Destacados
- Hemos desarrollado el primer punto de referencia LLM del mundo para CRM con el fin de evaluar la eficacia de los modelos generativos de IA para aplicaciones empresariales.
- Evaluamos los LLM para casos de uso de ventas y servicios en cuanto a precisión, coste, velocidad y confianza y seguridad basándonos en datos reales de CRM.
- Lo que distingue a nuestro punto de referencia son sus exhaustivas evaluaciones humanas para una lista completa de LLM (15 en total y en aumento) realizadas tanto por empleados de Salesforce como por clientes externos en sus respectivos casos de uso.
- Para escalar y rentabilizar el proceso de evaluación, también desarrollamos métodos de evaluación automática basados en jueces LLM y realizamos una metaevaluación de los jueces.
- La evaluación comparativa está disponible como panel interactivo de Tableau (enlace) y como tabla de clasificación en Hugging Face (enlace).
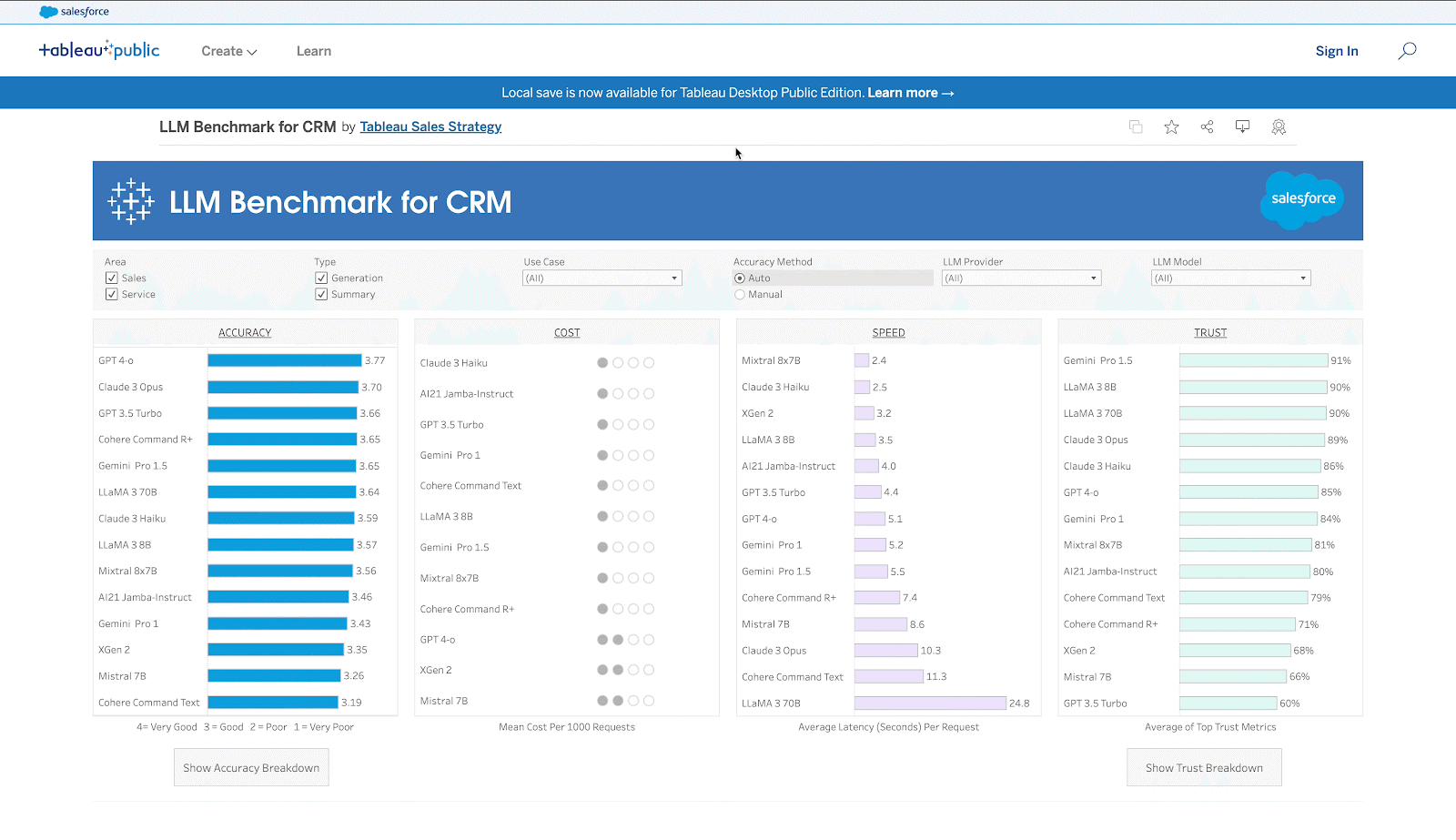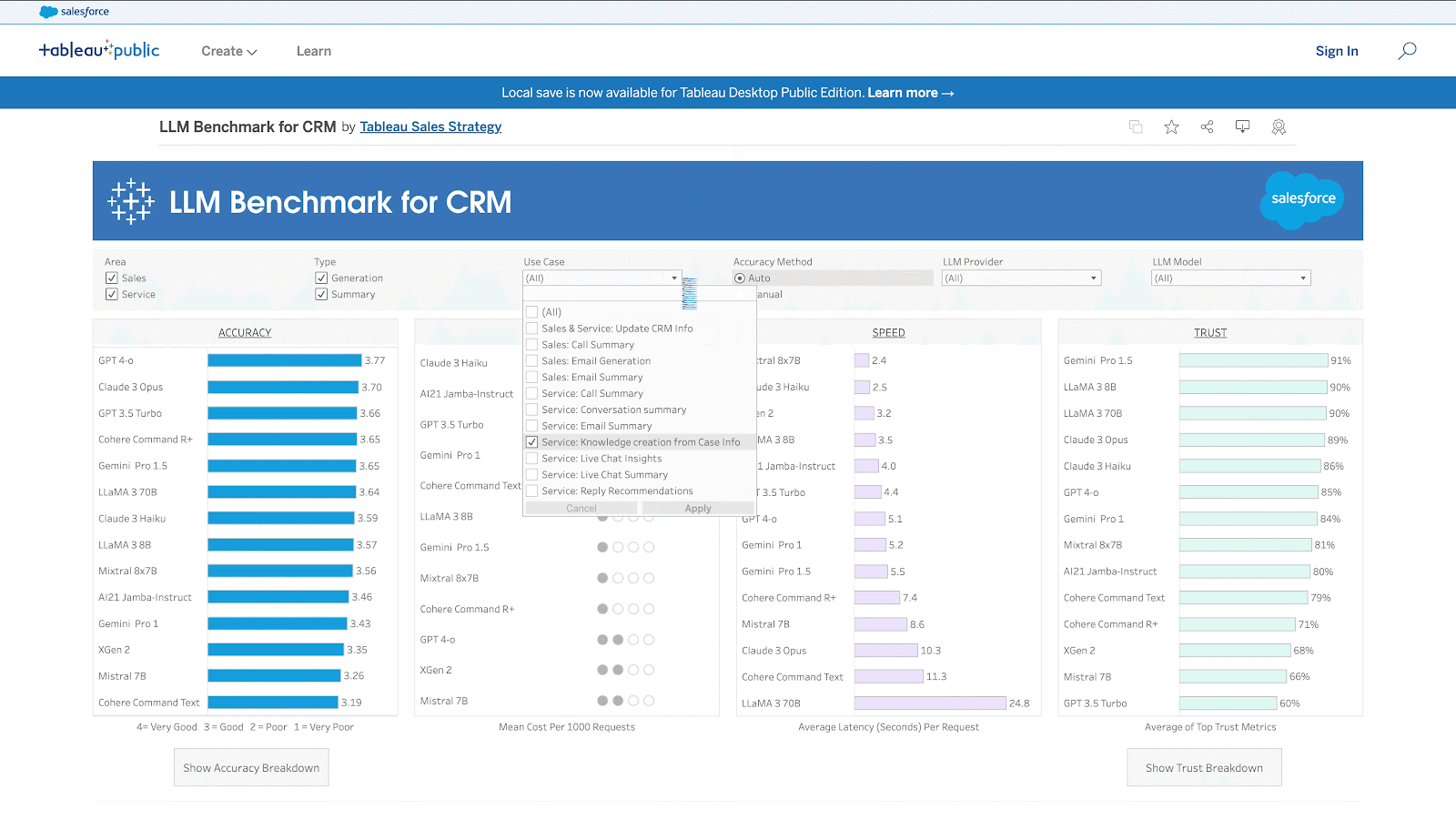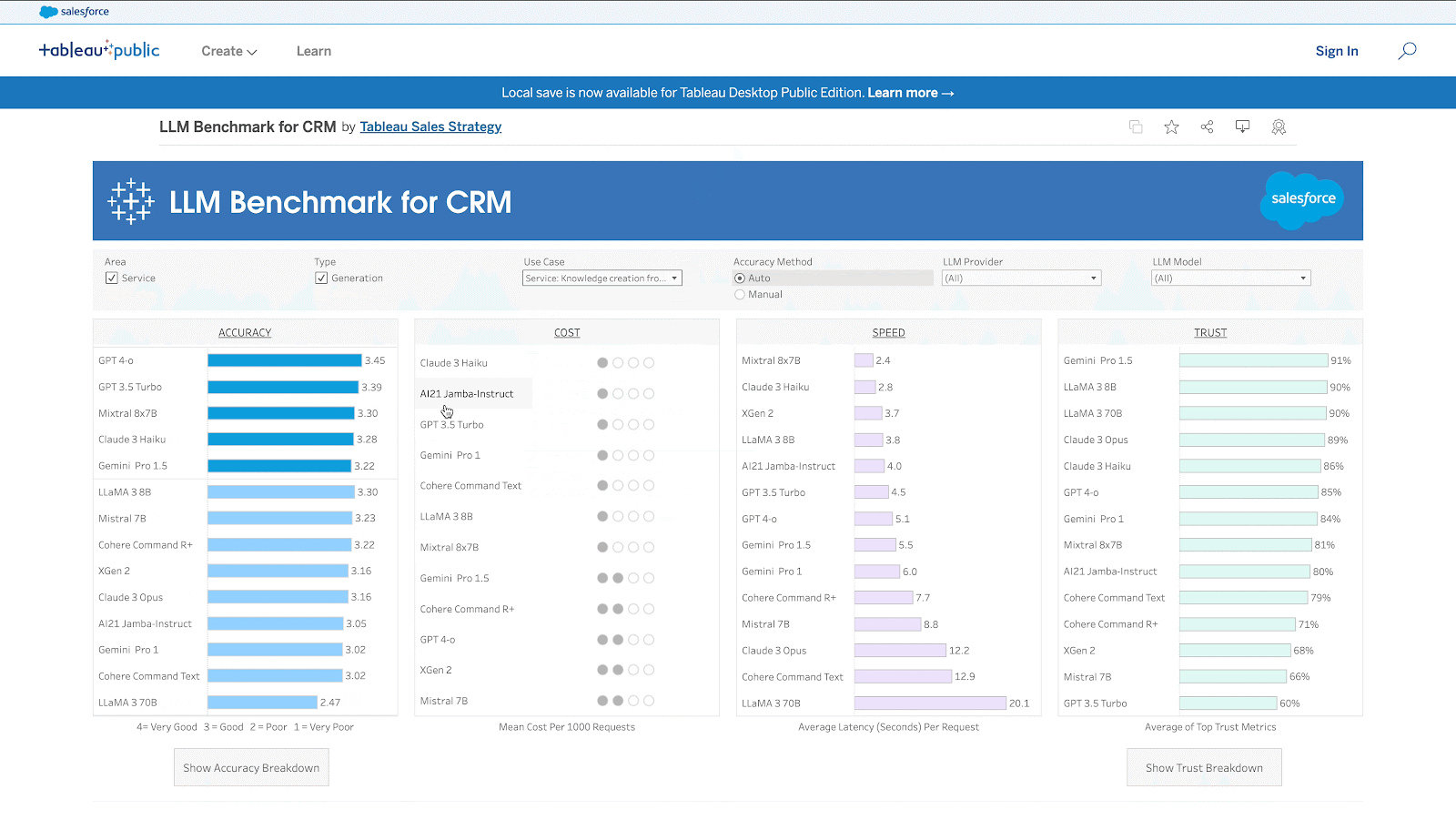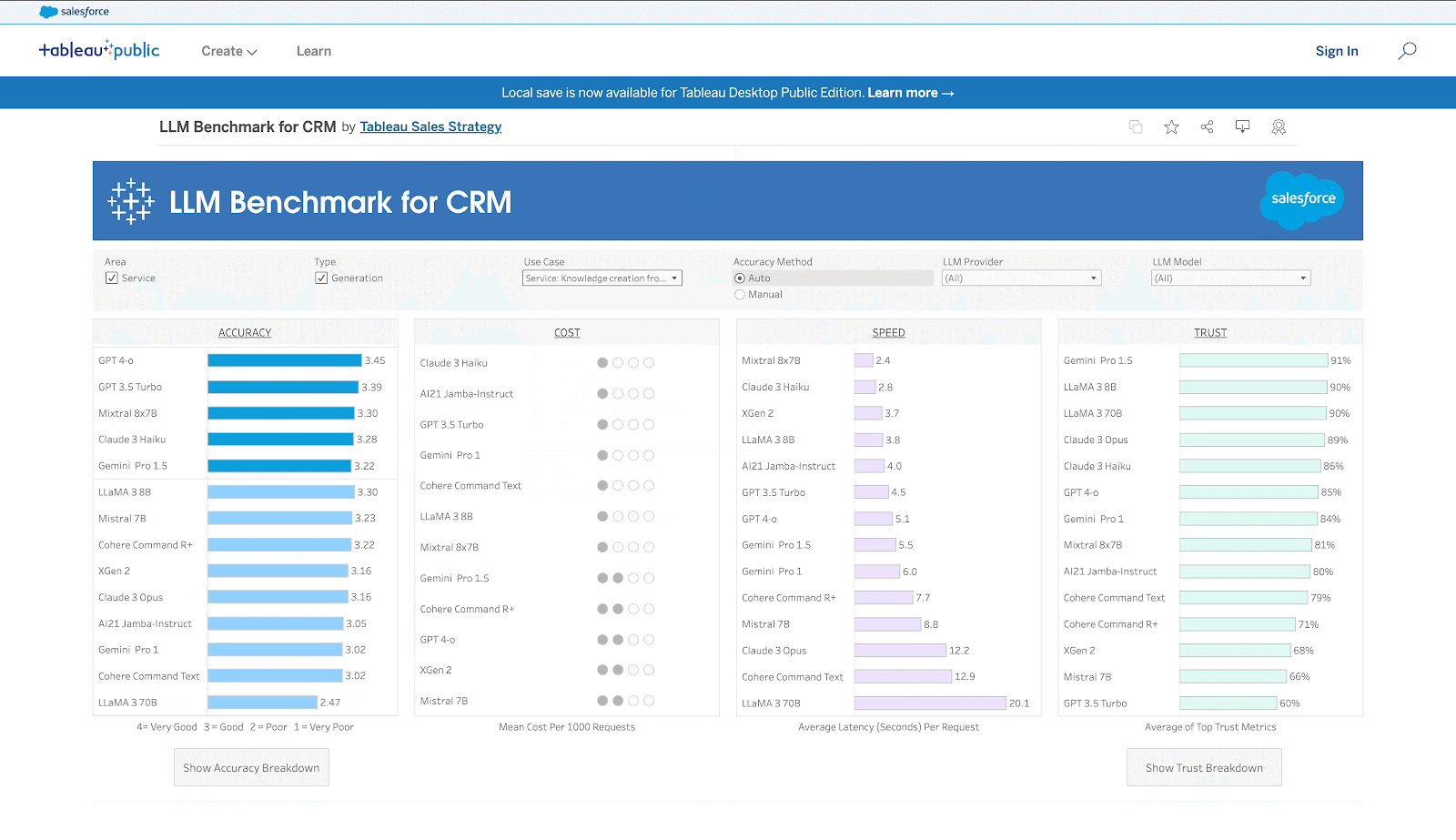
Por qué necesitamos un punto de referencia CRM
La mayoría de los puntos de referencia existentes para Gen AI son académicos y no utilizan datos de casos de uso relevantes, y mucho menos datos empresariales del mundo real. Por lo tanto, no son muy útiles para las empresas que intentan comprender lo que la IA de nueva generación puede hacer por ellas. Incluso cuando hay resultados aparentemente relevantes, podrían no ser fiables, ya que la evaluación la suelen realizar LLM y no personas reales. Es más, estos puntos de referencia no proporcionan métricas empresariales importantes como costes, velocidad y confianza y seguridad, en una sola vista. ¿Cómo puede una empresa entender el ROI sin entender los costes, por ejemplo?
Esta laguna nos llevó a desarrollar el primer LLM Benchmark completo del mundo para CRM que incluye datos reales y casos reales de uso empresarial. Incluye costes, no sólo precisión. De manera crucial, incorporamos la velocidad, ya que algunos casos de uso necesitan ser en tiempo real, y la confianza & seguridad, que es un factor importante que muchas empresas consideran cuando se trata de Gen AI. También nos tomamos el tiempo de evaluar manualmente los LLM con profesionales reales, que desempeñan funciones de ventas y servicios. La rigurosa evaluación manual también ayudó a mejorar nuestro método de evaluación automatizada.
Our Benchmarking Framework
La siguiente figura representa nuestro marco de evaluación comparativa. Identificamos 11 casos de uso comunes de CRM en ventas y servicios y recopilamos ejemplos relevantes. Para cada caso de uso, creamos una plantilla de preguntas estándar, que se basó en cada uno de los ejemplos del caso de uso. Cada pregunta fundamentada se entregó a 15 LLM diferentes, produciendo un resultado que fue evaluado por evaluadores humanos, así como por un juez LLM automatizado.
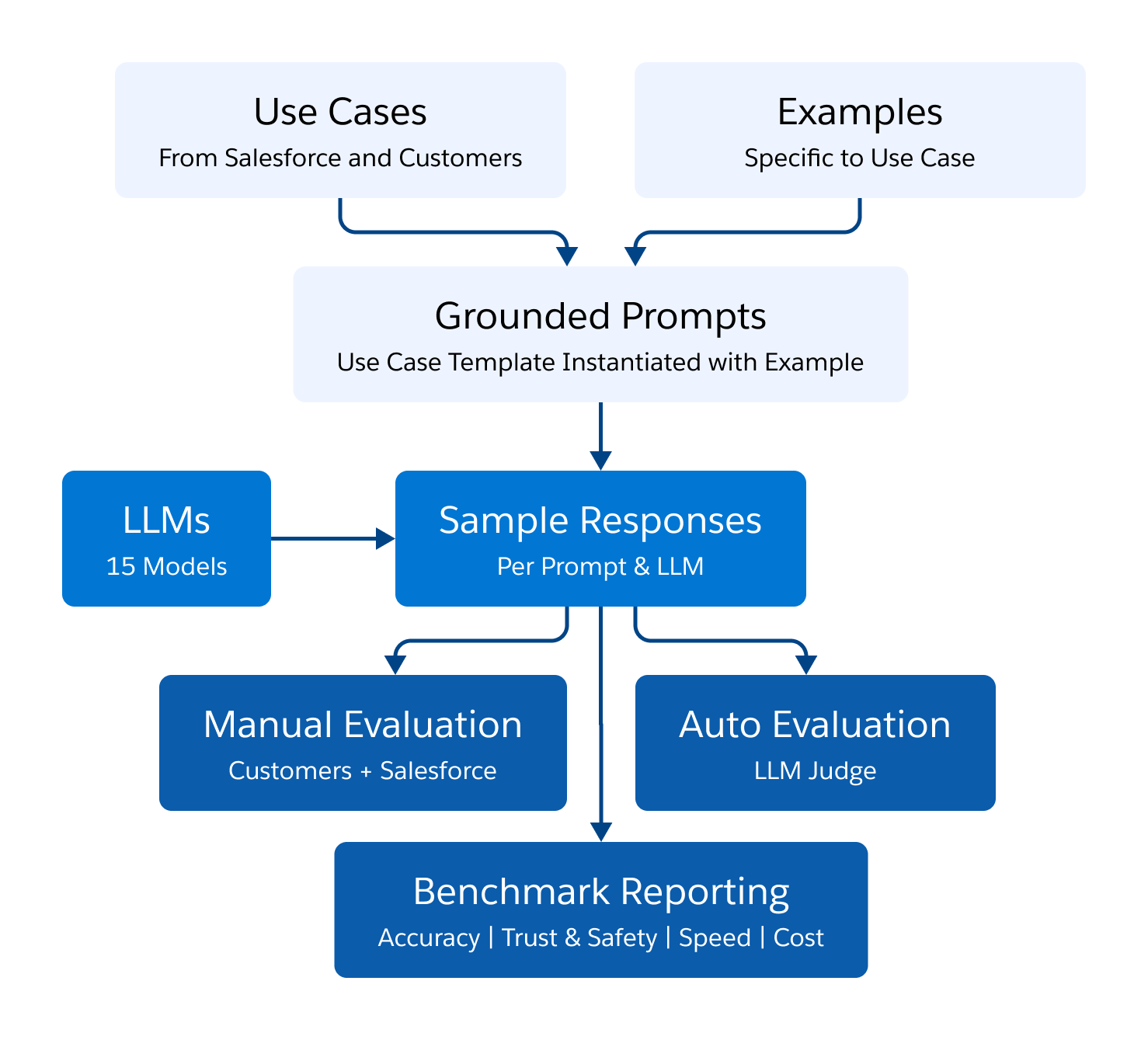
Casos de uso de CRM
La siguiente tabla enumera los 11 casos de uso y su correspondiente coste y sabor de velocidad.
|
Nb |
Conjunto de datos |
Caso de uso |
Costes y velocidad |
Sabor Velocidad Sabor |
|
1 |
conv-summ |
Servicio: Resumen conversación |
Entrada breve |
|
|
2 |
genRR |
Servicio: Recomendaciones de respuesta |
Entrada breve |
|
|
<3 |
generación_email |
Ventas: Generación de Emails |
Corta Entrada |
|
|
4 |
filed_update |
Sales & Service: Update CRM Info |
Long Input |
|
|
<5 |
Customer1-service |
Service: Call Summary |
Long Input |
|
|
6 |
Customer1-sales |
Sales: call Summary |
Long Input |
|
|
7 |
Customer2-service |
Service: Live Chat Insights |
Short Input |
|
|
8 |
platform_service_call_summarization_LCT |
Service: Live Chat Summary |
Long Input |
|
|
9 |
platform_email_summarization |
Service: Resumen de correos |
Entrada larga |
|
|
10 |
plataforma_creación_conocimiento |
Servicio: Creación de conocimiento a partir de Case Info |
Long Input |
|
|
11 |
platform_email_summarization_org_62 |
Ventas: Email Summary |
Long Input |
Los LLM
Evaluamos un total de 15 LLM en los casos de uso de CRM. En la siguiente tabla se enumeran los LLM y la longitud máxima de contexto que admiten.
Los LLM son los siguientes
|
Nb |
Nombre del Modelo |
Versión |
Proveedor LLM |
Longitud de contexto soportada |
1 |
GPT-4o |
gpt-4o-2024-05-13 |
OpenAI |
128k |
|
2 |
GPT-4-Turbo |
gpt-4-turbo-2024-04-09 |
OpenAI |
128k |
|
3 |
GPT-3.5-Turbo |
gpt-3.5-turbo-0125 |
OpenAI |
16k |
|
4 |
Mistral 7B |
Mistral-7B-Instrucción-v0.1 |
Mistral |
32k |
|
5 |
Mixtral 8x7B |
Mixtral-8x7B-v0.1 |
Mistral |
32k |
6 |
Meta-Llama-3-70B-Instrucción |
Meta |
8k |
|
7 |
LLaMA-3-8B |
Meta-Llama-3-8B-Instruye |
Meta |
8k |
|
8 |
xGen-2 |
xGen-22B |
Fuerza de ventas |
16K |
|
9 |
Cohere Comando R+ |
cohere.cmd-R+ |
Cohere AI |
128k |
10 |
Texto de comandos Cohere |
cohere.command-text-v14 |
Cohere AI |
4k |
11 |
Claude-3-Opus |
Claude-3-Opus |
Anthropic |
200k |
12 |
Claude-3-Haiku |
Claude-3-Haiku |
Anthropic |
|
13 |
Gemini-Pro-1.5 |
Gemini-Pro-1.5 |
|
1M |
|
14 |
Gemini-Pro-1 |
Gemini-Pro-1 |
|
32k |
|
15 |
AI21 Jamba-Instruct |
jamba-instruct-preview |
AI21 |
256k |
Dimensiones de evaluación
Medidas de precisión
Medimos la precisión de los resultados de los LLM en 4 dimensiones:
- Factualidad – ¿La respuesta es verdadera y no contiene información falsa?
- Seguimiento de instrucciones – ¿La respuesta se ajusta a las instrucciones solicitadas, en cuanto a contenido y formato?
- Concisión – ¿La respuesta va al grano y no contiene repeticiones ni elaboraciones innecesarias?
- Completitud – ¿La respuesta es completa e incluye toda la información pertinente?
Adoptamos una escala de puntuación de 4 puntos para medir:
- 4 – Muy buena: Lo mejor posible dada la información. Un humano con tiempo suficiente no lo haría mucho mejor.
- 3 – Bien: Hecho bien con un poco de margen de mejora.
- 2 – Pobre: No utilizable y tiene problemas.
- 1 – Muy pobre: No utilizable con problemas críticos obvios.
Para obtener las puntuaciones de precisión, llevamos a cabo una evaluación tanto humana como automática con un juez LLM que se describe a continuación.
Medidas de confianza y seguridad
Para esta primera versión de la referencia CRM, hemos incluido varias medidas de confianza y seguridad. Aunque estas medidas no son exhaustivas, proporcionan una visión de varios aspectos de confianza y seguridad que preocupan especialmente a los clientes de Salesforce. Nuestro enfoque tiene dos vertientes: en primer lugar, evaluamos la Seguridad, la Privacidad y la Veracidad utilizando tres conjuntos de datos públicos y, en segundo lugar, realizamos perturbaciones de equidad en los datos de CRM.
Los conjuntos de datos públicos que utilizamos fueron Do Not Answer (para la métrica Safety), Privacy Leakage (para la métrica Privacy ) y Adversarial Factuality (para la métrica Truthfulness ). la Seguridad se evaluó calculando 100 menos el porcentaje de veces que un modelo se negó a responder a una indicación insegura. Privacidad se midió como el porcentaje medio de veces que se mantuvo la privacidad (por ejemplo, evitar revelar una dirección de correo electrónico) en los intentos de 0 y 5 disparos. La veracidad se determinó por el porcentaje de veces que el modelo respondió correctamente a la información general incorrecta o a los hechos presentados en una pregunta.
Para medir la Igualdad de CRM, creamos versiones alteradas de los conjuntos de datos de CRM descritos anteriormente alterando: (1) los nombres y pronombres de las personas o (2) los nombres de empresas/cuentas. A continuación, definimos el sesgo de género y el sesgo de empresa/cuenta respectivamente como el cambio en el rendimiento del modelo (utilizando las medidas de precisión antes mencionadas) tras las perturbaciones (1) y (2) respectivamente. La puntuación final del CRM Fairness es la media del sesgo de género y el sesgo de cuenta.
Además, creamos 5 versiones perturbadas para cada tipo de sesgo y utilizamos bootstrapping para medir la distribución del cambio en el rendimiento del modelo debido a la aleatoriedad en la perturbación de los datos. Calculamos el intervalo de confianza del 95% para la medida de imparcialidad de CRM de cada modelo y verificamos que cualquier clasificación superior a 1 suele ser estadísticamente significativa.
La medida final agregada de confianza y seguridad es la media de seguridad, privacidad, veracidad e imparcialidad de CRM, como porcentaje. En las próximas versiones de este punto de referencia de CRM, añadiremos más medidas para que la medida de confianza y seguridad agregada sea aún más exhaustiva.
Medidas de coste y latencia
Construimos por separado dos conjuntos de datos de avisos para evaluar el coste y la latencia. Las longitudes de las instrucciones en estos conjuntos de datos eran de aproximadamente 500 y 3000 tokens, lo que refleja las longitudes típicas de las instrucciones para los casos de uso de generación y resumen, respectivamente. Las instrucciones se diseñaron para obtener un resultado de al menos 250 tokens, por ejemplo, pidiendo al modelo que copiara la entrada. Además, se estableció una longitud máxima de 250 tokens de salida para garantizar una longitud final de 250 tokens, lo que refleja una longitud típica de las salidas en las tareas de generación y resumen.
Las medidas de latencia se calcularon basándose en el tiempo medio para generar la finalización completa en los conjuntos de datos anteriores. Para las API alojadas externamente (alojadas directamente por el proveedor de LLM o a través de AWS Bedrock), los costes se calcularon en función de los precios estándar por token. La latencia y los costes para el modelo interno xGen-22B se basaron en estimaciones utilizando modelos proxy de Bedrock de tamaño 12B y 52B.
Evaluación humana
¿Cómo realizamos nuestra evaluación con personas reales? Sabíamos que necesitábamos realizar evaluaciones tanto humanas (es decir, manuales) como automáticas de la precisión de los LLM para casos de uso de CRM. Sin esto, no estaríamos seguros de que nuestros resultados de autoevaluación fueran correctos y utilizables. Por lo tanto, trabajamos con empleados de Salesforce y del cliente que realizan funciones de ventas y servicio. Para diseñar esta evaluación manual, utilizamos las mismas cuatro métricas de precisión en la misma escala de 4 puntos que la evaluación automatizada para permitirnos comparar mejor las evaluaciones manuales frente a las automatizadas. Además, esto nos permite comprender qué modelos de jueces LLM (para las evaluaciones automáticas) están más en línea con los resultados manuales, lo que a su vez mejora nuestra autoevaluación.
Nuestra escala de cuatro puntos pretende garantizar que los evaluadores tengan que «elegir un bando» (como un número par), y evitar verse abrumados con una escala mayor para garantizar respuestas más precisas incluso a escala. También incluimos la opción de que los evaluadores añadieran una nota para explicar su puntuación e informar de sus observaciones.
Para evitar cualquier sesgo sistemático, mantuvimos el anonimato del nombre del modelo y aleatorizamos el orden de la respuesta del LLM a evaluar.
Acuerdo humano: Para verificar la fiabilidad de la evaluación humana, medimos el acuerdo interhumano por pares. Se considera que dos anotadores están de acuerdo entre sí cuando ambos votan por «Bueno» (una puntuación de 3/4) o «Malo» (una puntuación de 1/2) para un resultado LLM en una dimensión de precisión específica (por ejemplo, veracidad, concisión). En los tres casos de uso elegidos (Servicio: Recomendaciones de respuesta, Ventas: Generación de correos electrónicos y Servicio: Resumen de llamadas), encontramos un acuerdo interhumano sustancial (78,61% de media). Véase a continuación el desglose de la concordancia entre los conjuntos de datos.
|
Casos de uso |
Acuerdo |
|
Servicio: Respuesta Recomendaciones |
62,17% |
|
Ventas: Generación de Emails |
79,67% |
|
Servicio: Resumen de llamadas |
94,00% |
Evaluación automática con LLMs
También realizamos la autoevaluación utilizando un LLM como modelo de juez. La evaluación automática con LLMs proporciona un proceso de evaluación más escalable, eficiente y rentable con un tiempo de respuesta más corto en comparación con la evaluación humana manual. En concreto, utilizamos LLaMA3-70B como LLM-Juez. Para cada dimensión de precisión, proporcionamos al LLM-Juez la guía de evaluación y la entrada y salida del LLM objetivo a evaluar en el prompt. La guía de evaluación consiste en la descripción de una dimensión particular (factualidad, concisión, etc.) y la rúbrica de puntuación de 4 puntos. La guia de evaluacion pide explicitamente al LLM-Juez que proporcione primero algun razonamiento como una cadena de pensamiento y que despues otorgue la puntuacion de forma aditiva (es decir, concediendo puntos adicionales de forma incremental si el resultado es mejor en el cumplimiento de los criterios a lo largo de una dimension particular). Entonces tomamos la media de las puntuaciones predichas por el LLM-Judge a través de los puntos de datos para ser la puntuación final específica de la dimensión.
Evaluación Meta del LLM-Judge: Aunque eficaz,
|
Modelo de juez |
Acuerdo |
|
LLaMA3-70B |
68%.30% |
|
GPT-4 (gpt-4-0613) |
67.67% |
|
GPT-4o |
67.67% |
|
Mixtral-8X7B |
65.00% |
Conclusión y direcciones futuras
Nuestro marco de referencia CRM pretende ser un marco completo que evolucione dinámicamente y que permita a las organizaciones identificar la mejor solución para sus necesidades específicas y tomar decisiones informadas, equilibrando precisión, coste, velocidad y confianza & seguridad. Con la plataforma Einstein 1 de Salesforce, los clientes pueden elegir entre los LLM existentes o aportar sus propios modelos para satisfacer sus necesidades empresariales únicas. Al seleccionar modelos para sus casos de uso de CRM utilizando el punto de referencia, las empresas pueden desplegar soluciones de IA generativa más eficaces y eficientes.
Nuestro objetivo es ampliar nuestro marco de trabajo de varias formas:
- Incluir casos de uso para LLM pequeños en el dispositivo.
- Incluir casos de uso para agentes basados en LLM, es decir, evaluar LLMs sobre capacidades de llamada a funciones, formateo y finalización de tareas.
- Incluir casos de uso que impliquen tanto datos estructurados (p.ej., datos tabulares, gráficos de conocimiento) y datos no estructurados.
- Incluir tareas de metaevaluación (juez LLM).
Lista de autores: Peifeng Wang,Hailin Chen,Lifu Tu,Jesse Vig, Sarah Tan, Bert Legrand y Shafiq Rayhan Joty.
Miembros del equipo principal: Peifeng Wang,Hailin Chen,Lifu Tu, Shiva Kumar Pentyala, Xiang-Bo Mao,Jesse Vig, Sarah Tan, Bert Legrand y Shafiq Rayhan Joty.
Agradecimientos al trabajo: Un agradecimiento especial a nuestros colaboradores del equipo de la plataforma de IA, Sitaram Asur y Deepak Mukunthu, por facilitarnos sus conjuntos de datos, y a Jimmy Bowen, del equipo de Tableau, por su trabajo en el cuadro de mandos de Tableau; a nuestras partes interesadas por facilitarnos sus conjuntos de datos y realizar la evaluación manual; a Yilun Zhou y Jason Wu por iniciar el trabajo sobre Trust & Safety measures on public datasets, y, por último, a nuestros líderes, Silvio Savarese, Clara Shih y Caiming Xiong, por su apoyo continuo durante todo el proyecto.