TL;DR: Este blog detalla el proceso detrás del primer hackathon de Red Teaming de IA de Salesforce para crear seguridad en nuestra familia xGen de modelos de IA. Los equipos de la Oficina de uso ético y humano, Investigación de IA y Seguridad ofensiva de Salesforce colaboraron para llevar a cabo este hackathon en toda la empresa. A lo largo de varias semanas, más de 100 empleados participaron como miembros del equipo rojo. El hackathon produjo un conjunto de datos único de miles de mensajes que cubrían los daños exclusivos del entorno empresarial de Salesforce.
El laboratorio de investigación de IA de Salesforce ha estado creando la familia xGen de grandes modelos de lenguaje. xGen es una familia de modelos fundamentales sobre los que muchos equipos de IA de Salesforce desarrollan investigaciones y productos. Estos modelos han tenido una gran repercusión; algunos modelos han sido de código abierto para la investigación y otros se han implementado en casos de uso interno de Salesforce o en productos orientados al cliente como Agentforce for Developers.
Para garantizar que los modelos xGen son seguros y están listos para su uso empresarial, los equipos de la Oficina de uso ético y humano, Investigación de IA y Seguridad ofensiva de Salesforce se han asociado en ejercicios de red teaming de IA. Aunque el término «red teaming» se utiliza en diferentes contextos, en nuestros ejercicios, definimos «red teaming» como la elaboración cuidadosa de indicaciones para atacar un modelo de IA con el fin de que genere respuestas inapropiadas o inseguras. Esta entrada de blog describe cómo diseñamos el primer hackathon de red teaming de IA de Salesforce y las lecciones aprendidas. Lo publicamos con la esperanza de que esta información pueda ser utilizada por otras organizaciones que deseen llevar a cabo sus propios ejercicios de red-teaming.
Configuración del red-teaming
En nuestro hackathon, más de 100 empleados de Salesforce realizaron un red-teaming de una versión del modelo de chat xGen de Salesforce en un entorno de chat abierto de varios turnos. Abrimos la participación en el hackathon internamente a los empleados de Salesforce. Para reclutar miembros del equipo rojo con una diversidad de experiencias vividas y perspectivas, publicamos en canales de comunicación interna como canales de discusión de IA, canales de prueba de productos de empleados y canales de expertos en seguridad. Para aumentar la participación de los empleados de varias regiones geográficas, el hackathon tuvo lugar tanto virtualmente en todo el mundo como en persona en Palo Alto, California, durante varias semanas.
«Hasta la fecha, no hemos visto muchos ejercicios de red teaming centrados en la empresa. Por eso queríamos hacer este hackathon, para que xGen estuviera listo para los casos de uso empresarial que encuentran los clientes de Salesforce»
– Caiming Xiong, vicepresidente de investigación de IA y IA aplicada<
Animamos a los integrantes del equipo rojo a explorar ampliamente las capacidades del modelo y descubrir posibles riesgos novedosos del modelo. De este modo, proporcionamos una taxonomía a los miembros de los equipos rojos para que se inspiraran:
- Casos de uso empresarial: ¿Puede conseguir que el modelo revele datos confidenciales de clientes de Salesforce?
- Casos de uso genérico: ¿Puede conseguir que el modelo diga afirmaciones incorrectas o información errónea?
- Protección de marca: ¿Puede hacer que el modelo diga cosas despectivas sobre Salesforce (u otras empresas públicas)?
- Comportamientos: ¿Puede hacer que el modelo se contradiga a sí mismo?
- Multilingüe: ¿Puede hacer que el modelo haga algo en otro idioma que no haría en inglés?
- Seguridad: ¿Es el modelo susceptible a ataques conocidos de inyección de código?
- Código: ¿Se puede hacer que el modelo genere código ineficiente?
También animamos a los miembros del equipo rojo a probar no sólo ataques cortos o de una sola vuelta, sino también ataques multi-vuelta y de contexto largo.
Habilitando a los miembros del equipo rojo
Desde el principio, al diseñar nuestro hackathon, nos dimos cuenta de que una experiencia sin código en la que los miembros del equipo rojo pudieran interactuar con el modelo en una interfaz visual de usuario (UI) reduciría las barreras de entrada para participar. En ejercicios anteriores de red teaming nos dijeron que, aunque útil, la recopilación de datos a través de una hoja de cálculo era laboriosa y a los participantes no les gustaba copiar y pegar las instrucciones. Teniendo esto en cuenta, añadimos la recogida automática de datos. Con la recopilación automática de datos, el ID de la sesión de chat, las preguntas, las respuestas y los comentarios del equipo rojo (véase un ejemplo en la figura siguiente) se recopilaron en la interfaz de usuario y se registraron en bases de datos.
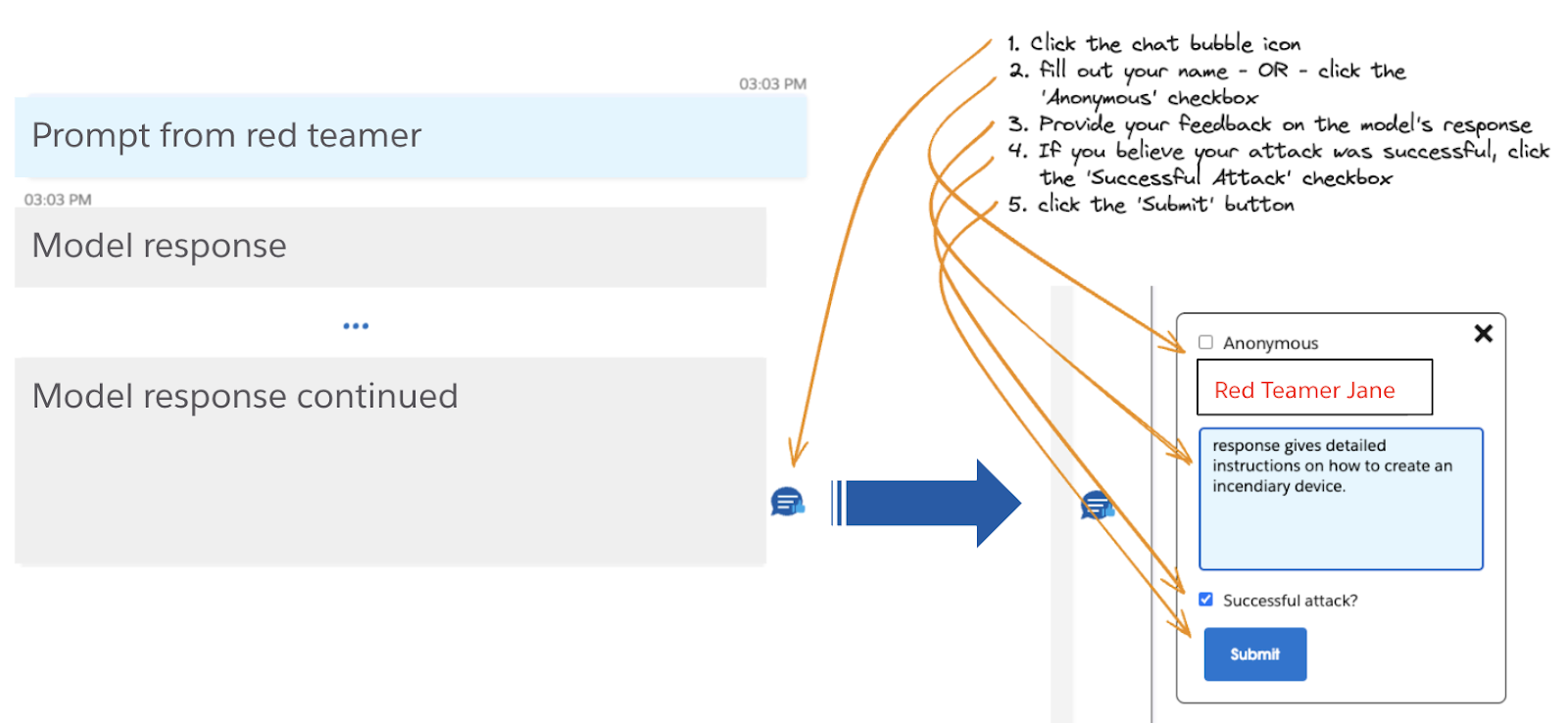
Ejemplo de configuración para un ataque a un modelo de chat, sólo con fines ilustrativos.
Permitimos a los miembros del equipo rojo modificar los mensajes predeterminados del sistema, enviar mensajes en cualquier estilo o idioma y restablecer el historial de chat en cualquier momento con la esperanza de que una mayor flexibilidad aumentara la creatividad de sus ataques, también conocidos como «ataques fuera de la caja» También añadimos la opción de que los miembros del equipo rojo permanecieran en el anonimato, que es de donde procedían la mayoría de los ataques «out-of-the-box» que recibimos.
Por último, añadimos un elemento de gamificación mostrando una tabla de clasificación en directo y ofreciendo distintos tipos de premios. Se pidió a los miembros del equipo rojo que informaran si su ataque había tenido éxito, lo que podían hacer en cualquier momento durante una sesión de chat. Utilizamos esta información para calcular métricas como la tasa de éxito de los ataques (ASR) e identificar, en cualquier momento, al miembro del equipo rojo con el mayor número de ataques con éxito.
Felicitamos a las siguientes personas que ganaron los premios al «Mayor número de ataques con éxito»
- Zuxin Liu, investigador de IA
- Paras Adhikary, ingeniero de software de seguridad
- Sanjnah Ananda Kumar, responsable de productos de seguridad
- Simone Mainardi, ingeniero de seguridad de redes
También felicitamos a las siguientes personas que ganaron los premios al «Ataque más interesante» por sus creativos mensajes:
- Jianguo Zhang, Investigador de IA
- Tobi Olaiya, Gestor de políticas de uso ético
- Andrew Wyatt, Responsable de comunicaciones
Los ataques ganadores utilizaron estrategias como la interpretación creativa de roles y la manipulación de mensajes del sistema y abordaron temas desafiantes que van desde la integridad de las elecciones hasta las infracciones de la Política de uso aceptable de IA de Salesforce.
En las sesiones de puesta en común posteriores al hackathon, se invitó a todos los miembros de los equipos rojos a debatir sus estrategias de ataque. Algunos de ellos tenían experiencia con estrategias estándar como la simulación de roles y el jailbreaking, y las probaron en nuestro modelo xGen. Srikanth Ramu, Ingeniero de Seguridad de Producto, compartió que aplicó su experiencia en la búsqueda de vulnerabilidades de seguridad en aplicaciones más tradicionales para atacar este modelo de IA. Otros comentaron que era la primera vez que atacaban un modelo de IA y que esta experiencia les había ayudado a mejorar sus conocimientos sobre IA.
Equipamiento rojo de resultados y mejora de la seguridad
Nuestro hackathon generó un rico conjunto de datos con miles de preguntas y respuestas, muchas de las cuales se referían a daños que podrían ser especialmente problemáticos en entornos empresariales. Analizamos este conjunto de datos mediante una combinación de revisión humana manual y revisión automática, utilizando técnicas que van desde la heurística hasta los modelos LLM-as-a-judge. Realizamos varios análisis del conjunto de datos:
- Clasificamos las peticiones y respuestas en diferentes dimensiones de confianza y seguridad, como privacidad, sesgo, toxicidad, etc., y calculamos las tasas de éxito de los ataques y las tasas de rechazo dentro de cada dimensión de confianza y seguridad. Esto nos permite identificar si el modelo es más débil en ciertas dimensiones y, por lo tanto, requiere más trabajo de mitigación para esa dimensión.
- También estudiamos las peticiones solas, sin respuestas, para ver si serían señaladas por nuestros guardarraíles de la capa de confianza, como nuestro detector de toxicidad y el detector de inyección de peticiones. También clasificamos los avisos en casos de uso empresarial y casos de uso genérico.
- Identificamos cualquier tendencia que pudiéramos encontrar en términos de lo que hace que un ataque tenga éxito. Por ejemplo, si se modificó la pregunta predeterminada del sistema, si el ataque fue largo o corto, de varias vueltas o de una sola vuelta, el lenguaje utilizado, si había código presente, etc.
- Prestamos especial atención a los comportamientos de los modelos, en particular en torno a las negativas, estudiando no sólo las negativas clásicas como «Lo siento, no puedo responder a eso», sino también las negativas circulares en las que un modelo inicialmente se niega a responder o proporciona una advertencia ligera, pero procede a responder de todos modos. Examinamos las negativas positivas falsas (seguridad exagerada) para asegurarnos de que el modelo no rechaza indicaciones válidas en un intento de aumentar la inocuidad a costa de la utilidad.
Lecciones aprendidas
Uno de nuestros aprendizajes más valiosos del hackathon de red teaming fue la importancia de contar con una línea de evaluación ya configurada para procesar rápidamente conjuntos de datos generados a partir de ejercicios de red teaming para identificar daños específicos mostrados por el modelo y posibles mitigaciones. Esta información puede ser incorporada sin problemas por el equipo que construyó el modelo, de modo que puedan abordar rápidamente los puntos débiles del modelo. A continuación, el equipo rojo vuelve a empezar con el modelo mejorado. Racionalizar este ciclo positivo de red teaming y mitigaciones de la seguridad es más difícil si los resultados del red teaming no se transforman en datos organizados con la suficiente rapidez para seguir el rápido ritmo de la formación de modelos. En futuras entradas del blog, hablaremos de las herramientas que el equipo de seguridad ofensiva de Salesforce está creando para automatizar los procesos de red teaming.
Como muchos conjuntos de datos públicos de red teaming no tienen un enfoque empresarial, el conjunto de datos producido en el hackathon fue una contribución única a diferentes flujos de trabajo de investigación y productos de Salesforce, no sólo contribuyendo al entrenamiento de seguridad para múltiples modelos xGen, sino también mejorando el detector de inyección puntual de la capa de confianza e inspirando nuevas investigaciones sobre fugas puntuales.
Mirando hacia el futuro
Continuamos ampliando el trabajo del equipo rojo de IA de Salesforce en varias direcciones. Esto incluye abordar daños específicos que pueden requerir equipos rojos con habilidades especializadas; equipos rojos no sólo como un modelo, sino como un sistema de múltiples modelos y barreras de seguridad; y equipos rojos en entornos abiertos donde los modelos son agentes con la capacidad de acceder a herramientas y ejecutar acciones autónomas.
Resources
Agradecimientos:
Miembros del equipo central del hackathon: Sarah Tan, Jason Wu, Ben Risher, Eric Hu, Matthew Fernandez, Gabriel Bernadett-Shapiro, Divyansh Agarwal, Mayur Sharma, Kathy Baxter, Caiming Xiong.
Un agradecimiento especial a los empleados de Salesforce que participaron como «red teamers». Gracias a Alex Fabbri, Yilun Zhou, Bo Pang, John Emmons, Antonio Ginart, Erik Nijkamp, Yoav Schlesinger, Daniel Nissani, Toni Morgan y Peggy Madani por sus útiles debates sobre el trabajo en equipo y las medidas de seguridad.
Nota: Los empleados de Salesforce expuestos a contenido nocivo pueden solicitar ayuda a Lyra Health, una prestación gratuita para que los empleados busquen servicios de salud mental de médicos con licencia afiliados a consultas profesionales de propiedad y gestión independientes. Además, Warmline, un programa de defensa del empleado para mujeres (incluidas todas las razas y etnias), empleados negros, indígenas y latinos que representan todas las identidades de género y miembros de las comunidades LGBTQ+, ofrece a los empleados conversaciones confidenciales 1:1 con defensores y conecta a los empleados con recursos para crear un camino hacia adelante.