Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Batchable y Queueable son los dos marcos asincrónicos predominantes disponibles para los desarrolladores en la plataforma Salesforce. Cuando trabaje con registros, es posible que se pregunte cuál debería usar. En esta publicación, presentaremos una solución alternativa que elige automáticamente la opción correcta entre los marcos Apex por lotes y en cola, lo que le permite concentrarse en la lógica que necesita implementar en lugar de qué tipo de ejecución asíncrona es la mejor.
Veamos un enfoque que combina lo mejor de ambos mundos. Tanto Batchable como Queueable se utilizan con frecuencia para:
- Realizar llamadas de API (ya que las llamadas no están permitidas dentro del código activable síncrono o directamente dentro de los trabajos programados)
- Procesar datos (con los que no sería posible trabajar cuando se llama al código sincrónicamente debido a cosas como los límites de Salesforce)
Dicho esto, hay algunas distinciones interesantes (con las que quizás ya esté familiarizado) que crean pros y contras obvios al usar cualquiera de los dos marcos.
Apex por lotes es:
- Más lento para iniciarse, más lento para moverse entre fragmentos por lotes
- Capaz de consultar hasta 50 millones de registros en su método de inicio
- Solo puede tener cinco trabajos por lotes trabajando activamente en un momento dado
- Puede mantener una cola de trabajos por lotes para que se inicie cuando los cinco trabajos por lotes simultáneos están ocupados procesando, pero solo puede haber un máximo de 100 trabajos por lotes en la cola flexible
Apex en cola es:
- Rápido de ejecutar y rápido de implementar
- Todavía sujeto al límite de filas de consultas de Apex de 50 000 registros
- Puede tener hasta 50 trabajos de Apex en cola iniciados desde dentro de una transacción síncrona
- Puede tener solo 1 trabajo que se puede poner en cola una vez que ya está en una transacción asíncrona
Estos pros y contras representan una oportunidad única para abstraer cómo se define un proceso asincrónico y crear algo reutilizable, independientemente de cuántos registros necesite para actuar.
Veamos una implementación de ejemplo y luego cómo funcionará exactamente esa abstracción.
Primero, un ejemplo del diseño en uso.
Este ejemplo asume que está trabajando con una organización B2C de Salesforce donde es importante que el nombre de la cuenta siempre coincida con el del contacto, y solo puede haber un contacto por cuenta. Observe cómo en nuestro ejemplo ContactAsyncProcessor , la única lógica que debe existir está asociada exactamente con esta regla comercial:
<dx-code-block title language="apex" code-block="public class ContactAsyncProcessor extends AsyncProcessor { protected override void innerExecute(List records) { Map accountsToUpdate = new Map(); for (Contact con : (List) records) { accountsToUpdate.put( con.AccountId, new Account( Id = con.AccountId, Name = con.FirstName + ‘ ‘ + con.LastName ) ); } update accountsToUpdate.values(); }
} // and then in usage
new ContactAsnycProcessor() .get(‘SELECT AccountId, FirstName, LastName FROM Contact’) .kickoff(); «>
Por supuesto, este es un ejemplo muy simple: no muestra cosas como que Contact.AccountId sea nulo, manejo de segundos nombres y más. Este ejemplo muestra cómo las subclases pueden ayudar a simplificar el código. Aquí, no necesita preocuparse por cuántos resultados devuelve la consulta de ejemplo, o si debe o no usar una implementación Batchable o Queueable; simplemente puede concentrarse en las reglas comerciales.
¿Cómo termina siendo esa clase principal AsyncProcessor ? Echemos un vistazo a lo que sucede detrás de escena.
Creación de un procesador asíncrono compartido
Para empezar, existen algunas limitaciones técnicas interesantes que debemos tener en cuenta cuando buscamos consolidar las interfaces Batchable y Queueable:
- Una clase de lote debe ser una clase externa. Es una sintaxis válida declarar una clase interna como Batchable, pero intentar ejecutar una clase interna a través de
Database.executeBatchgenerará una excepción.- Esta excepción asíncrona solo aparecerá en los registros y no se devolverá directamente a la persona que llama en un contexto síncrono, lo que puede ser muy engañoso ya que la ejecución no se detendrá como cabría esperar con una excepción tradicional.
- Una clase en cola puede ser una clase interna, pero una clase externa que implementa
Database.BatchableyDatabase.Statefultampoco puede implementarSystem.Queueable.
Desea que este marco sea flexible y escalable sin tener que realizar ningún cambio en él. Debe ser capaz de:
- Tomar una consulta o una lista de registros.
- Evaluar cuántos registros forman parte de la consulta o lista.
- Al verificar si está por debajo de un cierto umbral, qué subclases deberían poder modificarse, inicie un Queueable. De lo contrario, inicie un Batchable.
Este diagrama muestra lo que debe suceder de forma síncrona versus asíncrona:
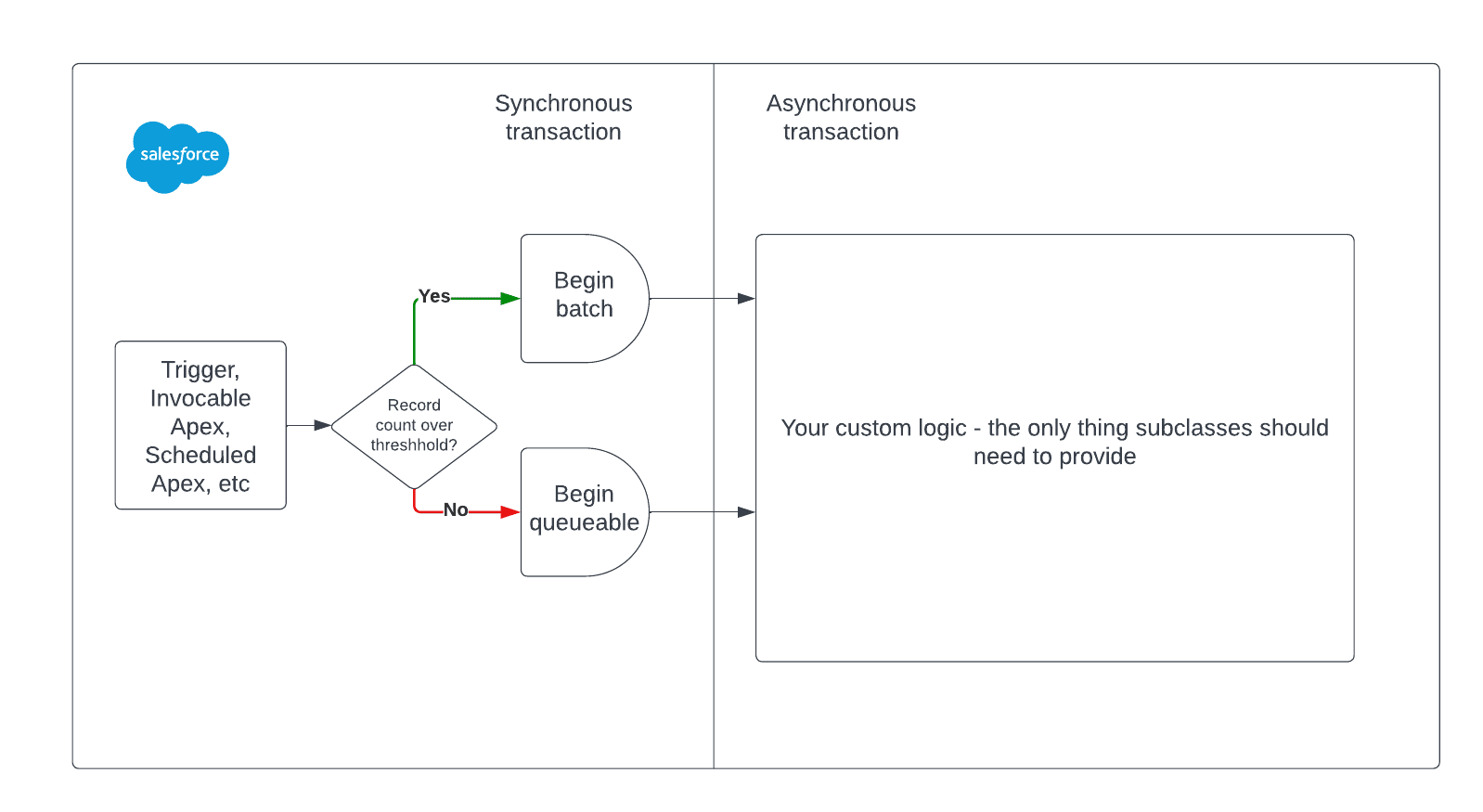
Estas limitaciones pueden ayudar a informar el diseño general de la abstracción compartida. Por ejemplo, debe tener una forma de interactuar con esta clase antes de que comience a procesar registros de forma asíncrona: este es el lugar perfecto para una interfaz.
Dado que la clase Batchable debe ser la clase externa, primero puede implementar Process allí.
No se preocupe demasiado por las variables de instancia de query y records , entrarán en juego pronto. Las partes cruciales de lo anterior son:
- La clase
AsyncProcessorestá marcada como abstracta. - El método
innerExecutetambién es abstracto. - Se han definido los métodos necesarios para
Database.Batchable - Se ha definido el método
kickoff, que satisface la interfaz deProcess
Al inicializar una nueva subclase de DataProcessor y luego llamar al método get , recibe una instancia de la interfaz DataProcessor.Process :
- Ya sea proporcionando una consulta basada en cadenas
- O proporcionando una lista de registros
this.getLimitToBatch(); Process process = this; if (shouldBatch == false && this.getCanEnqueue()) { // AsyncProcessorQueueable will be shown next process = new AsyncProcessorQueueable( this ); } return process; } protected virtual Integer getLimitToBatch() { return Limits.getLimitQueryRows(); } private Boolean getCanEnqueue() { // only one Queueable can be started per async transaction return this.hasBeenEnqueuedAsync == false || (this.isAsync() == false && Limits.getQueueableJobs()
La parte más importante de lo anterior es este extracto:
this.getLimitToBatch(); «>
El booleano shouldBatch descarta si se trata o no de un lote o de un proceso en cola que termina arrancando.
Finalmente, la implementación de AsyncProcessorQueueable :
El queueable también puede implementar la interfaz System.Finalizer , que le permite manejar errores de manera consistente utilizando solo un controlador de eventos de plataforma para BatchApexErrorEvent :
jobScopeLengthLimit, ExceptionType = fc.getException().getTypeName(), JobScope = this.getSafeSubstring( fullLengthJobScope, jobScopeLengthLimit ) .removeEnd(‘,’), Message = this.getSafeSubstring( fc.getException().getMessage(), textFieldLengthLimit ), Phase = ‘EXECUTE’, StackTrace = this.getSafeSubstring( fc.getException().getStacktraceString(), textFieldLengthLimit ) ); firedErrorEvent = errorEvent; EventBus.publish(errorEvent); } private List getRecordsInScope() { List scope = new List(); for ( Id recordId : new Map(this.processor.records).keySet() ) { scope.add(recordId); } return scope; } private String getSafeSubstring(String target, Integer maxLength) { return target.length() > maxLength ? target.substring(0, maxLength) : target; }
} «>
En resumen, la idea general es que las subclases extenderán la clase externa AsyncProcessor , lo que las obliga a definir el método abstracto innerExecute .
- Luego pueden llamar a
kickoffpara iniciar su proceso sin tener que preocuparse por los límites de consulta o qué marco asíncrono utilizará la plataforma subyacente.- Todos los límites de la plataforma, como solo poder iniciar una cola por transacción asíncrona, se manejan automáticamente por usted.
<dx-code-block title language="apex" code-block=" private Boolean getHasAlreadyEnqueued() { return this.isAlreadyAsync || (System.isQueueable() == false && System.isBatch() == false && System.isFuture() == false && Limits.getQueueableJobs()
-
- Ya no tiene que preocuparse por cuántos registros recupera una consulta determinada; el proceso se procesará automáticamente por lotes si, de lo contrario, corre el riesgo de exceder el límite de filas de consulta por transacción.
this.getLimitToBatch(); Process process = this; if (shouldBatch == false && this.getHasAlreadyEnqueued() == false) { process = new AsyncProcessorQueueable( this ); } return process;
} «>
-
- Las subclases pueden optar por implementar cosas como
Database.StatefulyDatabase.AllowsCalloutscuando sea necesario para sus propias implementaciones. Dado que estas son interfaces de marcador y no requieren una subclase para implementar métodos adicionales, es mejor que solo las subclases que necesitan absolutamente esta funcionalidad opten por esa funcionalidad (en lugar de que siempre se implementen enAsyncProcessor).
- Las subclases pueden optar por implementar cosas como
Debido a que, de forma predeterminada, las subclases solo tienen que definir su propia innerExecute de ejecución interna, usted se libera de todas las demás ceremonias que normalmente vienen con la creación de clases independientes que se pueden procesar en Batchable y Queueable . La lógica que es específica de su implementación, como hacer un seguimiento de cuántas llamadas se han realizado si está haciendo algo como una llamada por registro, aún debe implementarse y probarse.
Aquí hay un ejemplo más complicado que muestra cómo reiniciar recursivamente el proceso si supera el límite de llamada:
<dx-code-block title language="apex" code-block="public class BulkSafeHttpProcessor extends AsyncProcessor implements Database.AllowsCallouts { protected override void innerExecute(List records) { while (records.isEmpty() == false && Limits.getCallouts()
Como otro ejemplo de interfaz de marcador, así es como se ve el uso de Database.Stateful :
Note la completa falta de ceremonia en ambos ejemplos. Una vez que tenga todos los bits complicados en AsyncProcessor , puede concentrarse únicamente en la lógica. Esto realmente ayuda a mantener sus clases pequeñas y bien organizadas.
Prueba unitaria del procesador asíncrono
Aquí, solo mostraremos una prueba que demuestra que una subclase de AsyncProcessor se procesa automáticamente por lotes cuando se supera el límite configurado para la cola. Podrá acceder a todas las pruebas visitando el repositorio de este proyecto.
Conclusión
El patrón AsyncProcessor nos permite centrarnos en implementar nuestra lógica asíncrona sin tener que especificar directamente cómo se realiza el trabajo. Los usuarios más avanzados de este patrón pueden preferir anular información como el tamaño del lote, o permitir cosas como compartir o no contextos de consulta. Si bien hay muchos matices adicionales que se pueden considerar, este patrón es una excelente receta que también se puede usar tal cual siempre que necesite usar Apex asíncrono. Consulte el código fuente completo para obtener más información.
Sobre el Autor

James Simone es un miembro principal del personal técnico de Salesforce y ha estado desarrollando en la plataforma de Salesforce desde 2015. Ha estado blogueando desde finales de 2019 sobre el tema de Apex, Flow, LWC y más en The Joys of Apex . Cuando no está escribiendo código, le gusta escalar rocas, hornear pan de masa fermentada y correr con su perro. Anteriormente escribió en su blog sobre el patrón AsyncProcessor en la publicación The Joys of Apex: Batchable & Queueable Apex.
Obtenga las últimas publicaciones de blog de desarrolladores de Salesforce y episodios de podcast a través de Slack o RSS.
Agregar a Slack Suscríbete a RSS

…
Esta es una traducción realizada por EGA Futura, y este es el link a la publicación original: https://developer.salesforce.com/blogs/2023/02/exploring-a-combined-async-apex-framework.html