Todo el mundo quiere aplicaciones de IA generativa y sus capacidades rompedoras, como crear contenidos, resumir textos, responder preguntas, traducir documentos e incluso razonar por sí mismas para completar tareas.
La IA generativa es una de las tecnologías más avanzadas del mundo
¿Pero por dónde empezar? Cómo añadir grandes modelos lingüísticos (LLM) a su infraestructura para empezar a impulsar estas aplicaciones? ¿Debe entrenar su propio LLM? ¿Personalizar un modelo de código abierto preentrenado? ¿Utilizar modelos existentes a través de API?
Entrenar su propio LLM es una tarea desalentadora y costosa. La buena noticia es que no tiene por qué hacerlo. El uso de los LLM existentes a través de las API le permite liberar el poder de la IA generativa hoy mismo y ofrecer innovaciones de IA que cambian las reglas del juego rápidamente.
La IA generativa es una de las tecnologías más avanzadas del mundo
¿Cómo puede un LLM genérico generar resultados relevantes para su empresa? Al añadir las instrucciones correctas y los datos de base a la solicitud, puede dar a un LLM la información que necesita para aprender «en contexto» y generar resultados personalizados y relevantes, incluso si no se ha entrenado con sus datos.
Cómo puede un LLM genérico generar resultados relevantes para su empresa?
Tus datos te pertenecen, y pasárselos a un proveedor de API puede suscitar preocupaciones sobre la posibilidad de poner en peligro información sensible. Ahí es donde entra en juego la capa de confianza de Einstein. (Más sobre esto más adelante.)
¿Qué es un LLM?
Los modelos de lenguaje amplio (LLM) son un tipo de IA que puede generar respuestas similares a las humanas procesando entradas de lenguaje natural.



En esta entrada de blog, repasaremos las diferentes estrategias para trabajar con LLMs, y profundizaremos en la opción más sencilla y más utilizada: utilizar LLMs existentes a través de APIs.
Los LLMs
Como vicepresidente senior de relaciones técnicas con el público de Salesforce, a menudo trabajo con mi equipo para probar cosas en la empresa. Estoy aquí para guiarle a través de cada opción para que pueda tomar una decisión informada
1. Forma a tu propio LLM. Forma a tu propio LLM (Pista: No tienes que hacerlo)
Entrenar tu propio modelo te da control total sobre la arquitectura del modelo, el proceso de entrenamiento y los datos de los que aprende tu modelo. Por ejemplo, podría entrenar su propio LLM con datos específicos de su sector: Es probable que este modelo genere resultados más precisos para los casos de uso específicos de su dominio que un modelo de uso general
Pero entrenar tu propio LLM desde cero también tiene algunos inconvenientes:
- Tiempo: puede llevar semanas o incluso meses.
- Tiempo: puede llevar semanas o incluso meses
- Recursos: Necesitará una cantidad significativa de recursos computacionales, incluyendo GPU, CPU, RAM, almacenamiento y redes.
- Experiencia: Necesitará un equipo de ingenieros especializados en aprendizaje automático (ML) y procesamiento del lenguaje natural (NLP)
- Seguridad de los datos: Los LLM aprenden a partir de grandes cantidades de datos: cuantos más, mejor. La seguridad de los datos en su empresa, por otro lado, suele regirse por el principio del menor privilegio: Das a los usuarios acceso sólo a los datos que necesitan para hacer su trabajo específico. En otras palabras, cuantos menos datos, mejor. Equilibrar estos principios opuestos puede que no siempre sea posible.
- Los usuarios deben tener acceso a los datos que necesitan para realizar su trabajo
3. Utilizar modelos existentes a través de API
La última opción es utilizar modelos existentes (de OpenAI, Anthropic, Cohere, Google y otros) a través de APIs. Es de lejos el enfoque más fácil y más comúnmente utilizado para construir aplicaciones potenciadas por LLM. ¿Por qué?
- No necesitas dedicar tiempo y recursos a formar tu propio LLM.
- Por qué?
- No necesita ingenieros especializados en ML y NLP.
- No necesita ingenieros especializados en ML y NLP.
- No necesita ingenieros especializados en ML y NLP
- Debido a que la consulta se incorpora dinámicamente en el flujo de trabajo de los usuarios, solo incluye datos a los que tienen acceso.
¿El inconveniente de este enfoque? Estos modelos no han sido entrenados con los datos contextuales y privados de tu empresa. Así que, en muchos casos, el resultado que producen es demasiado genérico para ser realmente útil.
Empieza hoy mismo con un LLM
La Plataforma Einstein 1 te ofrece las herramientas que necesitas para crear fácilmente tus propias aplicaciones impulsadas por LLM.



Una técnica común llamada aprendizaje en contexto puede ayudarle a evitar esto. Puedes basar el modelo en tu realidad añadiendo datos relevantes a la pregunta
Por ejemplo, compare las dos indicaciones siguientes:
Propuesta nº 1 (no fundamentada con datos de la empresa):
Escriba un correo electrónico de presentación al CEO de Acme.
Prompta #2 (fundamentada con datos de la empresa):
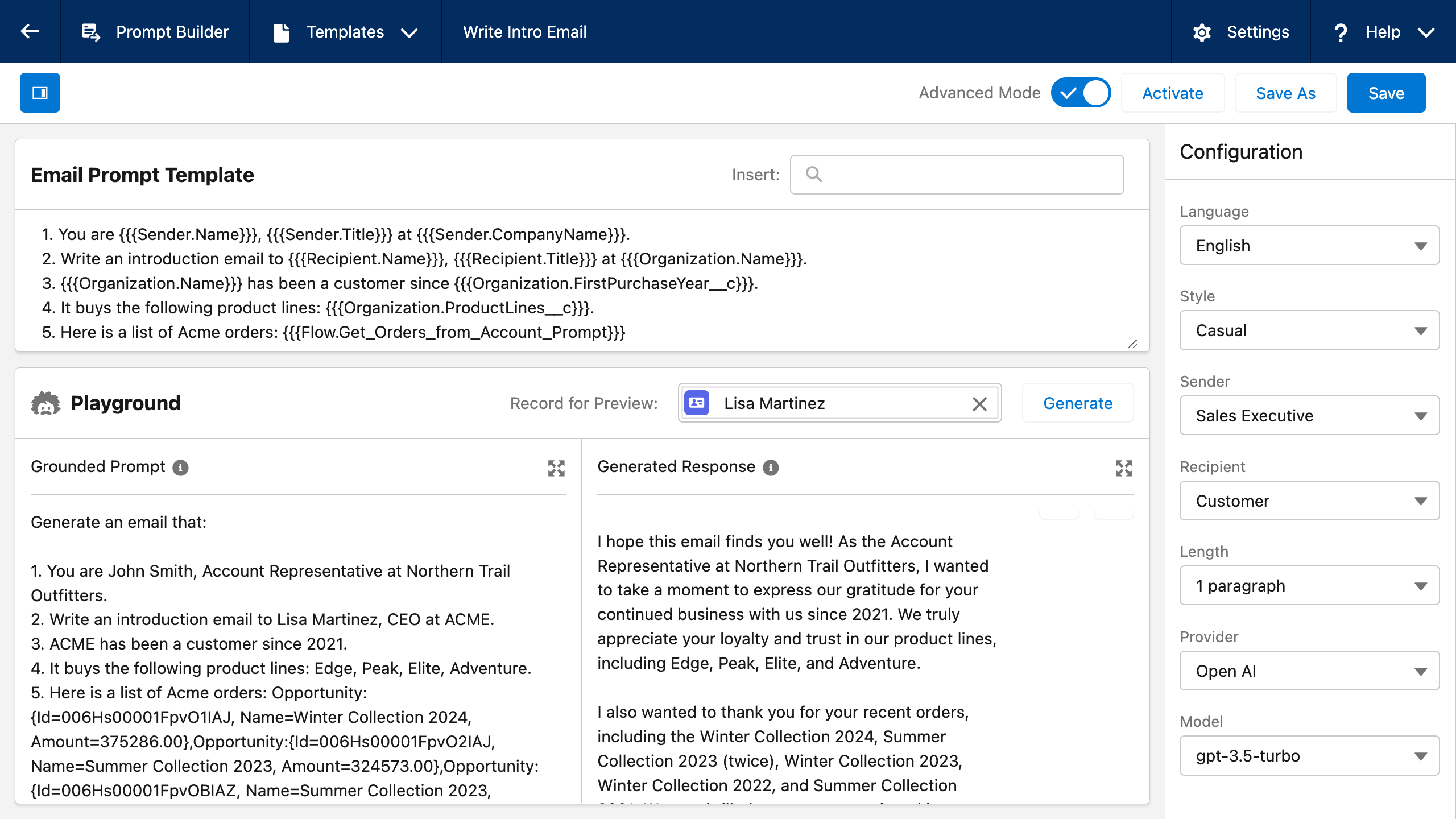
Usted es John Smith, representante de cuentas en Northern Trail Outfitters.
Escriba un correo electrónico de presentación a Lisa Martinez, Directora General de ACME.
Su nombre es John Smith
Acme es cliente desde 2021.
Compra las siguientes líneas de productos: Edge, Peak, Elite, Adventure.
Aquí tiene una lista de pedidos de Acme:
Colección de invierno 2024: 375.286 dólares
Colección de verano 2023: 402.255 $
Colección de invierno 2023: 357.542 $
Colección de verano 2022: 324.573 dólares
Colección Invierno 2022: 388.852 dólares
Colección de Verano 2021: $312,899
Dado que el modelo no dispone de datos relevantes de la empresa, la salida generada por el primer prompt será demasiado genérica para ser útil. Al añadir los datos del cliente a la segunda pregunta, el LLM obtiene la información que necesita para aprender «en contexto» y generar resultados personalizados y relevantes, aunque no haya sido entrenado con esos datos
Cuantos más datos de base se añadan a la pregunta, mejor será el resultado generado. Sin embargo, no sería realista pedir a los usuarios que introduzcan manualmente esa cantidad de datos de base para cada solicitud
Por suerte, Prompt Builder de Salesforce puede ayudarle a escribir estas solicitudes basadas en los datos de su empresa. Esta herramienta le permite crear plantillas de avisos en un entorno gráfico y vincular campos de marcadores de posición a datos dinámicos disponibles a través de la página Registro, flujos, Data Cloud, llamadas Apex o llamadas API.
Prompt Builder de Salesforce puede ayudarle a escribir estos avisos basados en los datos de su empresa
Pero añadir datos de la empresa a la solicitud plantea otro problema: Es posible que esté pasando datos privados y confidenciales al proveedor de API, donde podrían almacenarse o utilizarse para entrenar el modelo.
Datos de la empresa
Utiliza los LLM existentes sin comprometer tus datos
Aquí es donde entra en juego Einstein Trust Layer. Entre otras capacidades, la Capa de Confianza de Einstein te permite utilizar modelos existentes a través de APIs de forma fiable, sin comprometer los datos de tu empresa. Así es como funciona:
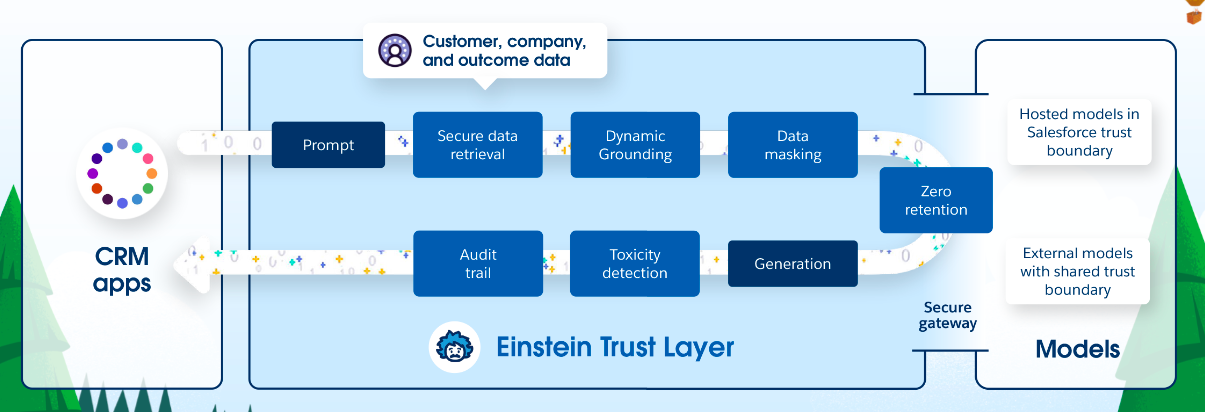
- Pasarela segura: En lugar de realizar llamadas directas a la API, se utiliza la pasarela segura de Einstein Trust Layer para acceder al modelo. La pasarela admite diferentes proveedores de modelos y abstrae las diferencias entre ellos. Incluso puede conectar su propio modelo si ha utilizado los enfoques de formación de su propio modelo o personalización descritos anteriormente
- Enmascaramiento de datos y conformidad: Antes de que la solicitud se envíe al proveedor del modelo, pasa por una serie de pasos que incluyen el enmascaramiento de datos, que sustituye los datos de información personal identificable (PII) por datos falsos para garantizar la privacidad de los datos y el cumplimiento de la normativa.
- Los datos de PII se envían al proveedor del modelo a través de un proceso de enmascaramiento
- Cero retención: Para proteger aún más sus datos, Salesforce tiene acuerdos de retención cero con los proveedores de modelos, lo que significa que los proveedores no persistirán ni seguirán entrenando sus modelos con los datos enviados desde Salesforce.
- Los datos se almacenan en la base de datos de Salesforce
- Enmascaramiento, detección de toxicidad y registro de auditoría: Cuando se recibe la salida del modelo, ésta pasa por otra serie de pasos, entre los que se incluyen el desenmascaramiento, la detección de toxicidad y el registro de auditoría. El desenmascaramiento restaura los datos reales que fueron sustituidos por datos falsos en aras de la privacidad. La detección de toxicidad comprueba si hay contenido dañino u ofensivo en el resultado. El registro de pista de auditoría graba todo el proceso con fines de auditoría.
- El registro de pista de auditoría graba todo el proceso con fines de auditoría
Cómo funciona la plataforma Einstein 1
La Plataforma Einstein 1 abstrae la complejidad de los grandes modelos lingüísticos. Te ayuda a empezar hoy con los LLM y a establecer una base sólida para el futuro. La plataforma Einstein 1 impulsa la próxima generación de aplicaciones Salesforce CRM (ventas, servicio, marketing y comercio) y le proporciona las herramientas que necesita para crear fácilmente sus propias aplicaciones impulsadas por LLM. Aunque Einstein 1 está diseñado para admitir las diferentes estrategias mencionadas anteriormente (entrenar su propio modelo, personalizar un modelo de código abierto o utilizar un modelo existente a través de API), está configurado de forma predeterminada para utilizar la estrategia «utilizar modelos existentes a través de API», que le permite desbloquear la potencia de los LLM hoy mismo y le proporciona el camino más rápido hacia la innovación en IA
La combinación de Prompt Builder y Einstein Trust Layer de Einstein 1 Platform te permite aprovechar los LLMs sin tener que entrenar tu propio modelo:
La combinación de Prompt Builder y Einstein Trust Layer te permite aprovechar los LLMs sin tener que entrenar tu propio modelo:
- Prompt Builder te permite cimentar prompts en los datos de tu empresa sin necesidad de entrenar un modelo en esos datos.
- La capa de confianza de Einstein le permite realizar llamadas API a los LLM sin comprometer los datos de la empresa.
- La capa de confianza de Einstein le permite realizar llamadas API a los LLM sin comprometer los datos de la empresa
| Recursos computacionales | Ingenieros deML y NLP | Resultados relevantes | Tiempo para innovar | ||
| Entrena tu propio modelo | Más alto | Sí | Más alto | Más lento. Entrenar un modelo puede llevar meses | |
| Personalizar un modelo de código abierto | Medio | Sí | Medio | Medio. También puede llevar meses | |
| Utilizar un modelo existente a través de APIs | Más bajo | No | Más bajo | Más rápido. Comience inmediatamente con llamadas a API | |
| Utilice un modelo existente a través de API con aprendizaje en contexto potenciado por Prompt Builder y Einstein Trust Layer | Lowest | No | High | Fastest. Comienza inmediatamente con llamadas a la API |
A la última: las tendencias más frescas en IA generativa para ventas
Descubra cómo más de 1.000 vendedores están utilizando la IA generativa en el trabajo, y conozca las áreas de interés para cerrar la brecha de confianza que aún persiste.

