TLDR
El SFR-Embedding-Mistral marca un avance significativo en los modelos de incrustación de texto, construyéndose sobre los sólidos cimientos de E5-mistral-7b-instruct y Mistral-7B-v0.1.
Las principales conclusiones son:
- SFR-Embedding-Mistral ocupa el primer lugar en rendimiento de incrustación de texto en el MTEB (puntuación media de 67,6, en 56 conjuntos de datos), alcanzando resultados de vanguardia.
- El modelo muestra una mejora sustancial en el rendimiento de la recuperación, pasando de una puntuación de 56,9 para E5-mistral-7b-instruct a una impresionante puntuación de 59,0.
- En tareas de agrupación, el modelo SFR-Embedding-Mistral muestra una notable mejora absoluta de +1,4 en comparación con E5-mistral-7b-instruct.4 en comparación con E5-mistral-7b-instruct.
Punto de control del modelo: https://huggingface.co/Salesforce/SFR-Embedding-Mistral
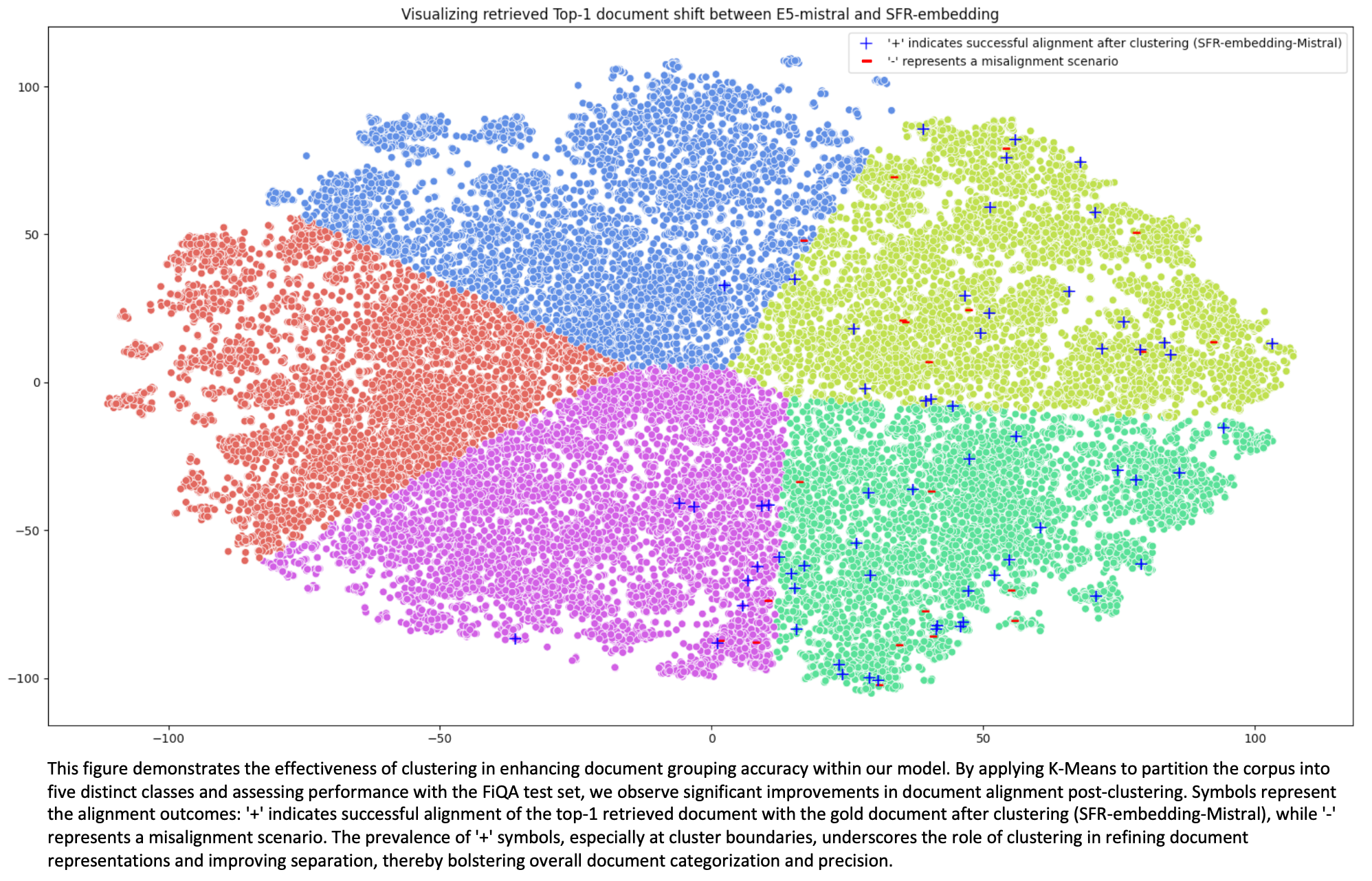
Detalles del entrenamiento
El modelo SFR-Embedding-Mistral se entrena con datos de diversas tareas. Para las tareas de recuperación, utiliza datos de MS-MARCO, NQ, FiQA, SciFact, NFCorpus, DBPedia, FEVER, HotpotQA, Quora y NLI. Las tareas de agrupación utilizan datos de arXiv, bioRxiv y medRxiv, aplicando filtros para excluir los conjuntos de desarrollo y prueba en el marco de agrupación MTEB. El modelo utiliza conjuntos de datos de AmazonReview, Emotion, MTOPIntent, ToxicConversation y TweetSentiment para la clasificación. En el ámbito de la similitud textual semántica (STS), se entrena con STS12, STS22 y STSBenchmark, mientras que para las tareas de reordenación utiliza datos de SciDocs y StackOverFlowDupQuestions. Empleamos la pérdida contrastiva, utilizando negativos por lotes junto con tareas de clasificación y agrupación por expectativas. Tratamos las etiquetas como documentos para estas tareas específicas y aplicamos la pérdida contrastiva exclusivamente a sus respectivos negativos, omitiendo los negativos por lotes. Los experimentos que presentamos a continuación muestran los resultados obtenidos en el dev set del benchmark MTEB.
Realizamos un ajuste fino del modelo e5-mistral-7b-instruct utilizando un tamaño de lote de 2.048, una tasa de aprendizaje de 1e-5 y una fase de calentamiento de 100 pasos seguida de un decaimiento lineal. Cada par consulta-documento se agrupa con 7 hard negatives. La longitud máxima de las secuencias es de 128 para las consultas y 256 para los documentos. Este proceso de ajuste tardó aproximadamente 15 horas en 8 GPUs A100. Se añaden adaptadores LoRA con rango r=8 a todas las capas lineales, lo que da como resultado 21M de parámetros entrenables. Nuestra implementación se basa en la biblioteca PEFT HuggingFace de https://github.com/huggingface/peft.
El entrenamiento multitarea beneficia la generalización
Hemos observado que los modelos de incrustación experimentan una mejora sustancial en el rendimiento de recuperación cuando se integran con tareas de agrupamiento, y su eficacia puede mejorarse aún más mediante la transferencia de conocimientos de múltiples tareas. Al orientar explícitamente los documentos hacia etiquetas de alto nivel, el entrenamiento con datos de agrupación permite a los modelos de incrustación navegar y recuperar información con mayor eficacia. Aunque los tres conjuntos de datos de agrupación proceden del ámbito científico, la incorporación de formación adicional en agrupación produce mejoras significativas en todas las tareas. Nuestra hipótesis es que las etiquetas de agrupamiento animan a los modelos a regularizar las incrustaciones basándose en conceptos de alto nivel, lo que resulta en una mejor separación de los datos en diferentes dominios.
Además, la generalización puede reforzarse empleando entrenamiento multitarea y adaptando los modelos a tareas específicas. Este enfoque no sólo mejora la precisión de los resultados de búsqueda, sino que también garantiza la adaptabilidad de los modelos a diversos dominios y tareas, lo cual es crucial para los escenarios de aplicación del mundo real.
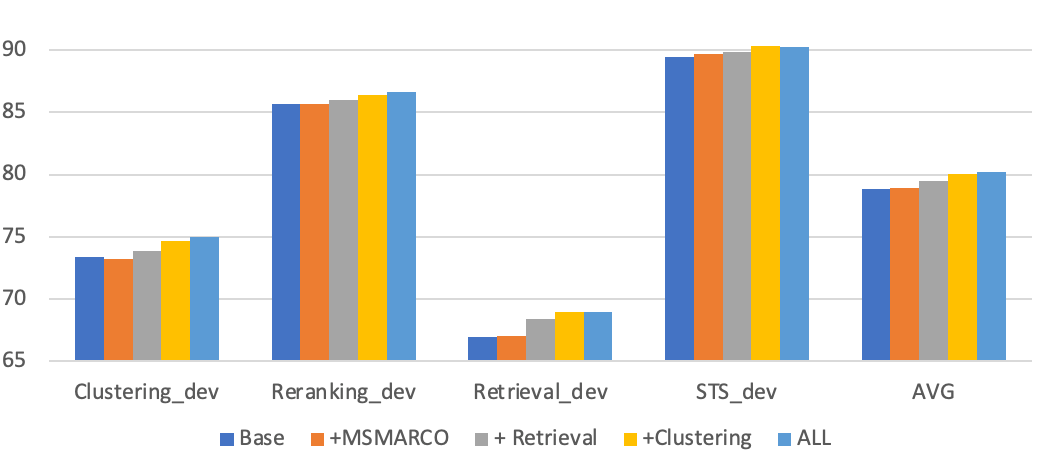
Lotes homogéneos de tareas
Los lotes homogéneos de tareas son otro factor que contribuye al rendimiento de nuestros modelos. Esta técnica construye lotes compuestos exclusivamente por muestras de una única tarea. En consecuencia, el negativo dentro del lote se vuelve más desafiante a medida que otros ejemplos dentro del lote se asemejan mucho al escenario del caso de prueba. Los resultados experimentales ponen de relieve una notable mejora en las tareas de recuperación con lotes homogéneos de tareas, en particular un aumento de 0,8 puntos.
| Loteo intercalado | Off | On |
| Clustering_dev | 75.29 | 75.04 |
| Reranking_dev | 86,57 | 86,54 |
| Retrieval_dev | 68,2 | 69.02 |
| STS_dev | 89,81 | 90,3 |
| AVG | 79,97 | 80,23 |
Impacto de los negativos duros
Una técnica eficaz para entrenar modelos de incrustación es utilizar «negativos duros»: puntos de datos que suponen un reto para los modelos a la hora de distinguirlos de los positivos. Por defecto, utilizamos el modelo BGE-base para extraer los negativos duros.
Estrategia para eliminar los falsos negativos
Al inspeccionar los negativos extraídos, una parte considerable parecen ser falsos negativos, lo que significa que son semánticamente idénticos a los documentos positivos correspondientes pero tratados erróneamente como negativos. Una estrategia para seleccionar de forma precisa y eficiente los negativos duros es crucial para el entrenamiento de incrustación, ya que ayuda a los modelos a identificar los documentos más relevantes para una consulta.
Los resultados indican que el rango de 30 a 100 produce un mejor rendimiento. Esto implica que los documentos mejor clasificados (0-100) pueden incluir algunos falsos negativos, mientras que los peor clasificados (50-100) carecen de suficiente desafío. Por lo tanto, encontrar el equilibrio adecuado entre estos factores es importante en la formación contrastiva
| Rango de selección de negativos | 0-100 | 30-100 | 50-100 |
| Clustering_dev | 74.6 | 75,04 | 74,91 |
| Reranking_dev | 86.57 | 86,54 | 86,45 |
| Retrieval_dev | 68,99 | 69,02 | 69/td> | STS_dev | 90.17 | 90,3 | 90,24 |
| AVG | 80,08 | 80,225 | 80,15 |
Número de negativos duros
La cantidad de negativos duros utilizados en el aprendizaje contrastivo puede afectar significativamente a la dinámica de aprendizaje del modelo. Incluir más negativas duras permite al modelo diferenciar distinciones más sutiles, mejorando potencialmente su capacidad de generalización. Sin embargo, nuestros hallazgos sugieren que el proceso de entrenamiento permanece relativamente estable independientemente del número de negativos duros utilizados.
| Número de negativos | #HN=1 | #HN=7 | #HN=15 | #HN=31 | #HN=31 | |||
| Clustering_dev | 74.96 | 75,04 | 75,11 | 75,07 | ||||
| Reranking_dev | 86,61 | 86.54 | 86,43 | 86,45 | ||||
| Retrieval_dev | 68,96 | 69,02 | 68,96 | 68,95 | 90.26 | 90,3 | 90,21 | 90,17 |
| AVG | 80,2 | 80,225 | 80,18 | 80,16 |
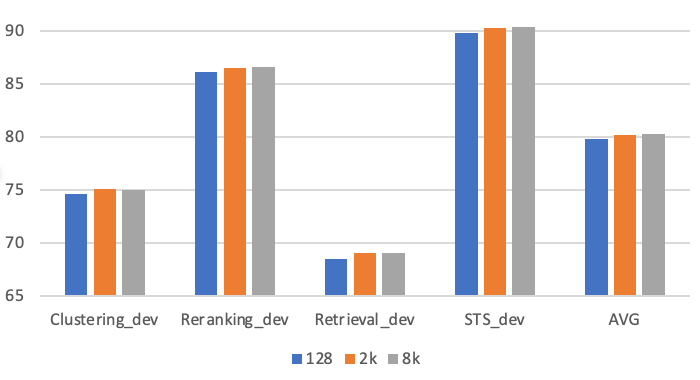
Impacto del tamaño del lote
La utilización de lotes de mayor tamaño ha demostrado ser ventajosa, principalmente debido a la inclusión de ejemplos negativos más desafiantes. Aprovechamos GradCache para facilitar el entrenamiento con lotes de gran tamaño. Realizamos experimentos con tamaños de lote de 128, 2.048 y 8.192 para evaluar el impacto del tamaño del lote. El uso de lotes de mayor tamaño (2.000+) produce una mejora considerable en comparación con los lotes de menor tamaño (p. ej., 128) utilizados habitualmente para el ajuste fino. Sin embargo, ampliar el tamaño del lote de 2048 a 8192 no supone ningún cambio significativo en el rendimiento.
Modelos de profesor para la minería de negativos duros
Es habitual utilizar modelos más avanzados para recopilar negativos duros difíciles. En nuestro estudio, empleamos cuatro modelos para investigar el impacto de los modelos de profesor en la minería de negativos duros, desde el modelo léxico clásico BM25 hasta modelos densos avanzados, como nuestro SFR-Embedding-Mistral. Los resultados indican que los modelos densos seleccionados sirven como modelos maestros superiores en comparación con BM25 y, en general, los modelos más potentes pueden producir negativos duros más eficaces (SFR-Embedding-Mistral > E5-Mistral > BGE-base). En el futuro, será interesante explorar el impacto del entrenamiento multirronda en dos frentes: (a) la minería de hard negatives (HN) con SFR-Embedding-Mistral, y (b) la utilización de los HN identificados para refinar y mejorar SFR-Embedding-Mistral.
En general, los modelos más potentes pueden producir hard negatives más eficaces (SFR-Embedding-Mistral > E5-Mistral > BGE-base)
Hard Negative Mining |
BM25 | BGE-base | E5-mistral | SFR-Embedding-Mistral | |
| Clustering_dev | 75.07 | 75,04 | 75,04 | 75,45 | |
| Reranking_dev | 86.43 | 86,54 | 86,52 | 86,6 | |
| Retrieval_dev | 68,42 | 69,02 | 69,06 | 69,15 | |
| STS_dev | 90.11 | 90,3 | 90,3 | 90,24 | |
| 80,01 |
80,23 |
80,23 |
80,36 |
|
Impacto de la longitud del contexto
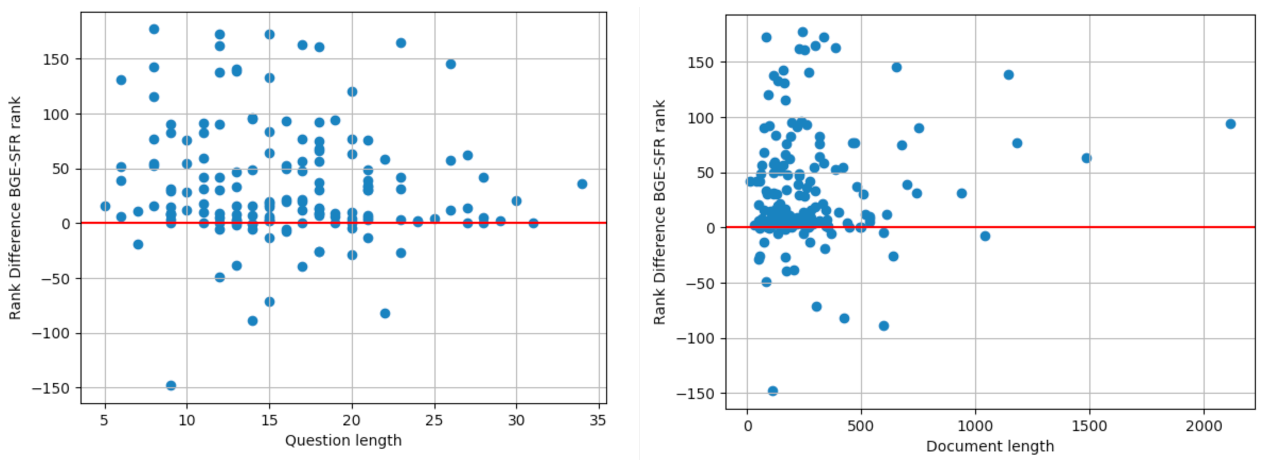
Mostramos la diferencia en la clasificación de los documentos positivos para el modelo BGE-large y nuestro modelo SFR-Embedding-Mistral en relación con la longitud de la consulta/pregunta (figura izquierda) y la longitud del documento (figura derecha). Más concretamente, el eje y representa el rango (documento-oro | BGE-large) – rango (documento-oro | SFR-Embedding-Mistral), lo que significa que cuanto mayor sea el valor absoluto, mayor será el contraste entre los dos modelos. En ambas figuras, el modelo SFR-Embedding-Mistral clasifica los documentos positivos mejor que el modelo BGE en general. Y lo que es más importante, observamos que a partir de un determinado umbral de longitud, es decir, 25 para las consultas y 700 para los documentos, es mucho menos probable que el modelo BGE clasifique el documento de oro mejor que el SFR-Embedding-Mistral, debido a la capacidad inherente de los LLM para representar contextos largos. Resulta especialmente atractivo para las aplicaciones posteriores de RAG, en las que es indispensable mantener intacta la estructura del documento. Por ejemplo, el sistema RAG mantiene la estructura de los documentos jurídicos largos durante el resumen mediante la comprensión y recuperación de varias secciones, lo que garantiza que el resumen capte con precisión la esencia del caso y el razonamiento jurídico, algo vital para los contextos jurídicos.
Evaluación completa en MTEB
MTEB (Massive Text Embedding Benchmark) es, con diferencia, la prueba de referencia más completa para evaluar modelos de incrustación, ya que abarca 56 conjuntos de datos de siete tipos de tareas: clasificación, agrupación, clasificación por pares, reordenación, recuperación, STS y resumen.
Según se desprende de la tabla de clasificación de MTEB (a 27 de febrero de 2024), SFR-Embedding-Mistral ocupa el primer puesto entre más de 150 modelos de incrustación, incluidos varios propios como voyage-lite-02-instruct, OpenAI text-embedding-3-large y Cohere-embed-english-v3.0. Destaca especialmente su rendimiento en tareas de recuperación, consideradas las más cruciales de todos los tipos de tareas MTEB. SFR-Embedding-Mistral sobresale con una puntuación media de 59,0, superando al modelo que ocupa el segundo lugar por un margen considerable (57,4). Este resultado subraya el excepcional rendimiento de nuestro modelo en diversas tareas y dominios.
Conclusión
SFR-Embedding-Mistral es el modelo mejor clasificado en la prueba comparativa MTEB, lo que se atribuye a varias innovaciones y estrategias fundamentales:
- El aprendizaje por transferencia de múltiples tareas, en particular la agrupación, mejora la adaptabilidad y el rendimiento del modelo.
- La agrupación homogénea de tareas aumenta la dificultad del objetivo contrastivo para el modelo, promoviendo una mayor generalización.
- La construcción de mejores negativos duros agudiza aún más la capacidad del modelo para discernir documentos engañosos discriminatorios.