¿Sabes cuál es el nombre más común en Estados Unidos (a partir de 2023)? Es James Smith. Ahora, imagínate esto: estás en tu CRM, hablando con «James Smith» de la empresa XYZ (ubicada en Delaware). ¿Es el mismo James Smith que el «James S» con el que habló tu colega, cuyas notas ves? ¿Es el «Jame S Mith» que interactuó con su campaña de marketing? ¿Y el «James Smith» de XYZ Inc. que vive en California? Todos ellos son clientes con diferentes perfiles, registros y puntos de contacto repartidos en varios sistemas. Pero, ¿me creería si le dijera que en realidad estamos hablando con la misma persona? Este es un problema común que muchas organizaciones encuentran en sus datos.
En la era digital actual, donde los datos reinan por encima de todo, las organizaciones se enfrentan a un reto formidable: dar sentido al vasto mar de información que se arremolina a su alrededor. A través de múltiples conjuntos de datos, las personas se representan de manera diferente: puede haber diferentes características, ruido, errores tipográficos, información parcial o incompleta, datos obsoletos, etc. En los distintos sectores o ámbitos, los clientes se enfrentan a diferentes requisitos de resolución de identidades. En el ámbito médico, por ejemplo, el riesgo de confundir los registros de Johnathan Smith con los de John Smith podría ser perjudicial. Por otro lado, un sector como el comercio minorista podría ser más flexible y querer asegurarse de que los usuarios se encuadran en tantos segmentos relevantes como sea posible.
Nuestro trabajo sobre la resolución de identidades pretende resolver este problema. El objetivo es identificar las mismas entidades en todos los conjuntos de datos y unificar los perfiles de origen en la mejor representación de cada cliente, pero con los datos dispersos por el paisaje virtual, esto puede ser una tarea desalentadora. Imagínese ordenar la miríada de piezas -nombres, direcciones, historial de navegación- para reconstruir una imagen clara de cada persona o entidad. La resolución de identidades es el pegamento que une los datos fragmentados, allanando el camino para servicios personalizados, mayor seguridad y conocimientos más profundos en nuestro mundo interconectado.
Nuestra investigación en IA ya está proporcionando experiencias inteligentes, como la resolución de identidades con coincidencia difusa del nombre de pila y soft-matching. Esta solución aborda el reto de la duplicación de registros al tiempo que ofrece la posibilidad de adaptar la coincidencia a diferentes sectores. Y ahora, hemos añadido control en la concordancia difusa para incluir no solo el nombre de pila, ¡sino todas las características! Al introducir la concordancia difusa en todas las características estamos potenciando a nuestro cliente al permitir criterios de concordancia más flexibles e inclusivos, acomodando variaciones en la introducción de datos personales y permitiendo un reconocimiento preciso incluso con discrepancias menores, asegurando así una experiencia de usuario más fluida y personalizada.
Descubramos la IA que impulsa esta nueva capacidad
Marco de dos pasos para la resolución de identidades
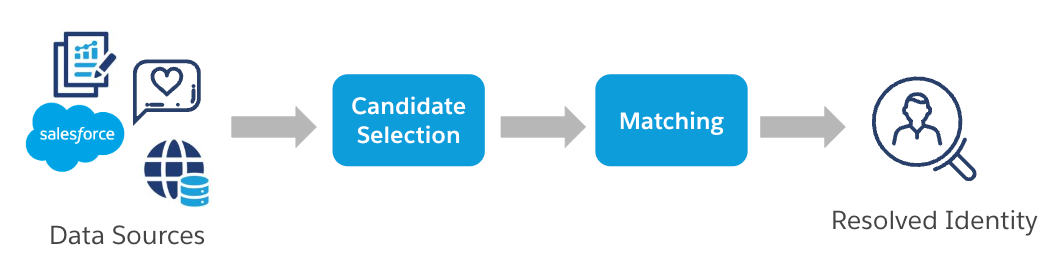
Comencemos por revisar nuestro marco general de dos pasos para la resolución de identidades. Para llevar a cabo la resolución de identidades, el primer paso tras la ingesta de datos es agrupar perfiles similares. Este paso se denomina selección de candidatos. Este paso es crucial para la eficiencia: con grupos de perfiles similares, la búsqueda de identidades coincidentes se reduce a los perfiles dentro del mismo grupo, en lugar de los millones de perfiles de todas las fuentes de datos. Una vez formados los grupos de perfiles similares, se pasa a la fase de comparación. En este paso, un perfil objetivo y sus candidatos (perfiles dentro del mismo clúster) se comparan más cuidadosamente para determinar la coincidencia final y la resolución de identidades.
Para permitir la coincidencia difusa con cualquier característica, hemos ampliado las capacidades tanto en el paso de selección de candidatos como en el de coincidencia.
Selección de candidatos basada en la incrustación
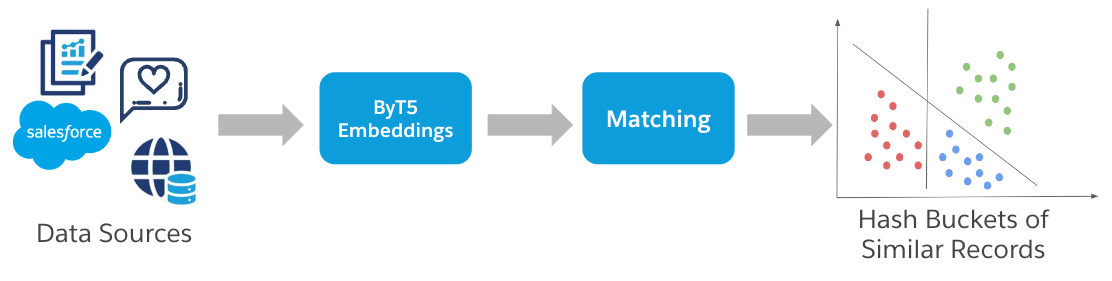
El objetivo final es permitir el emparejamiento difuso con cualquier subconjunto de características, elegido por el usuario. Pero antes de llegar a la etapa de comparación, primero tenemos que crear grupos de candidatos cercanos sobre la base de esas características. Para ello, necesitamos un método flexible que pueda encontrar candidatos similares basándose en cualquier subconjunto de características.
Para lograrlo, hemos desarrollado un método de selección de candidatos basado en la incrustación. Nuestro método primero pasa todos los registros a un modelo de incrustación, en este caso el modelo de código abierto ByT5, para crear incrustaciones, o representaciones vectoriales, de cada registro. Estas representaciones vectoriales capturan información significativa sobre el registro, y los vectores que están próximos geométricamente indican que los registros correspondientes son similares. Por ejemplo, la representación vectorial de «James Smith, California, EE.UU.» estará geométricamente próxima a la representación vectorial de «James R. Smith, CA, Estados Unidos de América».
Para aumentar la eficiencia computacional, primero cuantificamos el modelo de incrustación, reduciendo la precisión de los pesos del modelo de 32 bits a 8 bits. Esto mejora significativamente la velocidad de generación de incrustaciones. Una vez generadas todas las incrustaciones, aplicamos el hash de sensibilidad local, que genera cubos de hash, o grupos, de incrustaciones similares. Estos grupos de incrustaciones similares corresponden a registros similares. Así, para un registro objetivo, identificamos su clúster, determinado por los valores hash, y todos los registros de ese clúster se consideran los candidatos más estrechamente relacionados.
Fórmula de coincidencia para cualquier característica
Ahora que tenemos un método flexible basado en incrustaciones para encontrar candidatos similares, debemos encontrar las coincidencias reales de nuestro perfil objetivo entre los principales candidatos. Para ello, hemos desarrollado una fórmula de concordancia general, una combinación de distancias de edición y distancias metafónicas (pronunciación de palabras), para producir una puntuación de confianza de concordancia para cualquier par de cadenas, de cualquier característica.
Conclusión
La concordancia difusa consiste en identificar y vincular cadenas de texto similares, pero no idénticas. En el ejemplo anterior, hemos visto que «James Smith» y «James S» son la misma persona; con la concordancia exacta no habría habido forma de saberlo, pero con la concordancia difusa, estos dos textos eran lo suficientemente similares como para que existiera la posibilidad de que coincidieran.
Estamos encantados de anunciar la integración de la concordancia difusa en todas las funciones del objeto de contacto, proporcionando a los clientes las soluciones personalizadas que necesitan.
Explore más
Salesforce AI le invita a profundizar en los conceptos tratados en esta entrada de blog (enlaces más abajo). Conéctese con nosotros en las redes sociales y en nuestro sitio web para obtener actualizaciones periódicas sobre este y otros proyectos de investigación.
Agradecimientos
Esta nueva capacidad de Data Cloud es posible gracias a la colaboración de los equipos de AI Research y Data Cloud.
AI Research: Zhiwei Liu, Jianguo Zhang, Shelby Heinecke, Huan Wang, Caiming Xiong, Vera Serdiukova, Silvio Savarese
Data Cloud: Stanislav Georgiev, Torrey Teats, Suresh Thalamati, Srishti Hunjan, Anthony Yeung