Intro
En 2023, fuimos testigos del rápido desarrollo de la IA generativa, comenzando con el ascenso de ChatGPT. Esto condujo a un aumento en la creación de modelos lingüísticos de código cerrado (LLM) competitivos como Claude, Command y Gemini, así como modelos de código abierto como Llama-2, Mistral, incluido nuestro modelo XGen. A pesar de todos los avances y las rápidas mejoras, los problemas en estos modelos, como la tendencia a producir resultados sesgados o inconsistentes, pueden impedir que los usuarios confíen plenamente en estos sistemas.
En Salesforce, la confianza es nuestro valor número 1, y en Salesforce AI Research hemos ayudado a liderar el camino hacia la comprensión de lo que significa crear una generación de lenguaje natural (NLG) de confianza mediante el análisis de los métodos existentes, la mejora de los enfoques de modelado, la evaluación detallada y la implementación de soluciones en Salesforce Trust Layer. Salesforce Trust Layer está equipado con las mejores barreras de seguridad desde el producto hasta nuestras políticas. Diseñada para los estándares de seguridad empresarial, la capa de confianza de Einstein permite a los equipos beneficiarse de la IA generativa sin poner en peligro los datos de sus clientes.
La IA ha estado en el núcleo de los productos de Salesforce, como se muestra en la imagen siguiente, e incluso antes de esta reciente ola de trabajo LLM, Salesforce ha sido líder en IA, produciendo una investigación impactante para hacer que los modelos de IA sean más fiables.
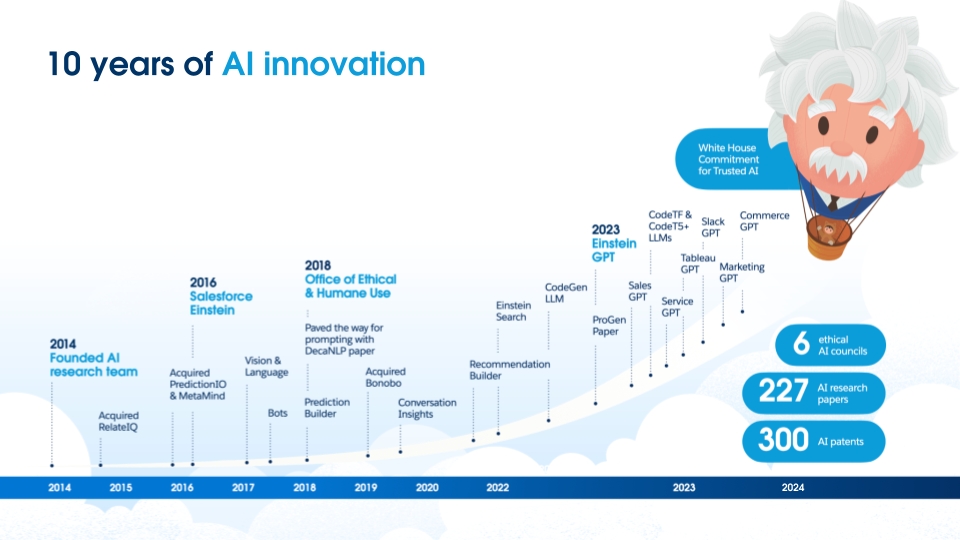
Por ejemplo, nuestro trabajo anterior se centraba en reducir el sesgo de género en los modelos de IA. También pedimos una evaluación más sólida de estos modelos y una comprensión de los errores factuales que se encuentran en tareas como el resumen. Para ayudar más a la comunidad a evaluar y comprender sus modelos, hemos lanzado herramientas de código abierto como Robustness Gym y SummVis. Robustness Gym es un conjunto de herramientas de evaluación sencillo y extensible que unifica varios paradigmas de evaluación de robustez, mientras que SummVis es una herramienta de visualización centrada en el resumen que permite a los usuarios comprender y visualizar métricas como la consistencia factual que fundamenta un resumen en su contexto de entrada.
Con la proliferación de los LLM, Salesforce ha seguido estando a la vanguardia de la investigación en IA fiable. Para que los métodos de IA sean fiables, los resultados deben ser coherentes con los datos de entrada y la evaluación debe ser sólida para comprender los puntos fuertes y débiles de los modelos. A continuación describimos brevemente algunas de nuestras contribuciones en las dimensiones de mejora de los métodos para la coherencia factual, junto con nuestro trabajo sobre la evaluación comparativa y la evaluación.
Métodos para mejorar la coherencia factual
Dentro de la mejora de la coherencia factual, parte de nuestro trabajo se ha centrado en una mejor fundamentación de las entidades que se encuentran en el contexto de entrada y en ensamblar modelos entrenados en diferentes niveles de datos ruidosos en nuestro artículo CaPE. En nuestro artículo sobre el preentrenamiento socrático, propusimos mejores formas de preentrenar un modelo que permitieran basar el resultado en preguntas importantes que pudiera plantear un usuario y, al mismo tiempo, hacer que el modelo fuera más controlable. En los casos en los que puede resultar difícil seguir entrenando un modelo, hemos propuesto varios métodos que editan la salida de un modelo existente, ya sea comprimiendo la salida o verificando el razonamiento del modelo.
Métodos de evaluación
Para comprender plenamente las mejoras introducidas por los métodos comentados anteriormente, es esencial realizar una evaluación exhaustiva. Hemos introducido métodos automáticos para evaluar si el resumen de un modelo es coherente con su contexto de entrada. Nuestros enfoques incluyen un modelo que comprueba si el resumen está vinculado a la entrada y un modelo que verifica si el contexto de entrada puede utilizarse para responder a preguntas basadas en el resumen del modelo. Sin embargo, gran parte de nuestro trabajo se centra en la construcción de puntos de referencia que pretenden comprender el estado actual del campo. Estos puntos de referencia cubren un conjunto diverso de tareas, desde la comprobación de hechos en diálogos hasta la clasificación en entornos de varios turnos para analizar si un modelo cambia o no sus respuestas a las consultas.
Varios de nuestros trabajos de evaluación comparativa se han centrado en el resumen. En nuestra evaluación comparativa AggreFact, agregamos sistemas de resumen recientes y proponemos un método para alinear sus tipos de error con el fin de realizar un análisis más exhaustivo. SummEdits propone un método eficaz para aprovechar los LLM en el proceso de anotación para el análisis de errores factuales y compara los LLM más recientes como modelos de evaluación. Con el mismo objetivo de perfeccionar los protocolos de evaluación, nuestro modelo de referencia RoSE introduce un protocolo para la evaluación humana de la relevancia de un resumen que logra un alto nivel de acuerdo entre los anotadores de los trabajadores de fuentes colectivas, y nuestro trabajo DiverseSumm se basa en las ideas de nuestros artículos anteriores sobre la evaluación y la descomposición de tareas en componentes más simples en el contexto del resumen de varios documentos.
A continuación seleccionamos dos trabajos representativos que ponen de relieve nuestros esfuerzos por mejorar la evaluación y comprender el rendimiento de los modelos en las dimensiones de calidad de la relevancia y la coherencia factual. Nuestros estudios de caso se centran en el resumen, pero podrían aplicarse a otras tareas de generación.
Estudio de caso 1: Confiar en la evaluación humana
Esta sección sigue a nuestro trabajo Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation.
Motivación
Para evaluar correctamente un sistema de resumen, el resumen de salida del modelo se evalúa con respecto a la información de la fuente, sus características intrínsecas y, potencialmente, con respecto a los resúmenes de referencia. Estas comparaciones se realizan utilizando tanto métricas de evaluación automática como evaluación humana. Esta configuración se muestra en la siguiente figura.
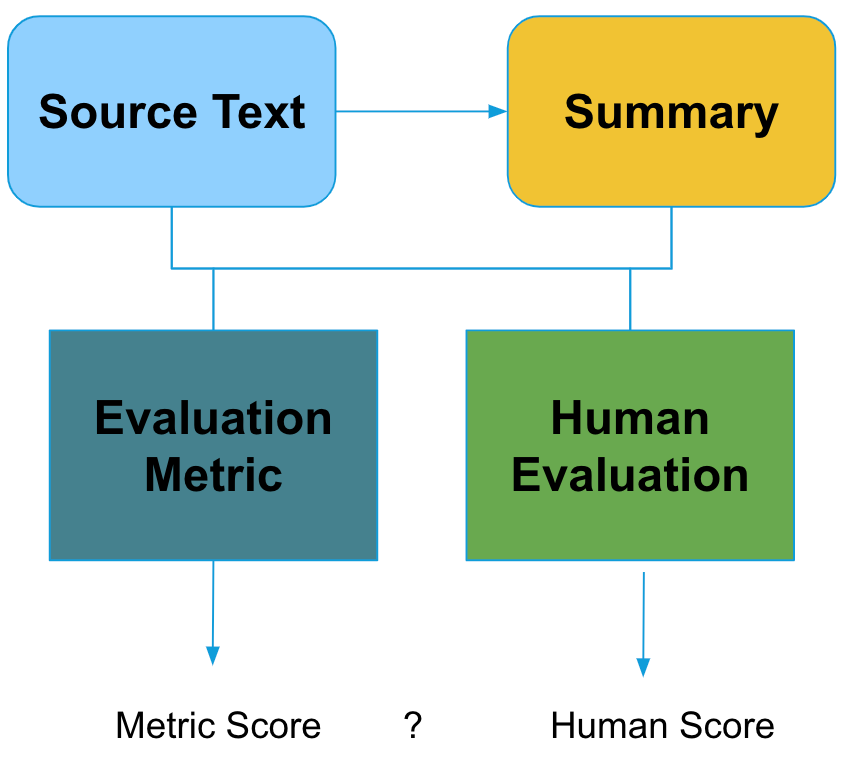
La evaluación humana se considera el patrón oro tanto para evaluar los sistemas de resumen como las métricas automáticas. Sin embargo, la mera evaluación humana no la convierte automáticamente en el «patrón oro». De hecho, es muy difícil realizar correctamente un estudio de evaluación humana, ya que los anotadores pueden no estar de acuerdo en lo que es un buen resumen y puede ser difícil extraer conclusiones estadísticamente significativas basándose en el tamaño actual de los conjuntos de evaluación.
Estas dificultades nos motivan a realizar un análisis en profundidad de la evaluación humana del resumen de textos. Nuestro primer objetivo es un mejor protocolo y punto de referencia.
Protocolo ACU
El objetivo de este protocolo es permitir a nuestros anotadores juzgar objetivamente si el resumen contiene información destacada del resumen de referencia.
Para ello, inspirándonos en el protocolo de evaluación piramidal, diseccionamos la tarea de evaluación en subtareas de grano más fino con la noción de unidades atómicas de contenido.
Tomamos el resumen de referencia y pedimos a los expertos que extraigan hechos simples, o unidades atómicas, de la referencia. La primera etapa la realizan los expertos, ya que se considera una tarea más difícil escribir las unidades. A continuación, para cada resumen generado por el sistema, comprobamos si ese hecho está presente o no. Esta segunda etapa de cotejo la realizan trabajadores de crowdsourcing. Este proceso se ilustra en la siguiente figura.
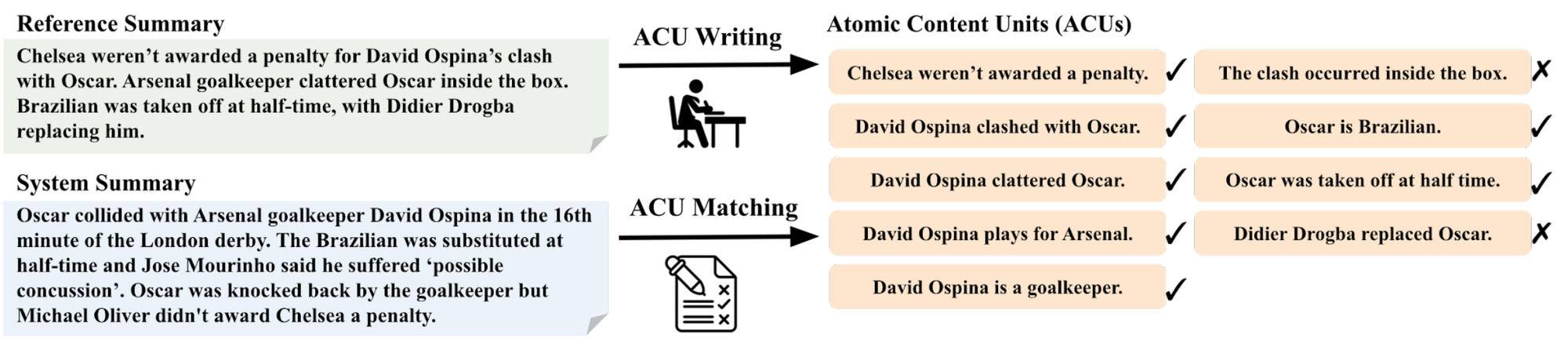
Siguiendo este protocolo, recopilamos datos de tres conjuntos de datos de resumen habituales en los ámbitos de las noticias y el diálogo. La referencia resultante, que denominamos RoSE (Robust Summarization Evaluation) contiene tres conjuntos de prueba y un conjunto de validación en el conjunto de datos CNN/DailyMail. Logramos una alta concordancia entre anotadores, con un alfa de Krippendorff de 0,75. Las estadísticas del conjunto de datos se muestran a continuación.
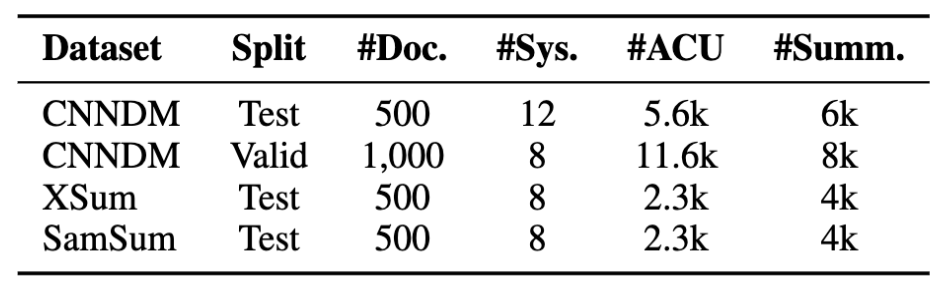
Nuestra prueba de referencia consiste en 22.000 anotaciones a nivel de resumen de 28 sistemas de alto rendimiento en tres conjuntos de datos. Los conjuntos de datos de evaluación humana estándar para el resumen suelen incluir unos 100 documentos, pero nosotros tenemos 5 veces más documentos, lo que nos permite extraer conclusiones más sólidas sobre las diferencias en el rendimiento del sistema.
Comparaciones de protocolos de evaluación
Para comprender mejor nuestro protocolo ACU, lo comparamos con otros tres protocolos de evaluación humana habituales, a saber, los protocolos que no tienen en cuenta un resumen de referencia (Prior y Ref-free) y los que comparan con una referencia (Ref-based y nuestro protocolo ACU). Para evaluar estos protocolos, recopilamos anotaciones sobre 100 ejemplos de nuestra referencia para los otros tres protocolos. El siguiente diagrama muestra lo que ve el anotador cuando anota según cada protocolo.
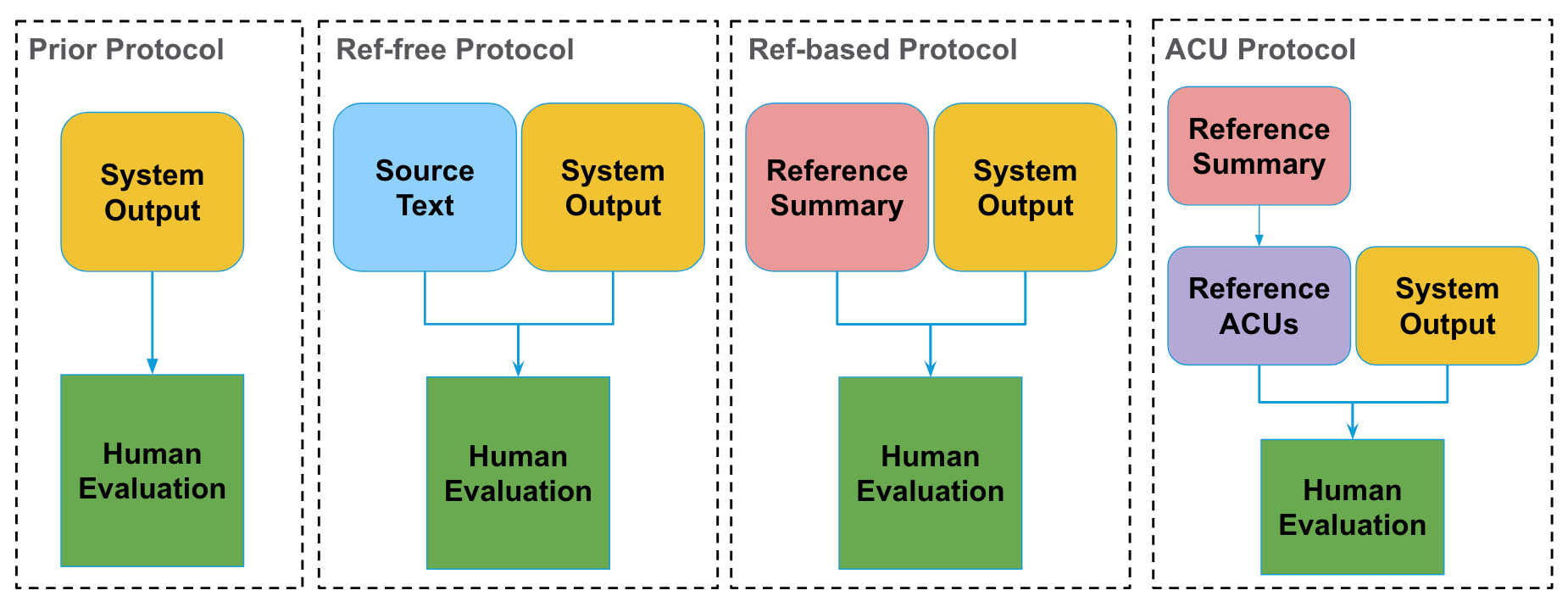
Realizamos un estudio centrado en los modelos BART y BRIO más recientes, que son modelos lingüísticos supervisados, y los LLM de disparo cero de T0 y GPT-3.5 (davinci-002). Los resultados se muestran en el diagrama siguiente.
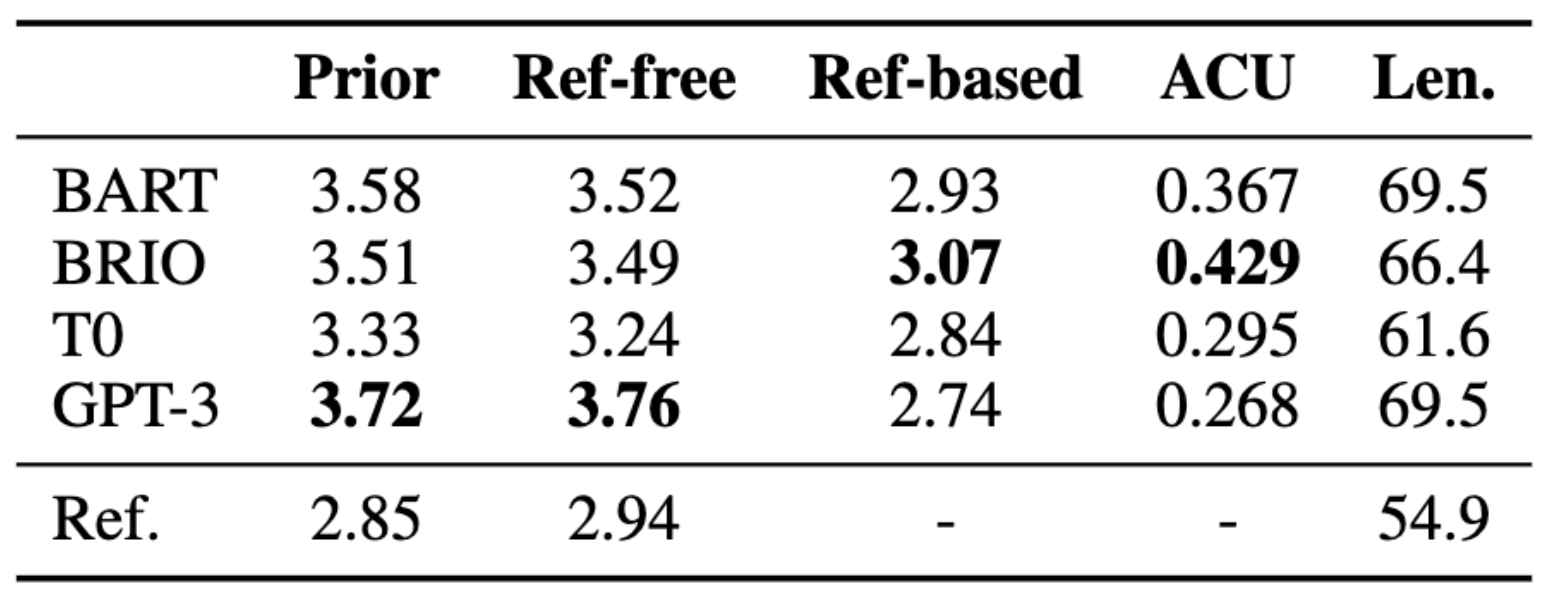
Encontramos que GPT3 funciona mejor en protocolos donde el anotador no ve la referencia, ya que no está entrenado para producir tales resúmenes. Además, hay problemas con las referencias que han sido señalados por trabajos anteriores, y no son favorecidos por los anotadores.
También analizamos los posibles factores de confusión en nuestra comparación de protocolos. Encontramos que la puntuación previa del anotador es un mejor predictor de su propia puntuación libre de referencias que si se utilizan las puntuaciones de otros anotadores; la correlación entre la puntuación previa de un anotador y la puntuación libre de referencias es de 0,404, mientras que la correlación entre la puntuación libre de referencias y la puntuación de otros anotadores es sólo de 0,188. Esto sugiere que la puntuación previa influye en la puntuación libre de referencias. Esto sugiere que la puntuación previa influye en la puntuación del juicio del anotador incluso cuando tienen acceso a los documentos.
Takeaways
Al evaluar el rendimiento del sistema, deberíamos tener objetivos claramente definidos. De lo contrario, como se ha visto anteriormente, la preferencia previa del anotador puede desempeñar un papel importante en los resultados de la evaluación.
También queremos señalar la diferencia entre la evaluación sin referencias y la basada en referencias y cómo elegir entre ellas. La evaluación basada en referencias puede ser más objetiva y fácil de realizar. Sin embargo, la evaluación basada en referencias puede ser más restrictiva, y algunos aspectos de la calidad son, por definición, libres de referencias, como la consistencia y la coherencia de los hechos. Además, la evaluación sin referencias se ajusta a técnicas de formación como RLFH; sin embargo, puede ser más ruidosa y subjetiva.
Subrayamos que una evaluación humana detallada de los protocolos puede conducir a resultados más sólidos y objetivos. El mismo principio se ha aplicado a la evaluación de varias cualidades de los resúmenes, como la consistencia y la coherencia de los hechos. Creemos que ampliar nuestro protocolo ACU a dimensiones de evaluación adicionales sin referencias es una dirección prometedora.
En general, la evaluación humana está adquiriendo aún más importancia con el progreso actual de los LLM y la introducción de técnicas de entrenamiento como RLHF, y queda mucho margen de mejora, como proponer protocolos de evaluación humana más específicos y mejorar la fiabilidad y reproducibilidad de las prácticas de evaluación humana.
Estudio de caso 2: Evaluación de referencia de confianza
Esta sección sigue nuestro trabajo SUMMEDITS: Measuring LLM Ability at Factual Reasoning Through The Lens of Summarization. Como se mencionó en la parte anterior, queremos realizar una evaluación específica de las dimensiones de calidad adicionales, y en este trabajo, nos centramos en la coherencia factual.
Motivación
Trabajos anteriores han señalado la baja concordancia entre anotadores y las variaciones en la forma en que diferentes documentos han anotado las categorías de factualidad. Esto es lamentable, ya que la factualidad debería ser una de las categorías más objetivas para anotar. Otro factor en esta anotación es que, a diferencia de una dimensión de calidad como la coherencia o nuestra anotación ACU, la evaluación de la factualidad generalmente requiere la lectura de toda la entrada, lo que puede ser muy costoso cuando sólo se anotan varios ejemplos por documento.
Principios rectores para la evaluación comparativa de la consistencia factual
Diseñamos una evaluación comparativa que incorpora varios principios de nuestro análisis de los trabajos existentes sobre la consistencia factual. En el artículo se ofrecen más detalles sobre nuestro análisis.
- Enmarcamos la evaluación de la coherencia factual como una clasificación binaria para mejorar la interpretabilidad; una clasificación de sí/no sobre si un resumen es coherente factualmente con la entrada es más interpretable que una puntuación entre 1 y 5.
- Nuestro objetivo es la coherencia factual, por lo que no queremos que factores como los errores gramaticales o de fluidez influyan en las anotaciones. Los puntos de referencia anteriores incluyen resúmenes que pueden tener imperfecciones de fluidez o formato. Eliminamos dichos resúmenes para que el anotador solo se centre en la etiqueta de coherencia factual.
- Queremos una alta concordancia entre anotadores para mejorar la reproducibilidad del protocolo, y también queremos una tarea que los humanos puedan realizar pero con la que los modelos puedan tener dificultades.
- Queremos que el punto de referencia sea diverso en una amplia gama de tipos de error y dominios.
Protocolo de anotación de summedits
Incorporamos los principios anteriores en nuestro esquema de anotación para mantener la coherencia factual.
En el primer paso, seleccionamos un documento y un resumen semilla (que pueden proceder del conjunto de datos original o ser generados por un LLM) y validamos que no contengan errores. Utilizamos un LLM para generar muchas ediciones menores de ese resumen, produciendo ediciones adicionales coherentes e incoherentes. A continuación, clasificamos manualmente cada edición como coherente, incoherente o dudosa. Eliminamos los casos dudosos para asegurarnos de que nuestro conjunto de datos sólo incluye muestras de alta calidad. A continuación se ofrece un resumen de nuestro proceso de anotación.
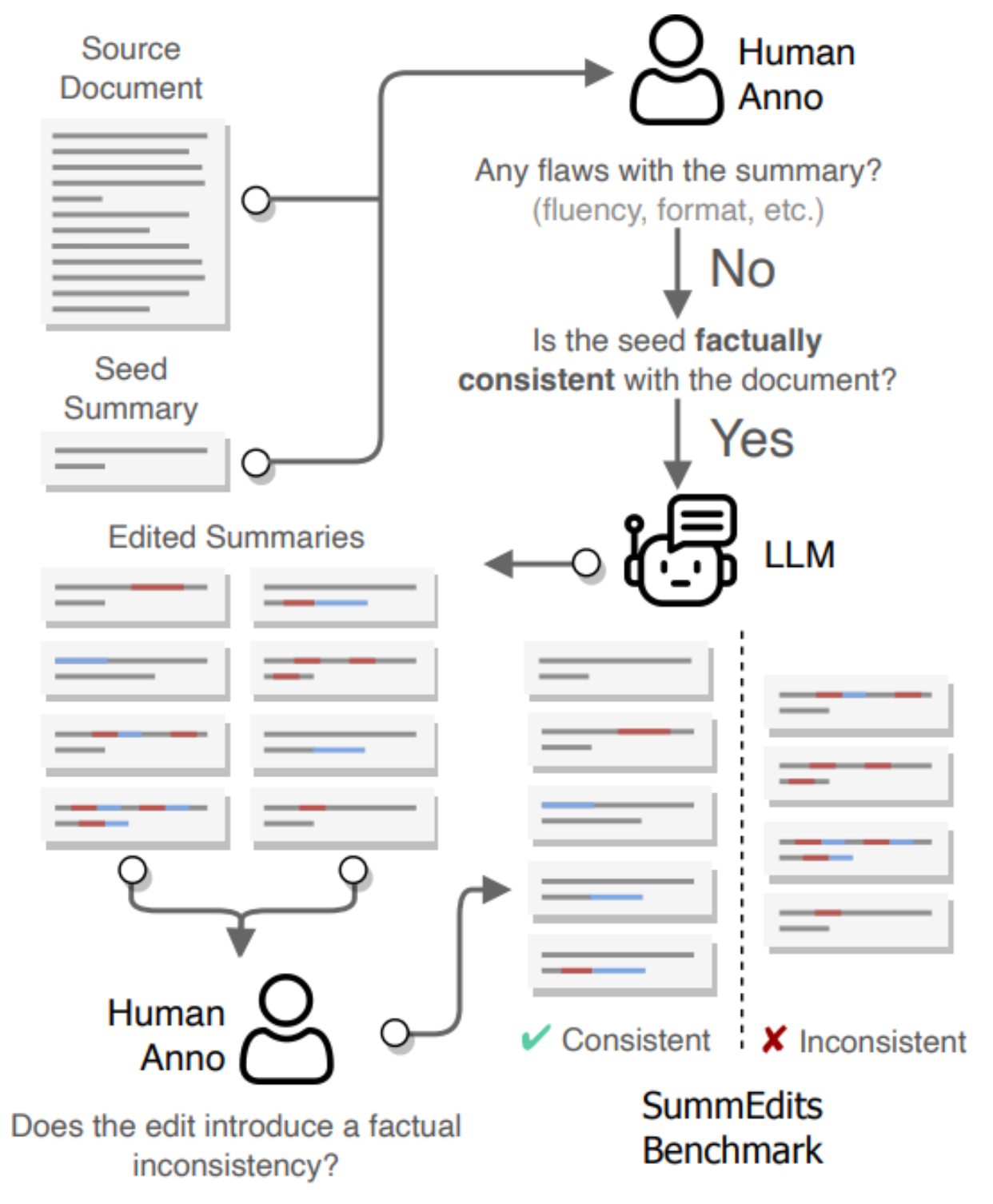
Para ser más concretos, pedimos a GPT3.5-turbo que edite el resumen de semillas modificando algunas palabras para crear ejemplos adicionales coherentes e incoherentes. Los resúmenes editados tienen una media de 3,6 palabras insertadas y 3,5 palabras eliminadas. Pedimos al modelo que genere unos 30 resúmenes modificados por documento, con lo que el anotador no tiene que leer varios documentos de entrada. Esto supone un coste de unos 300 dólares para 500 muestras anotadas. Contratamos a un editor profesional para este paso de anotación.
SummEdits Benchmark
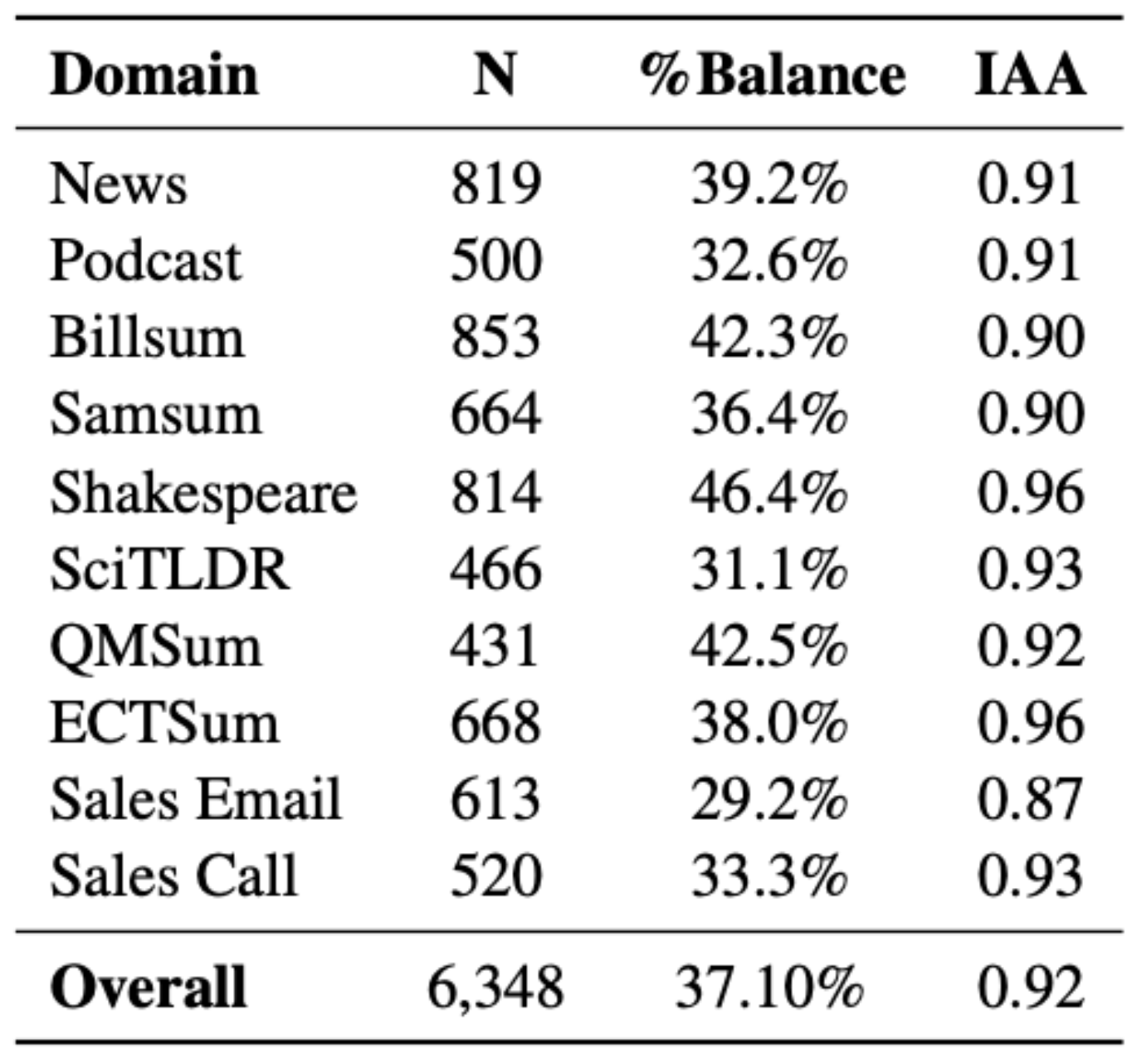
Aplicamos este enfoque en 10 dominios que van desde noticias a diálogos, textos científicos y llamadas de ventas. Para 5 de los dominios, generamos automáticamente un resumen semilla a partir del turbo GPT 3.5 debido a la falta de resúmenes de referencia existentes de alta calidad.
En el punto de referencia final, el 37% de los resúmenes son coherentes, acercándonos a nuestro objetivo de un punto de referencia equilibrado para facilitar una evaluación robusta.
Los autores del artículo anotaron el 20% de las muestras del punto de referencia como coherentes o incoherentes en cuanto a los hechos y lograron un alto acuerdo entre anotadores, e incluso mayor cuando se eliminaron los casos límite de las anotaciones iniciales. Véase la tabla siguiente para obtener una visión general de los dominios cubiertos, el tamaño del conjunto de datos y la concordancia.
Como se ha señalado, el proceso de creación de puntos de referencia es bastante eficiente, con un coste de 300 dólares por dominio. Lo comparamos con los costes estimados de un protocolo de coherencia factual anterior, FRANK, que costaría unos 6.000 dólares para producir un conjunto de datos de tamaño similar para un nuevo dominio, que luego habría que multiplicar por 10 para igualar el tamaño total de nuestro punto de referencia.
Análisis
En la tabla siguiente mostramos los resultados de precisión promediados entre dominios para SummEdits para los mejores LLM en el momento del envío.
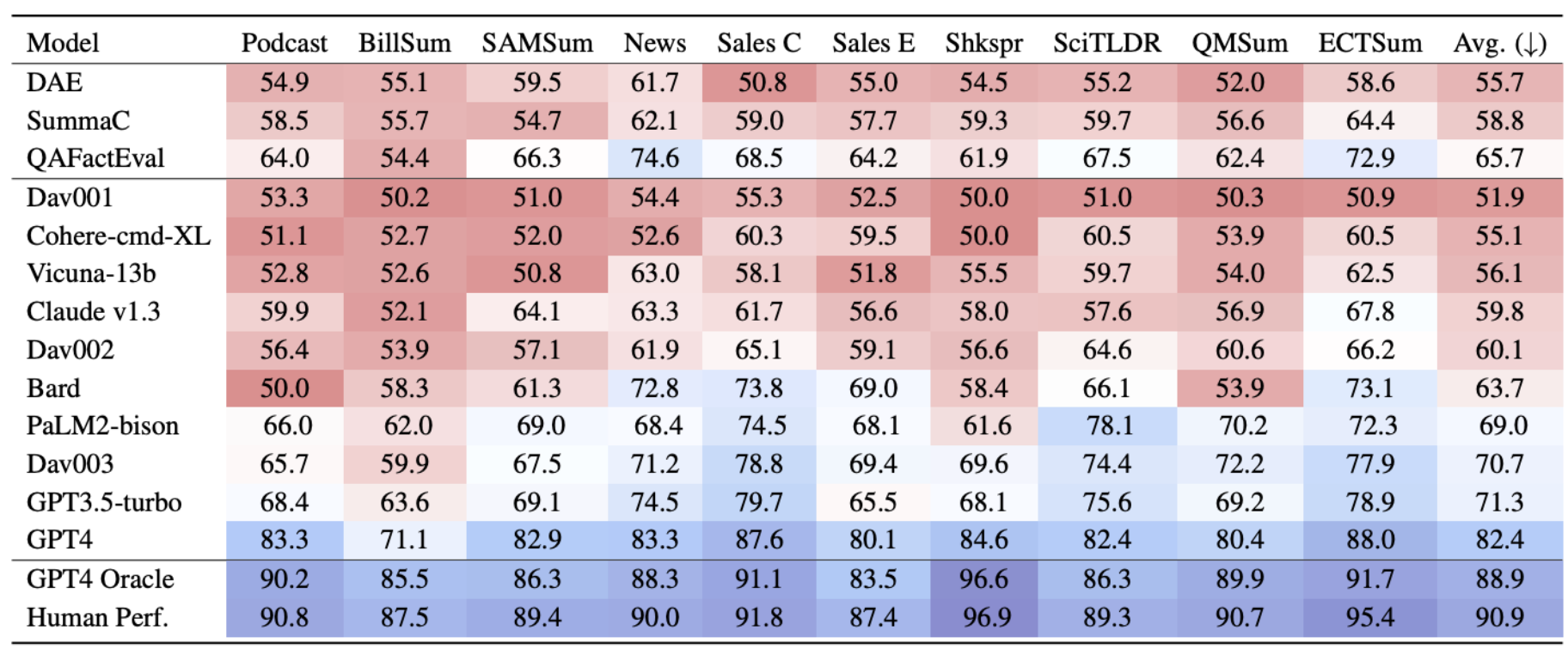
Encontramos que QAFactEval tiene un buen rendimiento, sólo superado en general por 4 LLM. Las métricas sin LLM obtienen los mejores resultados en el ámbito de las noticias, lo que tiene sentido dado que se desarrollaron y probaron principalmente con noticias. En el ámbito jurídico y en los diálogos de Shakespeare, la mayoría de los modelos obtuvieron peores resultados. Estas diferencias apuntan a la necesidad de desarrollar y probar en varios dominios.
En la parte inferior de la tabla, mostramos el rendimiento humano estimado, así como una configuración de oráculo. En la configuración de oráculo, añadimos el resumen de semillas al resumen del artículo y al resumen modificado. En este caso, el resumen inicial sirve como andamiaje de información, y la mejora del rendimiento confirma que se puede conseguir un alto rendimiento del modelo; el reto de la prueba consiste en alinear los hechos del resumen editado con el documento cuando el modelo no sabe lo que se ha editado.
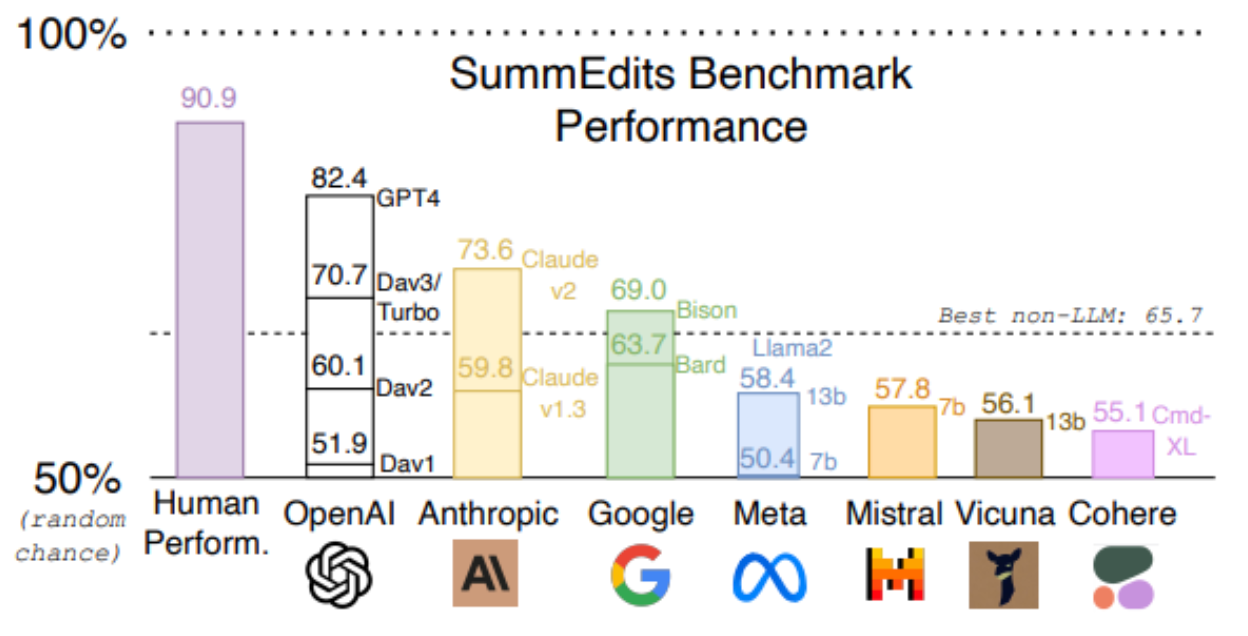
En la tabla siguiente, visualizamos el rendimiento medio de los modelos que compiten entre sí. Como puede verse, sigue habiendo una brecha entre el modelo superior y el rendimiento humano y una brecha considerable con otros modelos. Así pues, creemos que el SummEdits proporciona un punto de referencia robusto y desafiante para las comparaciones de evaluación de la consistencia factual del LLM.
Takeaways
En este trabajo, comparamos los LLM con datos anteriores, pero también los utilizamos para adoptar un enfoque crítico con respecto a las comparaciones previas y los posibles errores en su creación. Pedimos más puntos de referencia reproducibles y desafiantes como el que presentamos aquí. Las ediciones claras y atómicas y el desglose del proceso de anotación, similar al punto de referencia RoSE anterior, simplifican la recopilación de datos y permiten un mejor acuerdo entre los anotadores.
En general, dadas las mejoras de los LLM, podemos aprovecharlas para escalar los procesos de anotación. En este trabajo, encontramos que sólo GPT3.5 o 4 fueron capaces de generar ediciones suficientemente refinadas sin reescribir completamente los resúmenes. El LLM elegido podría muy bien tener un efecto sobre qué modelos se prefieren, e idealmente, podríamos aprovechar múltiples LLMs en este proceso.
Además, nos centramos en la tarea de clasificación binaria, pero estos datos podrían ser utilizados para la localización de errores o corrección de errores en futuros estudios. Además, a diferencia de otros puntos de referencia, estamos evaluando modelos como métricas y no modelos como resumidores subyacentes, pero podríamos aprovechar nuestros datos, por ejemplo, comparando la probabilidad de resúmenes coherentes entre resumidores.
Aunque hemos visto mejoras asombrosas en el rendimiento de los modelos en los últimos años, debemos ser conscientes de las desventajas restantes de estos modelos. Creemos que la mejora conjunta de estos modelos, así como la evolución de nuestros enfoques para evaluarlos, es esencial de cara al futuro. Seguiremos investigando en los ámbitos de la coherencia de los hechos y la evaluación, y abriremos el código de nuestros documentos y herramientas, como AuditNLG, para promover un NLG fiable