
P. ¿Diferencia entre Bulk Api Vs Data Loader?
- Dataloader es bueno para insertar hasta 5 millones de registros .
- La API masiva le permite ejecutar las inserciones en el cargador de datos de forma asincrónica . Usando el modo serial, se puede procesar un lote de 200 registros a la vez. El modo serial es mejor que el paralelo a la contención de la base de datos.
- La API masiva es muy rápida cuando se trabaja con grandes conjuntos de datos, como 2 millones. La API SOAP, la predeterminada del cargador de datos, será comparativamente lenta a la API Bulk.
P. ¿Podemos importar objetos de historial en Salesforce usando el cargador de datos?
El historial no se puede crear porque AccountHistory, CaseHistory y ContactHistory no admiten la operación create ().
“Tenga en cuenta que no es posible insertar directamente en las tablas Historial de oportunidades o Historial de casos. Estas tablas contienen principalmente la información del historial de auditoría de campo de los registros de oportunidades o casos. Si es necesario migrar dichos datos, debe migrar estos datos a un objeto personalizado de solo lectura «.
P. ¿Cuándo utilizar el cargador de datos?
Necesita cargar entre 50.000 y 5.000.000 registros. Data Loader es compatible con cargas de hasta 5 millones de registros. Si necesita cargar más de 5 millones de registros, use un producto de App Exchange.
P. ¿Podemos utilizar el nombre del tipo de registro en el cargador de datos al importar los datos?
No puede utilizar el nombre del tipo de registro en el cargador de datos para asignar a un tipo de registro. Deberá utilizar RecordTypeId para este propósito.
Cambiar los tipos de registro para varios registros a través del cargador de datos no es tan sencillo como parece. En lugar de utilizar el nombre del tipo de registro, se requiere el uso del ID del tipo de registro recopilado a través de la URL.
P. Quiero poder exportar los campos de cuenta relacionados para cada cotización en Salesforce usando Data Loader. ¿Es posible?
Puede exportar los valores de los atributos padre y padre desde el objeto hijo. Pero desde el padre, no puede exportar atributos relacionados con el objeto hijo.
Puede pasar a 5 niveles hasta el Padre u objetos relacionados.
Como no podemos consultar las relaciones de claves externas a más de 5 niveles de la raíz SObject
por lo tanto, el máximo hasta este nivel es compatible con Cotización:
Oportunidad.cuenta.Parent.Parent.Parent.Name
En el siguiente ejemplo, he mostrado cómo pasar de
Cotización -> Oportunidad -> Cuenta para padres -> Cuenta para padres.
Ejemplo
SELECCIONAR ID, Nombre,
OpportunityId,
Oportunidad.Nombre,
Opportunity.Account.Name,
Opportunity.Account.Id,
Opportunity.Account.ParentId,
Oportunidad.cuenta.Parent.Name
DESDE Cotización
Resultados

P. ¿Qué elementos no se pueden migrar con el cargador de datos?
- Los metadatos personalizados que son un registro de metadatos no se pueden migrar a través de Data Loader.
- Los eventos de plataforma no se pueden migrar.
- historial del objeto no podremos migrar porque el historial se crea automáticamente cuando cualquier cambio realizado por el usuario en el registro y también no tiene atributos creables y actualizables.
P. Quiero cargar archivos (.doc, .pdf) desde un sistema externo a los archivos adjuntos del registro del caso. ¿Cuál es el mejor enfoque?
Podemos ir con el cargador de datos usando SOAP API, que es por defecto (no Bulk API).
¿Por qué?
- No es necesario escribir ningún código para utilizar el cargador de datos
- Es una solución probada, por lo que no hay errores.
- Con SOAP API, necesitará alrededor de 500+ API (100000 registros / 200 tamaño de lote = 500 API requeridas) que no es demasiado (tenemos un límite de 100k API por 24 HRS para organizaciones empresariales).
- Además, dependiendo de los datos y el esquema, puede haber un problema de bloqueo con la API Bulk.
- La API masiva no permite un tamaño de archivo zip superior a 10 MB.
P. ¿Qué hacer cuando la inserción de carga de datos causa un bloqueo de datos?
Dado que su trabajo por lotes se ejecuta en paralelo en todos sus lotes , los lotes pueden intentar obtener bloqueos de forma independiente en la misma Cuenta, lo que genera esta excepción.
Las dos técnicas que suelen aplicarse son
- Ordene sus datos entrantes por Id. De registro principal, para evitar que los registros de diferentes lotes compitan por el bloqueo del principal.
- Asegúrese de que el Cargador de datos esté configurado para utilizar la API Bulk en modo serial, en lugar del modo paralelo.
«Habilitar el modo serial para API Bulk». Esto significa que su trabajo todavía se ejecutará técnicamente de forma asincrónica, pero eliminará la capacidad de ejecutarse en paralelo. Esta casilla de verificación es una buena opción para la resolución de problemas si observa números elevados, pero aumenta el tiempo de ejecución cuando le indica a Data Loader que debe procesar un lote a la vez.
P. ¿Cómo configurar Bulk API en el cargador de datos?
La API Bulk está optimizada para cargar o eliminar una gran cantidad de registros de forma asincrónica. Es más rápido que la API basada en SOAP debido al procesamiento paralelo y menos viajes de ida y vuelta de la red. De forma predeterminada, Data Loader utiliza la API basada en SOAP para procesar registros.
Para configurar el Cargador de datos para utilizar la API masiva para insertar, actualizar, insertar, eliminar y eliminar registros de forma permanente:
- Abra el Cargador de datos.
- Elija Configuración | Configuraciones .
- Seleccione la opción Usar API masiva.
- Haga clic en Aceptar .
P. ¿Qué es el modo serial para la opción Bulk API?
También puede seleccionar la opción Habilitar modo serial para API masiva. El procesamiento en paralelo puede causar contención de la base de datos. Cuando la contención es severa, la carga puede fallar. El modo serial procesa los lotes de uno en uno; sin embargo, puede aumentar el tiempo de procesamiento de una carga.
P. ¿Podemos realizar una eliminación completa cuando configuramos el cargador de datos para usar la API masiva?
Puede eliminar registros de forma definitiva cuando configure el Cargador de datos para usar API masiva. Tenga en cuenta que los registros eliminados de forma permanente se eliminan de inmediato y no se pueden recuperar de la Papelera de reciclaje.
P. ¿Cargador de datos frente al asistente de importación?
Utilice el Cargador de datos cuando:
- Necesita cargar entre 50.000 y 5.000.000 registros. Data Loader es compatible con cargas de hasta 5 millones de registros. Si necesita cargar más de 5 millones de registros.
- Debe cargar en un objeto que aún no es compatible con los asistentes de importación.
- Desea programar cargas de datos regulares, como importaciones nocturnas.
- Quiere exportar sus datos con fines de copia de seguridad.
Utilice los asistentes de importación cuando:
- Está cargando menos de 50.000 registros.
- El objeto que necesita importar es compatible con asistentes de importación.
- Desea evitar duplicados cargando registros de acuerdo con el nombre de la cuenta y el sitio, la dirección de correo electrónico de contacto o la dirección de correo electrónico principal.
P. ¿Qué es el tamaño de lote en el cargador de datos?
En una sola operación de inserción, actualización, inserción o eliminación, los registros que se mueven hacia o desde Salesforce se procesan en incrementos de este tamaño. El máximo es 200 registros . Valor recomendado entre 50 y 100.
El valor máximo es 10,000 si se selecciona la opción Usar API masiva.
P. ¿Cómo adjuntar archivos zip usando Data Loader?
Seleccione esta opción para utilizar Bulk API para cargar archivos zip que contienen archivos adjuntos binarios, como registros de archivos adjuntos o contenido de Salesforce CRM.
Esta opción solo está disponible si se selecciona la opción Usar API masiva.
P. ¿Cómo se agrega la regla de asignación en el cargador de datos?
Especifique el ID de la regla de asignación que se utilizará para inserciones, actualizaciones y actualizaciones. Esta opción se aplica a inserciones, actualizaciones y actualizaciones en casos y clientes potenciales.
1. Cree una regla de asignación de clientes potenciales
2. Ponga la asignación reglamentada en la configuración del cargador de datos
Nota: no funcionará si se convierte el estado del cliente potencial
P. ¿Cómo importar archivos adjuntos usando el cargador de datos?
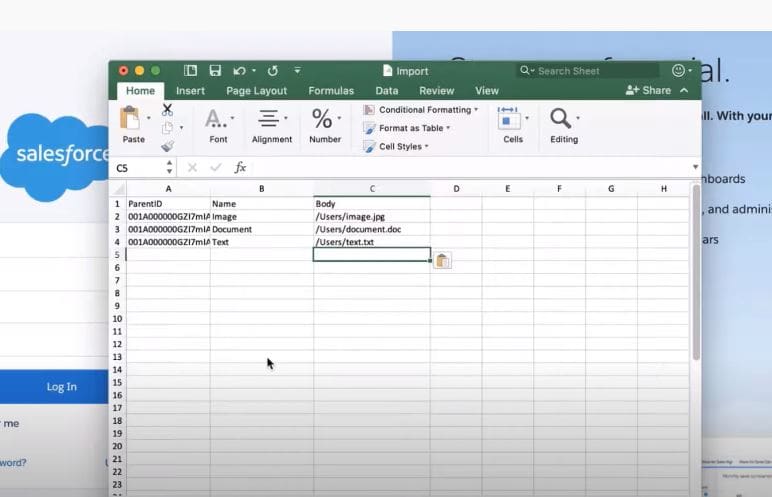
Cree un archivo attachments.csv (el nombre del archivo no es importante) con los siguientes encabezados de columna:
ParentId: ID del registro al que se debe asociar el archivo adjunto
Nombre: nombre del archivo adjunto
ContentType: formato de la extensión (p. Ej., .Xls, .pdf, etc.)
OwnerID: ID del propietario del archivo adjunto
Cuerpo: ruta del archivo al archivo adjunto en la máquina local (C: documentos y configuraciónschundesktopattachmentsfile.xls)
Inicie sesión en el cargador de datos.
Seleccione el comando «Insertar».
En el paso ‘Seleccionar objeto Sforce’, seleccione la casilla de verificación ‘Mostrar todos los objetos Sforce’ y luego seleccione «Archivos adjuntos».
Elija el archivo attachments.csv.
En el paso de mapeo, mapee los siguientes campos:
Identificación de los padres
Nombre
ID de propietario
Cuerpo: asegúrese de asignar la columna Cuerpo que creó anteriormente con la extensión del archivo. Así es como se designa el archivo y la ubicación de los archivos adjuntos que se insertarán.
Haga clic en «Aceptar» para continuar con la inserción. Puede que tarde unos minutos, pero los archivos adjuntos deben cargarse correctamente en su organización de Salesforce.
P. ¿Cómo importar registros relacionados (secundarios) usando una ID externa en Salesforce?
Asegúrese de que el objeto principal tenga un campo de identificación externo.
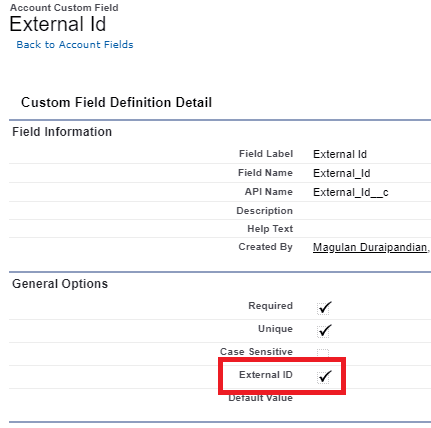
2. En el cargador de datos, utilice la operación Upsert.
Nota:
No seleccione Insertar operación. Dado que usaremos el campo Id para encontrar registros coincidentes, se insertarán todos los registros del archivo, ya que Id estará en blanco en el archivo de importación.
3. Haga coincidir los nuevos registros con el campo Id para que se inserten / creen nuevos registros en el archivo.
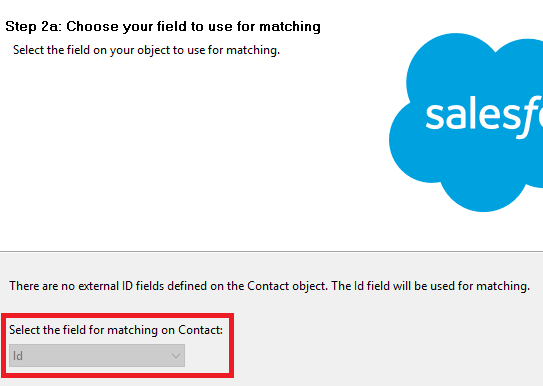
Nota:
Obtenemos este campo coincidente ya que estamos usando la operación Upsert.
4. Para la búsqueda de padres o el campo de detalles maestros, seleccione el campo Id. Externo.
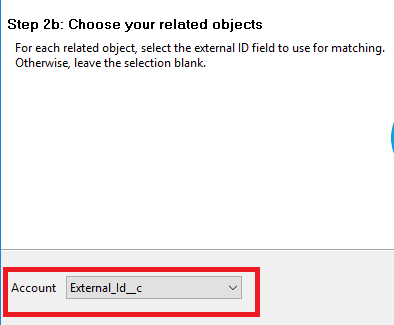
5. El mapeo mostrará el mapeo de identificación externa.
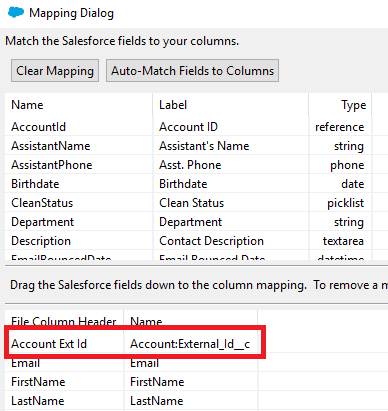
Esto evitará BUSCARV en la identificación del registro principal al insertar registros secundarios.
P. ¿Diferencia entre Id. De 15 y 18 dígitos?
Los campos de ID en la interfaz de usuario de Salesforce.com contienen cadenas de 15 caracteres, base 62, que distinguen entre mayúsculas y minúsculas. Cada uno de los 15 caracteres puede ser un dígito numérico (0-9), una letra minúscula (az) o una letra mayúscula (AZ). Dos ID únicos solo pueden ser diferentes por un cambio en el caso.
Debido a que hay aplicaciones como Access que no reconocen que 50130000000014c es un ID diferente de 50130000000014C, todas las llamadas a la API devuelven una versión de 18 dígitos, segura para mayúsculas y minúsculas. Las ID de 18 caracteres se han formado agregando un sufijo a cada ID en la API de Force.com. Las ID de 18 caracteres se pueden comparar de forma segura para determinar su exclusividad mediante aplicaciones que no distinguen entre mayúsculas y minúsculas, y se pueden usar en todas las llamadas a API al crear, editar o eliminar datos.
Si necesita convertir la ID de 18 caracteres a una versión de 15 caracteres, trunque los últimos tres caracteres. Salesforce.com recomienda que utilice el ID de 18 caracteres.
Versión de 15 dígitos que distingue entre mayúsculas y minúsculas a la que se hace referencia en la interfaz de usuario
Versión de 18 dígitos que no distingue entre mayúsculas y minúsculas a la que se hace referencia a través de la API
Los últimos 3 dígitos de la ID de 18 dígitos son una suma de comprobación de las mayúsculas de los primeros 15 caracteres; esta longitud de ID se creó como una solución para los sistemas heredados que no eran compatibles con las ID que distinguen entre mayúsculas y minúsculas.
La API aceptará el ID de 15 dígitos como entrada, pero siempre devolverá el ID de 18 dígitos.
P. ¿Podemos omitir los campos obligatorios en el cargador de datos?
Insertar los registros a través del Cargador de datos Los campos obligatorios no se pueden omitir.
P: ¿Cuáles son los campos obligatorios al insertar usuarios a través del cargador de datos ?:
- Alias
- Nombre de usuario
- Correo electrónico
- Primer nombre
- Apellido
- Configuración regional (LOCALESIDKEY)
- Idioma (LANGUAGELOCALEKEY)
- Codificación de correo electrónico (EMAILENCODINGKEY)
- Zona horaria (TIMEZONESIDKEY)
- Moneda (CURRENCYISOCODE)
- ProfileId (no es el nombre del perfil, sino el ID de 15 caracteres de la URL del perfil en la interfaz de usuario)
P. ¿Cómo diferenciar las comas dentro del campo mientras se carga usando el Cargador de datos?
El archivo CSV del cargador de datos para la importación contendrá comas para cualquier contenido del campo, deberá encerrar el contenido entre comillas dobles ”“. Data Loader podrá encontrar esto.
P. ¿Qué hacer si la eliminación completa no funciona en Apex Data Loader?
Respuesta: Verifique los permisos de su perfil La casilla de verificación «Bulk API Hard Delete» debe estar habilitada para eliminar permanentemente los registros usando Apex Data Loader. Al utilizar la operación de eliminación completa, podemos eliminar los registros existentes de nuestra organización de Salesforce de forma permanente. Los registros eliminados no estarán disponibles en la Papelera de reciclaje.
P: ¿Cómo importar valores de listas de selección de selección múltiple a través del cargador de datos?
Al utilizar el cargador de datos de Apex insertando o actualizando campos de lista de selección múltiple a través del Cargador de datos de Apex, los valores múltiples para el campo de lista de selección múltiple están separados por un punto y coma «;».
P. ¿Cómo importar datos en diferentes idiomas a Salesforce?
Siga los sencillos pasos a continuación para importar datos de diferentes idiomas utilizando el cargador de datos de Apex.
Abra el archivo .xls que muestra correctamente los demás caracteres del idioma y que se preparó para la importación.
Haga clic en Archivo -> Guardar como. En «Guardar como tipo», seleccione Texto Unicode (* .txt).
Haga clic en el botón «Guardar».
Abra el archivo .txt en el Bloc de notas.
En el Bloc de notas, haga clic en Archivo -> Guardar como, en «Nombre de archivo», cambie la extensión del archivo de .txt a .csv. «Guardar como tipo», seleccione «Todos los archivos», en «Codificación», seleccione «UTF-8», haga clic en el botón «Guardar».
Importe el archivo .csv.
P. ¿Cómo empezar a cargar datos desde la fila 101 del archivo CSV en Data Loader?
Respuesta: Abra su cargador de datos y luego la sección Menú. Vaya a Configuración -> desplácese hacia abajo y configure el campo «Comenzar en la fila» para comenzar el proceso desde el número de fila 101 del archivo CSV.
Puede ver la siguiente pantalla.
Start_at_row_in_data_loader
P. ¿Cómo podemos omitir las reglas de flujo de trabajo cuando utilizamos el cargador de datos?
No tenemos ninguna opción para omitir las reglas de flujo de trabajo, las reglas de validación y los activadores del cargador de datos. Pero podemos desactivar las reglas del flujo de trabajo mientras cargamos datos a través del cargador de datos. Pero no es una buena práctica, porque el flujo de trabajo se puede desactivar en la aplicación antes de usar el Cargador de datos, pero los usuarios pueden crear / editar registros durante este proceso que no deben interrumpirse.
P. ¿Qué es un ID externo en el cargador de datos en Salesforce?
Supongamos que tenemos una tabla de cuentas en Salesforce y una tabla de cuentas fuera de Salesforce (por ejemplo, archivo .csv, base de datos sql). En Salesforce, todos los registros se pueden identificar con una identificación de registro y fuera de Salesforce no podemos reconocer registros con una identificación de Salesforce, esa es la razón para comparar la tabla externa y la tabla de salesforce en Salesforce para uno de los campos que tenemos para habilitar la identificación externa ( podemos habilitar la identificación externa para texto, número, número automático y correo electrónico). Si habilitamos la identificación externa, podemos comparar esa columna en particular con la columna que está disponible en la tabla externa. Al comparar si los valores de ambas columnas son iguales, se actualizará; de lo contrario, se insertará.
Un campo de ID externo es simplemente un campo que es un identificador único para su registro, que no es el ID de Salesforce, que generalmente proviene de un sistema externo. Por ejemplo, si está importando cuentas, puede tener un campo llamado ‘Número de cuenta ERP‘, que es el identificador de sus cuentas dentro de su sistema ERP.
P. ¿Asignar conjunto de permisos a varios usuarios a través del cargador de datos?
Para asignar un conjunto de permisos para varios usuarios usando el cargador de datos de ápice, siga los pasos a continuación,
Cree un archivo .CSV con la identificación de usuario y la identificación del conjunto de permisos que se asignarán.
Inicie sesión en el cargador de datos de Apex.
Haga clic en el botón «Insertar».
Seleccione «Asignación de conjunto de permisos» como objeto y busque el archivo .csv creado en el paso 1
P. ¿Cómo utilizar la operación Upsert con Apex Data Loader?
La operación Upsert hace uso de la clave principal del registro de sObject (Id. De registro de Salesforce.com) o la identificación externa, si se especifica, para determinar si se deben crear nuevos registros o de lo contrario tenemos que actualizar los registros existentes.
P. ¿Cuál es el formato de archivo de mapeo archivado del cargador de datos?
.SDL ( archivo «Salesforce Data Loader» de asignación de campo)
P. ¿Cómo insertar valores nulos en el cargador de datos?
En la configuración del cargador de datos, debemos habilitar la casilla de verificación ‘insertar valores nulos’; de lo contrario, no podemos insertar valores nulos.
P. ¿Qué formato de archivo admite el cargador de datos o el asistente de importación?
.CSV (valores separados por comas)
P. ¿Qué operaciones podemos realizar en el cargador de datos?
Insertar (Insertar registros nuevos, sin necesidad de identificación)
Actualizar (Actualización de los registros existentes según el ID del registro)
Upsert (Para Upsert deberíamos tener un campo de ID externo en el objeto, basado en el campo de ID externo si el valor ya existe, se actualizará, si no existe, se insertará)
Eliminar (elimine los registros según la identificación proporcionada, para eliminar solo necesitamos la identificación, los registros eliminados se pueden encontrar en la papelera de reciclaje)
Eliminación completa (elimine los registros según la identificación proporcionada, para eliminar solo necesitamos la identificación, los registros eliminados no se pueden encontrar en la papelera de reciclaje, Nota: si habilitamos la API masiva en la configuración del cargador de datos, solo podemos realizar la eliminación completa).
Exportar (Desde cualquier objeto podemos exportar registros basados en la consulta SOQL, Nota: No podemos exportar registros eliminados que están en la papelera de reciclaje)
Exportar todo (Desde cualquier objeto podemos exportar registros basados en la consulta SOQL, Nota: Usando Exportar todos podemos exportar registros eliminados que están en la papelera de reciclaje también)
Q. ¿Pueden los usuarios transferir en masa registros a los que no tienen acceso de lectura?
Falso
P. ¿Qué formato de fecha y hora admite el archivo .csv para cargar en Salesforce?
AAAA-MM-DDThh: mm: ss.00Z
P. ¿Existe alguna opción para especificar la zona horaria para cargar registros en el cargador de datos de Apex?
Si. Presente en la página de configuración del cargador de datos de Apex.
…
Esta es una traducción realizada por EGA Futura, y este es el link a la publicación original: https://www.sfdcamplified.com/2021/04/interview-questions-on-data-loader-and-import-wizard-in-salesforce.html#utm_source=rss&utm_medium=rss&utm_campaign=interview-questions-on-data-loader-and-import-wizard-in-salesforce