TL;DR: Moirai es un modelo básico de series temporales de última generación que ofrece capacidades de previsión universales. Destaca como un modelo versátil de previsión de series temporales capaz de abordar diversas tareas de previsión a través de múltiples dominios, frecuencias y variables de una manera de disparo cero.para lograrlo, Moirai aborda cuatro retos principales: (i) la construcción de un LOTSA, un conjunto de datos de series temporales diverso y a gran escala, que comprende 27.000 millones de observaciones que abarcan nueve dominios distintos, (ii) el desarrollo de múltiples capas de proyección de tamaño de parche, que permiten a un único modelo capturar patrones temporales a través de varias frecuencias, (iii) la implementación de un mecanismo de atención a cualquier variable, que permite a un único modelo manejar previsiones a través de cualquier variable, y (iv) la integración de una distribución de mezcla para modelar distribuciones de predicción flexibles. A través de una evaluación exhaustiva en entornos dentro y fuera de la distribución, Moirai demuestra su destreza como pronosticador de disparo cero, ofreciendo sistemáticamente un rendimiento competitivo o superior en comparación con los modelos de disparo completo.
La necesidad de un pronosticador universal
Los datos de series temporales están presentes en numerosos ámbitos, como el comercio minorista, las finanzas, la fabricación, la sanidad y las ciencias naturales. En todos estos sectores, la previsión de series temporales es una aplicación crítica con importantes implicaciones para la toma de decisiones. Aunque se han logrado avances significativos en el aprendizaje profundo para la predicción de series temporales, los avances recientes todavía se adhieren predominantemente al paradigma convencional de entrenar un modelo para un conjunto de datos específico con un contexto y una longitud de predicción fijos y predefinidos. Este paradigma impone inevitablemente una carga significativa en términos de costes computacionales para la formación de estos modelos, especialmente cuando se amplía a un gran número de usuarios.
Por ejemplo, la creciente demanda de servicios de computación en la nube ha aumentado la importancia de la gestión eficiente de los recursos en la infraestructura de TI. La previsión operativa ha surgido como un componente crítico en la canalización de la gestión de estos recursos, como principal factor impulsor de la planificación de la capacidad, la planificación presupuestaria, la evaluación de riesgos de escenarios, la optimización de costes y la detección de anomalías. Sin embargo, con la demanda cada vez mayor de recursos informáticos y el tamaño creciente de la infraestructura de TI, la capacidad de los proveedores de servicios para gestionar las necesidades de previsión a través de la multitud de tareas se ve continuamente desafiada, además de tener que construir pronosticadores específicos de tareas/usuarios.
Esto nos motiva a avanzar hacia el paradigma de previsión universal (véase la Figura 1), donde un único gran modelo pre-entrenado es capaz de manejar cualquier problema de previsión de series temporales.
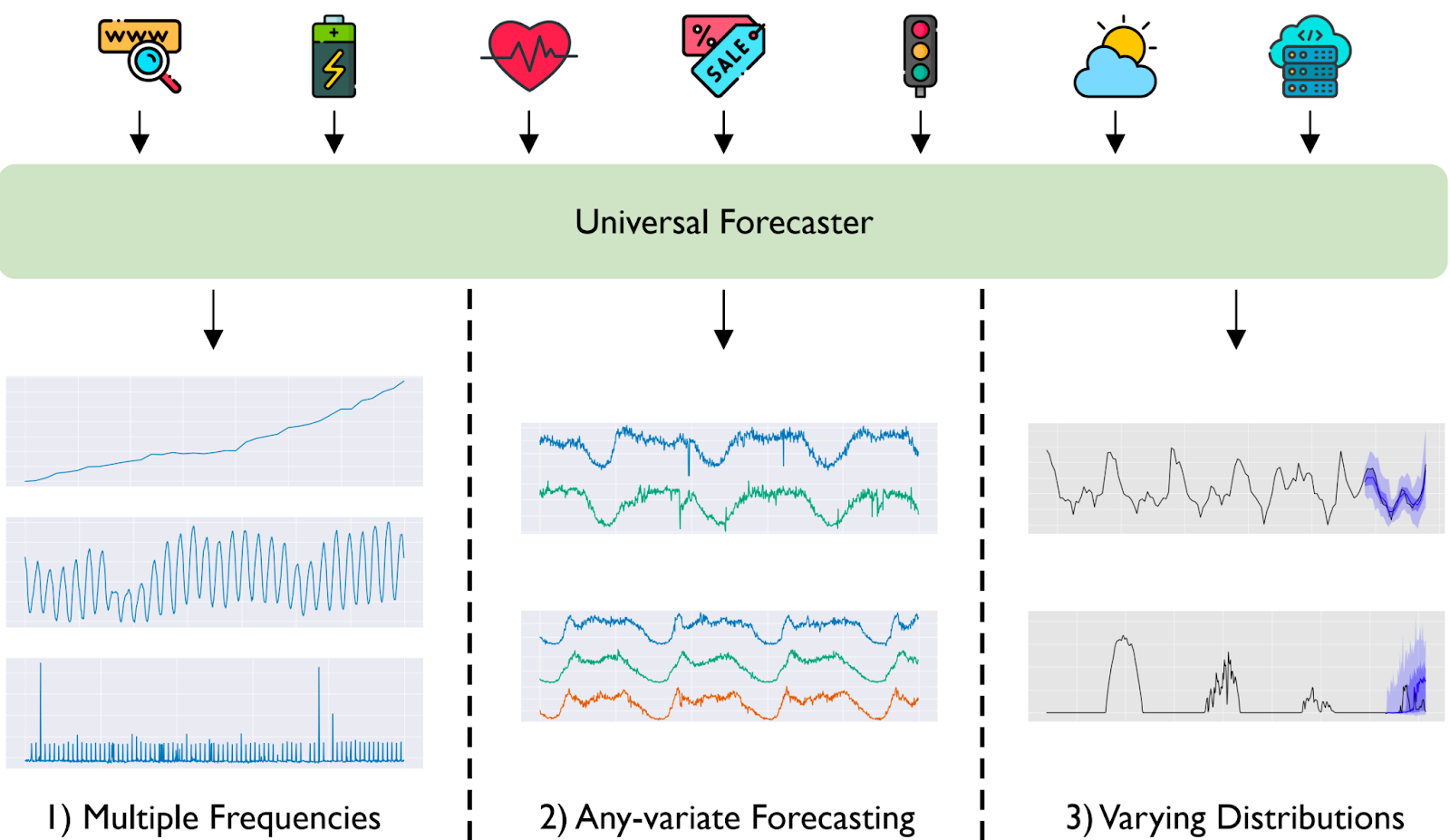
Figura 1. Un pronosticador universal es un gran modelo preformado capaz de gestionar cualquier problema de previsión de series temporales. Un pronosticador universal es un gran modelo preentrenado capaz de manejar cualquier problema de previsión de series temporales. Se entrena en un conjunto de datos de series temporales a gran escala que abarca múltiples dominios. En comparación con el paradigma actual, la previsión universal se enfrenta a los tres problemas clave de i) frecuencias múltiples, ii) previsión de cualquier variable y iii) distribuciones variables.
Los retos para construir un pronosticador universal
El cambio de paradigma hacia modelos basados en fundamentos fue inicialmente impulsado por el campo del Procesamiento del Lenguaje Natural (PLN), que entrenó con éxito Modelos de Lenguaje de Gran Tamaño (LLM) en diversos datos a escala web, capaces de abordar una amplia variedad de tareas posteriores e incluso multilingües. Una importante innovación que permite a los LLM manejar múltiples idiomas es la codificación por pares de bytes (BPE), que convierte idiomas heterogéneos en un formato unificado. A diferencia de la PLN, el campo de las series temporales no tiene un equivalente en BPE, por lo que no es trivial construir una base de series temporales que pueda manejar la heterogeneidad de los datos de series temporales.
- En primer lugar, la frecuencia (por ejemplo, frecuencias de muestreo por minutos, horas o días) de las series temporales desempeña un papel crucial en la determinación de los patrones presentes en los datos. Sin embargo, el aprendizaje entre frecuencias plantea problemas debido a la interferencia negativa, y los enfoques existentes suelen sortear este problema para los conjuntos de datos multifrecuencia entrenando un modelo por frecuencia.
- En segundo lugar, los datos de series temporales presentan heterogeneidad en términos de dimensionalidad, donde las series temporales multivariantes pueden tener un número variable de variables. Además, cada variable suele medir una cantidad semánticamente distinta en los distintos conjuntos de datos. Aunque tratar cada variable de una serie temporal multivariante de forma independiente puede mitigar este problema, lo ideal sería que un modelo universal fuera lo suficientemente flexible como para considerar las interacciones entre variables y tener en cuenta las covariables exógenas.
- En tercer lugar, la previsión probabilística es un requisito fundamental para muchas aplicaciones. Sin embargo, los distintos conjuntos de datos poseen diferentes propiedades de soporte y distribución. Por ejemplo, utilizar una distribución simétrica (p. ej., Normal, Student-T) como distribución predictiva puede no ser adecuado para series temporales positivas. En consecuencia, los enfoques estándar que predefinen una distribución paramétrica simple pueden carecer de la flexibilidad necesaria para captar eficazmente la diversa gama de conjuntos de datos.
- Por último, el desarrollo de un gran modelo preentrenado capaz de realizar previsiones universales requiere un amplio conjunto de datos que abarque diversos dominios. Lamentablemente, los conjuntos de datos de series temporales existentes no suelen ser lo suficientemente amplios y diversos como para permitir el entrenamiento de dichos modelos.
Nuestro nuevo enfoque: Unified Training of Universal Time Series Forecasting Transformers
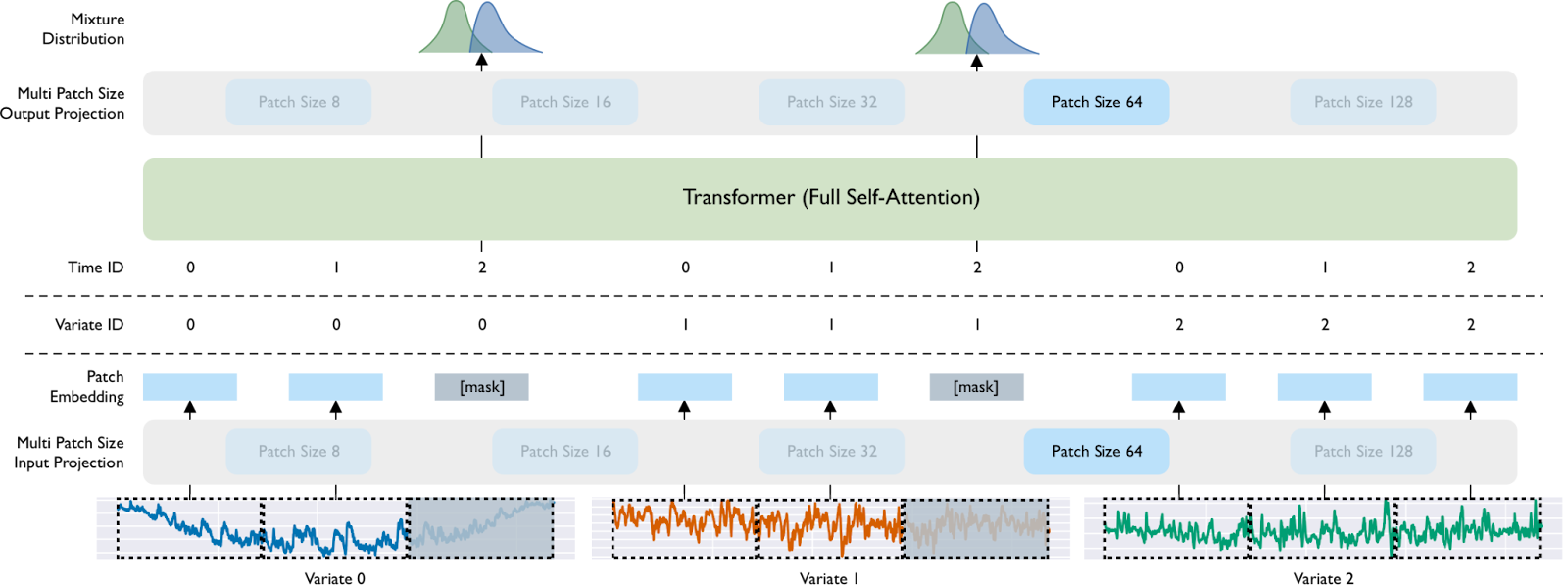
Figura 2. Arquitectura general de Moirai. Arquitectura general de Moirai. La visualización muestra una serie temporal de 3 variables, en la que las variantes 0 y 1 representan las variables objetivo (es decir, las que deben pronosticarse), y la variante 2 sirve como covariable dinámica (con valores conocidos en el horizonte de pronóstico). Utilizando un tamaño de parche de 64, cada variable se parchea en tres tokens. Estos parches, junto con los identificadores de secuencia y variante, se introducen en el transformador. Los parches sombreados de la visualización indican el horizonte de predicción. A continuación, las representaciones de salida correspondientes de estos parches se asignan a los parámetros de la distribución de la mezcla.
Para abordar estos retos, presentamos mejoras novedosas (véase la Figura 2) en la arquitectura convencional de Transformer de series temporales para gestionar la heterogeneidad de los datos de series temporales arbitrarias. He aquí algunas de las principales características y contribuciones de nuestro trabajo:
- En primer lugar, proponemos abordar el reto de las frecuencias variables en los datos de series temporales mediante el aprendizaje de múltiples capas de proyección de entrada y salida. Estas capas están diseñadas para manejar los diversos patrones presentes en las series temporales de diferentes frecuencias. Mediante el empleo de proyecciones basadas en parches con tamaños de parche más grandes para datos de alta frecuencia y viceversa, las capas de proyección se especializan para aprender los patrones específicos de cada frecuencia.
- En segundo lugar, abordamos el problema de la dimensionalidad variable utilizando nuestro mecanismo propuesto de Atención a Cualquier Variable. Este enfoque considera simultáneamente los ejes temporal y variado como una única secuencia, aprovechando la incrustación de posición rotatoria (RoPE) y los sesgos binarios de atención aprendidos para codificar los ejes temporal y variado, respectivamente. Es importante destacar que Any-variate Attention permite que el modelo acepte un número arbitrario de variantes como entrada.
- En tercer lugar, superamos el reto de requerir distribuciones predictivas flexibles introduciendo una mezcla de distribuciones paramétricas. Al optimizar la log-verosimilitud negativa de una distribución flexible, nos aseguramos de que nuestro modelo sea competitivo con la optimización de la métrica objetivo, una potente característica para el preentrenamiento de pronosticadores universales. Este enfoque permite la evaluación posterior utilizando cualquier métrica objetivo.
- Por último, para facilitar el entrenamiento de nuestro modelo de grandes series temporales, presentamos LOTSA, la mayor colección de conjuntos de datos de series temporales abiertos mediante la recopilación de fuentes de conjuntos de datos de series temporales disponibles públicamente. Este esfuerzo pretende cubrir un amplio espectro de dominios, consolidando conjuntos de datos de diversas fuentes con formatos variados. La colección resultante abarca nueve ámbitos, con un total de 27.000 millones de observaciones, cuyas principales estadísticas figuran en los cuadros 2 y 3. Para más detalles sobre las propiedades clave de estos conjuntos de datos, como el dominio, la frecuencia, el número de series temporales, el número de variables objetivo, el número de covariables pasadas y el número total de observaciones, consulte nuestro documento de investigación (https://arxiv.org/abs/2402.02592).

Inmersión más profunda: Moirai
Ilustrado en la Figura 2, Moirai sigue un enfoque basado en parches (no solapados) para modelar series temporales con una arquitectura de codificador enmascarado. Una de las modificaciones que proponemos para ampliar la arquitectura a la configuración de cualquier variable consiste en «aplanar» las series temporales multivariantes, considerando todas las variantes como una única secuencia. Los parches se proyectan posteriormente en representaciones vectoriales a través de una capa de proyección de entrada de tamaño multiparche. La [máscara] significa una incrustación aprendible que sustituye a los parches que caen dentro del horizonte de previsión. Los tokens de salida se decodifican a través de la proyección de salida multiparche en los parámetros de la distribución de la mezcla. Aunque no se visualiza, se aplica una normalización de instancia (no aprendible) a las entradas/salidas, en línea con la práctica estándar actual para los modelos de previsión profunda.
En nuestra tarea de preentrenamiento, formulamos el objetivo de optimizar la log-verosimilitud de la distribución de mezcla. El diseño tanto de la distribución de los datos como de la distribución de la tarea son dos aspectos críticos del proceso de preentrenamiento. Este diseño confiere capacidades versátiles a nuestro modelo de grandes series temporales (LTM), permitiéndole adaptarse a una serie de tareas posteriores. Esta flexibilidad contrasta con el paradigma predominante de predicción profunda, en el que los modelos suelen estar especializados para conjuntos de datos y entornos específicos.
Results
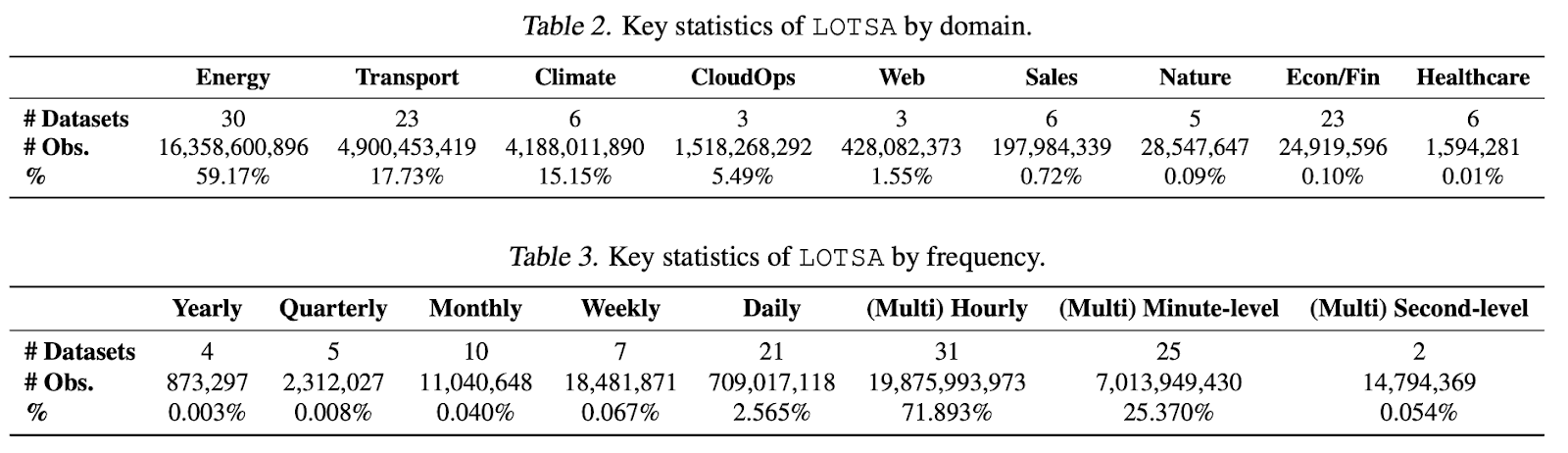
Entrenamos Moirai en 3 tamaños: pequeño/base/grande con 14m/91m/311m parámetros En las evaluaciones dentro de la distribución utilizando el Monash Time Series Forecasting Benchmark, Moirai muestra un rendimiento fenomenal, superando todas las líneas de base.
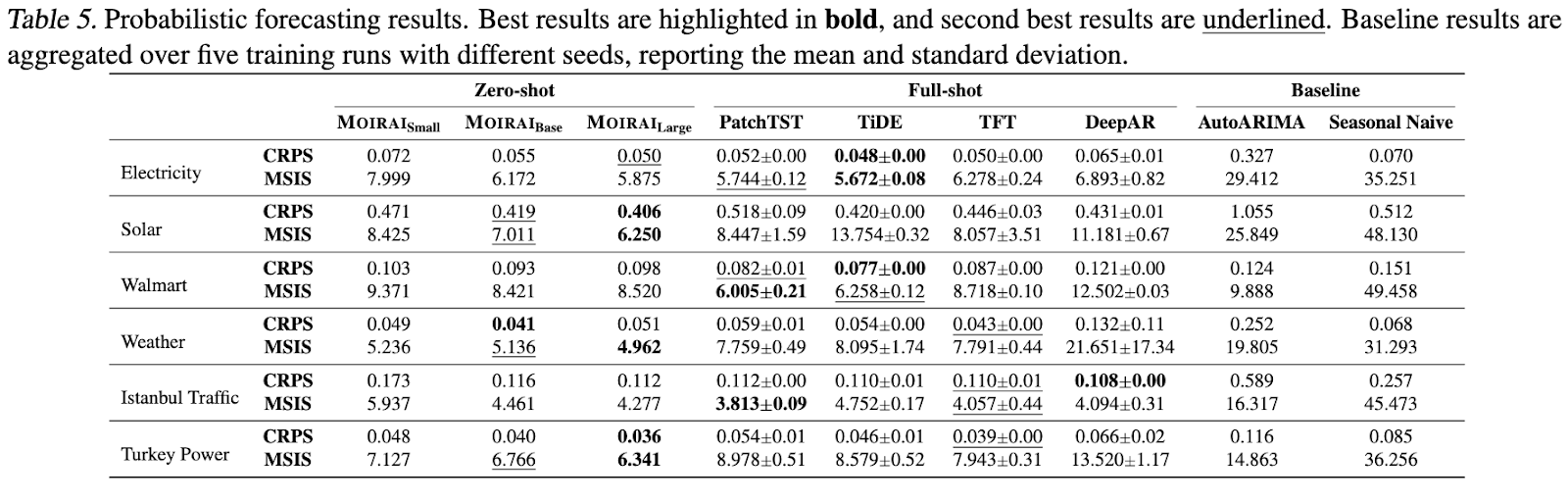
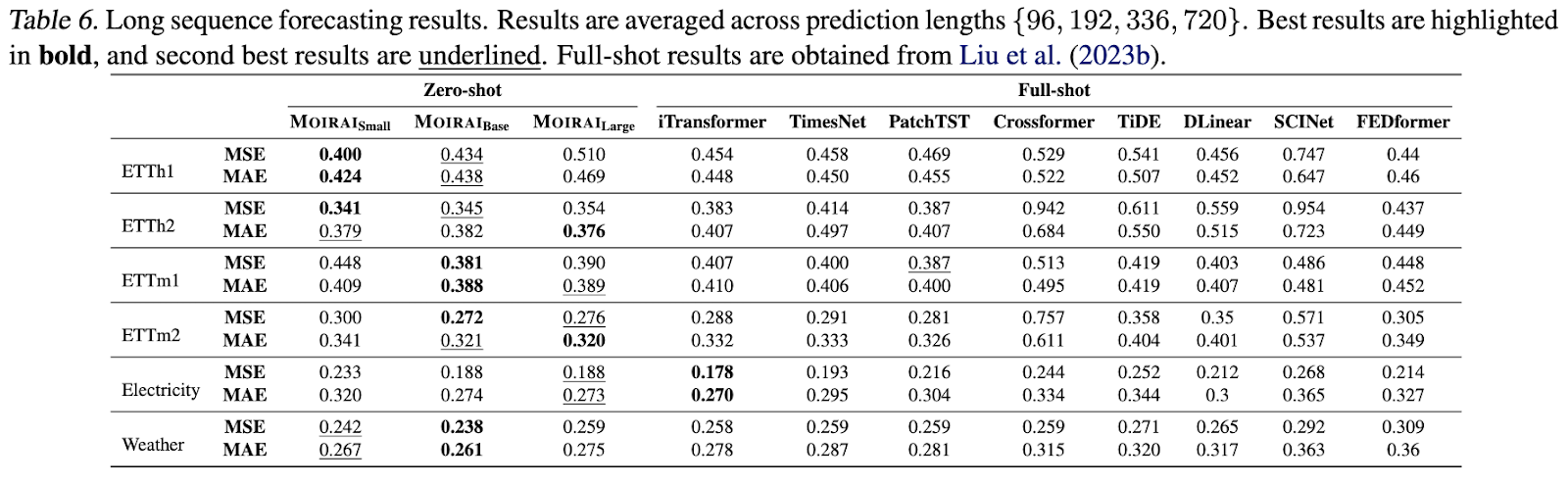
En evaluaciones de previsión fuera de distribución/zero-shot, Moirai demuestra sistemáticamente un rendimiento competitivo y, en algunos casos, supera a los modelos de disparo completo más avanzados. Esta superioridad se observa tanto en las previsiones probabilísticas como en las de secuencia larga.
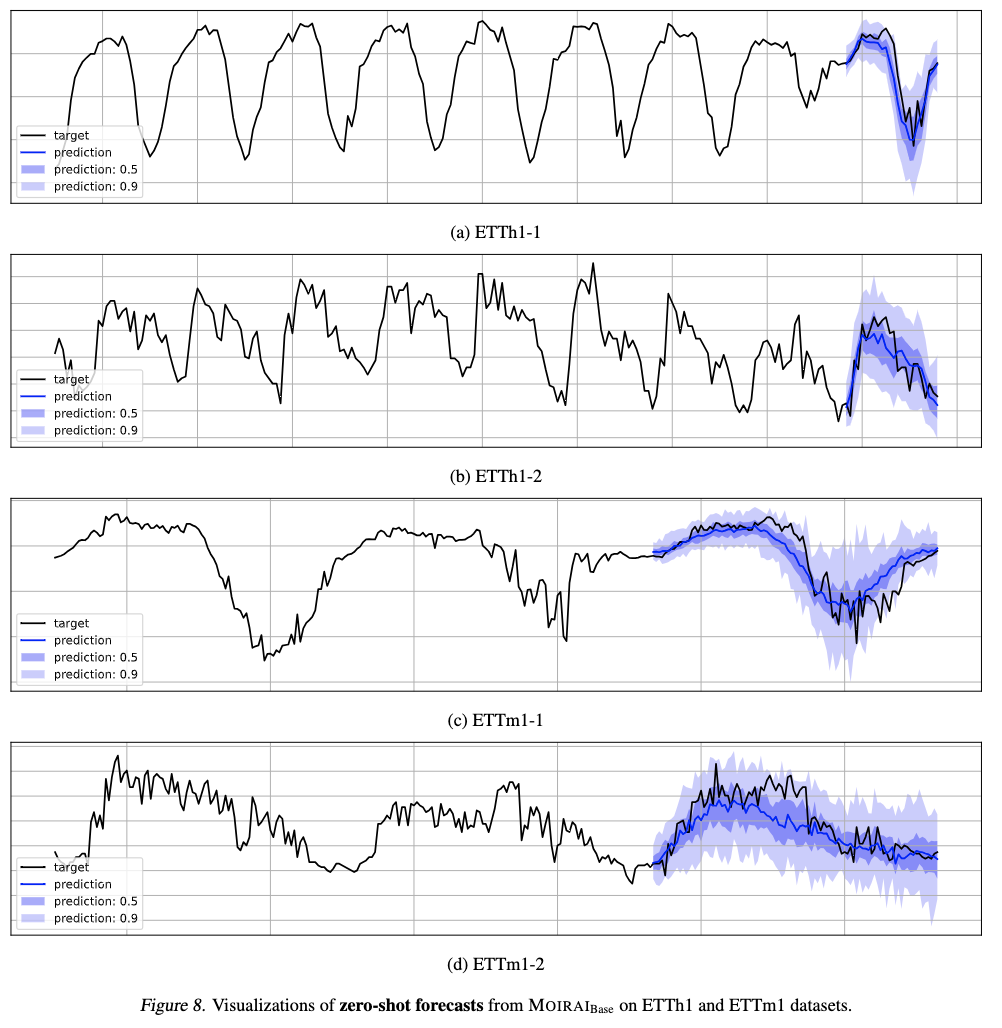
Aquí se muestran algunas visualizaciones de las previsiones de disparo cero de Moirai en los conjuntos de datos más populares. Como se muestra, Moirai elabora hábilmente previsiones marcadas por patrones estacionales discernibles de ETTh1-1 y ETTh1-2, al tiempo que captura con precisión los patrones de tendencia de ETTm1-1 y ETTm1-2. Estas ilustraciones subrayan la capacidad de Moirai para ofrecer predicciones perspicaces en distintos escenarios.
Impact: Por qué Moirai es importante
Moirai proporciona sólidas capacidades de previsión de disparo cero en una amplia gama de series temporales que abarcan diferentes dominios y frecuencias. Al aprovechar la potencia del preentrenamiento de datos a gran escala, este modelo básico de series temporales revoluciona el panorama, apartándose del anticuado enfoque de un modelo por conjunto de datos. Ofrece ventajas sustanciales a los usuarios en tareas de previsión posteriores, eliminando la necesidad de datos adicionales, amplios recursos computacionales y aportaciones de expertos que suelen ser necesarios para lograr previsiones precisas con modelos de aprendizaje profundo. Además, la capacidad de Moirai para manejar series temporales multivariantes de cualquier dimensión democratiza aún más la previsión precisa al reducir la dependencia tanto de los recursos informáticos como de la experiencia en aprendizaje profundo. Además de ser un avance importante para el mundo académico, Moirai tiene múltiples aplicaciones, incluyendo operaciones de TI, previsión de ventas, planificación de capacidad, previsión de energía y muchas otras.
The Bottom Line
- Moirai está diseñado para lograr una previsión universal con transformadores de series temporales basados en codificadores enmascarados.
- LOTSA es la mayor colección de datos abiertos para el preentrenamiento de modelos de previsión de series temporales.
- Moirai aborda los desafíos clave de la previsión universal para admitir varios dominios, múltiples frecuencias y cualquier variable de forma cero.
- Evaluado tanto en entornos dentro de distribución como fuera de distribución, Moirai brilla como pronosticador de disparo cero, ofreciendo un rendimiento competitivo o incluso superior en comparación con los modelos de disparo completo.
Explore más
Salesforce AI le invita a profundizar en los conceptos tratados en esta entrada de blog (consulte los enlaces a continuación). Conéctese con nosotros en las redes sociales y en nuestro sitio web para obtener actualizaciones periódicas sobre este y otros proyectos de investigación.
Acerca de los autores
Gerald Woo es candidato a doctor en el Programa de doctorado industrial de la Universidad de Gestión de Singapur e investigador en Salesforce AI Research Asia y su investigación se centra en el aprendizaje profundo para series temporales, incluido el aprendizaje de representación y la previsión.
Chenghao Liu es un científico aplicado líder en Salesforce AI Research Asia, que trabaja en la investigación de AIOps, incluyendo la previsión de series temporales, la detección de anomalías y el aprendizaje automático causal.
Doyen Sahoo es el director de Salesforce AI Research Asia. Doyen dirige varios proyectos relacionados con IA para operaciones de TI o AIOps, IA para software e inteligencia de series temporales, trabajando tanto en investigación fundamental como aplicada.
Caiming Xiong Ocupa los cargos de director general y vicepresidente de Salesforce AI Research. Supervisa el desarrollo y la aplicación de tecnologías como grandes modelos de lenguaje (LLM), LLM multimodales, grandes modelos de acción, IA para software, series temporales y otras áreas de investigación fundamentales. Además, Caiming dirige la transición de estos proyectos de IA desde las fases de investigación a los entornos de producción.
Tecnología de la información