¿Cómo puede un ordenador discernir el significado de una frase? Por «discernir su significado» me refiero a comprender las palabras de la frase, su contexto, matices y relaciones con otras palabras. Cuando pensamos en inteligencia artificial (IA) en el ámbito de los LLM, pensamos en generación de textos. Pero, ¿cómo entiende realmente el ordenador su consulta cuando usted pregunta «¿Podrá la IA entender alguna vez los maullidos de mi gato y traducirlos al inglés?» Esto entra dentro del ámbito de la comprensión del lenguaje natural (NLU) y, más concretamente, de la incorporación de texto. Desde la recuperación de documentos hasta la clasificación del sentimiento de una reseña de producto, la incrustación de texto es el héroe olvidado que impulsa nuestros sistemas de IA modernos.
En Salesforce AI Research somos conscientes de la importancia de contar con un modelo de incrustación de texto de alto rendimiento y del papel fundamental que desempeña para permitir una mejor representación de los datos textuales y capturar las relaciones semánticas y los matices de forma eficaz. Por eso hemos lanzado SFR-Embedding, el modelo de inserción de texto de mayor rendimiento (en comparación con otros modelos). Antes de entrar de lleno en lo que le hace destacar, veamos cómo funcionan los modelos de incrustación de texto.
¿Cómo funcionan los modelos de incrustación de texto?
Los modelos de incrustación de texto (también conocidos como codificadores vectoriales) son como traductores para ordenadores: toman palabras, frases o incluso párrafos enteros de texto y los convierten a un formato que los ordenadores puedan entender y con el que puedan trabajar más fácilmente.
Piensa en cada palabra o frase de un texto como la consulta anterior «¿Podrá la IA entender alguna vez los maullidos de mi gato y traducirlos al inglés?» Se trata de datos no estructurados para el ordenador, es decir, que no tienen una organización o un formato predefinidos. Un modelo de incrustación de texto toma estos datos (cada palabra o frase) y los convierte en un conjunto de números (vectores) que captan su significado y contexto. Estos vectores son formatos fácilmente interpretables y manipulables por los ordenadores. Permiten al ordenador convertir los datos en una forma estructurada, en la que la información se organiza en varios vectores para facilitar su análisis e interpretación. Por ejemplo, en lugar de decir «gato», el modelo podría convertirlo en una serie de números similares a otros que representan el aspecto de un gato, su comportamiento y su relación con otras palabras de su entorno. Es una forma de que los ordenadores establezcan asociaciones y comparen estos conjuntos de números para comprender la similitud o diferencia de significado de las palabras.
Los modelos de incrustación de texto mejoran significativamente el rendimiento de la recuperación, que mide la capacidad de la base de datos para encontrar información relevante a partir de la consulta de un usuario. Esta mejora se debe a que los vectores permiten emparejar con mayor precisión las consultas con los documentos pertinentes. Al comparar los vectores de la consulta y los documentos de la base de datos, los sistemas pueden identificar rápidamente la información más relevante, haciendo que las búsquedas sean más rápidas y eficaces. Este proceso analizará inicialmente el sentimiento de su consulta, encontrará documentos similares que puedan abordar la consulta y, a continuación, generará una respuesta para usted.
En el equipo de investigación de IA de Salesforce, reconocemos el papel vital que desempeña la incorporación de texto en nuestros esfuerzos de inteligencia artificial. Los sistemas CRM manejan con frecuencia grandes cantidades de datos, que abarcan correos electrónicos de clientes, comentarios, notas y mucho más. Para nosotros es esencial comprender rápidamente esta afluencia de información y conectar sin problemas a las personas con los datos que necesitan. Esta comprensión impulsa el desarrollo por parte de nuestro equipo de IA del modelo de incrustación de texto de vanguardia, conocido como SFR- Embedding.
Presentación de SFR-Embedding de Salesforce Research: El modelo de inserción de texto de mayor rendimiento
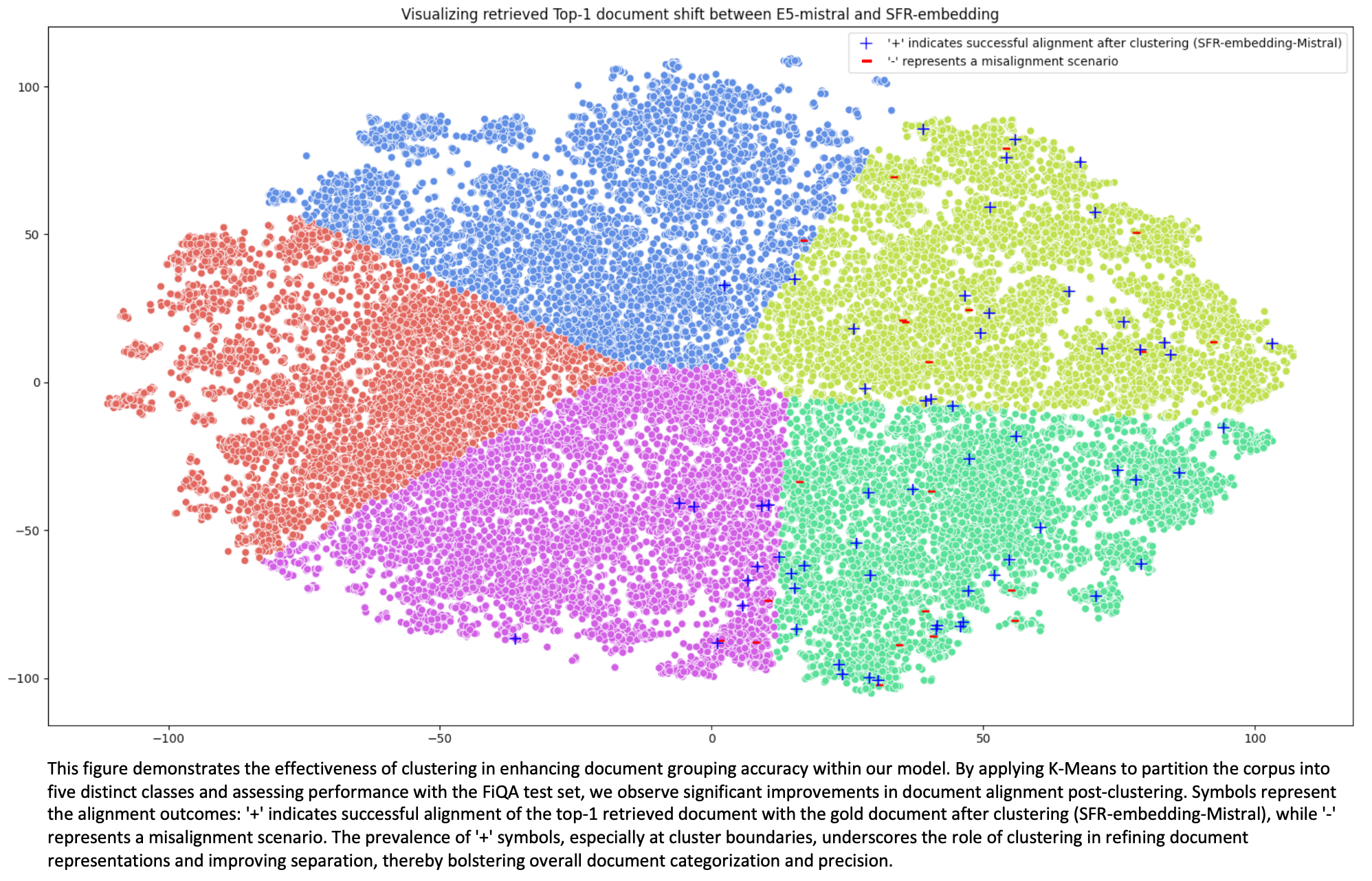
SFR-Embedding es un innovador avance en los modelos de incrustación de texto, que se basa en la sólida base establecida por sus predecesores, E5-mistral-7b-instruct y Mistral-7B-v0.1. Este innovador modelo ha alcanzado rápidamente la cima, con una impresionante puntuación media de 67,6 en 56 conjuntos de datos de la prestigiosa prueba MTEB.
Lo que hace destacar a SFR-Embedding es su extraordinario rendimiento en tareas como la búsqueda de información específica y la agrupación de elementos relacionados. En comparación con los modelos anteriores, ha mostrado una mejora significativa, ya que su puntuación ha pasado de 56,9 a un impresionante 59,0 en tareas de recuperación. Y en tareas de agrupación, es incluso mejor, con una mejora notable de +1,4 en comparación con su predecesor, E5-mistral-7b-instruct. Lo mejor de este modelo es que se ha entrenado en una mezcla de tareas diferentes, como la búsqueda de información, la organización de datos y la categorización de contenidos. Esto significa que es muy versátil y puede enfrentarse a una amplia gama de retos. Además, utiliza algunos trucos muy inteligentes, como agrupar tareas similares durante el entrenamiento y centrarse en los fragmentos de información más importantes. Por lo tanto, SFR-Embedding no sólo es realmente bueno en lo que hace, sino que también es inteligente y adaptable, lo que lo convierte en la mejor opción para todo tipo de proyectos.
Un paso crucial para las respuestas generativas de IA
Como hemos mencionado antes, la incrustación de texto consiste en convertir datos no estructurados en valores numéricos llamados vectores que conservan su significado y sus matices. Nuestro modelo SFR-Embedding obtiene los mejores resultados en tareas de recuperación, lo que significa que nuestro modelo es eficaz a la hora de encontrar y seleccionar información relevante de un gran conjunto de datos o colección de documentos. Este es un componente crucial en el proceso de recuperación para un flujo de trabajo de Generación Aumentada de Recuperación (RAG). En un flujo de trabajo RAG, una vez recuperados los pasajes relevantes, sirven como contexto o conocimiento para que un modelo generativo, como un modelo lingüístico, genere una respuesta o salida.
Conclusión
El modelo SFR-Embedding representa un avance significativo en la tecnología de incrustación de texto, ofreciendo un rendimiento de primer nivel en diversas tareas y dominios. Construido sobre bases sólidas y aprovechando técnicas innovadoras como el entrenamiento multitarea y los negativos duros optimizados, este modelo destaca a la hora de discernir información relevante con precisión. Tanto si se enfrenta a tareas de recuperación, agrupación o clasificación, nuestro modelo está preparado para satisfacer sus necesidades con eficacia y precisión.
Explore más
Salesforce AI le invita a profundizar en los conceptos tratados en esta entrada de blog (enlaces más abajo). Conéctese con nosotros en las redes sociales y en nuestro sitio web para obtener actualizaciones periódicas sobre este y otros proyectos de investigación.
Agradecimientos
El SFR-Embedding fue una colaboración dentro del equipo de investigación de Salesforce AI: Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, Semih Yavuz.
El SFR-Embedding fue una colaboración dentro del equipo de investigación de IA de Salesforce