TLDR
El aprendizaje a partir de las preferencias humanas, concretamente el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF), ha sido un componente reciente clave en el desarrollo de grandes modelos lingüísticos como ChatGPT o Llama2. Hasta hace poco, el impacto del entrenamiento a partir de la retroalimentación humana en los modelos texto-imagen era mucho más limitado. En este trabajo, Diffusion-DPO, aportamos el beneficio del aprendizaje a partir de la retroalimentación humana a los modelos de difusión, dando como resultado un modelo generativo de texto-a-imagen de última generación. Esto cierra la brecha entre la familia StableDiffusion de modelos de código abierto y modelos cerrados como Midjourney v5 (el más actual en el momento de este proyecto) y abre la puerta a una nueva generación de modelos alineados de texto-a-imagen.
En resumen:
- Adaptamos el método de entrenamiento Direct Preference Optimization (DPO) a modelos texto-imagen
- Los modelos StableDiffusion-XL ajustados mediante DPO superan con creces su inicialización y son comparables a modelos de código cerrado como Midjourney y Meta’s Emu
- Implementaciones públicas del código de entrenamiento y de los modelos resultantes
Introducción
La historia de la alineación (i.la historia de la alineación (es decir, la alineación con los objetivos/preferencias/ética humanos) en los grandes modelos lingüísticos (LLM) es muy diferente de la alineación en los modelos de texto a imagen (T2I). Mientras que los LLM actuales más potentes, como GPT4, Bard y Llama2, citan específicamente la alineación mediante RLHF como un componente clave de sus preferencias de entrenamiento, los modelos T2I de última generación se entrenan principalmente mediante un único y sencillo objetivo: aprender a denotar imágenes. En algunos casos, como en la familia de modelos StableDiffusion, se utiliza una segunda fase de aprendizaje para eliminar el ruido de las imágenes visualmente atractivas con el fin de inclinar el modelo hacia generaciones de «mayor valor estético». Aunque útil, se trata de un marcado contraste entre los LLM y los modelos T2I. El campo de los primeros tiene muchas recetas para incorporar la retroalimentación humana en sus modelos con enormes beneficios, mientras que el segundo tiene en gran medida enfoques justificados empíricamente o ad hoc.
Método: Difusión-DPO
Una de las diferencias clave en la generación de difusión (T2I) respecto a la generación de lenguaje es cuál es la unidad incremental de generación. En los LLM es un token único (palabra, palabra-parte u otro trozo de texto) que, en última instancia, formará parte de la generación final. En los modelos de difusión, cada decisión incremental del modelo dirige una generación ruidosa hacia una versión limpia desenotizada (para más información sobre los modelos de difusión, véase nuestro blog sobre trabajos anteriores EDICT). Esto significa que puede haber muchos caminos hacia la misma imagen, lo que cambia el significado y la importancia de los pasos secuenciales de difusión.
Para considerar cómo aplicar RLHF a los modelos de difusión, recurrimos a un reciente desarrollo en el ajuste de preferencias para LLMs llamado Optimización Directa de Preferencias (DPO). DPO permite directamente el aprendizaje de un modelo para convertirse en «óptimo» con respecto a un conjunto de datos de las preferencias humanas que simplifica enormemente la tubería RLHF. Se trata de un marco mucho más sencillo que los métodos RLHF tradicionales, que requieren el aprendizaje de un modelo de «recompensa» para evaluar y criticar los resultados de los modelos generativos. El objetivo de la OPD se reduce a un criterio sencillo: ajustar el modelo para que sea más probable que produzca los datos preferidos y menos probable que produzca datos no preferidos.
La clave matemática detrás de Diffusion-DPO es formular qué significa «más probable» para los modelos de difusión. La conclusión (después de un poco de matemática pesada) resulta ser bastante simple: los modelos de difusión están entrenados para eliminar el ruido de las imágenes y si le das a un modelo de difusión una imagen ruidosa para eliminar el ruido, la «probabilidad» de la imagen limpia se escala con la calidad de la estimación de eliminación de ruido que hizo tu modelo. En otras palabras, el objetivo de la Difusión-DPO es ajustar el modelo para que sea mejor en la eliminación de ruido de los datos preferidos y relativamente peor en la eliminación de ruido de los datos no preferidos.
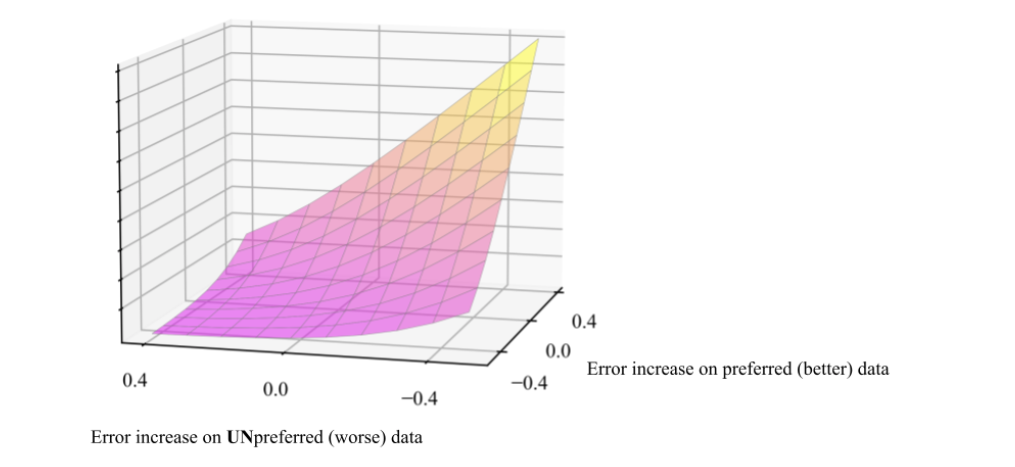
El aumento/disminución del error (mejorando/empeorando) se mide por el rendimiento relativo a un modelo de «referencia» o inicialización. En nuestros experimentos utilizamos principalmente StableDiffusion-XL-1.0, nos referiremos a este modelo específico como «SDXL». Usamos SDXL como punto de partida y lo entrenamos en el conjunto de datos Pick-a-Pic, que consiste en pares de preferencias recogidas entre dos imágenes generadas a partir del mismo pie de foto.
Results
En primer lugar, comparamos visualmente las generaciones de nuestro modelo SDXL ajustado a DPO (DPO-SDXL) con el SDXL original. Vemos que DPO-SDXL es más fiel a la indicación dada y produce imágenes de gran calidad que son muy agradables para los humanos, en otras palabras, ¡el modelo se ha alineado con nuestras preferencias! Tenga en cuenta que las preferencias no son universales, pero parece que el amor por las imágenes detalladas y emocionantes es una preferencia común compartida por una amplia franja de usuarios.

Recogemos 5 respuestas para cada comparación y elegimos el voto mayoritario como decisión colectiva.

Vemos que DPO-SDXL mejora significativamente a SDXL, ganando aproximadamente ⅔ de las veces.
Comparación con los modelos de código cerrado más avanzados
Aunque nuestros resultados en las pruebas académicas demuestran la eficacia de alinear los modelos de difusión con las preferencias de los usuarios, también queremos entender si el proceso de alineación ayuda a cerrar la brecha con los potentes modelos de código cerrado. Modelos de código cerrado como Midjourney y Meta’s Emu han demostrado ser capaces de generar imágenes significativamente mejores que las alternativas de código abierto. Ahora exploramos si la SDXL ajustada a la OPD es competitiva con Midjourney y Emu. Dado que sus conjuntos de datos de entrenamiento y (en el caso de Midjourney) las recetas de entrenamiento no están disponibles, estas no son comparaciones de manzanas con manzanas, sino más bien un esfuerzo para documentar el rendimiento relativo de los diferentes modelos.
Midjourney es un sistema de generación de texto a imagen de código cerrado muy potente y popular conocido por la alta calidad de sus generaciones. Evaluamos cómo SDXL y SDXL-DPO se comparan con Midjourney en términos de preferencias del usuario. Comparamos estos modelos con Midjourney 5.1 (el último modelo disponible en el momento de nuestros experimentos) utilizando una colección de 346 imágenes generadas por Midjourney alojadas en Kaggle. Generamos imágenes con SDXL y SDXL-DPO utilizando las mismas indicaciones y pedimos a los crowdworkers que elijan una imagen entre Midjourney y SDXL en preferencia por pares, formulando la siguiente pregunta: «¿Qué imagen prefieres?«. Recogemos 5 respuestas para cada comparación y elegimos el voto mayoritario como la decisión colectiva.
Los usuarios prefieren Midjourney 5.1 a SDXL por un margen sustancial (58% a 42%), pero después de sintonizar SDXL con DPO, la preferencia de los usuarios por SDXL mejora significativamente – SDXL-DPO es seleccionado sobre Midjourney el 51% de las veces. Estos resultados indican que el ajuste DPO permite a un modelo de código abierto igualar el rendimiento de los potentes modelos de código cerrado Midjourney.
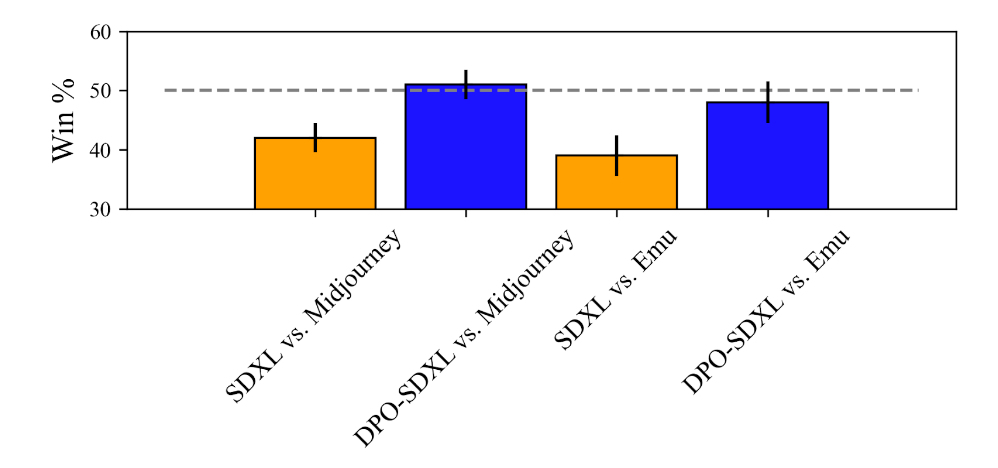
A continuación, comparamos SDXL y SDXL-DPO con Emu, un modelo reciente desarrollado y alojado por Meta. Comparamos los modelos utilizando un subconjunto de 200 Partiprompts seleccionados aleatoriamente (la interacción con el navegador es una forma lenta de recopilar datos) empleando el mismo protocolo de crowdsourcing utilizado para Midjourney. Emu es preferido a SDXL vainilla por un margen significativo (61% a 39%), reflejando los resultados reportados en el documento de Emu. Por el contrario, SDXL-DPO es capaz de reducir la brecha con Emu. Emu es preferido por un margen mucho más estrecho a SDXL-DPO (54% a 46%) y, de hecho, el punto de equilibrio cae dentro de la barra de error de 1 desviación estándar.
Estos resultados demuestran el poder del aprendizaje de preferencias en los modelos de difusión. A pesar de entrenarse en una configuración offline con un conjunto de datos limitado,
Diffusion-DPO cierra la brecha entre los modelos de código abierto y de código cerrado más avanzados.
Generación en tiempo real: Diffusion-DPO goes Turbo
Los modelos de difusión pueden acelerarse destilando su conocimiento a través de un proceso adicional que permite la generación de imágenes realistas con sólo unas pocas llamadas a funciones. El modelo preeminente de esta clase es SDXL Turbo, que genera imágenes en sólo 1-4 pasos. La OPD también puede beneficiar mucho a este tipo de modelos. Usando exactamente la misma pérdida de DPO (sólo modificando algunos de los ajustes para alinearlos con el entrenamiento original de SDXL Turbo) somos capaces de mejorar sustancialmente las generaciones de 4 pasos de SDXL Turbo.El desarrollo de este modelo está todavía en progreso, pero la versión temprana mostrada aquí gana el 55% de las comparaciones en PartiPrompts.
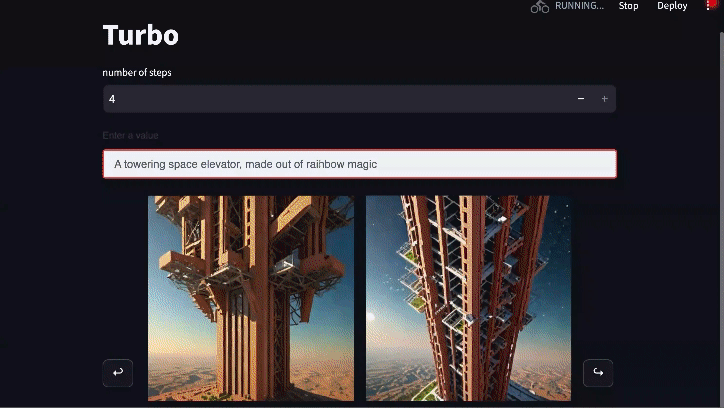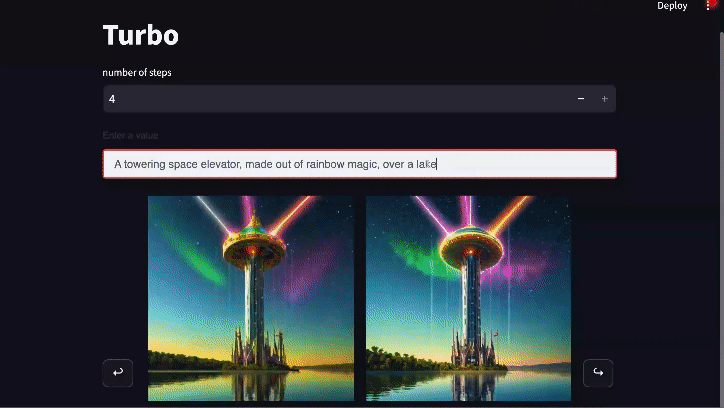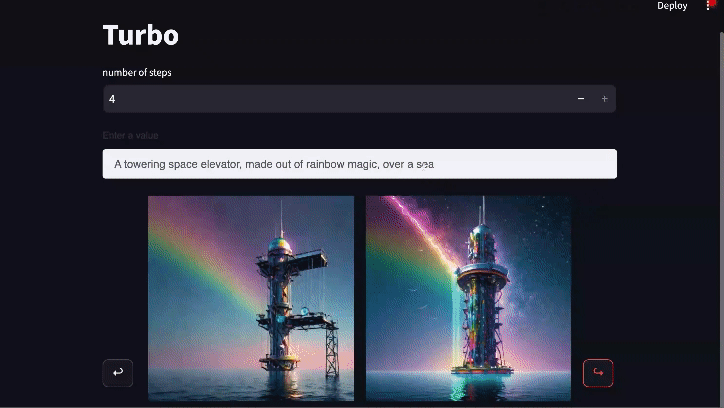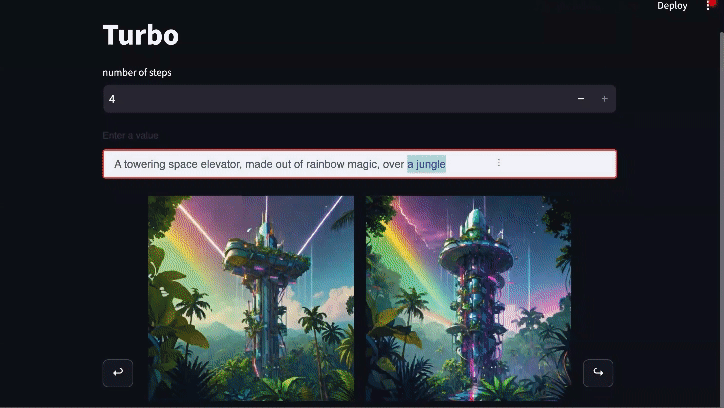
Enlace de vídeo para la versión completa del gif anterior (velocidad 2x respecto al original)
Áreas emergentes de mejora
Una de las quejas más comunes sobre las imágenes generadas por IA es la apariencia de las personas. Como humanos, las aberraciones en la apariencia humana renderizada realmente nos llaman la atención. Curiosamente, vemos que estas preferencias se reflejan en nuestro conjunto de datos de entrenamiento, lo que se traduce en una mejora sustancial en la generación de personas, como se muestra a continuación. Dado que estos cambios son bastante incidentales como parte de la alineación genérica, la mejora dirigida es un camino emocionante para el desarrollo futuro.

Generación a partir de diseños de color
La generación basada en trazos utilizando SDEdit es un interesante campo de pruebas de las tendencias aprendidas de nuestro modelo. En este caso, se utiliza un diseño de color (izquierda) como referencia para generar una imagen según las instrucciones Paisaje fantástico, tendencia en artstation (arriba) y Representación en alta resolución de una ciudad de ciencia ficción llena de color (abajo). DPO-SDXL genera imágenes visualmente mucho más emocionantes que el modelo de inicialización SDXL.
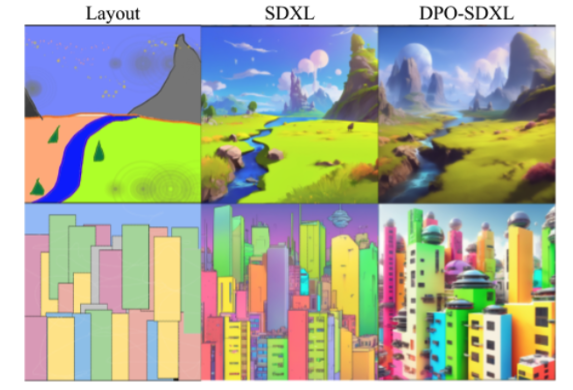
The bottom line
- Diffusion-DPO permite alinear los modelos de difusión con los objetivos/valores humanos
- Este proceso de entrenamiento cierra la brecha de rendimiento de StableDiffusion-XL-1.0 a frameworks de código cerrado como Midjourney v5 o Emu.
- Quejas comunes como la generación de personas emergen como mejoras cuando se entrena sobre preferencias humanas
Mirando hacia el futuro, hay muchos caminos por los que la optimización de preferencias en modelos de difusión seguirá. El trabajo presentado aquí se encuentra todavía prácticamente en una escala de prueba de concepto: se espera que ampliar la escala de entrenamiento pueda mejorar aún más los modelos. Además, hay muchas variedades de preferencia/retroalimentación que pueden utilizarse aquí. Aquí sólo hemos tratado las preferencias humanas genéricas, pero en nuestro artículo experimentamos que atributos como la fidelidad del texto o el atractivo visual pueden optimizarse de forma específica. Y eso sin tener en cuenta objetivos más específicos, como la personalización. RLHF ha sido un enorme y rápido crecimiento campo en modelos de lenguaje y estamos muy emocionados tanto para continuar el desarrollo de este tipo de enfoques de difusión y ver los trabajos de la comunidad de investigación más amplia también.
Los autores del artículo de investigación analizado en este blog son Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty y Nikhil Naik.
Más información
Modelos: Entrenado y liberado por Meihua Dang SDXL SD1.5
Código: Integrado en difusores: https://github.com/huggingface/diffusers/tree/main/examples/research_projects/diffusion_dpo
Paper: Arxiv