Por Yuliya Feldman y Scott Nyberg
En nuestra serie de preguntas y respuestas «Engineering Energizers», examinamos las experiencias profesionales que han formado a los líderes de ingeniería de Salesforce. Conozca a Yuliya Feldman, arquitecta de ingeniería de software en Salesforce. Yuliya trabaja en el equipo de servicios de aprendizaje automático de Salesforce Einstein, responsable de poner en funcionamiento los modelos de IA, que sirven como motor de los productos de IA generativa de Salesforce.
Siga leyendo para saber cómo el equipo de Yuliya supera los retos críticos de ingeniería para ayudar a crear el futuro de la IA generativa.
¿Cuál es la misión de IA de tu equipo?
La misión del equipo es hacer que los modelos de IA sean operativos, es decir, permitirles dar soporte a escenarios del mundo real. Después de que los científicos de investigación creen sus modelos generativos de IA, nuestro equipo proporciona un marco de infraestructura rico en funciones para garantizar que los clientes tengan una ruta clara hacia el modelo correcto que les ayude a recibir rápidamente respuestas a sus consultas.
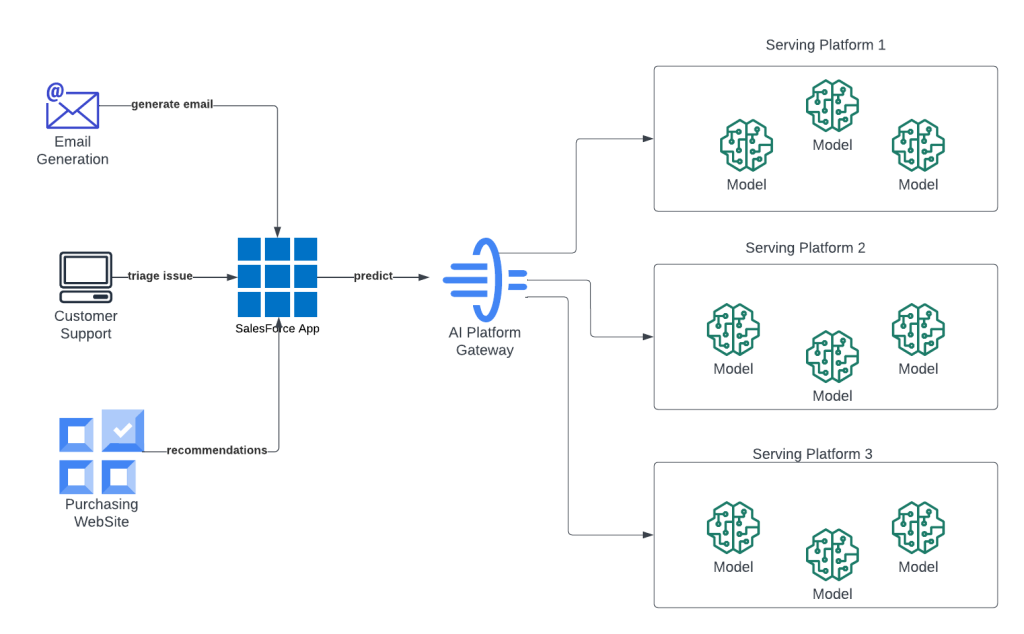
Una mirada a la plataforma de IA del equipo en acción.
¿Cómo define la operacionalización del modelo de IA?
La operacionalización de modelos se centra en transformar los modelos de aprendizaje automático entrenados en herramientas útiles para nuestros clientes. Esta transformación implica varias fases:
Almacenamiento del modelo: El archivo de datos del modelo entrenado -compuesto por pesos y metadatos necesarios durante el tiempo de inferencia que constituyen el conocimiento adquirido durante el entrenamiento- se almacena para su accesibilidad.
La operacionalización del modelo se centra en transformar los modelos de aprendizaje automático entrenados en herramientas útiles para nuestros clientes
Integración de código: el archivo de datos del modelo se combina con código adicional, que traduce los datos del modelo, descifra las acciones necesarias en función de los datos de entrada y proporciona los resultados a los clientes.
Acceso y registro: El modelo y su código relacionado deben registrarse, un proceso que especifica los atributos y ubicaciones para el acceso al modelo. Esto permite a los clientes utilizar los servicios del modelo.
Acceso y registro
Ejecución y escalado del modelo: La ejecución del modelo requiere el hardware y el software adecuados. Herramientas como AWS SageMaker, Triton y contenedores personalizados desempeñan un papel clave en la carga, ejecución y escalado eficiente de múltiples modelos o modelos de gran tamaño. La optimización del uso de la memoria y la incorporación de un enrutamiento inteligente también ayudan a impulsar el proceso de escalado.
¿Cómo contribuye tu equipo al proceso de operacionalización de modelos de IA?
Nuestro talentoso equipo agiliza el complejo proceso de operacionalización, garantizando que los modelos sean accesibles, escalables y ricos en funciones, satisfaciendo las necesidades específicas de los diversos casos de uso de los clientes. He aquí un vistazo a lo que hacemos:
- Carga de modelos: Proporcionamos canalizaciones y directrices para garantizar que los modelos se cargan sin problemas en nuestra infraestructura de servicio y están listos para su uso futuro.
- Carga de modelos:
- Personalización de la operación: Una vez cargados los modelos, las habilidades de resolución de problemas de nuestro equipo se ponen en marcha para optimizar la latencia, el rendimiento y la escalabilidad, personalizando cada operativa para satisfacer los requisitos específicos de los casos de uso de nuestros clientes.
- Personalización de la operativa
- Mejora de características. Normalmente, los distintos casos de uso requieren características distintas. En consecuencia, el equipo puede mejorar las capacidades de la plataforma para dar soporte a un nuevo conjunto de características.
- Para mejorar las capacidades de la plataforma para dar soporte a un nuevo conjunto de características.
- Para mejorar las capacidades de la plataforma para dar soporte a un nuevo conjunto de características
- Enrutamiento inteligente. Para dar soporte a instancias de múltiples modelos o casos de uso complicados que requieren la obtención y el procesamiento de datos antes de realizar predicciones, nuestro equipo desarrolla estrategias de enrutamiento inteligente, garantizando un enrutamiento sin fisuras y la ejecución de complejas canalizaciones de inferencias.
- Enrutamiento inteligente.
- Enrutamiento inteligente
- Producción: Una vez operacionalizado, el modelo pasa a producción, donde nuestro equipo aprovecha las alertas y los sistemas de monitorización para detectar cualquier problema y proporciona un triaje rápido para cualquier problema, colaborando con otros equipos si es necesario.
- Producción
¿Cuáles son un par de grandes retos de modelado de IA que tu equipo ha abordado recientemente?
Un reto clave al que nos enfrentamos fue ejecutar varias versiones del mismo modelo de IA para diferentes organizaciones arrendatarias de Salesforce. Esto nos obligaba a ejecutar las versiones simultáneamente y a garantizar que las solicitudes de cada inquilino se dirigían a la versión correcta del modelo. Para hacer frente a este reto, creamos una lógica adicional y colaboramos estrechamente con otros equipos de IA para gestionar el enrutamiento basado en la información de los inquilinos y los metadatos del modelo.
Otro reto fue la gestión de miles de modelos de IA. Proporcionar a cada modelo su propio punto final de contenedor es inviable debido a la tremenda cantidad de hardware que se necesitaría. Tampoco podíamos cargar miles de modelos en un contenedor debido a las limitaciones de memoria. En consecuencia, nuestro equipo dio un giro y distribuyó los modelos en varios contenedores compartidos. En última instancia, esto facilitó el enrutamiento eficaz de las consultas de datos de los clientes al contenedor correcto
¿A qué riesgos se enfrenta su equipo a la hora de implementar su solución para los clientes?
El equipo necesitaba diseñar nuestro marco de trabajo para que fuera escalable horizontalmente, soportando el rendimiento y la latencia. El rendimiento equivale al número de solicitudes que procesa el marco por unidad de tiempo. Mantener este equilibrio es un reto cuando la capacidad del marco se ve sobrecargada. En última instancia, con cada caso de uso, debemos apoyar una variedad de requisitos SLA.
Además, para mitigar los riesgos de rendimiento, realizamos periódicamente pruebas de rendimiento, planteándonos preguntas como:
- ¿Funciona nuestra solución según lo previsto?
- ¿Funciona nuestra solución según lo previsto?
- ¿Cómo podemos mejorar el rendimiento, especialmente al incorporar nuevas funciones?
Al centrarnos en estas preocupaciones, nuestro equipo analiza y adapta constantemente nuestro marco de trabajo para garantizar que satisfacemos las necesidades en constante evolución de nuestros clientes.
Preguntas frecuentes
¿Cómo ayuda su marco a mejorar la experiencia de IA generativa para los clientes?
Nos centramos en ofrecer una experiencia más fluida y satisfactoria a los clientes en el espacio de la IA generativa, donde la baja latencia es ahora un requisito clave.
La IA generativa es una de las tecnologías más avanzadas del mundo
Por ejemplo, en el campo de la generación de código de IA generativa, el proceso de consulta del cliente puede ser bastante largo. Algunas solicitudes tardan más de 20 segundos en ofrecer una respuesta, lo que provoca una experiencia de usuario menos satisfactoria. Este reto dio lugar a una nueva solicitud de funcionalidad: la posibilidad de transmitir respuestas en tiempo real. Esto permitiría a los clientes ver cómo se genera su respuesta línea por línea
Esto nos llevó a mejorar nuestro marco de trabajo para incluir las funciones de transmisión de respuestas de los servicios de servicio de modelos (por ejemplo, Triton Server, SageMaker), lo que nos permitirá ofrecer una experiencia muy fluida y en tiempo real a los clientes de IA generativa de Salesforce.
La capacidad de transmisión contrasta con nuestras otras API, que utilizaban un modelo síncrono de solicitud-respuesta que proporcionaba respuestas después de procesar la solicitud.