En nuestra serie de preguntas y respuestas «Engineering Energizers», exploramos las trayectorias de los líderes de ingeniería que han alcanzado logros significativos en sus respectivos campos. Hoy, destacamos a Claire Cheng, Vicepresidenta de Ciencia de datos e ingeniería y líder del equipo de la Fundación Einstein en Salesforce. El equipo de Claire mejora el servicio al cliente con el sistema Retrieval Augmented Generation (RAG) integrado en Data Cloud, transformando texto no estructurado en formatos de búsqueda para una recuperación y generación de información eficientes.
Explore los obstáculos técnicos a los que se enfrentó el equipo de Claire y las continuas mejoras que están implementando en función de los comentarios de los usuarios.
Data Cloud
¿Cuál es la misión de tu equipo?
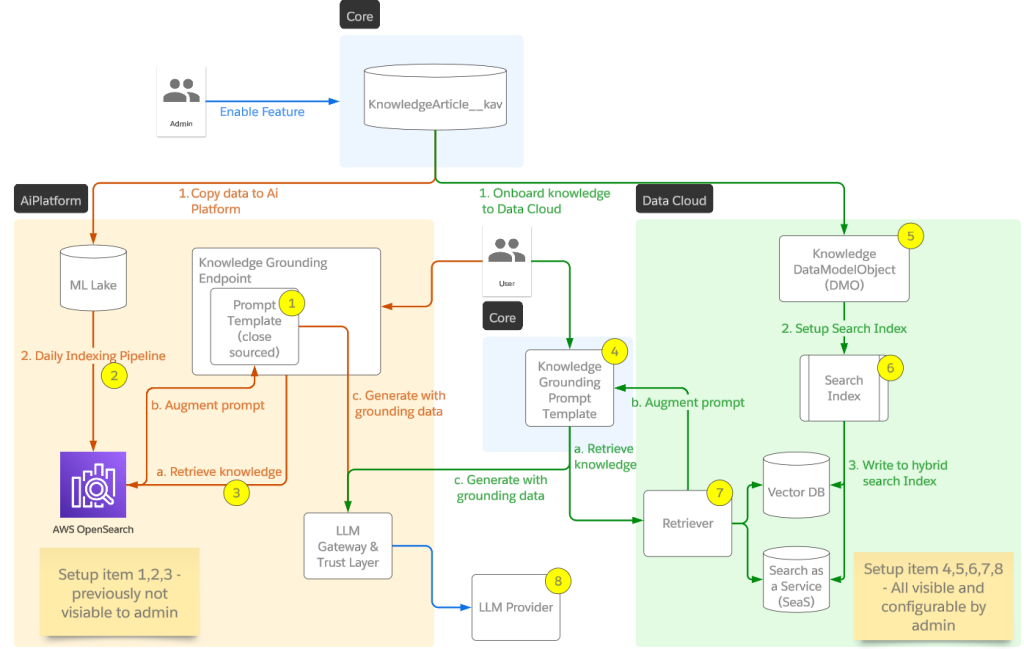
El equipo se dedica a desarrollar capacidades fundacionales de IA generativa que mejoren el CRM de IA líder del sector de Salesforce a través de servicios y modelado de IA, aplicaciones de IA generativa basadas en la nube y copilotos. Un objetivo clave de nuestros esfuerzos es mejorar las experiencias de los clientes mediante la integración de RAG con Data Cloud. Esta integración transforma el texto no estructurado en información que permite realizar búsquedas, aprovechando el sólido marco de Data Cloud para la ingestión, transformación e indexación de datos.
Data Cloud es una solución de gestión de datos que permite a los clientes realizar búsquedas en texto no estructurado
Al procesar datos sin procesar y convertirlos en conocimiento e información procesables, RAG permite una recuperación rápida y eficiente de la información relevante durante las interacciones con los clientes. Esto no sólo mejora la experiencia del cliente, sino que también refuerza la capacidad de la IA generativa para proporcionar respuestas más relevantes y precisas mediante la incorporación de un contexto de base adicional. El equipo se compromete a perfeccionar continuamente esta integración y a desarrollar nuevas mejoras para crear un sistema RAG modular más completo, escalable y mensurable.
¿Podría compartir con nosotros un ejemplo práctico de cómo funciona el sistema RAG?
Por ejemplo, si un cliente minorista pregunta sobre una política de devoluciones, RAG puede formular automáticamente una o varias consultas precisas basadas en la pregunta del usuario y el contexto, recuperar el conocimiento relevante de Data Cloud, ensamblar y comprimir los contenidos recuperados e instruir al modelo de gran lenguaje (LLM) para que genere una respuesta coherente. Esto acelera los tiempos de respuesta al tiempo que garantiza la precisión y la relevancia.
La integración de RAG en Data Cloud ha introducido mayores oportunidades de personalización para la recuperación de información, lo que permite a los usuarios adaptar la forma en que se ingieren, transforman y utilizan los datos. Además, los recuperadores se exponen de forma nativa en Prompt Builder, que permite a los usuarios configurar los objetos de consulta y los requisitos dentro del proceso de ingeniería de consultas. De este modo, RAG deja de ser un sistema cerrado y se convierte en una función transparente y configurable dentro del ecosistema de Salesforce.
RAG en Data Cloud mejoró la calidad y la personalización a escala.
¿Cuáles fueron los principales retos a los que se enfrentó su equipo a la hora de integrar y personalizar RAG para su uso con Data Cloud?
La integración y personalización de RAG para su uso con Data Cloud supuso varios retos importantes, centrados principalmente en la adaptación del sistema para mejorar la compatibilidad de los datos y las capacidades de procesamiento de IA. Inicialmente, la transición nos exigió transformar RAG de un sistema cerrado construido para Service GPT a un sistema más abierto y configurable en Data Cloud. Esta adaptación fue crucial para manejar una gama más amplia de fuentes de datos de entrada y para dar a los usuarios un mayor control sobre el procesamiento de datos.
Data Cloud
Para lograrlo, mejoramos nuestros procesos de ingesta y transformación de datos, que no solo proporcionaban una mayor flexibilidad, sino que también garantizaban que RAG pudiera comunicarse eficazmente con la infraestructura de Data Cloud. También desarrollamos nuevos adaptadores para traducir los formatos de datos de Data Cloud a formas utilizables por nuestros modelos de IA, solucionando así los problemas de compatibilidad.
Además, nos centramos en aportar más IA a los pasos de comprensión y preprocesamiento de datos a través de diversos tipos y estructuras de datos en Data Cloud. Estas mejoras en el preprocesamiento (como la optimización de trozos, la indexación aumentada, etc.) fueron esenciales para mantener el rendimiento y la precisión del sistema, garantizando que RAG pudiera seguir recuperando información relevante y precisa en el nuevo marco. Estas adaptaciones fueron clave para integrar con éxito RAG con Data Cloud, permitiendo que el sistema funcionara eficientemente en su nuevo entorno.
Durante la personalización de RAG con Data Cloud, ¿hubo algún problema inesperado?
Durante la personalización de RAG para Data Cloud, un problema inesperado que surgió fue la escala de procesamiento de datos. Data Cloud maneja una enorme cantidad de datos, y optimizar RAG para procesarlos de forma eficiente sin sacrificar el rendimiento supuso un reto importante. Para resolverlo, empleamos una estrategia de pruebas exhaustivas y mejoras iterativas. Nuestro equipo llevó a cabo un importante rediseño del canal de procesamiento de datos, lo que permitió la inferencia de modelos de IA en línea, y ajustó los algoritmos de IA para manejar mejor grandes volúmenes de datos.
Con el enfoque iterativo, fuimos capaces de encontrar gradualmente el equilibrio óptimo entre rendimiento y precisión, asegurando que RAG pudiera funcionar eficazmente dentro del marco robusto de Data Cloud.
Preguntas frecuentes
¿Podría comentar algún comentario de los usuarios o algún reto operativo que haya surgido después de implementar RAG con Data Cloud?
Tras el despliegue de RAG en Data Cloud, aprovechamos la oportunidad para perfeccionar el sistema basándonos en los comentarios de los usuarios. Los usuarios expresaron su agradecimiento por la mayor transparencia y control proporcionados por la integración de Data Cloud, pero también destacaron la necesidad de un proceso de configuración más fácil de usar. Estos comentarios fueron muy valiosos, ya que impulsaron nuestro compromiso de hacer que el sistema sea accesible para todos los usuarios, independientemente de su experiencia en datos o IA.
Datos en la nube
En respuesta, nuestro equipo dedicó esfuerzos a mejorar la experiencia del usuario mediante el desarrollo de interfaces más intuitivas y la mejora de la documentación. Estas mejoras tenían como objetivo simplificar el proceso de incorporación y permitir a los usuarios aprovechar todas las capacidades de RAG con mayor eficacia. Nos entusiasmaron estas mejoras continuas y mantuvimos nuestro compromiso de hacer evolucionar continuamente el sistema para satisfacer las necesidades de nuestros usuarios.
Además, estamos explorando el desarrollo de herramientas automatizadas que puedan ayudar a los usuarios a establecer, probar y gestionar sus configuraciones de RAG y a supervisar el rendimiento de RAG más fácilmente. Esta iniciativa forma parte de nuestro esfuerzo continuo por hacer de RAG no sólo una herramienta potente, sino también accesible y fácil de usar para un abanico más amplio de usuarios.
Preguntas frecuentes
Más información
- ¿Hambre de más historias de Data Cloud? Lea este blog para conocer la fórmula secreta de Data Cloud para procesar un cuatrillón de registros al mes.
- Manténgase en contacto: únase a nuestra Comunidad de talentos!
- Consulta nuestros equipos de Tecnología y Producto para saber cómo puedes participar.