En nuestra serie de preguntas y respuestas «Engineering Energizers», nos adentramos en las trayectorias de los líderes de ingeniería que han logrado avances notables en sus áreas de especialización. En esta edición presentamos a Adithya Vishwanath, Vicepresidente de ingeniería de software de Salesforce. Dirige el departamento Data Cloud, una plataforma fundamental que integra diversas fuentes de datos y ofrece información en tiempo real y una gestión de datos optimizada en Customer 360 de Salesforce
Descubra cómo Adithya y su equipo afrontan los retos de la gestión de datos no estructurados, desde el procesamiento de múltiples formatos de datos hasta la resolución de problemas de escalabilidad.
¿Cuál es la misión de su equipo?
Transformamos la forma en que Salesforce gestiona y procesa los datos a través de Data Cloud. Nos dedicamos a crear una plataforma sólida que se integre perfectamente en el ecosistema de Salesforce. Nuestras responsabilidades clave abarcan el desarrollo de la infraestructura necesaria para Data Cloud, garantizando una integración perfecta de la plataforma y abordando las complejidades de los datos no estructurados
La gestión de datos no estructurados implica trabajar con una gran variedad de formatos, incluidos archivos de audio, vídeo y PDF. Nuestra tarea consiste en descomponer y procesar estos tipos para que resulten útiles y accesibles para las aplicaciones de Salesforce.
La gestión de datos no estructurados implica trabajar con una gran variedad de formatos, incluidos archivos de audio, vídeo y PDF
Nuestro objetivo es garantizar que Data Cloud no sólo mejore las capacidades de Customer 360, sino que también establezca nuevos puntos de referencia en el procesamiento e integración de datos en todo el ecosistema de Salesforce. Al concentrarnos en estas áreas críticas, nos comprometemos a ofrecer soluciones innovadoras que impulsen el futuro de la gestión y la utilización de datos en Salesforce.
Data Cloud es la solución de gestión de datos más avanzada de Salesforce
>
–>
Adithya explica cómo su equipo utiliza herramientas punteras para mejorar su productividad.
¿A qué reto se enfrentó tu equipo con los datos no estructurados y cómo se abordó?
Los datos no estructurados plantearon un reto distinto debido a su diversidad y complejidad. Por ejemplo, al trabajar con archivos de audio y vídeo, nuestro equipo tuvo que desarrollar un método para fragmentar y vectorizar los datos. Esto implicaba dividir los archivos en segmentos más pequeños y manejables, y convertirlos en números de coma flotante para facilitar el análisis.
Datos no estructurados
Un obstáculo importante era garantizar búsquedas de similitud vectorial precisas y eficientes en conjuntos de datos extensos. Para hacer frente a esto, implementamos algoritmos avanzados de IA y optimizamos nuestra infraestructura para gestionar el alto volumen de transacciones de manera eficaz.
Estas mejoras nos permitieron proporcionar rápidamente perspectivas y extraer información pertinente, garantizando que nuestros usuarios pudieran acceder y utilizar datos no estructurados de manera eficiente. Gracias a la actualización de nuestros sistemas para dar soporte a estos intrincados procesos, logramos avances sustanciales en la gestión de datos no estructurados, mejorando así las capacidades de análisis de datos para nuestros clientes.
La gestión de datos no estructurados es una de las tareas más complejas de la empresa
¿Cuál fue el mayor reto al que se enfrentó su equipo durante el desarrollo inicial de Data Cloud?
Uno de los retos más formidables a los que nos enfrentamos fue la integración del ecosistema central monolítico de Salesforce, que funciona con un servicio Java a gran escala, con nuestro ecosistema de Data Cloud basado en microservicios. La estructura monolítica requería un ciclo de calidad riguroso y pruebas exhaustivas, mientras que los microservicios exigían un enfoque de desarrollo más ágil. Unir estos dos sistemas para garantizar una experiencia del cliente sin fisuras supuso un obstáculo importante.
Preguntas frecuentes
Teníamos que asegurarnos de que, a pesar de los diferentes ciclos de vida de desarrollo, podríamos avanzar rápidamente en el código del lado de los microservicios sin socavar la estabilidad y el rendimiento del núcleo monolítico. Esto supuso un meticuloso equilibrio de los controles de calidad, empleando sofisticados conjuntos de puertas para gestionar las versiones sin impedir los procesos ágiles inherentes a los microservicios
Alcanzar este equilibrio era esencial para mantener altos estándares en ambos entornos de desarrollo. El reto principal consistía en integrar estos sistemas de forma que permitieran una innovación rápida y un rendimiento constante y fiable
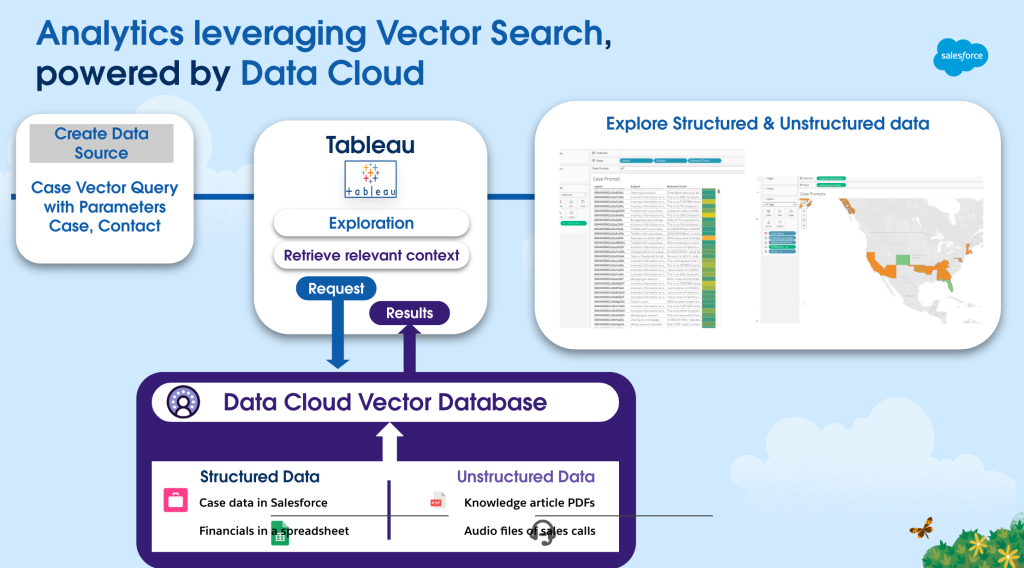
¿Cómo amplió su equipo los sistemas para gestionar los datos no estructurados de la gran base de clientes de Salesforce?
Cómo amplió su equipo los sistemas para gestionar los datos no estructurados de la gran base de clientes de Salesforce?
Con Salesforce prestando servicio a más de 150.000 clientes, cada uno de ellos con miles de usuarios interactuando simultáneamente, era crucial garantizar que nuestra infraestructura pudiera soportar estas transacciones sin ninguna caída en el rendimiento.
Para lograrlo, escalamos nuestras operaciones implementando modelos directamente en Amazon EMR en EKS dentro de clústeres Kubernetes, aprovechando su escalabilidad y eficiencia. Esto nos permitió ejecutar minimodelos en cada nodo y administrar las transacciones de forma independiente, permitiéndonos procesar aproximadamente 250 billones de transacciones a través de los inquilinos de Data Cloud por semana mientras mantenemos un alto desempeño y fiabilidad.
Además, nos concentramos en optimizar nuestros conductos de procesamiento de datos para manejar datos no estructurados de forma eficiente a escala. Esto implicó perfeccionar nuestra infraestructura y adoptar prácticas sólidas de gestión de datos. Estos esfuerzos garantizaron que pudiéramos satisfacer las demandas de nuestra gran base de usuarios sin dejar de ofrecer un procesamiento de datos fluido y eficiente.
Datos no estructurados
¿Qué estrategias utilizó su equipo para equilibrar calidad y velocidad en el desarrollo?
Inicialmente, nuestro equipo se enfrentó a desafíos con esto, particularmente debido a las diferentes demandas de nuestros ecosistemas monolíticos y de microservicios. Para solucionarlo, introdujimos una serie de puertas de calidad diseñadas para garantizar que cualquier componente que se considerara listo pudiera liberarse sin comprometer la integridad del sistema general. Sin embargo, pronto descubrimos que el exceso de controles obstaculizaba nuestros procesos ágiles.
Para perfeccionar nuestra estrategia, empezamos a centrarnos en identificar y priorizar los «santos griales» para cada versión: se trataba de características críticas que eran esenciales y no negociables. Esta estrategia nos permitió concentrar los recursos en estas tareas clave, garantizando resultados de alta calidad sin comprometer la velocidad de desarrollo.
Además, al programar los equipos de control de calidad con antelación y optimizar nuestros procesos, conseguimos un equilibrio que permitió un desarrollo rápido pero fiable. Este enfoque nos ayudó a mantener altos estándares tanto en nuestros sistemas monolíticos como de microservicios, lo que nos permitió ofrecer productos robustos y fiables sin dejar de cumplir nuestros rápidos plazos de desarrollo.
Seguridad
Por favor, comparta un ejemplo de un compromiso significativo que su equipo haya realizado durante el desarrollo.
Por favor, comparta un ejemplo de un compromiso significativo que su equipo haya realizado durante el desarrollo
Durante el desarrollo de la compatibilidad con entornos aislados para Data Cloud, nos enfrentamos a una importante disyuntiva. Los entornos sandbox son esenciales para los desarrolladores, ya que les permiten probar y personalizar las funciones de Data Cloud antes de su despliegue completo. Sin embargo, la implementación de este soporte requirió importantes recursos, lo que obligó a reasignar esfuerzos de otros proyectos
Por ejemplo, nuestro desarrollo en un ecosistema concreto tuvo que reducirse considerablemente. A pesar de que el sistema gestionaba millones de transacciones, solo mantuvimos un soporte mínimo para centrarnos en la iniciativa sandbox.
Esta decisión fue crucial, ya que nos permitió ofrecer una característica importante sin comprometer la funcionalidad y estabilidad general de Data Cloud. Mediante la reasignación estratégica de recursos y la priorización de las necesidades urgentes, conseguimos mantener nuestros compromisos y ofrecer eficazmente capacidades clave a nuestros clientes.
Datos Cloud
>
Adithya adelanta una tecnología de ingeniería emergente que su equipo está investigando en la actualidad.
¿Cuáles son los objetivos futuros de tu equipo?
De cara al futuro, nuestro equipo se está concentrando en cuatro áreas clave: 1) la mejora de los conductos de datos no estructurados; 2) el fortalecimiento de la gobernanza; 3) la ampliación de las funciones remotas de Data Cloud; y 4) la mejora de las experiencias de los desarrolladores. Nuestros esfuerzos en curso para mejorar el manejo de los datos no estructurados son cruciales, ya que nuestro objetivo es avanzar en nuestras capacidades de IA y desarrollar un gráfico de conocimiento más completo.
En términos de gobernanza, estamos comprometidos con el establecimiento de sólidos marcos de gobernanza de datos. Esto incluye la implementación de acceso basado en roles, acceso a atributos y enmascaramiento a nivel de campo para garantizar la seguridad y el cumplimiento de los datos en varias aplicaciones.
Además, nos estamos centrando en el desarrollo de funciones remotas de Data Cloud para apoyar mejor a nuestros clientes a gran escala. Esto les permitirá gestionar varias instancias de Salesforce de forma más eficaz. Estas iniciativas están diseñadas para fomentar la innovación y mantener la posición de liderazgo de Data Cloud en la tecnología de procesamiento e integración de datos. Al dar prioridad a estas áreas, pretendemos ofrecer soluciones avanzadas que respondan a las necesidades cambiantes de nuestros clientes y del mercado en general.
Por último, estamos centrados en mejorar la experiencia de los desarrolladores, permitiendo que tanto los desarrolladores de aplicaciones internos como externos utilicen la plataforma de Data Cloud a través de una variedad de bibliotecas, kits de herramientas y utilidades.
Data Cloud
Más información
- Lea este blog para saber cómo el equipo de Data Cloud está escalando volúmenes de datos masivos y reduciendo los cuellos de botella en el rendimiento.
- Siga conectado: únase a nuestra Comunidad de talento
- Consulta nuestros equipos de Tecnología y Producto para saber cómo puedes participar.