Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Cuando trabaje en un entorno empresarial, es posible que deba procesar grandes cantidades de registros de Salesforce utilizando las API de la plataforma. En esta serie de dos publicaciones, presentaremos opciones para procesar datos a escala. En esta primera publicación, nos centraremos en las operaciones de lectura con la API REST y las API masivas. Presentaremos qué opción es mejor para casos de uso específicos y cuáles son los límites, y compartiremos ejemplos de solicitudes. En la segunda publicación, veremos las operaciones de escritura con la API compuesta y las API masivas.
API REST
La API REST le permite leer una gran cantidad de registros de forma sincrónica y es la API más fácil de usar. Sin embargo, tiene algunas limitaciones. En primer lugar, solo puede devolver un máximo de 2000 registros por llamada a la API. Si necesita más datos, necesitará solicitudes adicionales para recuperar lotes de hasta 2000 registros. En segundo lugar, esta API no es adecuada para operaciones de escritura en lotes grandes de varios miles a millones de registros.
La API REST generalmente es más adecuada cuando se trabaja con una interfaz de usuario debido a su enfoque más granular. También es más simple de implementar en comparación con la API masiva, ya que se basa en un solo tipo de solicitud y esas solicitudes son sincrónicas.
Para leer un lote de registros, simplemente realice una solicitud GET en el extremo de consulta con un parámetro q que contenga una consulta SOQL codificada en URL.
Si la consulta SOQL devuelve menos de 2000 registros, la respuesta de la API se verá así:
Aspectos destacados de la respuesta:
- El atributo
totalSizele brinda la cantidad total de registros que se pueden seleccionar con la consulta SOQL - El indicador
doneestablecido entrueindica que no hay registros adicionales para obtener para esta consulta
Sugerencia: las respuestas de la API REST están disponibles en JSON de forma predeterminada, pero también se pueden obtener como XML agregando un encabezado Accept: application/xml a las solicitudes.
Si una consulta SOQL devuelve más de 2000 registros, la respuesta de la API contiene solo un subconjunto de los resultados y tendrá que usar un localizador de consultas o una paginación para acceder a los resultados restantes.
Uso del localizador de consultas para recuperar resultados adicionales
Si una consulta devuelve más de 2000 registros, la primera respuesta de la API se verá así:
Aspectos destacados de la respuesta:
- El atributo
totalSizele brinda la cantidad total de registros que se pueden seleccionar con la consulta SOQL. En este caso, este número es mayor que el número de elementos en la matrizrecords. - El indicador
doneestablecido enfalseindica que hay registros adicionales que se pueden devolver (esta respuesta solo incluye los primeros 2000 registros). -
nextRecordsUrlcontiene un enlace con la URL del localizador de consultas. -
recordscontiene los primeros 2000 registros devueltos por la consulta.
Un localizador de consultas representa un cursor del lado del servidor en la base de datos. El localizador de consultas actúa como un identificador para obtener conjuntos de resultados de consultas adicionales. A partir de Winter '23 (API v56.0), un cursor permanece disponible hasta por dos días y no hay límites para la cantidad de cursores abiertos.
El final de la URL del localizador de consultas se compone de dos partes separadas por un guión ( - ): el ID del localizador de consultas y un desplazamiento. En el ejemplo anterior, 0r82211CelDTLqEAEX-2000 fue el localizador de consultas para el siguiente lote de resultados a partir del registro 2000. Si quisiéramos obtener un lote a partir del registro 4000, podríamos usar directamente 0r82211CelDTLqEAEX-4000 .
Si ejecuta una solicitud GET en la URL del localizador de consultas, obtendrá el próximo lote de hasta 2000 registros. Si el nuevo lote es el último, el indicador done será true y nextRecordsUrl no estará presente. Si hay algunos registros adicionales, done será false y obtendrá otra URL del localizador de consultas para recuperar el siguiente lote de registros (el ID del localizador de consultas seguirá siendo el mismo, pero se incrementará el desplazamiento).
La URL del localizador de consultas le permite controlar la compensación de resultados, pero no puede especificar el tamaño del lote de resultados. Esto significa que el localizador de consultas no es adecuado para trabajar con una interfaz de usuario, ya que probablemente no mostraría 2000 registros a la vez. La paginación es un mejor enfoque en este caso.
Uso de la paginación para recuperar resultados adicionales
La paginación se basa en el mismo punto final de consulta REST, pero la diferencia es que usted controla la respuesta con tres palabras clave en la consulta SOQL:
- Uno o más criterios de clasificación gracias a la cláusula
ORDER BY - Un tamaño de página inferior a 2000 registros gracias a la cláusula
LIMIT - Una compensación de resultado en forma de una cláusula
OFFSET, que se puede derivar del índice de la página con esta fórmulaoffset = page index * page size
Por ejemplo, la siguiente consulta devolvería un lote de 1000 cuentas ordenadas por fecha de creación a partir del resultado 2000.
Si bien la paginación generalmente se usa mejor para los casos de uso de la interfaz de usuario, también se puede usar en operaciones de ejecución prolongada, siempre que los resultados estén ordenados por un campo cuyos valores no cambien durante el cruce de resultados (la fecha de creación es un buen ejemplo).
La API REST funciona bien para recuperar varios miles de registros, pero más allá de esta escala, de decenas de miles a millones de registros, querrá usar las API masivas.
API masivas
Las API masivas llevan la escala a otro nivel a expensas de la sincronicidad. Un mayor tiempo de procesamiento para recuperar más datos implica que las operaciones de consulta ya no son sincrónicas, a diferencia de la API REST. Esto significa que la API masiva generalmente requiere más código en el lado del cliente y requiere algún tipo de mecanismo de sondeo.
Hay dos generaciones de API masivas: API masiva y API masiva 2.0. Estas dos API funcionan de manera diferente y tienen distintas ventajas y desventajas . No replicaremos el contenido de Bulk API 2.0 y Bulk API Developer Guide en esta publicación, pero destacaremos los diferenciadores clave entre las dos generaciones de API.
La principal diferencia entre las dos API es la cantidad de solicitudes que se requieren para procesar una consulta. La API masiva 2.0 se introdujo para reducir este número a un mínimo de tres solicitudes en comparación con un mínimo de seis para la API masiva original.
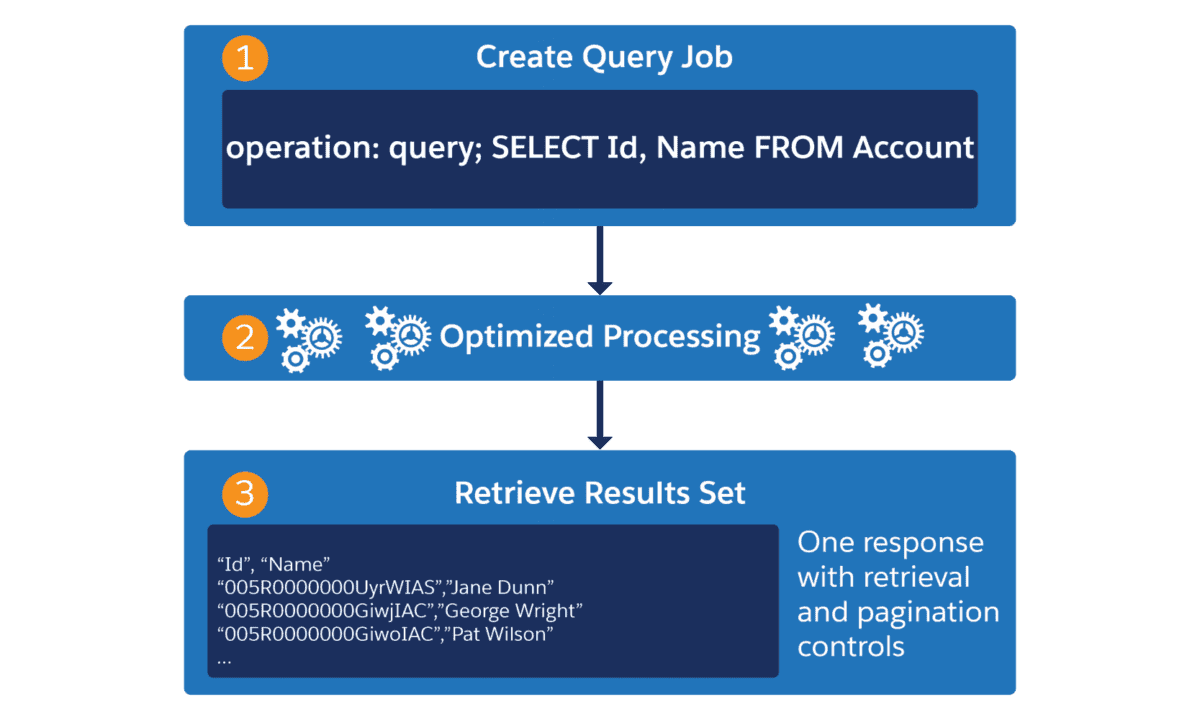
Aquí hay un diagrama que ilustra las solicitudes requeridas para una consulta de Bulk API 2.0:

- El cliente envía una primera solicitud que crea e inicia un trabajo de consulta y especifica una consulta SOQL.
- Mientras se procesa la consulta, el cliente realiza llamadas para sondear el estado del trabajo.
- Una vez que se completa el trabajo, el cliente puede recuperar los resultados de la consulta en una sola solicitud.
En comparación, el siguiente diagrama presenta la misma consulta con la API masiva original:

- El cliente envía una primera solicitud que crea un trabajo de consulta.
- El cliente puede agregar uno o más lotes de consultas al trabajo con consultas SOQL.
- Una vez que se agregan los lotes, el cliente cierra el trabajo para que pueda ejecutarse.
- Mientras se ejecuta el trabajo, el cliente sondea el estado del trabajo.
- Una vez que se completa el trabajo, el cliente obtiene los ID de resultado del trabajo.
- Gracias a los ID de resultados del trabajo, el cliente obtiene los datos de los resultados.
Además del mayor número de solicitudes, y a partir de Winter '23 (API v56.0), la API masiva original aún conserva una ventaja sobre la API masiva 2.0: la variedad de formatos admitidos. La API masiva original acepta y produce CSV, XML o JSON. Los datos binarios también son compatibles con las operaciones de ingesta. Por el contrario, Bulk API 2.0 solo funciona con CSV.
Independientemente del tipo de API masiva que utilice, asegúrese de habilitar la compresión para las respuestas de la API. Todo lo que necesita hacer es pasar un encabezado Accept-Encoding: gzip en su solicitud al recuperar los conjuntos de resultados. Este pequeño cambio marcará una gran diferencia en términos de rendimiento.
palabras de cierre
Ahora puede echar un vistazo a las diferentes opciones de API para leer datos a escala. La cantidad de registros que desea procesar debe ser el factor principal para elegir la API correcta para el trabajo correcto, pero tenga en cuenta otras limitaciones. Asegúrese de consultar la documentación de la API (consulte las guías en la sección de recursos) para comprender los casos de uso correctos y los límites para estas API. También le recomiendo que utilice nuestra colección Postman de API de Salesforce Platform para probar las diferentes API antes de implementar un nuevo cliente.
Estén atentos a la segunda publicación de esta serie en la que nos centraremos en las operaciones de escritura con las API masivas y la API compuesta.
Te dejamos esta tabla que proporciona un buen resumen de las diferencias clave entre estas API para operaciones de lectura:
| API REST con localizador de consultas |
API REST con paginación |
API masiva | API masiva 2.0 | |
|---|---|---|---|---|
| Tipo de operación | Solo lectura | Crear, leer, actualizar, modificar y eliminar | ||
| Número máximo de registros devueltos por consulta | 2000 registros por respuesta | De varios cientos de miles a millones de registros (ver documentación para más detalles) |
||
| Tipo de proceso | Sincrónico | Asincrónico | ||
| Número mínimo de tipos de solicitudes para obtener el primer lote de resultados | 1 | 6 | 3 | |
| Formatos admitidos | JSON o XML | CSV, JSON o XML + binario (solo ingesta) |
CSV | |
| Vida útil de los resultados de la consulta | 2 días | N/A siempre que los valores del campo de pedido no cambien durante el cruce de resultados | 7 días | |
Recursos
Sobre el Autor
Philippe Ozil es un defensor principal de desarrolladores en Salesforce, donde se enfoca en la plataforma de Salesforce. Escribe contenido técnico y habla con frecuencia en conferencias. Es un desarrollador de pila completa y disfruta trabajar en proyectos DevOps, robótica y realidad virtual. Sígalo en Twitter @PhilippeOzil o consulte sus proyectos de GitHub @pozil .
Obtenga las últimas publicaciones de blog de desarrolladores de Salesforce y episodios de podcast a través de Slack o RSS.
Agregar a Slack Suscríbete a RSS

…
Esta es una traducción realizada por EGA Futura, y este es el link a la publicación original: https://developer.salesforce.com/blogs/2022/12/processing-large-amounts-of-data-with-apis-part-1-of-2.html