TLDR
Entrenamos una serie de 7B LLMs llamados XGen-7B con atención densa estándar en hasta 8K de longitud de secuencia para hasta 1.5T tokens. También afinamos los modelos en datos de instrucción de dominio público. Los principales resultados son:
- En pruebas estándar de PNL, XGen consigue resultados comparables o mejores que los LLM de código abierto más avanzados (por ejemplo, MPT, Falcon, LLaMA, Redpajama, OpenLLaMA) de tamaño de modelo similar.
- Nuestra evaluación específica sobre modelos de secuencias largas muestra los beneficios de nuestros modelos 8K-seq sobre los modelos 2K- y 4K-seq.
- XGen-7B archiva resultados igualmente sólidos tanto en texto (por ejemplo, MMLU, QA) como en tareas de código (HumanEval).
- Coste de formación de 150.000 dólares en tokens de 1T según los precios de Google Cloud para TPU-v4.
Por escrito: https://arxiv.org/abs/2309.03450
Codebase: https://github.com/salesforce/xGen
Model Checkpoint: https://huggingface.co/Salesforce/xgen-7b-8k-base
Por qué XGen-7B con 8K de longitud de secuencia
A medida que los LLM se hacen omnipresentes, sus aplicaciones a secuencias largas han sido un punto clave, especialmente para aplicaciones como el resumen de texto (potencialmente intercalado con otras fuentes de datos como tablas e imágenes), la escritura de código y la predicción de secuencias de proteínas, que requieren que el modelo considere eficazmente las dependencias estructurales de larga distancia. Un contexto amplio permite a un LLM preentrenado examinar datos de clientes (por ejemplo, documentos que el LLM no utilizó en el entrenamiento) y responde a consultas útiles de búsqueda de información.
Aún así, la mayoría de los LLM de código abierto (por ejemplo, LLaMA, MPT, Falcon) han sido entrenados con un máximo de 2K tokens de longitud de secuencia, lo que supone una limitación clave en el modelado de secuencias largas. Aún no se han evaluado soluciones de tiempo de inferencia como ALiBi para modelos más grandes (por ejemplo, MPT-7b-StoryWriter-65k+). Trabajos recientes sobre el escalado de modelos han demostrado que, para un presupuesto de computación determinado, los mejores resultados no se obtienen necesariamente con los modelos más grandes, sino con modelos más pequeños entrenados con más datos (medidos por el número de tokens). Por lo general, también se prefiere un modelo más pequeño por la eficacia de la inferencia durante el servicio, incluido el servicio en el dispositivo. En vista de ello, entrenamos una serie de LLM de 7B denominados XGen con atención densa estándar en secuencias de hasta 8K de longitud para un máximo de 1,5T tokens. También afinamos los modelos XGen en datos de instrucción de dominio público, creando sus homólogos afinados por instrucción (XGen-7B-inst).
|
Modelo |
Descripción |
|
|
XGen-7B-4K-base |
Entrenamos para 800B tokens con una longitud de secuencia de 2k tokens primero, luego para otros 400B tokens (total 1.2T tokens) con 4k. Liberado bajo Apache-2.0. |
|
|
XGen-7B-8K-base |
Inicializado con XGen-7B-4K-base y entrenado para 300B tokens más (total 1.5T tokens) con 8K de longitud de secuencia. Liberado bajo Apache-2.0. |
|
|
XGen-7B-{4K,8K}-inst |
XGen-7B-{4K,8K}-inst |
Supervised fine tuned on public domain instructional data including databricks-dolly-15k, oasst1, Baize and GPT-related datasets. Publicado únicamente con fines de investigación. |
Datos de pre-entrenamiento
Empleamos una estrategia de entrenamiento en dos etapas, en la que cada etapa utiliza una mezcla de datos diferente.
Primera etapa (1,37T tokens)
|
Nombre del conjunto de datos |
Número efectivo de fichas (B) |
Muestreo prop. (%) |
|||||||
|
Datos en lenguaje natural |
1309,99 |
95,31 |
|||||||
|
Datos del código |
64,53 |
4,69 |
|||||||
|
Total |
1374,52 |
100 |
|||||||
|
Nombre del conjunto de datos |
Número de fichas utilizadas (B) |
Prop. de muestreo. (%) |
|
Datos de la fase 1 |
55 |
50% |
|
BigCode Starcoder |
55 |
50% |
Usamos tiktoken de OpenAI para tokenizar nuestros datos. Añadimos tokens adicionales para espacios en blanco consecutivos y tabuladores, así como los tokens especiales descritos en el artículo de Starcoder.
Detalles del entrenamiento
Los modelos XGen-7b se entrenan con nuestra biblioteca interna JaxFormer, que facilita un entrenamiento eficiente de los LLM bajo un paralelismo tanto de datos como de modelos optimizado para el hardware TPU-v4. La receta de entrenamiento y la arquitectura del modelo siguen el modelo LLaMA, mientras que nosotros realizamos dos exploraciones adicionales. En primer lugar, investigamos la aparición de los denominados «picos de pérdida» [PaLM, loss spikes] durante el entrenamiento, es decir, la pérdida estalla de repente temporalmente mientras se desconoce la causa raíz de estos picos. En segundo lugar, los modelos XGen admiten secuencias de hasta 8.192 tokens (en lugar de los 2.048 habituales), por lo que introducimos el entrenamiento por etapas.
Picos de pérdida
A medida que los modelos se escalan a tamaños mayores, el propio entrenamiento es cada vez más sensible a las inestabilidades, que provocan un rendimiento deficiente del modelo si no se abordan con cuidado. En nuestra exploración, hemos reunido pruebas de varios factores que contribuyen individualmente a un entrenamiento inestable. Estos hallazgos preliminares incluyen «circuitos secuenciales sobre paralelos», «swish-GLU sobre GeLU», «RMS-Norm sobre Layer-norm». Específicamente, los circuitos paralelos ampliamente utilizados, que paralelizan el cómputo de autoatención y feed-forward como se adoptó en [GPT-J, PaLM, CodeGen] pueden afectar a la estabilidad del entrenamiento.

La figura anterior muestra la pérdida en términos de entropía cruzada a lo largo del tiempo siguiendo las conocidas leyes de escalado. Sorprendentemente, el entrenamiento no sufre inestabilidades ni picos de pérdida. Los dos picos de pérdida representados en la figura se esperan cuando se amplía la longitud de la secuencia, por ejemplo de 2k a 4k tokens, ya que el modelo necesita adaptarse a secuencias más largas.
Longitud de la secuencia
El entrenamiento con secuencias más largas es computacionalmente desproporcionadamente costoso ya que la complejidad de la autoatención es cuadrática, es decir, el proceso de entrenamiento es lento. Para mitigar la lentitud del entrenamiento, introducimos el entrenamiento por etapas con una longitud de secuencia creciente. Primero, se observan 800B tokens con una secuencia de 2k tokens, luego 400B tokens con 4k, finalmente, 300B tokens con 8k de longitud.
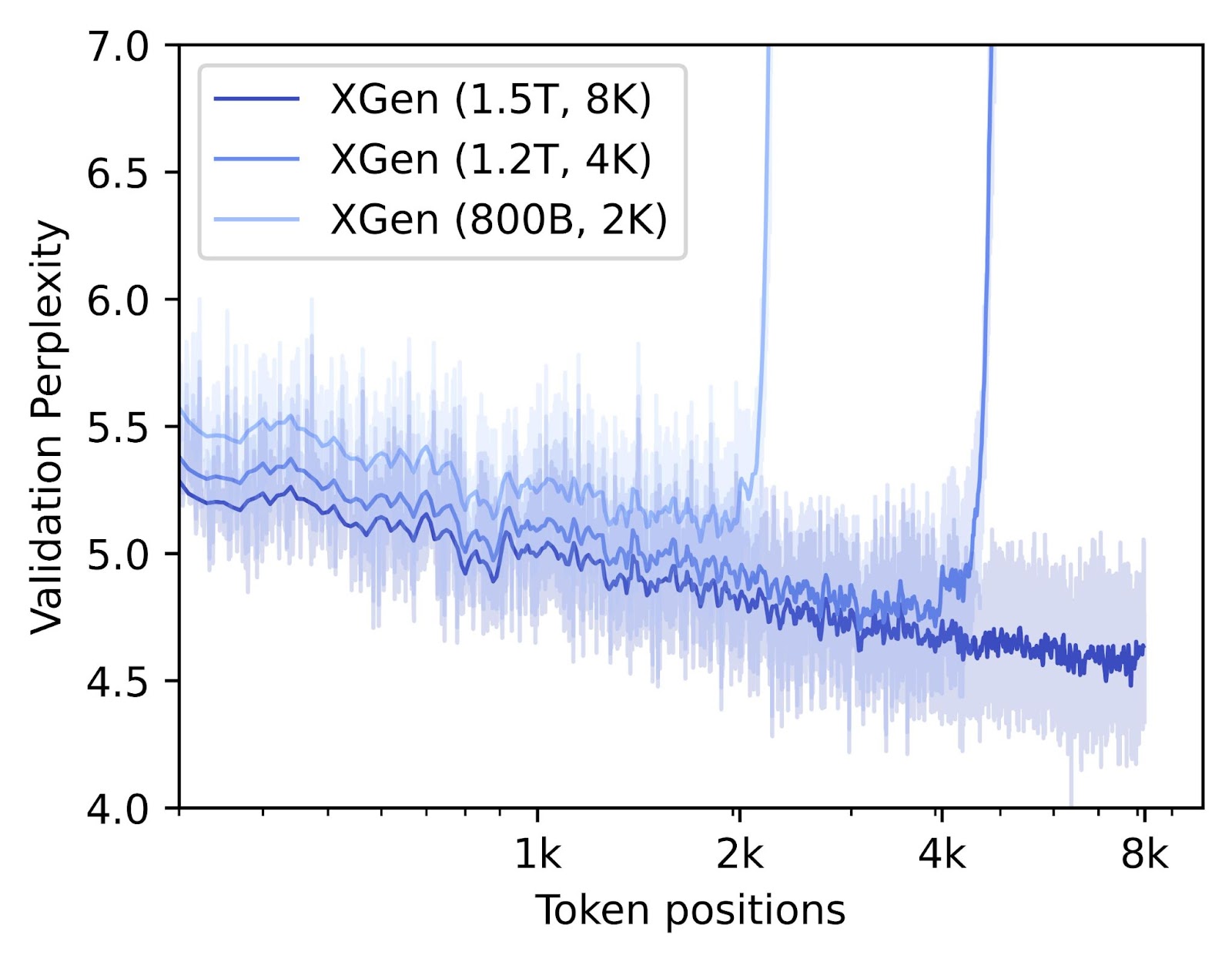
Verificamos la adaptación a secuencias más largas calculando la perplejidad media en cada posición de token en un conjunto de validación retenido que contiene documentos de 8k de longitud de secuencia o más. Si el modelo aprende a utilizar la secuencia completa, es de esperar que la perplejidad disminuya con la longitud de la secuencia, ya que los tokens anteriores contienen información para el siguiente token previsto. Es decir, para una frase larga, cuanto más contexto se proporcione en forma de palabras anteriores, más fácil será adivinar la palabra siguiente. La figura anterior muestra que XGen, en cada etapa, aprende a utilizar contextos más largos, de hasta 8k de longitud de secuencia.
Resultados en Benchmarks Estándar
(i) MMLU
En primer lugar consideramos el benchmark Measuring Massive Multitask Language Understanding (ver ejemplos aquí), que es más reciente que otros, por lo que podría decirse que es menos susceptible a la contaminación de datos, como se ha informado en estudios recientes (véase la página 32 del documento GPT-4 y una discusión relacionada aquí), y se ha utilizado sistemáticamente como punto de referencia de evaluación. Recientemente, sin embargo, se ha informado de incoherencias en la notificación de las puntuaciones MMLU, lo que dio lugar a clasificaciones erróneas en la tabla de clasificación Open LLM de Hugginface; de hecho, Huggingface tuvo que escribir más tarde un blog para aclararlo. En nuestro trabajo, seguimos el estándar MMLU original, que es coherente con los resultados publicados (es decir, en LLaMA).
Resultados del aprendizaje en contexto de 5 disparos MMLU: En primer lugar, mostramos los resultados en el escenario de evaluación original (y recomendado) de 5 disparos, en el que el LLM recibe 5 demostraciones. XGen consigue los mejores resultados en la mayoría de las categorías, también en media ponderada.
|
Modelos |
Humanidades |
STEM |
Ciencias Sociales |
Otros |
Promedio ponderado |
|
XGen-7b |
33.8 |
30,7 |
40,0 |
41.5 |
36,3 |
|
LLaMA-7b |
33.9 |
30,6 |
38,2 |
38,2 |
35.1 |
|
OpenLLaMA-7b |
28.1 |
28,5 |
31,2 |
32.8 |
29,9 |
|
Falcon-7b |
26,5 |
25.4 |
29.2 |
26.8 |
26.9 |
|
MPT-7b |
25.9 |
26,2 |
26,9 |
28,1 |
26.7 |
|
Redpajama-7b |
26.1 |
25.2 |
27.4 |
26.7 |
26,3 |
|
Cerebras-GPT-13b |
26,1 |
26.5 |
25,8 |
26,6 |
26.2 |
|
Dolly-v2-12b |
26.9 |
25,7 |
25,3 |
26,5 |
26.2 |
|
OPT-13b |
26,2 |
24,3 |
23.4 |
26 |
25.1 |
|
GPT-J-6b |
25,9 |
24.0 |
24.0 |
25.8 |
25.1 |
Resultados de 0 disparos de la MMMLU: En MMLU tiro cero, de forma similar vemos buenos resultados aunque la diferencia con LLaMA es generalmente menor aquí.
|
Modelos |
Humanidades |
Humanidades |
STEM |
Ciencias Sociales |
Otros |
Promedio ponderado |
|
XGen-7b |
31.4 |
27,8 |
32,1 |
37.2 |
32,1 |
|
|
LLaMA-7b |
32.3 |
27,1 |
31,3 |
36.8 |
32,0 |
|
|
OpenLLaMA-7b |
28.0 |
27,6 |
28,9 |
30,1 |
28.6 |
|
|
MPT-7b |
27,4 |
25.2 |
26.0 |
30.7 |
27.4 |
|
|
Redpajama-7b |
27.5 |
25.5 |
24,2 |
25,0 |
25.8 |
|
|
GPT-J-6b |
25,3 |
24.5 |
25,5 |
27,6 |
25.7 |
|
|
Dolly-v2-12b |
26.2 |
26.0 |
24.0 |
24.9 |
25.4 |
|
|
Cerebras-GPT-13b |
24,3 |
25.0 |
23.0 |
26.0 |
24.6 |
|
|
OPT-13b |
26,3 |
23,3 |
23.6 |
23.6 |
24.4 |
|
|
Falcon-7b |
24.8 |
21.7 |
24.0 |
24,4 |
23.9 |
(ii) General Zero-shot Results
A continuación, presentamos los resultados generales de zero-shot en tareas generales de PLN que implican razonamiento de sentido común y GC.
|
Modelos |
MMLU -wavg |
ARC_ch |
Hella Swag |
Winogrande |
TruthfulQA |
BoolQ |
PiQA |
OpenBookQA |
|
XGen-7b |
32.1 |
41.2 |
74.2 |
64,9 |
39,1 |
74.3 |
75,5 |
40,2 |
|
LLaMA-7b |
32.0 |
44,8 |
76,2 |
69.6 |
34 |
74,9 |
78,7 |
44.2 |
|
Falcon-7b |
23.9 |
43.4 |
76,4 |
67,2 |
34,3 |
73.8 |
79,4 |
44,0 |
MPT-7b |
27.4 |
41,7 |
76,1 |
68.6 |
33,4 |
74,1 |
79.1 |
41,8 |
|
OpenLLaMA-7b |
28.6 |
38,7 |
71,8 |
67.0 |
35,2 |
70,6 |
76.0 |
39.0 |
|
Redpajama-7b |
25.8 |
39.1 |
70.3 |
63.8 |
33,3 |
69,3 |
76.9 |
40,0 |
|
GPT-neox-20b |
24.5 |
41,1 |
70,5 |
66.1 |
31,4 |
64,9 |
76,7 |
38.8 |
|
OPT-13b |
24.4 |
35.8 |
69,9 |
64,7 |
33,9 |
65.0 |
75,7 |
39.8 |
|
GPT-J-6b |
25,7 |
36,3 |
66.2 |
64,5 |
36,0 |
65,4 |
75.4 |
38,2 |
|
Dolly-v2-12b |
25.4 |
39.6 |
70.8 |
61.8 |
34,4 |
56,3 |
75.4 |
39,2 |
|
Cerebras-GPT-13b |
24.6 |
32.4 |
59.4 |
60.8 |
39,2 |
61,1 |
73.5 |
35,8 |
|
StableLM-alpha-7b |
24.4 |
27,0 |
40,7 |
51.5 |
41,7 |
59,0 |
65,8 |
32.4 |
(iii) Resultados en la generación de código
Para evaluar la capacidad de generación de código de XGen a partir de instrucciones en lenguaje natural (docstrings), lo evaluamos en el conocido benchmark HumanEval. Fijamos la temperatura de muestreo en 0,2, p en 0,95 (para muestreo top-p), y num_samples_per_task (n) en 200. Informamos de los resultados estándar de cero disparos con la métrica pass@1.
|
Modelos |
pass@1 |
|
XGen-7b |
14.20 |
|
LLaMA-7b |
10,38 |
|
OpenLLaMA-7b |
0 (Los espacios en blanco consecutivos se tratan como uno, rompiendo la sintaxis de Python) |
|
Falcon-7b |
0 (no generó código con sentido) |
|
MPT-7b |
15.90 |
|
Redpajama-7b |
5.24 |
Resultados en tareas de generación de secuencias largas
Para seguir evaluando nuestro modelo XGen-7b 8k en comparación con las líneas de base que se limitan a entradas de 2k, pasamos a la generación de diálogos largos, el resumen de textos y la garantía de calidad. Todas estas tareas se benefician del procesamiento y la comprensión de un contexto largo para generar una respuesta correcta. Hay que tener en cuenta que, para estas tareas, la mayoría de los modelos base preentrenados no consiguieron generar una respuesta plausible debido a la dificultad de la tarea. Por tanto, utilizamos modelos ajustados a las instrucciones.
Diálogo
Para evaluar las capacidades de comprensión y resumen de diálogos largos, presentamos los resultados de tres tareas de resumen de diálogos: AMI, ForeverDreaming (FD) y TVMegaSite (TMS). La longitud media de las fuentes de estos conjuntos de datos es de aproximadamente 5.570, 6.466 y 7.653, respectivamente. Evaluamos específicamente muestras de menos de 8K de longitud utilizando varios modelos ajustados a las instrucciones. En particular, cuando no se aplicó el truncamiento de la entrada, tanto MPT-7b-inst como Alpaca-inst no obtuvieron buenos resultados en este escenario. Nuestro modelo (XGen-7B-inst) obtuvo las puntuaciones ROUGE más altas en todas las métricas.
|
Modelo |
AMI |
FD |
TMS |
R-1 |
R-2 |
R-L |
R-1 |
R-2 |
R-L |
R-1 |
R-2 |
R-L |
|
XGen-7b-inst |
31.34 |
8.25 |
17.00 |
29.34 |
5.39 |
16.43 |
26.39 |
3.94 |
13.71 |
|
Falcon-7b-inst |
14.89 |
1,97 |
9,28 |
18,90 |
1.80 |
9,37 |
18,90 |
1,80 |
9.37 |
|
MPT-7b-inst |
11,95 |
1,88 |
8.10 |
14.27 |
1.40 |
8.89 |
19.80 |
2,39 |
10,23 |
|
Alpaca-7b-inst |
9.69 |
1,77 |
6,43 |
16,26 |
1.56 |
10.66 |
12.26 |
1.15 |
7.30 |
Control de calidad de forma larga
A continuación, evaluamos nuestro XGen-7b-inst en una tarea de control de calidad de forma larga que hemos diseñado internamente. Pedimos a ChatGPT que genere preguntas a partir de (a) documentos largos de Wikipedia que abarcan cuatro dominios: Física, Ingeniería, Historia y Entretenimiento, y (b) resúmenes de estos documentos. A continuación, consultamos los LLM para generar respuestas a estas preguntas. Las respuestas suelen tener hasta 256 tokens. Utilizamos GPT-4 para evaluar la calidad de las respuestas en términos de coherencia (estructura y organización) y relevancia (relevancia de la respuesta generada para la pregunta y el documento contextual) en una escala de 0 a 3. A partir de los resultados que se muestran a continuación, vemos que nuestro modelo obtiene puntuaciones más altas en diferentes aspectos en comparación con las líneas de base consideradas.
|
Modelo |
Métricas |
||
|
Coherencia |
Relevancia |
Avg. Ratings |
|
|
XGen-7b-inst |
2,55 |
2,52 |
2.54 |
|
MPT-7b-inst |
2,5 |
2.45 |
2,48 |
|
Alpaca-7b-inst |
1.65 |
1,91 |
1.78 |
|
Falcon-7b-inst |
2,26 |
2.13 |
2,19 |
Resumen
Aquí evaluamos nuestro modelo en dos conjuntos de datos de resumen de texto incluidos en el SCROLLS Benchmark, a saber, QMSum y GovReport. Cubren dos ámbitos diferentes: conversaciones en reuniones e informes gubernamentales. Además, los datos de QMSum incluyen consultas específicas en lenguaje natural que indican al modelo los aspectos clave del documento fuente que deben incluirse en el resumen. Vemos que nuestro modelo XGen-7b supera a otras líneas de base en estas tareas.
|
Modelo |
QMSum |
InformesGov |
||||
|---|---|---|---|---|---|---|
|
R-1 |
R-2 |
R-L |
R-1 |
R-2 |
R-L |
|
|
XGen-7b-inst |
27.96 |
5,66 |
24.26 |
21.28 |
8.19 |
20.08 |
|
Falcon-7b-inst |
15.68 |
2,81 |
14,01 |
17.8 |
6,13 |
16,66 |
|
MPT-7b-inst |
21.75 |
4.38 |
19.29 |
18.11 |
6.96 |
17.11 |
|
Redpajama-7b-inst |
19.81 |
2.66 |
17.58 |
19.63 |
6,93 |
18,48 |
Como vemos resultados alentadores de nuestros modelos XGen-7b en estas tareas de secuencias largas, nos gustaría señalar que como estos modelos no están entrenados con los mismos datos de instrucción, no son estrictamente comparables.
Nota sobre Riesgos Potenciales
Por último, a pesar de nuestro esfuerzo por abordar los riesgos de sesgo, toxicidad y alucinaciones tanto en las etapas de pre-entrenamiento como de ajuste fino, al igual que otros LLMs, los modelos XGen-7b no están libres de dichas limitaciones. Esperamos que nuestra base de código de código abierto ayude a otros investigadores a comprender mejor estos retos y a mejorar estas limitaciones clave para que la IA sea beneficiosa para todos.