En nuestra serie de preguntas y respuestas «Engineering Energizers», exploramos las inspiradoras trayectorias de líderes de la ingeniería que han hecho avanzar significativamente sus campos. Hoy nos reunimos con Soumya KV, que dirige el desarrollo de la capa de aplicaciones internas de Data Cloud en Salesforce. Su equipo, con sede en la India, está especializado en la segmentación y activación avanzada de datos, lo que permite estrategias de marketing personalizadas y una mejor toma de decisiones para los clientes de Salesforce.
Únase a Soumya y a su equipo mientras abordan importantes retos de escalabilidad para obtener información más detallada para los clientes de Salesforce
¿Cuál es la misión de su equipo?
Nuestra misión es diseñar, desarrollar, probar y mejorar continuamente las aplicaciones internas de Data Cloud que optimizan la segmentación y el compromiso de los clientes a través de la segmentación y la activación.
Nuestra misión es diseñar, desarrollar, probar y mejorar continuamente las aplicaciones internas de Data Cloud
La segmentación divide los datos de los clientes en grupos específicos en función de criterios como la edad, la ubicación y los intereses. Esto ayuda a las empresas a dirigir sus esfuerzos de marketing, aumentando las tasas de conversión o generando mejores perspectivas de negocio. Por ejemplo, una empresa de calzado deportivo puede dirigirse a personas de entre 20 y 35 años apasionadas por el deporte. Al utilizar los datos segmentados, la empresa puede adaptar las campañas de marketing para que resuenen con este público en particular, lo que puede conducir a un mayor compromiso y tasas de conversión
A continuación, Activation enriquece los datos segmentados y los envía al destino adecuado dentro y fuera de Salesforce. Esto puede incluir Marketing Cloud para campañas de correo electrónico y SMS y Commerce Cloud orientada a casos de uso de comercio y activando directamente a un cliente y a la ubicación de destino del socio del ecosistema.
La activación enriquece entonces los datos segmentados y los envía al destino apropiado dentro y fuera de Salesforce
El trabajo de nuestro equipo es crucial porque, sin segmentación y activación, los datos recopilados en la Nube de Datos quedarían sin explotar e inutilizables para los clientes. En última instancia, permitimos que los clientes tomen decisiones informadas, se dirijan a públicos específicos y obtengan valor empresarial de sus datos.
La segmentación y la activación de los datos son esenciales para el éxito de la empresa
El equipo se dedica a desarrollar las últimas soluciones, como la segmentación en BYOL, el cálculo de segmentación en tiempo real, al tiempo que perfecciona continuamente las capacidades de segmentación, la escalabilidad y la usabilidad. En el frente de la activación, están mejorando las funciones para la activación del ecosistema, facilitando las integraciones impulsadas por ISV con los socios. Además, el equipo da prioridad al desarrollo de una plataforma de salida que proporcione a los clientes flexibilidad para configurar y utilizar los datos de salida en varios destinos, como GCS, Azure y SFTP. Esto incluye la compatibilidad con diversos tipos de archivos, tamaños, métodos de cifrado y técnicas de compresión.
Datos de salida
También nos hacemos propietarios del servicio, manteniendo los sistemas de producción y asegurando su salud y estabilidad. Esto implica la supervisión, el soporte y el cumplimiento de los requisitos de disponibilidad, fiabilidad, rendimiento y seguridad de los datos de los sistemas.
También nos hacemos cargo del servicio
>
–>
Soumya describe la cultura de su equipo de ingeniería de aplicaciones de Data Cloud.
¿A qué retos se enfrenta su equipo mientras trabaja en la capa interna de aplicaciones de Data Cloud?
El mayor reto al que nos enfrentamos es la gestión de la escala. Manejamos una cantidad ingente de datos, con más de 4500 inquilinos y procesando un cuatrillón de registros mensuales. Diariamente, procesamos más de 42 trillones de registros y gestionamos 36.000 ejecuciones de segmentos y 12.500 de trabajos de activación. Esto representa un crecimiento de más del 100% en comparación con el año anterior.


Para contrarrestar este desafío, empleamos muchas estrategias:
- Supervisión y análisis continuos: el equipo supervisa continuamente el sistema de producción, llevando a cabo una evaluación del rendimiento, analizando el comportamiento del sistema, la latencia, la utilización de la memoria, la CPU y el coste. Supervisan de cerca la escala, los patrones de usabilidad y el uso de recursos para evaluar patrones y optimizar el rendimiento.
- Optimización y puesta a punto: el equipo se centra en optimizar los trabajos de segmentación y activación, las operaciones de la base de datos y la arquitectura de la plataforma para poner a punto la escalabilidad, el rendimiento y la gestión eficiente de conjuntos de datos más grandes. Evalúan y perfeccionan continuamente sus procesos para mejorar la estabilidad y el rendimiento general del sistema.
- Exploración de técnicas de optimización: se exploran técnicas como la agrupación de datos por lotes y la programación optimizada para agrupar trabajos relacionados y reducir el tiempo de procesamiento.
- Adopción de nuevas tecnologías: el equipo se mantiene al día de las últimas tendencias y utiliza tecnologías según proceda. Esto incluye el aprovechamiento de opciones como AWS EMR on EKS para mejorar la escalabilidad y Spark DistCp para capacidades de transferencia de datos en paralelo más rápidas.
- Adopción de nuevas tecnologías: el equipo se mantiene actualizado sobre las últimas tendencias y utiliza las tecnologías según corresponda
- Implementación de Guardrails: el equipo implementa guardrails para garantizar el uso adecuado de las capacidades y evitar el uso indebido. Esto incluye establecer límites, proporcionar directrices para un uso óptimo, ofrecer herramientas de autoayuda y educar a los clientes.
- Implementación de Guardrails: el equipo implementa guardrails para garantizar un uso adecuado de las capacidades y evitar su uso indebido
¿En qué tecnología confía más tu equipo para gestionar el reto del escalado?
Apache Spark es una tecnología crucial para procesar la ingente cantidad de datos que manejamos a diario. Con billones de registros que procesar a diario, las capacidades de procesamiento distribuido de Spark nos permiten distribuir las cargas de trabajo en un clúster de máquinas, lo que posibilita la ejecución en paralelo y la escalabilidad. Esto significa que podemos procesar eficientemente grandes conjuntos de datos, ejecutando complejas operaciones de unión y consulta de una manera eficiente y oportuna.
Spark
Spark destaca en el manejo de cálculos complejos y operaciones de unión, por lo que es ideal para procesar consultas intrincadas para extraer audiencias específicas en base a los criterios de filtrado de un segmento determinado. Los trabajos de Spark ejecutan estas consultas en conjuntos de datos distribuidos, aprovechando el procesamiento paralelo para garantizar un procesamiento rápido a pesar de los enormes volúmenes de datos.
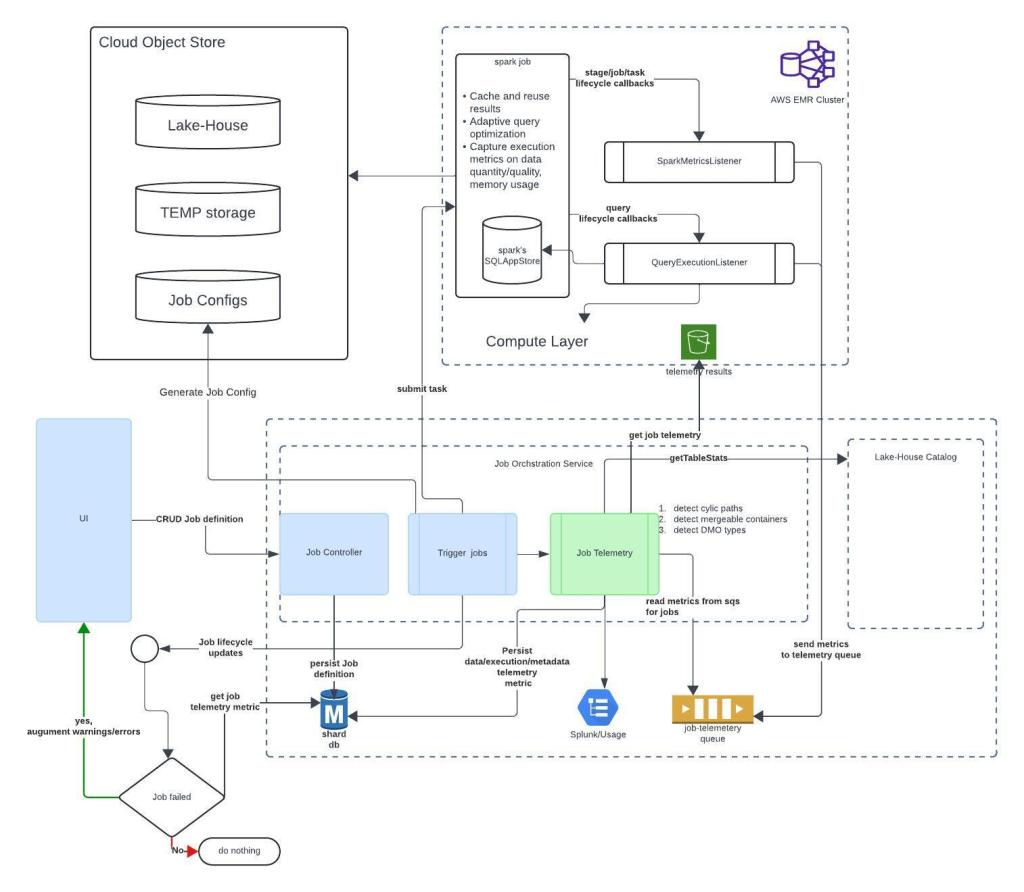
Uso de Spark en el procesamiento de segmentación.
Spark es esencial en el escenario de activación, ya que nos permite enriquecer los datos segmentados añadiendo los atributos necesarios a través de uniones con otras tablas para mejorar el compromiso del cliente. Spark se aplica eficientemente para los requisitos de filtrado de consentimiento/opt-out. Spark DistCp se utiliza para la copia distribuida que permite la transferencia de grandes conjuntos de datos con latencias bajas. También se utiliza para cifrar grandes cargas de datos antes de su salida para garantizar la seguridad de los datos. Esto garantiza que los datos activados sean completos y personalizados para satisfacer las necesidades específicas de nuestros clientes
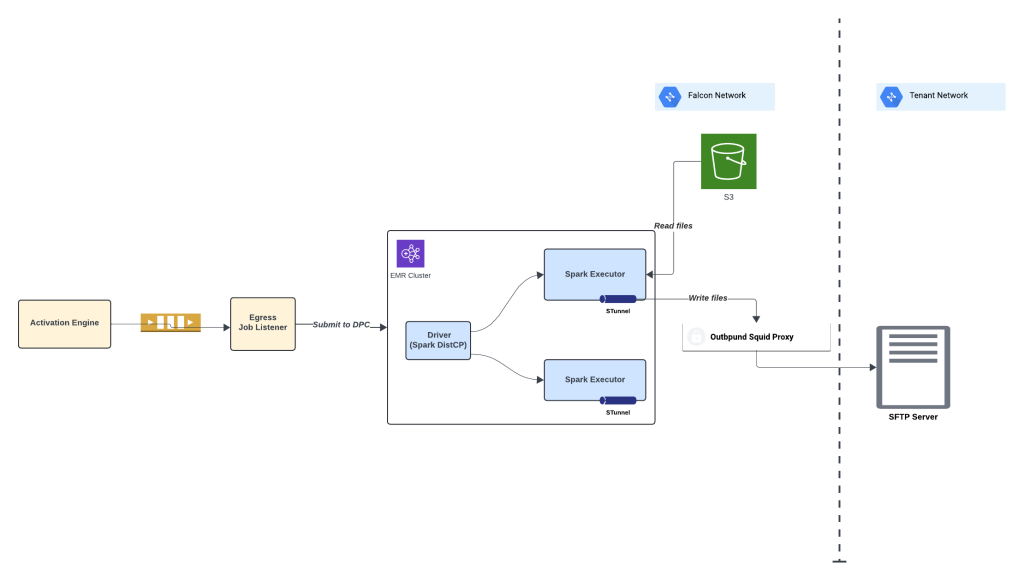 Uso de Spark distcp en el paso de salida de activación.
Uso de Spark distcp en el paso de salida de activación.Debajo del capó, el motor computacional central de Spark gestiona varios aspectos de la ejecución de trabajos. Se encarga de la programación de los trabajos en el clúster, la gestión de la memoria y la recuperación de fallos, garantizando una utilización eficiente de los recursos y manteniendo la estabilidad del entorno de procesamiento. Este robusto motor nos permite ejecutar cálculos complejos en grandes conjuntos de datos con un rendimiento mejorado
¿Podría darnos una idea de los procesos de pruebas y control de calidad de su equipo para garantizar la fiabilidad y estabilidad de la capa de aplicaciones de Data Cloud?
Nuestro equipo sigue un exhaustivo proceso de pruebas y control de calidad que contiene múltiples capas:
- Pruebas unitarias: Los desarrolladores realizan pruebas unitarias exhaustivas en el código que escriben, garantizando una cobertura y eficacia suficientes.
- Pruebas unitarias
- Pruebas de integración: Probamos la funcionalidad sin fisuras entre los módulos, incluida la integración de la interfaz de usuario, las acciones de la base de datos y la integración con los sistemas upstream/downstream.
- Pruebas de Funcionalidad: Escribimos casos de prueba exhaustivos que cubren todos los requisitos, los revisamos con compañeros y miembros senior, y validamos la funcionalidad a través de varios escenarios, incluyendo pruebas negativas y de camino feliz.
- Automatización: Automatizamos las pruebas de interfaz de usuario y backend, utilizando entradas variadas para identificar problemas o errores. Esto incluye la automatización de las pruebas de integración funcionales de backend para salvaguardar la funcionalidad existente durante futuras mejoras.
- Automatización
- Pruebas de Rendimiento: Realizamos pruebas de rendimiento para evaluar la escalabilidad y el rendimiento. Esto incluye pruebas con grandes conjuntos de datos, ejecutando cientos de trabajos paralelos de segmento/activación para evaluar la escalabilidad y el rendimiento. Comparamos el rendimiento del sistema para determinar los objetivos alcanzables y los acuerdos de nivel de servicio.
>
Soumya nos cuenta por qué los ingenieros deberían unirse a Salesforce.
Soumya nos cuenta por qué los ingenieros deberían unirse a Salesforce
¿Cómo influyen los comentarios de los clientes en su trabajo en la capa de aplicaciones de Data Cloud?
Como organización centrada en el cliente, buscamos activamente los comentarios de los clientes y las partes interesadas para guiar la dirección del trabajo de nuestro equipo. Recopilamos información a través de varios canales, como las interacciones con los clientes y los compromisos del equipo de atención al cliente. Estos canales nos permiten comprender las necesidades de los clientes, sus preferencias de uso y las oportunidades de mejora
Un ejemplo reciente de comentarios de clientes que influyeron en nuestro trabajo fue el de una organización orientada a las métricas. Querían medir el tiempo de procesamiento de cada paso de nuestra solución, incluida la segmentación, la activación y la entrega de datos, para optimizar sus procesos. En respuesta, estamos desarrollando un panel de métricas de trazabilidad que proporciona información sobre nuestras etapas de procesamiento.
Además de las métricas, también recibimos comentarios sobre los requisitos de latencia, las mejoras de usabilidad, la compatibilidad con diversos marcos de conectores, las capacidades de creación de segmentos inteligentes y óptimos, y la generación de cargas útiles de salida de datos que se alineen con las capacidades de procesamiento de su sistema. También recibimos información sobre la mejora de la seguridad, el cifrado y el enmascaramiento de datos
Más información
- ¿Hambre de más historias sobre Data Cloud? Lea este blog para saber cómo el equipo de la capa informática de procesamiento de big data Data Cloud de la India da soporte a millones de tareas relacionadas con Data Cloud al mes.
-
<¡
- Manténgase conectado: únase a nuestra Comunidad de talentos!
- Consulta nuestros equipos de Tecnología y Producto para saber cómo puedes participar.