TL;DR: Presentamos una arquitectura novedosa, BootPIG, que permite la generación de imágenes personalizadas sin ningún ajuste fino en tiempo de prueba.
Periódico completo: https://arxiv.org/abs/2401.13974
Background
Los modelos de conversión de texto en imagen, como DALLE-3[1], Midjourney[2] y StableDiffusion[3], se han convertido en un potente medio para crear imágenes de alta calidad. Pero, ¿qué pasaría si quisiera crear una nueva imagen centrada en su perro? ¿O si fueras una empresa de zapatillas que quiere generar imágenes de alta calidad presentando su zapatilla más reciente? Dado que estos modelos se basan únicamente en la introducción de texto para el control, no conocerán las características específicas del sujeto y, por lo tanto, no conseguirán representar con precisión el perro o la zapatilla. Sin embargo, este problema de la generación basada en el sujeto, es decir, la generación de una imagen que contenga un sujeto deseado como el perro o la zapatilla, es una aplicación importante y potente de los modelos texto-imagen. Concretamente, la generación por temas permite a usuarios y empresas generar rápida y fácilmente imágenes que contengan un animal, un producto, etc. concretos, que pueden utilizarse para divertirse o para crear anuncios.
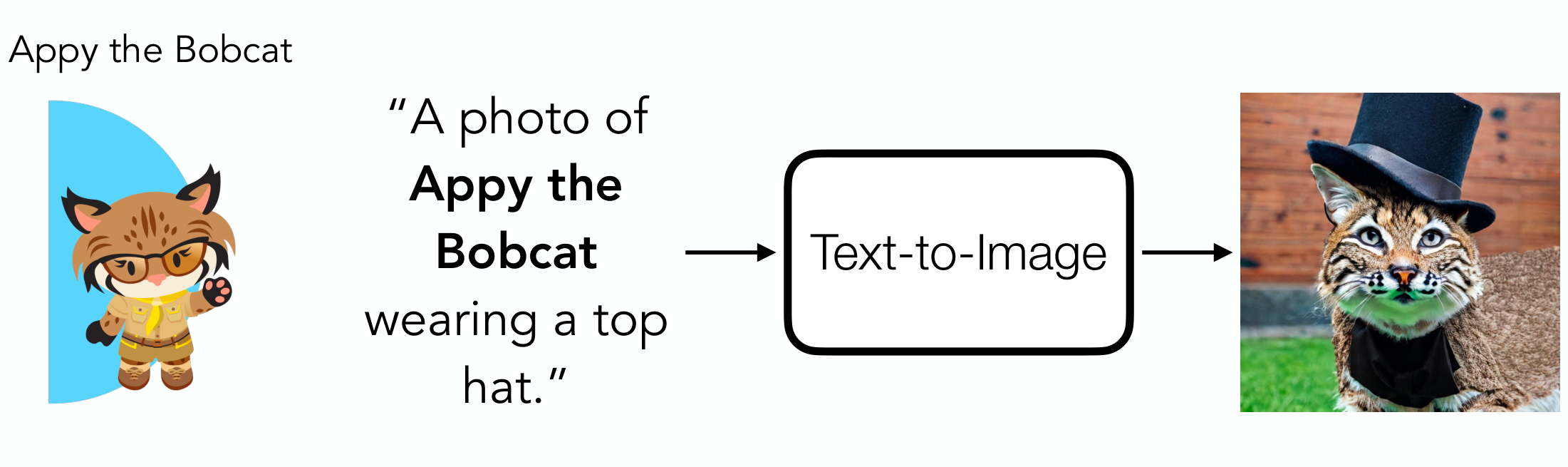
Para hacer frente a este problema, muchos métodos, como DreamBooth4, utilizan el ajuste fino en tiempo de prueba, que actualiza el modelo texto-imagen para aprender el sujeto objetivo. Estos métodos consumen mucho tiempo y deben volver a entrenarse para cada nuevo sujeto. Recientemente, trabajos como BLIP-Diffusion5 han intentado mitigar estos problemas permitiendo la generación basada en el sujeto cero, en la que un usuario puede proporcionar una imagen (o varias) de su sujeto objetivo y se pueden generar escenas novedosas que contengan el sujeto sin necesidad de entrenar el modelo para que aprenda específicamente su sujeto. Desgraciadamente, los métodos de generación basados en el sujeto cero no alcanzan el rendimiento de los enfoques ajustados al tiempo de prueba, como DreamBooth. Para cerrar esta brecha, presentamos BootPIG, una arquitectura que permite la generación basada en sujetos de última generación sin necesidad de un ajuste fino que consuma mucho tiempo.
Problema
¿Qué es la generación basada en sujetos de disparo cero? En términos sencillos, significa crear nuevas escenas que contengan un sujeto objetivo (por ejemplo, su perro o gato) sin entrenar el modelo de generación de imágenes específicamente para el sujeto. En este trabajo, presentamos una arquitectura y un método de preentrenamiento que dota a los potentes modelos texto-imagen de la capacidad de personalizar imágenes según un sujeto específico, sin necesidad de ningún ajuste.
Método: BootPIG
A continuación describimos: (1) la arquitectura de BootPIG y (2) un proceso de entrenamiento que permite a BootPIG generar imágenes sin necesidad de realizar disparos. La arquitectura de BootPIG se basa en modelos de texto a imagen preentrenados e introduce nuevas capas para permitir que el modelo preentrenado acepte imágenes del sujeto en el momento de la prueba. El proceso de formación entrena estas nuevas capas y permite así al modelo BootPIG generar imágenes del sujeto deseado sin ningún ajuste específico. Además, el proceso de entrenamiento de BootPIG no requiere imágenes reales del objeto y sólo dura una hora.
Arquitectura: La arquitectura de BootPIG comparte similitudes con la arquitectura de ControlNet6. En concreto, introducimos una copia de la arquitectura original de texto a imagen, a la que llamamos U-Net de referencia. La U-Net de referencia toma como entrada imágenes de referencia, por ejemplo, imágenes de su perro o gato, y aprende características que permiten a la arquitectura texto-a-imagen original, a la que llamamos U-Net de base, sintetizar el sujeto en la escena deseada. Además, añadimos operadores de autoatención de referencia (RSA) en lugar de las capas de autoatención de la U-Net base. El operador RSA realiza la operación de Atención entre las características de la U-Net Base (consulta) y la concatenación de las características de la U-Net Base y las características de la U-Net de Referencia (claves, valores). Durante el entrenamiento, la U-Net de base y la U-Net de referencia se entrenan conjuntamente. Todos los parámetros de la U-Net de referencia se actualizan, mientras que sólo se entrenan las capas RSA de la U-Net de base.
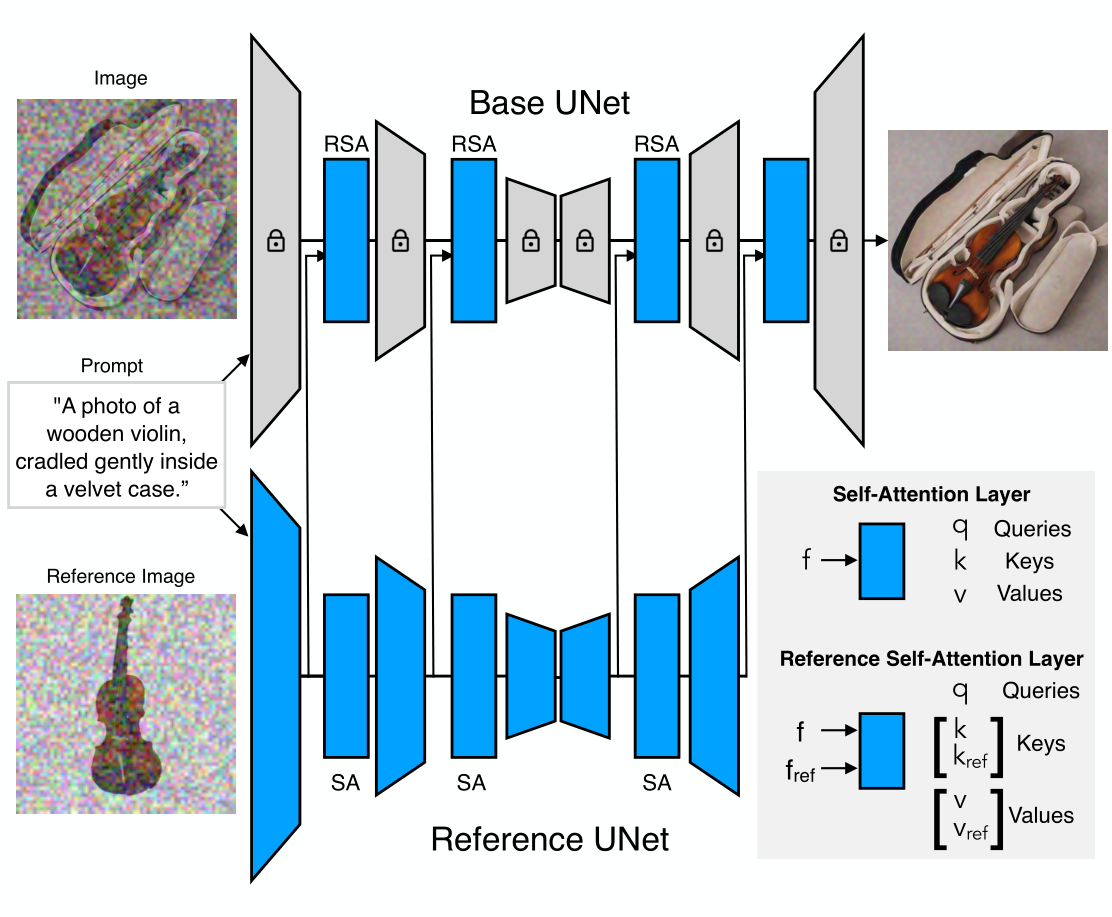
Datos: BootPIG se entrena íntegramente con datos sintéticos. Durante el entrenamiento, BootPIG requiere tripletas de la forma, (imagen, pie de foto, imagen de referencia). En primer lugar, utilizamos ChatGPT7 para generar leyendas para las imágenes potenciales. A continuación, utilizamos StableDiffusion para generar imágenes para cada uno de estos pies de foto. Por último, utilizamos Segment Anything8, un modelo de segmentación de última generación, para segmentar el sujeto en cada imagen y utilizamos esta parte segmentada de la imagen como imagen de referencia.
Results
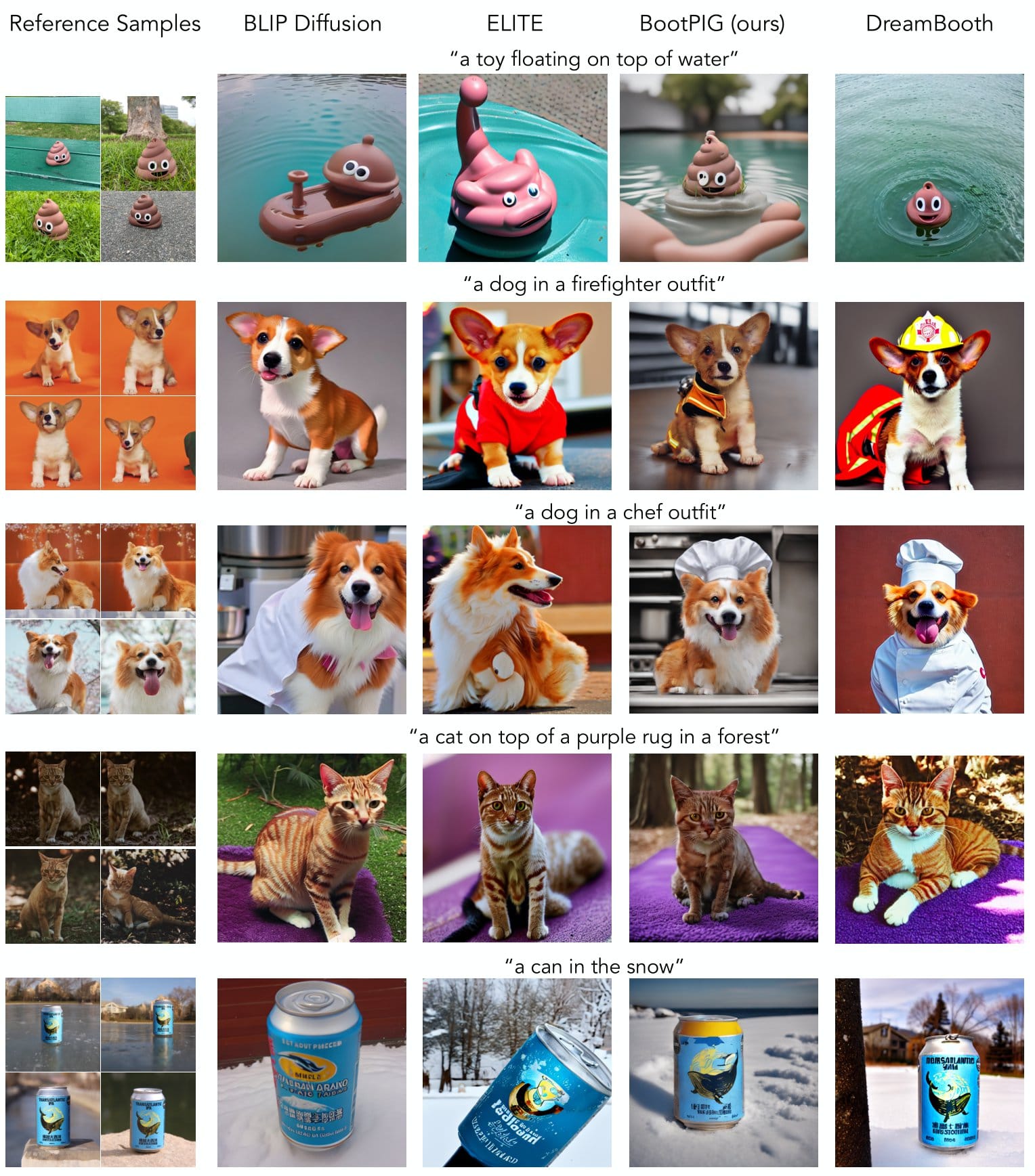
BootPIG demuestra resultados cuantitativos de última generación en la generación de imágenes sin sujeto. A continuación presentamos comparaciones cualitativas (visuales) con los métodos existentes de disparo cero y de ajuste fino del tiempo de prueba. Como se ve en la figura, BootPIG es capaz de mantener las características clave de los sujetos, como las marcas de pelo del perro de la 3ª fila, en la nueva escena.
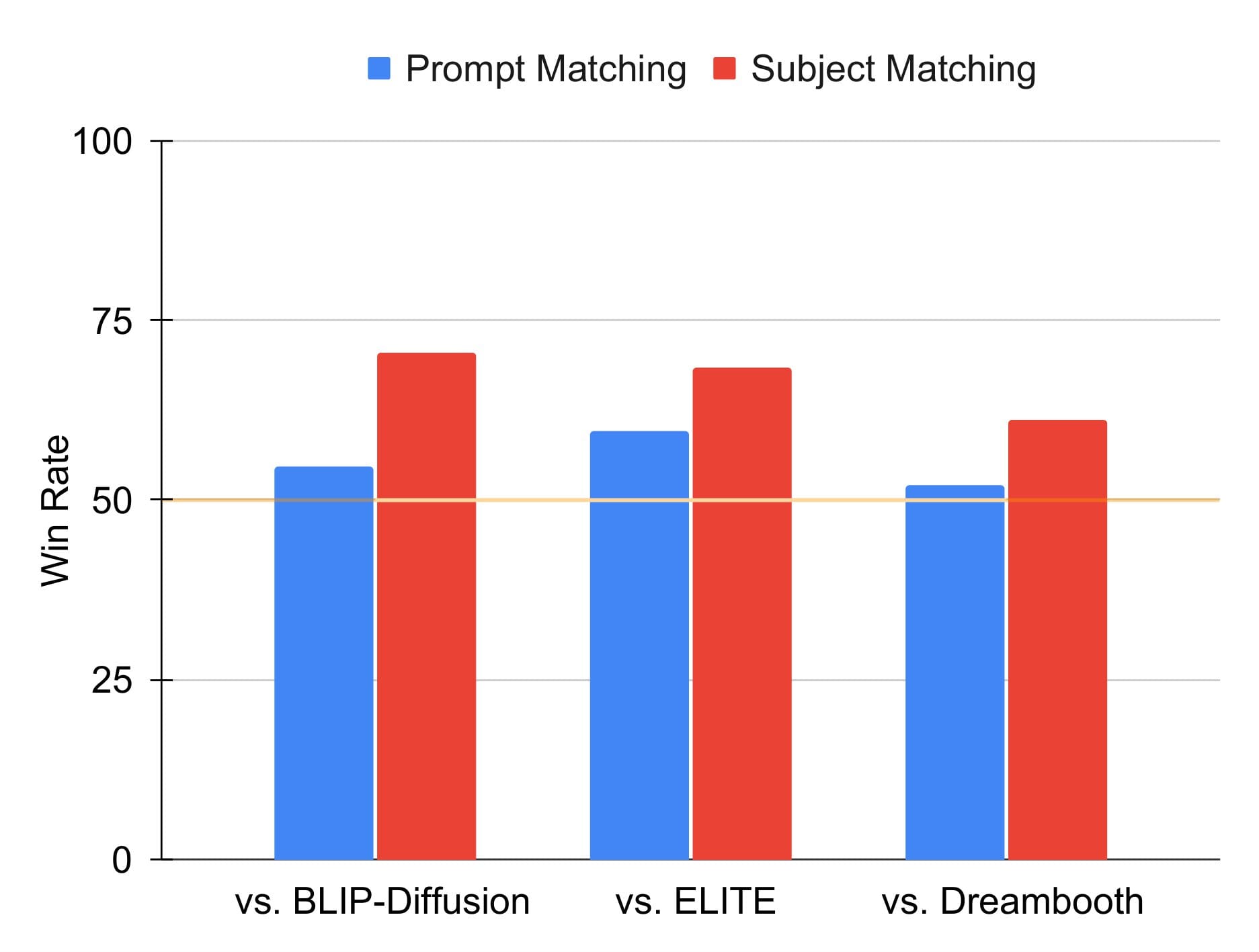
Además, descubrimos que los evaluadores humanos prefieren BootPIG a los métodos de generación basados en sujetos existentes. En este caso, realizamos dos estudios comparativos: uno evalúa qué método genera una imagen que coincide mejor con la petición (coincidencia de petición) y otro evalúa qué método genera una imagen que mantiene las características clave del sujeto (coincidencia de sujeto).
Impacto y consideraciones éticas
La posibilidad de personalizar imágenes según un tema abre muchas vías de aplicación. Desde crear imágenes de marketing con su producto hasta pintar a su mascota en una foto familiar, las posibilidades de generación personalizada son infinitas. Además, el hecho de poder generar estas imágenes sin tener que esperar al proceso de ajuste, significa que estas aplicaciones están a sólo unas pulsaciones de tecla.
Aunque BootPIG permite muchas aplicaciones interesantes, es importante tener en cuenta las limitaciones de los modelos texto-a-imagen. Los modelos texto-imagen reflejan los prejuicios recogidos en sus datos de entrenamiento. Como resultado, pueden generarse estereotipos perjudiciales y contenidos inapropiados. Además, la generación basada en temas introduce el riesgo de la desinformación. BootPIG se basa en modelos texto-imagen preentrenados y, por tanto, puede perpetuar estos sesgos.
Conclusión y direcciones futuras
BootPIG permite a los usuarios generar cualquier imagen con el tema que deseen, evitando la molestia de ajustar el modelo texto-imagen durante la inferencia. BootPIG preentrena un codificador temático general, que puede manejar múltiples imágenes de referencia, utilizando únicamente datos sintéticos. El proceso de entrenamiento completo dura aproximadamente una hora. El trabajo futuro podría explorar el uso de BootPIG para el inpainting basado en el sujeto o buscar la introducción de controles visuales adicionales (por ejemplo, mapas de profundidad) en el modelo, mapas de profundidad) en el modelo.
Detalles adicionales
Consulte el artículo completo y otros experimentos en: https://arxiv.org/abs/2401.13974
Permanezca atento a la publicación del código y los modelos.
Citaciones
- Betker, James, et al. «Improving image generation with better captions». https://cdn.openai.com/papers/dall-e-3.pdf.
- Midjourney. https://www.midjourney.com/home/.
- Rombach, Robin, et al. «Síntesis de imágenes de alta resolución con modelos de difusión latente» Actas de la conferencia IEEE/CVF sobre visión por ordenador y reconocimiento de patrones. 2022.
- Ruiz, Nataniel, et al. «Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation» Actas de la Conferencia IEEE/CVF sobre visión por ordenador y reconocimiento de patrones. 2023.
- Li, Dongxu, Junnan Li y Steven CH Hoi. «Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing» arXiv preprint arXiv:2305.14720 (2023).
- Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. «Adding conditional control to text-to-image diffusion models» Actas de la Conferencia internacional IEEE/CVF sobre visión por ordenador. 2023.
- ChatGPT. https://chat.openai.com/.
- Kirillov, Alexander, et al. «Segment anything.» arXiv preprint arXiv:2304.02643 (2023).
- Bianchi, Federico, et al. «Easily accessible text-to-image generation amplifies demographic stereotypes at large scale.» Actas de la Conferencia ACM 2023 sobre imparcialidad, responsabilidad y transparencia. 2023.
Acerca de los autores
Senthil Purushwalkam es investigador científico en Salesforce AI. Sus intereses de investigación se centran en la visión por ordenador y la PNL.
Akash Gokul es residente de IA en Salesforce Research. Actualmente trabaja en la mejora de modelos generativos multimodales.
Shafiq Rayhan Joty es Director de investigación en Salesforce Research AI, donde dirige el trabajo del grupo de PNL sobre modelado de grandes lenguajes (LLM) e IA generativa. Sus intereses de investigación se centran en los LLM, la PNL multimodal y la PNL robusta.
Nikhil Naik es investigador principal en Salesforce AI. Sus intereses de investigación se centran en la visión por ordenador, el procesamiento del lenguaje natural y sus aplicaciones en ciencias. Su trabajo actual se centra en el modelado generativo y el aprendizaje de representación multimodal