Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
En ocasiones, los desarrolladores y arquitectos participan en la fase de extinción de incendios de la implementación de un cliente. Esto suele ser después de que se completa la implementación y las aplicaciones se encuentran con múltiples problemas relacionados con el rendimiento. Es posible que los usuarios se quejen de ralentizaciones periódicas o que surjan excepciones de límite de gobernador en varias áreas dentro de la aplicación. Dichos problemas afectan la confianza del cliente y, cuando no se abordan como una prioridad, pueden ser indicativos de cuellos de botella potenciales de escala y rendimiento para una organización.
En esta publicación de blog, presentaremos una metodología que puede ayudarlo a analizar su aplicación de manera integral. Cubriremos un enfoque correctivo basado en temas de alto nivel que los desarrolladores pueden tomar para abordar los problemas de rendimiento y escalabilidad de su organización.
Análisis de arriba hacia abajo para una organización
El enfoque que se describe aquí es el enfoque de "análisis de arriba hacia abajo mediante la evaluación de un solo usuario" que presentamos muy brevemente en la serie Cómo escalar la prueba en Salesforce en el blog de Salesforce Architects. Proporciona una comprensión detallada del rendimiento de una aplicación de Salesforce en varias capas de la aplicación, como la capa del servidor o la capa de la base de datos. Con esta metodología, debería poder obtener primero una vista holística de toda la aplicación. En segundo lugar, debería poder dividir la aplicación en componentes clave que están causando problemas de rendimiento y escalabilidad. Luego puede escalar mejor las aplicaciones y restaurar rápidamente la confianza de los clientes.
El enfoque de análisis de arriba hacia abajo se compone de tres pasos principales.
Paso 1: creación de perfiles de aplicaciones y recopilación de datos
Lo primero que debe hacer es realizar un "perfilado" de una aplicación mediante la Evaluación de un solo usuario. La creación de perfiles significa ejecutar un escenario comercial de extremo a extremo, incluida la navegación por cada acción, la actualización de páginas donde sea necesario y la recopilación de puntos de datos relevantes.
El enfoque de creación de perfiles que se describe aquí le permite analizar una aplicación que se ejecuta en Lightning Experience (LEX) y supone que está familiarizado con herramientas como Apex Log Analyzer y Salesforce Community Page Optimizer .
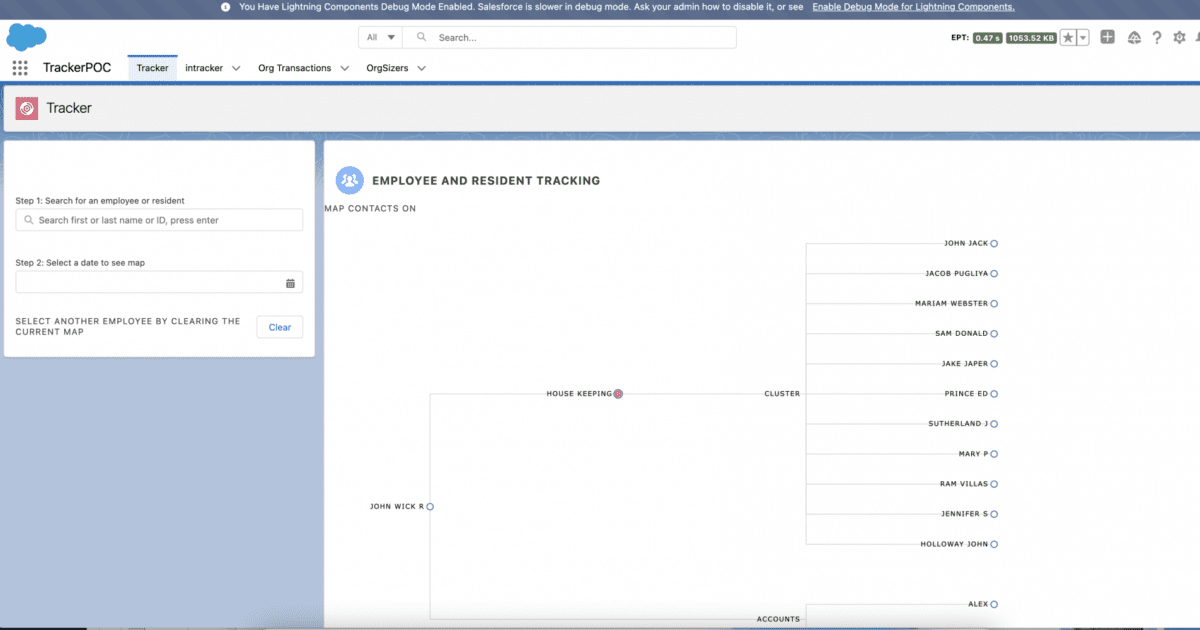
Veamos ahora cómo puede perfilar una aplicación de gestión de empleados de hotel de muestra. Esta aplicación muestra los detalles de los empleados del hotel y permite que un supervisor cree grupos de empleados y les asigne tareas cada día según la demanda. La aplicación contiene tres pestañas, donde cada pestaña contiene tres componentes Lightning Web Components (LWC). La aplicación tiene problemas de rendimiento durante la temporada alta.

Lo primero que debe hacer es habilitar el modo de depuración para el usuario que realiza la ejecución del proceso comercial. En segundo lugar, instale y habilite el complemento Optimizador de páginas comunitarias de Salesforce. Finalmente, divida el ciclo de vida de su proceso comercial en múltiples hitos; estos se pueden asociar con páginas, componentes o procesos comerciales, lo que se sienta intuitivo. Por ejemplo, en nuestra aplicación de muestra, el ciclo de vida consta de diferentes fases, como la búsqueda de un empleado, la visualización del mapa/grupo de empleados, la asignación de tareas a los empleados, etc. Cada una de estas fases puede ser un hito durante la creación de perfiles.
Empecemos a ejecutar el primer paso del hito comercial de su aplicación. En nuestra aplicación de muestra, el primer hito es buscar un empleado utilizando un LWC que muestra un cuadro de búsqueda con sugerencias de escritura anticipada y un campo para capturar la fecha para la cual se deben asignar las funciones y los grupos. Una vez que se ejecuta un hito, puede continuar con la extensión del complemento Community Optimizer para extraer registros solo para este paso. Lo primero que debe recopilar aquí son los XHR (XMLHttpRequests) que se muestran en la pestaña Información.

Utilice la plantilla de hoja de cálculo a continuación y capture los XHR totales con los detalles que se muestran en la primera página. Esto puede parecer un poco obvio, pero lo que proporciona este conjunto de datos es una vista resumida del total de XHR que se han invocado en la aplicación. En aras de la brevedad aquí, no hemos agregado todos los XHR de los registros. Recuerde, en esta etapa solo se trata de perfiles y recopilación de datos. No empieces a analizar las cosas todavía. Lo haremos una vez que se haya recopilado toda la información relevante del generador de perfiles.
| Métrico | Servidor | |||||
| Nombre | # Acciones | Duración (ms) | Red (ms) | Acciones (ms) | DB (ms) | Otro (ms) |
| aura?r=11&ui-búsqueda-componentes-forcesearch-sgdp.ScopesCache.getScopeMaps=1&auraXhr=true | obtener mapas de alcance | 659 | 529 | 108 | 21 | 22 |
| aura?r=12&ui-setup-components-aura-components-gear.Gear.getGearSetupApps=1&auraXhr=true | getGearSetupApps | 583 | 527 | 29 | 12 | 27 |
Ahora que tenemos todos los XHR de este caso de uso, debemos recopilar todas las acciones que están en XHR. Para eso, navegaremos a la pestaña Acciones del complemento Optimizer y descargaremos todas las acciones usando el botón Exportar. Hay un Incluir acciones de Salesforce caja; una vez marcada, también proporcionará una lista de todas las acciones de back-end relacionadas con Salesforce que se utilizan para proporcionar el diseño de la página, obtener registros, etc. Con el fin de crear perfiles, puede mantener la casilla de verificación sin marcar.

Puede agregar los datos exportados a otra pestaña de la hoja donde se recopilaron los XHR.
| nombre | duración | antecedentes | almacenable | abortable | servidorTiempoTotal | servidorDbTime | tiempo de devolución de llamada | poner en colaEsperar | controlador | componente |
| guardarAvailableEmployeeList | 6185 | FALSO | FALSO | FALSO | 4985 | 944 | 15 | 0 | apex://AddEmployeeController_cc | c: Agregar empleado |
| obtenerRegistros | 886 | FALSO | FALSO | FALSO | 190 | 47 | 27 | 0 | apex://SingleRelatedListController | c:Lista relacionada única |
Repita los dos pasos anteriores de recopilación de XHR y acciones para cada paso de hito de la aplicación. Nuestra aplicación tenía tres pasos importantes dentro de ella, por lo que idealmente deberíamos recopilarla en tres etapas. Una advertencia sobre el uso del complemento Optimizer es que no elimina automáticamente las acciones de los pasos anteriores. Al crear el perfil de la aplicación, debe borrar manualmente la lista de acciones después de cada hito.
La siguiente tabla enumera todas las acciones en tres hitos para la aplicación de muestra. Puede utilizar esta tabla como plantilla al perfilar sus propias aplicaciones.
| nombre | duración | antecedentes | almacenable | abortable | servidorTiempoTotal | servidorDbTime | tiempo de devolución de llamada | poner en colaEsperar | controlador | componente |
| getTemplateDescriptorWithExpansionBundle | 422 | FALSO | CIERTO | CIERTO | 119 | 34 | 0 | 0 | aura://DynamicComponentController | ninguna |
| getObjectInfo | 363 | FALSO | FALSO | FALSO | 21 | 0 | 0 | 0 | aura://RecordUiController | ninguna |
| guardarAvailableEmployeeList | 6185 | FALSO | FALSO | FALSO | 4985 | 944 | 15 | 0 | apex://AddEmployeeController_cc | c: Agregar empleado |
| getNextEmployees | 1559 | FALSO | FALSO | FALSO | 487 | 160 | 28 | 0 | apex://AddEmployeeController_cc | c: Agregar empleado |
| obtenerRegistros | 886 | FALSO | FALSO | FALSO | 190 | 47 | 27 | 0 | apex://SingleRelatedListController | c:Lista relacionada única |
| obtenerRegistros | 907 | FALSO | FALSO | FALSO | 136 | 30 | 20 | 0 | apex://SingleRelatedListController | c:Lista relacionada única |
| obtener los siguientes empleados | 849 | FALSO | FALSO | FALSO | 342 | 12 | 30 | 0 | apex://AddEmployeeController_cc | c: Agregar empleado |
| getLayoutUserState | 337 | FALSO | FALSO | FALSO | 30 | 0 | 0 | 0 | aura://RecordUiController | ninguna |
| getTemplateDescriptorWithExpansionBundle | 683 | FALSO | CIERTO | CIERTO | 234 | 33 | 0 | 0 | aura://DynamicComponentController | ninguna |
| getRecordWithFields | 490 | FALSO | FALSO | FALSO | 134 | 24 | 0 | 0 | aura://RecordUiController | ninguna |
| getRecordActions | 388 | FALSO | FALSO | FALSO | 69 | 18 | 0 | 0 | aura://Controlador de Acciones | ninguna |
| getRecordAvatars | 486 | FALSO | FALSO | FALSO | 178 | 67 | 0 | 0 | aura://RecordUiController | ninguna |
| actualizarMru | 385 | FALSO | FALSO | FALSO | 73 | 18 | 0 | 0 | aura://RecordMruController | ninguna |
Hay dos columnas importantes en esta tabla. La columna ServerTotalTime indica el tiempo total en milisegundos que tardaron los servidores de aplicaciones y los servidores de bases de datos en completar el procesamiento de la solicitud. Esto no incluye el tiempo que tardó la solicitud en pasar del cliente a los servidores de aplicaciones. La columna ServerDbTime es simplemente el tiempo que se pasa en los servidores de la base de datos para que se complete la solicitud. La lectura de los datos de estas dos columnas debería dar una claridad de primer nivel sobre dónde se gasta el tiempo para la mayoría de las solicitudes.
No existe una línea de base específica para las métricas en columnas individuales, ya que depende de la naturaleza de las acciones del lado del servidor. Por ejemplo, una acción que actualiza 50 campos en una entidad inflada (un objeto de Salesforce con un gran volumen de datos) dará como resultado un tiempo de base de datos elevado frente a una acción que consulta cinco campos con los filtros indexados adecuados.
Con esto, nuestro ejercicio de recopilación de datos ya está completo.
Paso 2: masaje de datos
Una aplicación empresarial puede ser complicada y, por lo tanto, los datos sin procesar anteriores de XHR, acciones, tiempo del servidor, etc. deben sintetizarse de manera que se segreguen en Business Case, Server Time y DBTime. Esto lo ayuda a dividir y decodificar aplicaciones grandes.
Cree la siguiente tabla recopilando los datos sin procesar recopilados en el paso anterior para comprender lo que sucede dentro de la aplicación. Puede utilizar esta tabla como plantilla para sus propias aplicaciones. Para nuestra aplicación de muestra, nos estamos enfocando en DBTime (ServerDbTime) para ayudarnos a dar sentido a toda la aplicación. En caso de que DBTime no sea un cuello de botella, cree esta tabla utilizando el ServerTotalTime de la aplicación.
| Tiempo total de base de datos (ms) | Nombre de caso de uso comercial | Tiempo de base de datos de caso de uso (ms) | Contribución general de tiempo de base de datos (%) | Etapas de aplicación | Etapas DB tiempo (ms) | Contribución DB dentro del caso de uso (%) | Contribución total del tiempo de la base de datos (%) | Fases dentro de la etapa | Fases DB Tiempo (ms) | Contribución dentro de las etapas (%) | Contribución total del tiempo de la base de datos (%) | Comportamiento | Componente |
| 5880 | Trazabilidad de empleados | 5500 | 94 | EmpleadoRetirada | 2800 | 51 | 48 | Aterrizaje | 34 | 1 | 0.6 | getNavigationMenu | forceCommunity:navegaciónMenuBase |
| ObtenerListaDeEmpleados | 1746 | 62 | 30 | getEmployeeData | c: Agregar empleado | ||||||||
| Obtener empleado relacionado | 1020 | 36 | 17 | getNextEmployees | c: Agregar empleado | ||||||||
| EmpleadoMapaPantalla | 880 | dieciséis | 15 | EmpleadoMapaDatos | 278 | 32 | 5 | obtenerRegistros | c:MapaEmpleado | ||||
| Mostrar mapa | 602 | 68 | 10 | getLayoutUserState | c:MapaEmpleado | ||||||||
| Rastreador de empleados | 2200 | 40 | 37 | Actualizar registro de empleado | 1300 | 59 | 22 | Actualizar registro de empleado | c: Rastreador de actividad | ||||
| RecuperarSiguienteEmpleado | 700 | 32 | 12 | getNextEmployees | c: Agregar empleado | ||||||||
| VisualizaciónActividadRegistro | 200 | 9 | 3 | mostrarActividad | c: Rastreador de actividad | ||||||||
| Tiempo de integración | 380 | 6 | EmpleadoIntegración |
Esto es lo que representa cada columna de la tabla:
- Tiempo total de base de datos: tiempo total de base de datos en diferentes casos de uso para los que se recopilaron datos de la aplicación
- Nombre del caso de uso comercial: representa el nombre real del caso de uso comercial; esto será útil en pasos futuros
- Usecase DB Time: el tiempo que tarda en completarse el caso de uso real
- % de contribución de tiempo general de DB : la contribución porcentual de ese caso de uso específico con respecto al tiempo total en la primera columna
- Etapas de la aplicación: el nombre de la etapa o hito de la aplicación en ese caso de uso específico
- Fases dentro de la Etapa: Podemos dividir cada hito en diferentes fases. Por ejemplo, en nuestra aplicación de muestra, el primer hito de la búsqueda de empleados se puede dividir en fases como Aterrizaje (o carga de la página), ObtenerEmployeeList (o ejecución de la búsqueda), etc.
- Acciones: representa el nombre de la acción Lightning, que provoca la contribución específica en el lado del servidor
- Luego tenemos la base de datos real y la contribución de tiempo del servidor (ms) para eso dentro de la etapa específica.
Un desarrollador o un arquitecto de aplicaciones de nivel empresarial debería poder comprender este concepto de etapa y fases en función de lo que se aplica a sus casos de uso.
Luego, estos datos deben simplificarse aún más en las siguientes tablas estructurales para eventualmente bifurcarse entre los casos de uso y las diferentes etapas de la aplicación. Esto nos ayudará a comprender los cuellos de botella.
Bifurcación de la aplicación general y la contribución de DB
| Fase de aplicación | Tiempo de base de datos (ms) |
| Acceso | 34 |
| EmpleadoRetirada | 2800 |
| EmpleadoMapaPantalla | 880 |
| Rastreador de empleados | 2200 |
Bifurcación de fases dentro de la aplicación
| Fase de aplicación | Subfase dentro de la aplicación | DB Tiempo de subfase |
| Aterrizaje | N / A | 34 |
| EmpleadoRetirada | ObtenerListaDeEmpleados | 1780 |
| Obtener empleado relacionado | 1020 | |
| EmpleadoMapaPantalla | EmpleadoMapaDatos | 242 |
| Mostrar mapa | 638 | |
| Rastreador de empleados | Actualizar registro de empleado | 1300 |
| RecuperarSiguienteEmpleado | 700 | |
| VisualizaciónActividadRegistro | 200 |
También puede visualizar estos datos a través de un gráfico circular y profundizar en cada subfase para averiguar dónde se gasta el tiempo máximo de base de datos.


Con todo el masaje de datos hecho, ahora es el momento de analizar este conjunto de datos.
Paso 3: Análisis de datos
Ahora es el momento de dar sentido a los datos de la representación visualizada arriba. Se puede hacer la siguiente interpretación para la aplicación de muestra:
- El paso comercial de recuperación de empleados de toda la aplicación requiere el 48 % de DBTime
- Dentro de este paso, la subfase GetEmployeeList contribuye con el 64 % del tiempo total
- El Rastreador de Empleados es el segundo paso comercial más alto, tomando el 37% del DBTime total
Por lo tanto, un desarrollador o arquitecto debe centrarse de inmediato en la subfase GetEmployeeList de toda la aplicación para que sea más escalable. En esta subfase, ya se identificó la acción Lightning específica que aporta la mayor parte del tiempo del servidor como parte de la recopilación de datos.
Ahora, la siguiente pregunta es: dentro de esta acción, ¿qué clase y método es el verdadero culpable? Aquí es donde Apex Log Analyzer vendrá a su rescate. También puede instrumentar el código Apex con el registro utilizando el marco de registro de Nebula y luego determinar las consultas problemáticas y los DML, etc. Para los fines de este blog, utilizaremos Apex Log Analyzer. Active el filtro Debug Logs with Finest Mode, vuelva a ejecutar solo el caso de uso específico que desencadena la acción y descargue el registro para visualizarlo con Apex Log Analyzer. Pasa el cursor sobre la pestaña Base de datos y busca la sección en la que se pasa la mayor parte del tiempo.

Por ejemplo, si hay una consulta que requiere mucho tiempo de la base de datos (que se puede identificar en la columna Tiempo total), busque opciones para ajustar la consulta.

Si la acción que lleva tiempo incluye acciones estándar como UpdateRecord o SaveRecord , las operaciones en segundo plano relacionadas, como desencadenadores y flujos, son las que contribuyen al aumento del tiempo de la base de datos. Ahora que conocemos las acciones, los SOQL exactos y los puntos de entrada del código que contribuyen al tiempo de base de datos elevado, es hora de remediar estos problemas.
Acciones de remediación a realizar sobre los datos analizados
Según el análisis, puede haber varias vías que un desarrollador debería tomar. Los clasificaremos en los siguientes tres enfoques de alto nivel basados en temas que puede tomar para resolver problemas. Puede haber optimizaciones que queden fuera de este tema, pero están más allá del alcance de esta publicación de blog.
Tema 1: Reparación de aplicaciones de lectura intensiva
Si la optimización cae en este tema, donde la mayor parte del tiempo se dedica a SOQL con mucho tiempo de base de datos, se pueden tomar los siguientes enfoques:
- Evalúe todos los SOQL en la ruta de LECTURA que pueden vivir con datos eventualmente consistentes y aproveche Platform Cache para esos SOQL para reducir el costo de lectura. Hay varios ejemplos mencionados en este blog que cubren cómo y qué escenarios pueden ser útiles para implementar Platform Cache.
- En sus consultas SOQL, elimine los campos no garantizados o hágalos más restrictivos. Filtre explícitamente los valores NULL en la cláusula WHERE para permitir un mayor rendimiento de las consultas. Del mismo modo, reduzca la duración del filtro Fecha y hora cuando corresponda.
- El Optimizador de consultas de Lightning Platform indexa automáticamente los campos que considera adecuados para la indexación periódica. Sin embargo, puede haber situaciones en las que la creación de un índice personalizado sea la opción adecuada para reducir el tiempo de la base de datos. Comuníquese con los equipos de soporte con los puntos de datos apropiados para crear un índice personalizado.
Tema 2: Corrección de aplicaciones con uso intensivo de escritura
Si se trata de una aplicación de escritura intensiva y las acciones estándar como UpdateRecord o SaveRecord están contribuyendo a aumentar el tiempo, aquí hay algunos enfoques que puede tomar:
- Aproveche la memoria caché de la plataforma para reducir las llamadas a la base de datos para lecturas posteriores dentro de los activadores
- Evite las recurrencias que surgen de los DML de objetos cruzados y las actualizaciones de campos del mismo registro dentro de los disparadores. Consulte la guía de automatización activada por registro para obtener más información.
- Identifique y planifique una estrategia de archivo para objetos con grandes volúmenes de datos (entidades infladas). Las entidades infladas pueden generar un rendimiento deficiente, informes más lentos o bloqueo de registros, etc.
- Use un buen marco de activación que sea escalable, rastreable, reutilizable, atómico y optimizado. Consulte las recetas de Apex para ver un marco de activación en acción.
Tema 3: Reparación relacionada con las acciones de LWC
Este tema de optimización puede surgir cuando está claro que la recuperación de datos dentro de los componentes de LWC en las páginas Lightning están impulsando tiempos de servidor altos. Existen algunos antipatrones comunes para la escalabilidad de las aplicaciones LEX, que incluyen el uso incorrecto de la recuperación de datos, almacenamiento insuficiente de datos en caché, inicialización de componentes mal implementada y uso incorrecto de force:refreshView o window.location.reload , entre otros.
La publicación de blog Prácticas recomendadas de rendimiento de componentes web Lightning cubre varias técnicas de optimización de rendimiento en detalle. Sin embargo, aquí hay un resumen rápido:
- Optimice las llamadas a adaptadores estándar como
getRecordogetRecordUi. Por ejemplo, al usar el adaptador de cablegetRecord(ver documentos ), solicite solo los campos que requiere el componente y evite solicitar un registro por diseño a menos que necesite absolutamente todos esos datos. - Evite recargar páginas usando
window.location.reloaddurante los flujos de trabajo normales, ya que provoca llamadas de recuperación de datos innecesarias debido al arranque de la aplicación. - Asegúrese de aprovechar los mecanismos integrados de LWC para el almacenamiento en caché del lado del cliente o cree su propia solución de almacenamiento en caché personalizada.
- Evalúe las opciones para usar la creación de instancias diferidas o la representación condicional en sus componentes para reducir la cantidad de solicitudes de lectura durante la carga de la página o las operaciones posteriores.
- Si las llamadas de
reportFailedActiondominan serverTime, significaría queel tiempo de página experimentado (EPT) para los usuarios es bajo. Si bien arreglar las llamadas dereportFailedActionno reducirá la carga general de la base de datos, debería mejorar la experiencia del cliente. También reducirá la cantidad de solicitudes pendientes, y hay límites en la cantidad de solicitudes que cada navegador puede tener pendientes a la vez.
Para obtener instrucciones detalladas sobre cómo crear y diseñar páginas Lightning que escalan y funcionan, consulte estos recursos:
Conclusión
La metodología descrita aquí brinda orientación sobre los datos específicos que se deben recopilar para la creación de perfiles, así como también cómo manipular esos datos para obtener información sobre la aplicación. Puede proporcionar una vista holística de cualquier aplicación creada en Salesforce. Esto se puede aprovechar como punto de partida para desmitificar las aplicaciones creadas en Salesforce e identificar los puntos conflictivos dentro de ellas, lo que le permite tomar las medidas correctivas adecuadas según el tema que mejor se aplique a su tipo de aplicación.
Sobre el Autor

Anand Vardhan es Propietario de Producto en el equipo de Ingeniería Asistente de Rendimiento en Salesforce. Trabaja en el diseño y desarrollo de características de productos requeridas para aplicaciones escalables de implementaciones de clientes muy grandes y complejas para satisfacer las necesidades comerciales. Anand se especializa en ingeniería de rendimiento y escala, optimizaciones del lado del servidor, Lightning, diseño de API, arquitectura de datos, grandes volúmenes de datos y almacenamiento en caché. Se puede contactar a Anand en LinkedIn .

…
Esta es una traducción realizada por EGA Futura, y este es el link a la publicación original: https://developer.salesforce.com/blogs/2022/05/analyze-performance-scale-hotspots-in-complex-salesforce-apps.html