En nuestra serie de preguntas y respuestas «Engineering Energizers», exploramos las mentes innovadoras que dan forma al futuro de la ingeniería de Salesforce. Hoy, nos reunimos con Erwin Karbasi, que dirige el desarrollo del marco de evaluación central de Salesforce (SF Eval), una revolucionaria herramienta interna utilizada por los ingenieros de Salesforce para evaluar el rendimiento de los modelos generativos de IA.
Explore cómo SF Eval aborda los retos de las pruebas de IA, mejora la fiabilidad de las aplicaciones e incorpora los comentarios de los usuarios para mejorar de forma continua los resultados de los modelos de IA.
¿Cuál es la misión de su equipo de IA?
Nuestro equipo garantiza que los componentes de IA de Salesforce, como Einstein Copilot, ofrecen resultados que son no sólo de alta calidad, fiables y relevantes, sino también éticamente alineados. Este compromiso genera confianza entre nuestros usuarios, ya que probamos rigurosamente estos componentes a través de SF Eval. (Este sólido marco nos ayuda a identificar y abordar posibles problemas, como el sesgo y la precisión, garantizando que nuestras herramientas de IA superen las expectativas de los usuarios en términos de calidad y fiabilidad.
Prueba de los resultados
SF Eval es una plataforma completa y por capas que integra métricas tradicionales de aprendizaje automático con métricas asistidas por IA para evaluar el rendimiento de los modelos de IA de forma exhaustiva. Esto incluye la evaluación de varios componentes, como las instrucciones, los modelos de lenguaje de gran tamaño (LLM) y Einstein Copilot. Al garantizar que estos componentes cumplen altos estándares de precisión y relevancia, dotamos a las empresas de herramientas de IA fiables
¿Cuáles son los retos a la hora de evaluar la precisión y relevancia de la IA generativa y los LLM?
- Ambigüedad de las preguntas: esto puede dar lugar a respuestas irrelevantes de la IA. Para mitigarlo, el equipo perfecciona las instrucciones para que sean más claras y coherentes, precisas y menos propensas a generar resultados erróneos
- Exactitud real de los resultados de LLM: Salesforce aborda este reto incorporando mecanismos de comprobación de hechos en tiempo real y supervisión humana. Este doble enfoque permite la verificación de los resultados críticos, confirmando que la información proporcionada por la IA es precisa y fiable.
- Exactitud real: Salesforce aborda este reto incorporando mecanismos de comprobación de hechos en tiempo real y supervisión humana
- Exactitud de la información obtenida: el equipo aborda esta cuestión utilizando fuentes fiables para la recuperación de datos e implementando algoritmos de reordenación. Estos algoritmos ayudan a validar y garantizar la relevancia y la precisión de los datos recuperados, lo que es crucial para mantener la relevancia y la integridad de las respuestas generadas por IA.
- Precisión: el equipo aborda esta cuestión utilizando fuentes fiables para la recuperación de datos e implementando algoritmos de reordenación
Estas estrategias mejoran colectivamente la confianza del usuario y la fiabilidad de las aplicaciones de IA.
¿Cuáles fueron los retos iniciales en el desarrollo de SF Eval?
Al principio, definir las métricas adecuadas fue un gran obstáculo. El equipo tuvo que decidir si adoptar las métricas existentes en el sector o desarrollar otras nuevas adaptadas a sus necesidades específicas, como la relevancia de los datos de CRM. Esto era crucial para garantizar la calidad y pertinencia de los resultados de la IA
La integración supuso otro reto, ya que requería una coordinación perfecta entre varios componentes de la amplia plataforma de Salesforce. Esta integración era esencial para crear un marco cohesivo que pudiera dar soporte eficaz tanto a las aplicaciones internas como a las necesidades de los usuarios externos.
Por último, abordar las necesidades de los clientes internos y externos era complejo. El equipo tenía como objetivo crear una plataforma unificada que pudiera atender las diversas necesidades de los usuarios, integrándose a la perfección en sus procesos de desarrollo. Esto requirió comentarios y ajustes continuos para garantizar que el marco de trabajo cumplía todas las expectativas de los usuarios y mejoraba su experiencia general con las herramientas de Salesforce AI.
Preguntas frecuentes
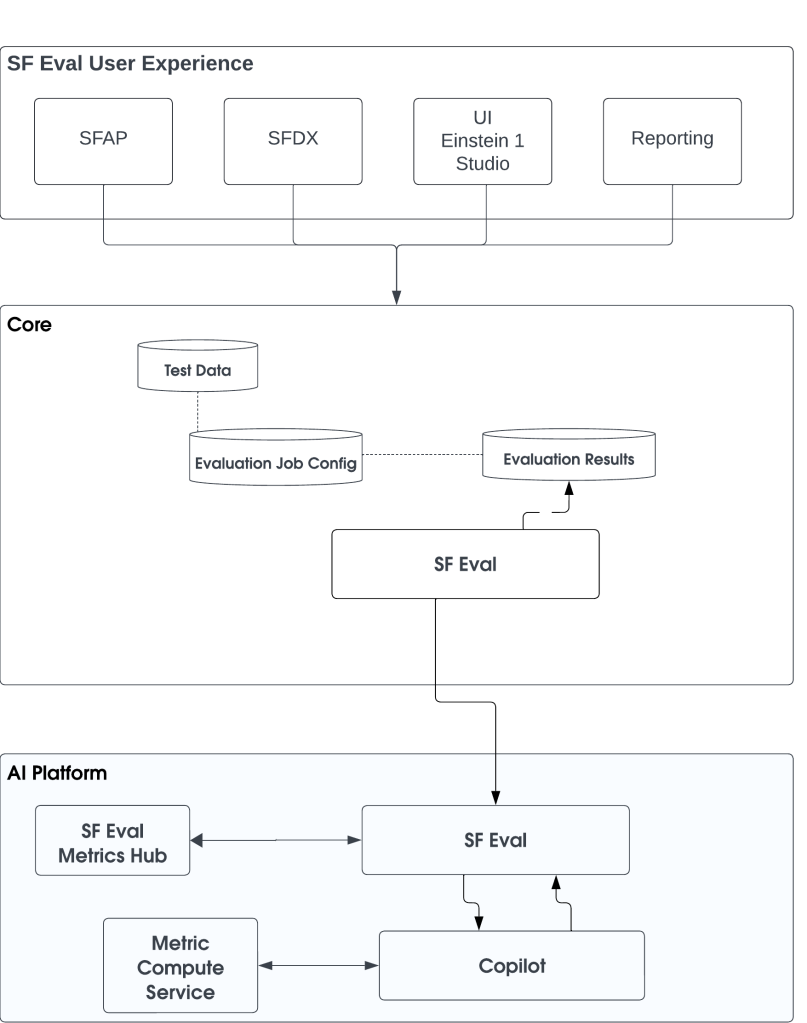
El ecosistema SF Eval, accesible a través de SFDX / Einstein 1 Studio, permite a los usuarios realizar evaluaciones gen AI y puntuarlas utilizando métricas del centro de métricas.
¿Cuál es una característica adicional clave de SF Eval que aborda un reto importante a la hora de probar aplicaciones de IA?
Una característica específica es su completa evaluación comparativa y sus capacidades de evaluación y mejora rápidas. Esta característica es crucial para evaluar y mejorar sistemáticamente el rendimiento de la IA. Mediante el uso de una serie de pruebas y métricas estandarizadas, SF Eval puede comparar los modelos de IA con los estándares y las mejores prácticas del sector. Este proceso ayuda a identificar los puntos fuertes y débiles de los resultados de la IA, proporcionando una vía clara para realizar mejoras específicas. Además, la evaluación y la mejora inmediatas garantizan que las instrucciones utilizadas para probar la IA se perfeccionen continuamente en cuanto a claridad, relevancia y eficacia, lo que se traduce en interacciones de IA de mayor calidad
Otra característica fundamental se centra en el aspecto de recuperación, conocido como RAG (Retrieval-Augmented Generation). Esta función implementa modelos de evaluación conscientes del contexto que mejoran la capacidad de la IA para generar respuestas contextualmente relevantes en diversos dominios y escenarios. Al garantizar que los datos recuperados son pertinentes para las instrucciones, esta función aborda importantes retos relacionados con la precisión y la pertinencia de los contenidos generados por la IA
¿Cómo se puede utilizar SF Eval en las diferentes etapas de su aplicación, y cuáles son los propósitos específicos de cada una?
SF Eval se utiliza en tres fases clave:
- Desarrollo: Durante la fase de desarrollo, se emplea SF Eval para probar y validar rigurosamente las indicaciones iniciales y los planes estratégicos. Esto implica identificar y rectificar cualquier posible error o ineficacia en una fase temprana del proceso, garantizando que los elementos fundacionales sean sólidos y eficaces antes de pasar a las siguientes fases.
- Desarrollo
- Desarrollo
- Benchmarking: En la fase de evaluación comparativa, SF Eval lleva a cabo un análisis comparativo detallado de varios LLM en función de criterios clave como la precisión, la fiabilidad, las métricas de rendimiento y la rentabilidad. Esta fase es crucial para que los responsables de la toma de decisiones seleccionen el LLM más adecuado que se alinee con los requisitos específicos de CRM y los objetivos estratégicos de la organización.
- Producción: Una vez en producción, SF Eval supervisa continuamente el sistema desplegado para garantizar que se adhiere a los estándares de calidad establecidos durante la fase de desarrollo. Detecta cualquier deriva o desviación en el rendimiento, lo que permite realizar ajustes oportunos en los avisos o planes estratégicos. Esta evaluación continua garantiza que el sistema siga siendo eficiente, fiable y alineado con los resultados deseados en un entorno operativo del mundo real.
¿Cómo mejora SF Eval la fiabilidad y el rendimiento de las aplicaciones de IA desde el desarrollo hasta después de la implementación?
SF Eval está estructurado en capas, empezando por las pruebas ad hoc en la fase de desarrollo, en la que los desarrolladores pueden recibir información inmediata sobre los resultados de la IA. Le siguen las pruebas por lotes, que simulan situaciones reales para evaluar los resultados de forma más exhaustiva. La capa superior incluye la supervisión y observabilidad en tiempo de ejecución, lo que garantiza una evaluación continua incluso después de la implantación. Este enfoque de varios niveles permite probar y perfeccionar a fondo las aplicaciones de IA, garantizando que funcionen de forma óptima en el mundo real
¿Cómo influyen los comentarios de los clientes en el desarrollo de aplicaciones de IA en Salesforce?
Una característica específica es su adaptabilidad dinámica a los comentarios de los clientes. Esta característica es crucial para refinar los resultados de la IA basándose en las interacciones de los usuarios en tiempo real. Al incorporar los comentarios directamente en el proceso de evaluación, SF Eval puede ajustar las indicaciones para mejorar su relevancia, claridad y eficacia. Este mecanismo de bucle de retroalimentación garantiza que las aplicaciones de IA se mantengan alineadas con las necesidades y expectativas de los usuarios, lo que mejora significativamente la capacidad de respuesta y la adaptabilidad de las interacciones basadas en indicaciones.
SF Eval
Los comentarios de los clientes determinan de forma significativa el desarrollo de las aplicaciones de IA en Salesforce, garantizando que las herramientas no sólo satisfacen las necesidades de los usuarios, sino que también se adaptan a ellas. Por ejemplo, los comentarios han llevado a la mejora de los modelos de análisis de sentimientos para detectar emociones sutiles como la frustración o la confusión, mejorando así la eficacia de las interacciones de asistencia al cliente.
El mecanismo de bucle de comentarios de Salesforce dentro de SF Eval facilita este proceso de mejora continua. Este mecanismo permite a los usuarios proporcionar comentarios en tiempo real sobre los resultados de la IA, que Salesforce integra en el desarrollo continuo de la IA. Esta integración ayuda a realizar ajustes dinámicos en los modelos y algoritmos de IA basados en las interacciones y aportaciones de los usuarios, lo que garantiza que las aplicaciones de IA sean prácticas, se centren en el usuario y se ajusten a las expectativas cambiantes de los usuarios.
La integración de Salesforce en SF Eval facilita este proceso de mejora continua
Los comentarios de los clientes no sólo influyen, sino que son fundamentales en el proceso de desarrollo iterativo de Salesforce, ya que fomentan mejoras que perfeccionan la experiencia del usuario y la fiabilidad de las aplicaciones.