación con otros rerankers.
- Mayor tamaño de documento: LlamaRank admite un tamaño máximo de documento/pedazo de 8k, en comparación con los 4k de Cohere.
- Calibración lineal de puntuación: A diferencia de Cohere, LlamaRank produce puntuaciones lineales & calibradas en todos los pares (doc, query), lo que facilita la interpretación de las puntuaciones de relevancia:
- > 0,9 – Altamente relevante
- 0,8 ~ 0,7 – Relevante
- 0,6 ~ 0,5 – Algo relevante
- 0,4 ~ 0,3 – Marginalmente relevante.4 ~ 0.3 – Marginalmente Relevante
- 0.2 ~ 0.1 – Ligeramente Relevante
- ~ 0.0 – Irrelevante
Consideraciones
Aunque LlamaRank ofrece numerosas ventajas, hay algunas consideraciones a tener en cuenta, especialmente en lo que respecta al tamaño del modelo. Como reranker de parámetros 8B, está en el límite superior en términos de tamaño. Para un modelo de reranking, quizá lo ideal sería algo en el rango de 1~4B parámetros. El trabajo futuro puede centrarse en cómo reducir este modelo sin sacrificar la calidad.
Conclusión
LlamaRank es un importante paso adelante en la tecnología de reordenación. Es una herramienta versátil y potente para una amplia gama de tareas de clasificación de documentos y casos de uso de GAR. Estamos impacientes por ver cómo la comunidad aprovechará y desarrollará las capacidades de LlamaRank en el futuro.
¡Permanezca atento a más actualizaciones y mejoras!
Contribuidores técnicos: Antonio A. Ginart, Naveen Kodali, Jesse Vig, Shafiq Joty, Caiming Xiong, Silvio Savarese, John R. Emmons
¡Y un agradecimiento especial a Donna Tran y a todo nuestro equipo de anotación de datos RLHF!
LamaRank es una herramienta de gran utilidad para la comunidad científica