UniControl es aceptado en NeurIPS’23.
¿Es posible que un único modelo domine el arte de crear imágenes a partir de bocetos, mapas, diagramas y mucho más? Aunque los generadores de texto a imagen basados en la difusión, como DALL-E-3, han mostrado resultados notables a partir de instrucciones en lenguaje natural, lograr un control preciso de los diseños, los límites y la geometría sigue siendo un reto utilizando sólo descripciones de texto. Ahora, los investigadores han desarrollado UniControl, un modelo unificado capaz de manejar diversas condiciones visuales que van desde los bordes hasta los mapas de profundidad dentro de un marco unificado.

Background
La síntesis de texto a imagen (T2I) se ha disparado recientemente gracias a los avances en modelos generativos profundos. Sistemas como DALL-E 2, Imagen y Stable Diffusion pueden generar ahora imágenes de gran realismo fotográfico controlables mediante instrucciones de lenguaje natural. Estos avances se basan en modelos de difusión que han demostrado ser extremadamente eficaces para la generación de texto a imagen.
Sin embargo, el control mediante indicaciones de texto apenas es preciso para los atributos espaciales, estructurales y geométricos. Por ejemplo, pedir «añadir un gran cubo morado» depende de la comprensión implícitamente aprendida del modelo sobre la geometría 3D. Enfoques recientes como ControlNet han introducido el condicionamiento a señales visuales adicionales, como mapas de segmentación o detecciones de bordes. Esto permite un control explícito de las regiones de la imagen, los límites, la ubicación de los objetos, etc.
Pero cada modelo ControlNet sólo maneja una condición visual específica, como los bordes o los mapas de profundidad. Para ampliar las capacidades es necesario un reentrenamiento exhaustivo. La compatibilidad con diversas entradas controlables requiere el desarrollo de modelos especializados para cada tarea. Esto sobrecarga los parámetros, limita el intercambio de conocimientos y dificulta la adaptación entre modalidades o la generalización fuera del dominio.
Motivación
Existe una necesidad acuciante de modelos unificados que puedan manejar diversas condiciones visuales para la generación controlable. La consolidación de las capacidades en un único modelo mejoraría enormemente la eficiencia de la formación y el despliegue sin necesidad de múltiples modelos específicos para cada tarea. También permite explotar las relaciones entre condiciones, como la profundidad y la segmentación, para mejorar la calidad de la generación.
Por ejemplo, la estimación de la profundidad depende en gran medida de la comprensión de la segmentación semántica y el diseño global de la escena. Un modelo unificado puede aprovechar mejor estas relaciones en comparación con los modelos de tareas aisladas. Además, añadir nuevas modalidades a modelos individuales conlleva un reentrenamiento masivo, mientras que un enfoque consolidado podría generalizarse sin problemas.
El principal reto consiste en superar el desajuste entre diversas condiciones como bordes, poses, mapas, etc. Cada una de ellas requiere operaciones especializadas en función de sus características. Mezclar trivialmente diversas entradas en un modelo falla debido a este desajuste de características. El objetivo es desarrollar una arquitectura unificada que generalice las tareas y adapte sus componentes condicionantes. Y lo que es más importante, esto debe lograrse sin necesidad de un reentrenamiento exhaustivo cada vez que se amplíen las capacidades.
Methods
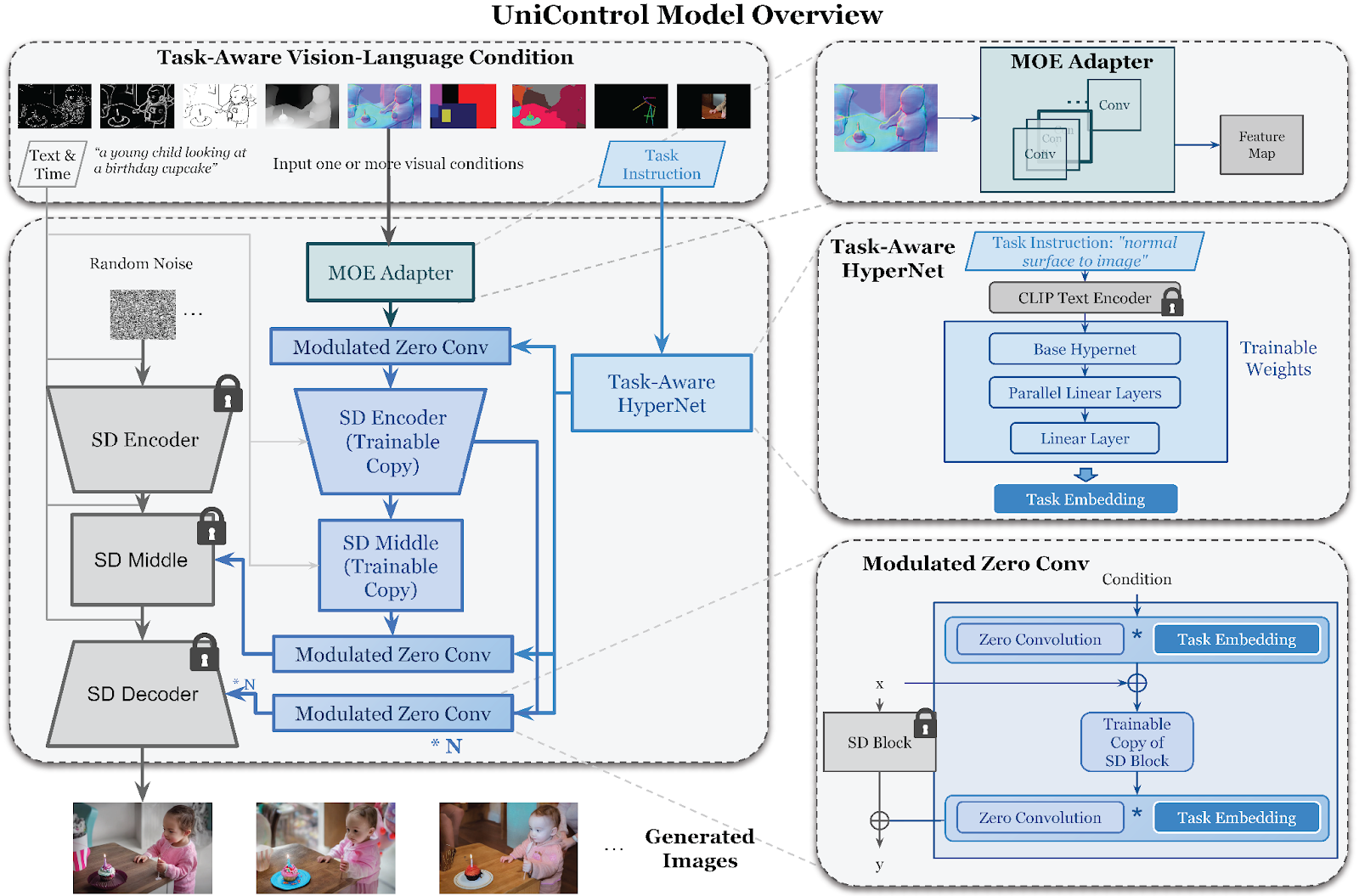
El UniControl propuesto introduce dos nuevos componentes para permitir la generación unificada controlable multitarea:
1. Adaptadores de Mezcla de Expertos. Adaptadores de mezcla de expertos: Módulos convolucionales paralelos, uno por tarea, que se adaptan a las características visuales de cada condición.
2. Task-Aware HyperNetwork: Modula dinámicamente los núcleos de convolución de un modelo base en función de las instrucciones de la tarea.
UniControl se ha entrenado en doce tareas distintas que abarcan bordes, regiones, mapas y mucho más. La arquitectura general del modelo se mantiene constante en todas las tareas, mientras que los componentes de acondicionamiento se especializan.
Adaptadores-mezcla-de-expertos
Los adaptadores proporcionan vías específicas para que cada tarea procese sus características visuales de forma adecuada. De este modo se supera el desajuste entre diversas condiciones que necesitan un tratamiento especializado.
Por ejemplo, una ruta de mapa de segmentación se centra más en las relaciones semánticas espaciales que en la geometría 3D. Por el contrario, un adaptador de profundidad hará hincapié en la disposición global y las orientaciones de las superficies. Con adaptadores separados por tarea, UniControl puede extraer representaciones matizadas adaptadas a cada tipo de entrada.
Esta modularización imita una mezcla de expertos. Cada adaptador actúa como un «experto» especializado para su tarea. Las vías paralelas evitan los objetivos contradictorios que surgirían de un manejo enredado de todas las condiciones. El modelo compone dinámicamente las salidas de los adaptadores relevantes en función de la tarea de entrada.
Hiperred consciente de la tarea
La hiperred permite la modulación dinámica de UniControl en función de la tarea especificada. Introduce instrucciones como «mapa de profundidad a imagen» y emite vectores de incrustación. Estas incrustaciones pueden especializar el modelo modulando sus núcleos de convolución en función de la tarea.
Por ejemplo, el condicionamiento de la profundidad puede modular las primeras capas para centrarse más en el diseño global y la geometría. Mientras tanto, la adaptación de los bordes puede enfatizar los detalles de mayor frecuencia en las etapas posteriores. La hiperred permite a UniControl aprender la comprensión y el procesamiento especializados de cada tarea y, al condicionar las instrucciones, también permite la generalización a nuevas tareas en el momento de la prueba. Las relaciones aprendidas durante el entrenamiento multitarea permiten una modulación sensible incluso para tareas desconocidas. La composición de incrustaciones de tareas conocidas relacionadas facilita la transferencia sin disparos.
Experimentos
UniControl se entrenó en un conjunto de datos MultiGen-20M con más de 20 millones de tripletas imagen-texto-condición. Los principales resultados demostraron:
- Supera a ControlNets de una sola tarea en la mayoría de las tareas, beneficiándose del entrenamiento conjunto. El diseño unificado mejora la eficiencia.
- Se generaliza a tareas híbridas no vistas como profundidad+pose sin reentrenamiento mediante la composición de adaptadores.
- UniControl mantiene 1,4B parámetros mientras que un conjunto de modelos de una sola tarea (es decir, Multi-ControlNet) requeriría más de 4B parámetros.
- La transferencia de cero disparos a nuevas tareas como la coloración y el inpainting se consigue mezclando adaptadores de tareas relacionadas.


Demostración en vídeo
Explore More
arXiv: https://arxiv.org/abs/2305.11147
Código: https://github.com/salesforce/UniControl
Web: https://canqin001.github.io/UniControl-Page/
HF Space: https://huggingface.co/spaces/Robert001/UniControl-Demo
Contacto: [email protected]