Independientemente de si está configurando un modelo de datos o probando nuevos flujos activados por Data Cloud, los entornos aislados ofrecen una potente plataforma para la innovación sin comprometer la estabilidad de sus sistemas de producción.
Los entornos aislados ofrecen una potente plataforma para la innovación sin comprometer la estabilidad de sus sistemas de producción
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Reúna todos los datos de sus clientes en Data Cloud | Blog de desarrolladores de Salesforce
Data Cloud es más que un lago de datos. Es una plataforma de datos activa. Los desarrolladores pueden traer datos desde cualquier sistema, canal o flujo de datos, ya sea en flujos continuos o en lotes. Con Data Cloud, puede conectar sus datos a través de diferentes sistemas que contienen los datos de sus clientes. Data Cloud se basa en nuestra plataforma Hyperforce , lo que significa que Data Cloud puede absorber fácilmente grandes volúmenes de datos. Con Hyperforce, Data Cloud es rápido y también puede capturar eventos segundos después de que ocurran.
Si piensa en cuántos clics hace cada cliente, el volumen de datos se expande rápidamente. Por ejemplo, a medida que los clientes abren y hacen clic en los correos electrónicos, navegan por las páginas de sus aplicaciones móviles y miran los productos en su sitio web, puede capturar esos datos de participación a medida que ocurren. Cuando envía un correo electrónico u oferta y es relevante para la persona que lo recibe, es mucho más probable que haga clic. Cuando un cliente hace clic, puede capturar la interacción en Data Cloud. A continuación, puede utilizar esa información para averiguar qué les interesa y si es probable que realicen una compra o no.
La nube de datos está integrada
Tener todos estos datos en tiempo real de múltiples fuentes empresariales es excelente. Pero los datos no son significativos a menos que pueda usarlos. Data Cloud se conecta de forma nativa a muchos proveedores de nube, como Google Cloud Storage , Azure Storage y Amazon S3 . Data Cloud también se conecta de forma nativa a Salesforce . Después de solo unos pocos clics, puede conectar cualquier organización de Sandbox o de producción de Salesforce a Data Cloud. Luego, Data Cloud puede ingerir cualquier objeto de Salesforce en un flujo de datos .
Después de que sus datos se ingieran en objetos de lago de datos (DLO) y se asignen a objetos de modelo de datos (DMO), un modelo de datos como el siguiente se integra dinámicamente en Data Cloud. Esto le permite ver visualmente todos los flujos de datos que están creando la vista única de su cliente.
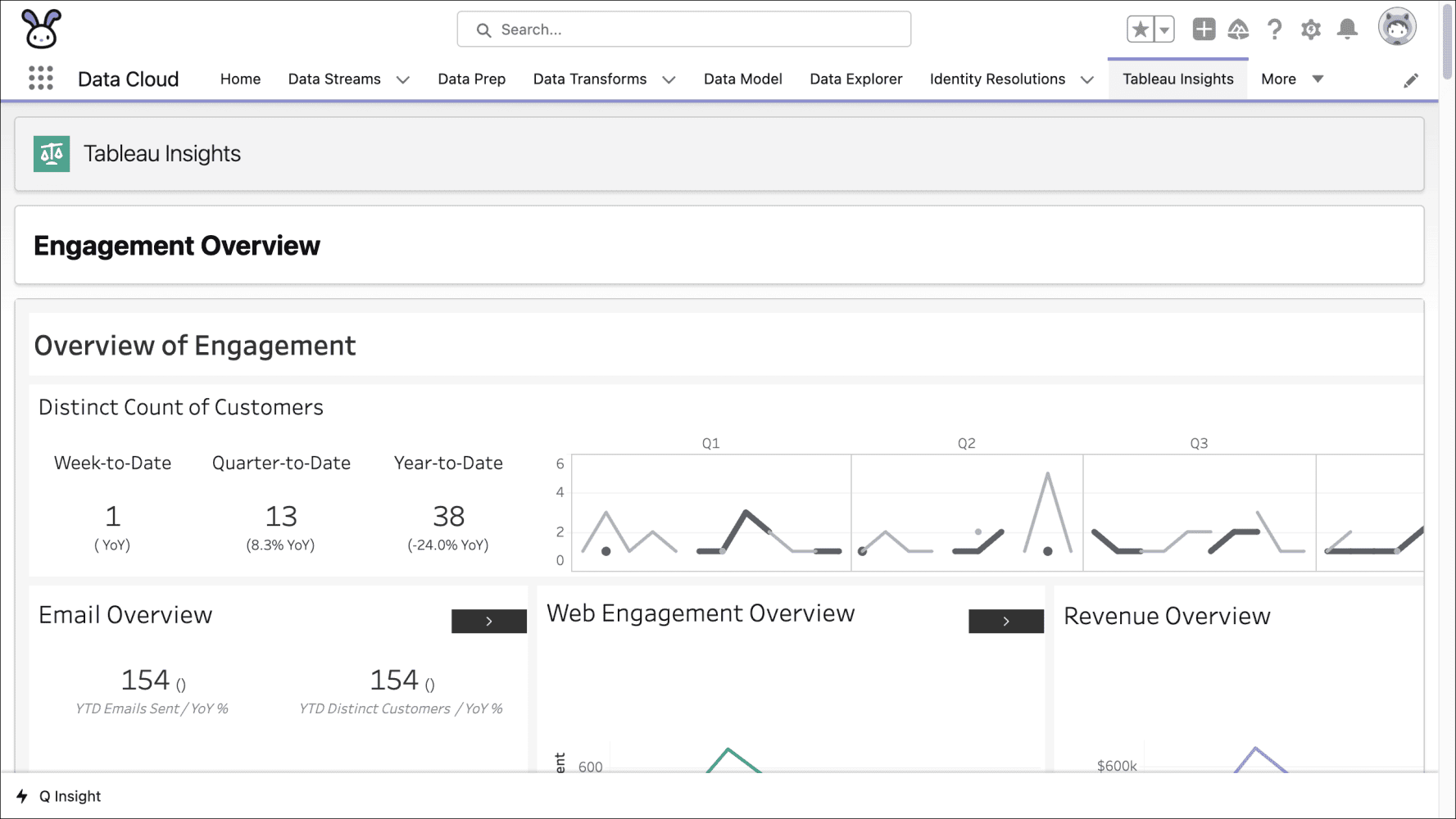
Atrás quedaron los días en que Data Cloud era solo una plataforma de datos para marketing. Los datos almacenados en Data Cloud ahora se pueden usar en muchos sistemas. Los datos de Data Cloud se pueden usar en Amazon Ads y Google Ads mediante activaciones y objetivos de activación . También puede usar el conector de nube de datos nativo en Tableau para obtener nuevos conocimientos. Los aceleradores de Tableau listos para usar le permiten moverse aún más rápido usando tableros y libros de trabajo prediseñados y listos para usar. Con Data Cloud más Tableau, puede cubrir fácilmente nuevos conocimientos sobre su negocio al reunir todos sus datos. Los desarrolladores ahora pueden incorporar estos conocimientos impulsados por IA en una aplicación de su elección.
La nube de datos está automatizada
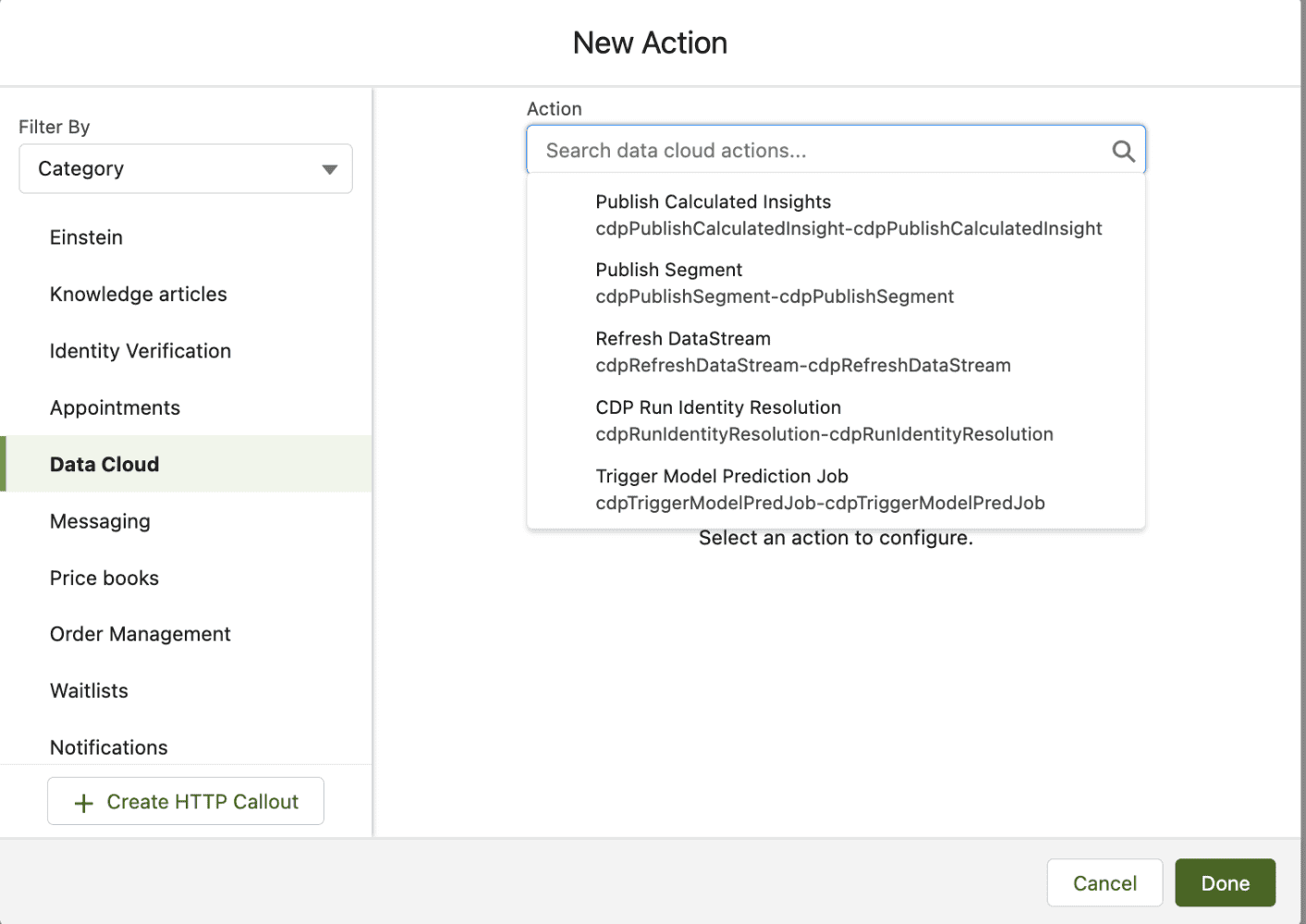
Los datos de Data Cloud también se pueden enviar a Salesforce mediante acciones de datos y eventos de la plataforma y luego aprovecharse en flujos mediante una variedad de acciones de datos que están disponibles en Salesforce Flow. Los desarrolladores pueden usar Flow para publicar información y segmentos calculados, actualizar flujos de datos, ejecutar resoluciones de identidad e incluso activar modelos de predicción. El flujo también puede obtener datos de un objeto de modelo de datos y almacenar esa información en una variable de colección para usarla en otras partes del flujo.
La nube de datos está abierta
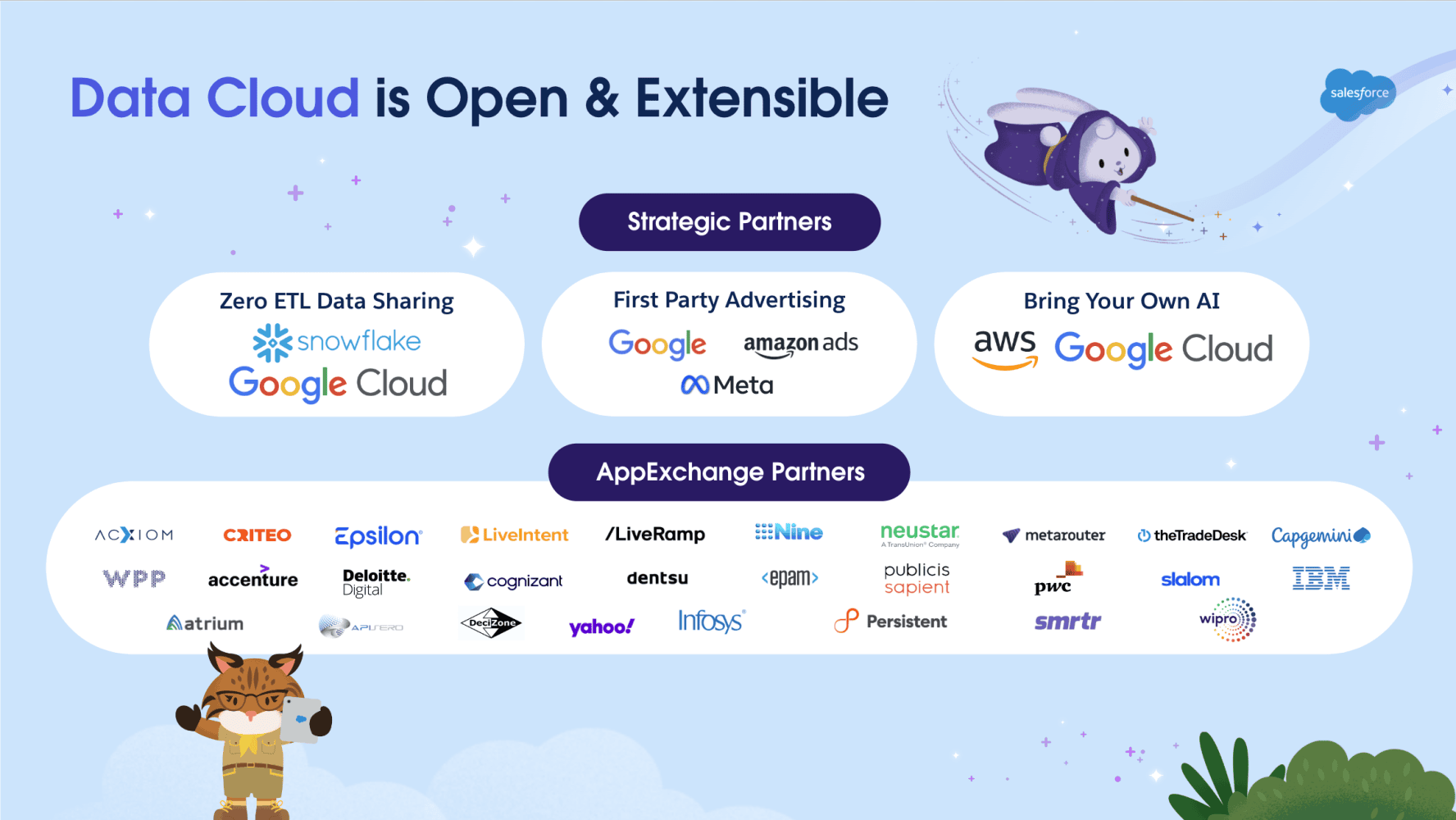
Data Cloud tiene muchas asociaciones estratégicas con empresas como Amazon, Google, Snowflake y Meta. Estas asociaciones han ampliado la plataforma para permitir mayores posibilidades y ayudar a que sus datos sean más procesables. La mejor noticia es que nuestras asociaciones están creciendo constantemente, ¡y pronto habrá nuevas!
Recursos
Sobre los autores
Muralidhar Krishnaprasad (también conocido como MK o Murali para abreviar) es el vicepresidente ejecutivo de ingeniería que ejecuta datos, ML y análisis dentro de la organización de Marketing Cloud. Se unió a Salesforce hace tres años y está a cargo de crear, integrar y hacer crecer varios productos relacionados con datos, ML y análisis. Está liderando la iniciativa para repensar nuestra estrategia general de próxima generación que reúne lo mejor de big data, ML y análisis junto con nuestra plataforma para construir la base para el futuro digital.
Danielle Larregui es promotora sénior de desarrolladores en Salesforce, donde se enfoca en la creación de contenido de Data Cloud y Marketing Cloud. Le encanta la UI/UX, el marketing digital y la codificación. Danielle también disfruta asistir a grupos de usuarios, conferencias comunitarias y eventos técnicos de Salesforce. Puede seguirla en Twitter@dnlarreguioLinkedInpara mantenerse al día con su contenido técnico.
Dianne Siebold es redactora técnica principal del equipo de Experiencia de contenido en Salesforce. Se especializa en desarrollo, inteligencia artificial y tecnologías de integración.
Obtenga las últimas publicaciones de blog de desarrolladores de Salesforce y episodios de podcast a través de Slack o RSS.
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Libere el poder de Apex en Salesforce Data Cloud — Parte 1 | Blog de desarrolladores de Salesforce
Trailblazer.me estará fuera de línea por mantenimiento programado a partir del 21 de julio de 2023 a las 6 p. m. (hora del Pacífico) hasta el 22 de julio de 2023 mientras transformamos Trailblazer.me en la nueva cuenta de Trailblazer. Durante este tiempo de inactividad, no podrá iniciar sesión en ninguna aplicación relacionada, incluidas Ayuda y capacitación, AppExchange, Trailhead y Trailblazer Community, y más.
Salesforce Data Cloud permite a los desarrolladores aprovechar el poder de los grandes datos para las empresas. Al utilizar Data Cloud, los clientes pueden consolidar los datos de clientes de múltiples sistemas en una única instancia de Salesforce, creando una vista unificada de los datos en toda la empresa. Estos datos se pueden utilizar para análisis, aprendizaje automático y acciones automatizadas. En este primer blog de nuestra serie de dos partes, exploraremos diferentes utilidades de Apex para consultar datos en Data Cloud y brindaremos orientación sobre cómo utilizarlas de manera efectiva.
Apex ofrece una variedad de utilidades para Data Cloud. Por ejemplo, permite que los desarrolladores construyan con Lightning Web Components para personalizar las experiencias de usuario estándar de Data Cloud, o que los ISV construyan su propio código para automatizar operaciones específicas de Data Cloud, como la resolución de identidades, la creación y ejecución de conocimientos calculados de Data Cloud o la segmentación.
Objetos de Salesforce Data Cloud frente a objetos estándar/personalizados
Antes de analizar cómo consultar datos de Data Cloud, comprendamos un poco acerca de los objetos de Salesforce Data Cloud y cómo difieren con respecto a los objetos estándar/personalizados de Salesforce Platform.
Salesforce Data Cloud tiene un modelo de datos canónico que incluye objetos de lago de datos (DLO) y objetos de modelo de datos (DMO). Puede leer acerca de cómo estos objetos se asignan entre sí y sus propósitos en la documentación de ayuda.
Los objetos de Data Cloud pueden ingerir y almacenar volúmenes de datos mucho más grandes (en la magnitud de miles de millones de registros) en comparación con los objetos estándar y personalizados regulares en la Plataforma de Salesforce. Los objetos estándar/personalizados están diseñados para casos de uso transaccional y no son adecuados para almacenar y procesar big data. Por otro lado, los objetos de Data Cloud agregan capacidades similares a las de un lago de datos .
Otra distinción clave es que los objetos de Data Cloud no admiten disparadores Synchronous Apex. Sin embargo, aún puede lograr la automatización de procesos suscribiéndose a Change Data Capture (CDC) y utilizando Flows o Apex. Lo que es común entre los objetos de la nube de datos y los objetos de la plataforma es que están construidos sobre la misma base impulsada por metadatos, lo que hace posible el uso de características de la plataforma, como Salesforce Flow, Apex y Platform Events.
Cómo consultar datos de Data Cloud en Apex
Antes de profundizar en algún código, exploremos un ejemplo de caso de uso de una aplicación de nube de datos.
Ejemplo de caso de uso y supuestos
Para nuestros ejemplos de código en esta publicación de blog, supongamos que estamos trabajando para una empresa ficticia llamada Solar Circles que captura datos de todos sus paneles solares instalados en Data Cloud. Cada mes, se generan decenas de millones de puntos de datos a partir de estos paneles. Al tener estos datos en Data Cloud, Solar Circles obtiene la capacidad de realizar análisis, utilizar técnicas de aprendizaje automático y obtener información procesable de los datos.
El código de Apex en esta publicación asume una condición importante: la nube de datos está habilitada y el código de Apex se ejecuta en la organización de la nube de datos y no en las organizaciones de Salesforce que están conectadas a la organización de la nube de datos.
Consultar datos de Data Cloud usando SQL
Para acceder a datos de objetos de Data Cloud (DLO o DMO), utilice la clase CdpQuery (ver documentos ) en Apex. Esta clase está disponible en el espacio de nombres ConnectApi (ver documentos ).
A continuación se muestra un fragmento de código de ejemplo que muestra cómo acceder a los datos de un objeto de nube de datos mediante una instrucción SQL.
<dx-code-block title language="apex" code-block="@AuraEnabled(cacheable=true)
public static void getSolarPanelData(String customerId) { List<Map> returnData = new List<Map>(); // Create input for query operation ConnectApi.CdpQueryInput queryInput = new ConnectApi.CdpQueryInput(); queryInput.sql = ‘SELECT * ‘ + ‘FROM Solar_Panel_Events_solar_panel_F4C03__dlm ‘ + ‘WHERE CustomerId__c = » + customerId + » ‘ + ‘ORDER BY date_time__c DESC LIMIT 50’; // Execute SQL ConnectApi.CdpQueryOutputV2 response = ConnectApi.CdpQuery.queryAnsiSqlV2( queryInput ); Map responseMetadata = new Map(); responseMetadata = response.metadata; // Parse response System.debug( ‘Number of rows in the result data set ‘ + response.rowCount ); System.debug(‘Next batch ID ‘ + response.nextBatchId); System.debug(‘Query Metadata’ + responseMetadata); for (ConnectApi.CdpQueryV2Row resultRow : response.data) { for (Object result : resultRow.rowData) { system.debug(result); } } «>
En el ejemplo anterior, estamos recuperando datos para un componente LWC personalizado en una página Lightning de caso de objeto estándar para un agente de servicio. El componente muestra datos de dispositivos recientes provenientes de los paneles instalados en el sitio del cliente.
Aspectos destacados del código
El método toma un parámetro customerId , lo que indica que recupera los datos del panel solar para un cliente específico
Se crea una instancia de ConnectApi.CdpQueryInput llamada queryInput para definir la operación de consulta.
La propiedad queryInput.sql se establece con una consulta SQL que selecciona todos los campos del objeto de datos Solar_Panel_Events_solar_panel_F4C03__dlm , filtrado por CustomerId__c
La consulta se ejecuta mediante ConnectApi.CdpQuery.queryAnsiSqlV2(queryInput) , que devuelve un objeto ConnectApi.CdpQueryOutputV2 denominado response
El response.metadata se asigna a responseMetadata , que almacena los metadatos de la respuesta de la consulta.
Consideraciones importantes
Apex tiene un límite de CPU de 10 segundos para transacciones sincrónicas. Data Cloud puede contener miles de millones de filas de datos. Al recuperar datos en Apex desde Data Cloud, asegúrese de agregar suficientes filtros y proporcionar contexto (como el recordId con el que está trabajando) para limitar la cantidad de filas y evitar alcanzar el límite de CPU de 10 segundos.
Si está recuperando una gran cantidad de datos, use Queueable Apex para ejecutar el proceso de forma asincrónica y aproveche el límite de CPU de 60 segundos.
Recomendamos usar queryAnsiSqlV2 (consulte los documentos ) en lugar de queryAnsiSql para aprovechar las solicitudes posteriores y los tamaños de respuesta más grandes para casos de uso en los que necesita extraer grandes volúmenes de datos.
Use nextBatchAnsiSqlV2(nextBatchId) (ver documentos ) para proporcionar batchId de la respuesta anterior para recuperar el siguiente conjunto de resultados.
También puede usar SOQL en lugar de SQL, pero asegúrese de obtener su SOQL usando el Explorador de datos , ya que hay funciones de SOQL que pueden no ser aplicables a los objetos de Data Cloud.
Cómo buscar información de perfil
Antes de analizar cómo buscar información de perfil de Data Cloud en Apex, debemos comprender qué es un perfil unificado.
Perfil unificado y resolución de identidad
Supongamos que Solar Circles, nuestro fabricante ficticio de paneles solares, tiene datos sobre un cliente llamado Martha en varios sistemas. Cada sistema tiene información diferente sobre ella, como diferentes direcciones de correo electrónico. Estos datos únicos se denominan puntos de contacto . Los clientes como Martha están representados por múltiples registros de contacto y perfiles específicos del sistema en varios sistemas. Esto es necesario para que cada nube y producto funcione de forma independiente, pero puede crear silos de datos.
A continuación se muestra un código Apex de utilidad de ejemplo que busca información de perfil. Tenga en cuenta que se utiliza el método queryProfileApi de la clase ConnectApi.CdpQuery .
<dx-code-block title language="apex" code-block=" @AuraEnabled public static List
Aquí hay un fragmento de código de ejemplo que invoca el código de utilidad anterior al pasar los parámetros.
<dx-code-block title language="apex" code-block=" List
El código busca la información de perfil del cliente Martha en el objeto de modelo de datos UnifiedIndividual__dlm .
Aspectos destacados del código
El método utiliza ConnectApi.CdpQuery.queryProfileApi() para ejecutar la consulta de datos de perfil en la nube de datos
Los parámetros de consulta incluyen los nombres del objeto del modelo de datos ( dataModelName ), el objeto del modelo de datos secundario ( childDataModelName ), el campo de clave de búsqueda ( searchKey ) y el nombre del cliente ( customerName )
Se pueden proporcionar parámetros opcionales adicionales, como expresiones de igualdad, nombres de campos de objetos secundarios, la cantidad de elementos para devolver, la cantidad de filas para omitir y el orden de clasificación para el conjunto de resultados.
La respuesta de la consulta se almacena en un objeto ConnectApi.CdpQueryOutput llamado response
El método devuelve response.data , que representa los datos recuperados de la consulta
Importante consideración
Vuelva a verificar los nombres de campo y objeto antes de usarlos en el código de Apex, ya que, de lo contrario, el método puede generar excepciones y errores internos del servidor.
¿Cómo consultar datos de conocimientos calculados?
Los conocimientos calculados le permiten definir y calcular métricas multidimensionales en todo su estado digital en Data Cloud. Data Cloud genera información calculada al escribir SQL , de manera declarativa usando Insights Builder o usando Apex.
Streaming vs insights calculados
Hay dos tipos de información en Data Cloud: transmisión e información calculada.
Los conocimientos calculados son funciones que pueden calcular métricas en datos históricos. Se procesan en lotes. Por ejemplo, en nuestra aplicación Solar Circles, podemos tener una visión calculada que mide la potencia total generada por los paneles agrupados por cada cliente.
La información de transmisión se genera casi en tiempo real mediante el análisis del flujo continuo de datos entrantes. Estos conocimientos permiten la activación inmediata de acciones en los sistemas posteriores. Por ejemplo, la información de transmisión se puede utilizar para identificar a los clientes cuyos paneles solares generan una potencia mínima. Al aprovechar una acción de datos en la transmisión de conocimientos, podemos crear de manera proactiva un caso para dichos clientes en Salesforce Service Cloud.
Consultar datos a partir de una perspectiva calculada
Para consultar datos de las perspectivas calculadas, use el método queryCalculatedInsights de la clase CdpQuery . A continuación se muestra un fragmento de código de ejemplo que muestra cómo consultar datos de una perspectiva calculada conocida.
Aspectos destacados del código
El método queryCalculatedInsights de ConnectApi.CdpQuery se usa para recuperar información calculada de Data Cloud.
El primer parámetro es el nombre de API de la información calculada, que debe terminar con __cio . Por ejemplo, <calculted insight api name> podría reemplazarse por totalpowergenerated__cio .
Los siguientes parámetros especifican dimensiones y medidas. Una dimensión representa un campo o atributo en el que se basa la información, mientras que una medida representa la métrica calculada. Proporcionar null para estos parámetros incluye todas las dimensiones y medidas disponibles.
Se puede especificar el orden de clasificación para el conjunto de resultados, pero en este fragmento de código, se establece en null .
Los parámetros opcionales adicionales incluyen filtrar el conjunto de resultados a un ámbito o tipo más específico y especificar la cantidad de elementos que se devolverán y la cantidad de filas que se omitirán antes de devolver los resultados.
Los datos resultantes se almacenan en un objeto ConnectApi.CdpQueryOutput denominado response .
Importante consideración
Asegúrese de proporcionar el nombre de API correcto para la información. Un nombre de API incorrecto da como resultado un error del sistema.
Conclusión
En esta publicación de blog, brindamos una descripción general de cómo puede aprovechar el poder de Salesforce Data Cloud y Apex para aprovechar los grandes datos para las empresas. Los ejemplos de código y los puntos destacados demuestran enfoques prácticos para acceder y consultar datos de objetos de Data Cloud.
La publicación también destaca las mejores prácticas y las limitaciones que se deben tener en cuenta al trabajar con Data Cloud y Apex, como administrar los límites de la CPU, utilizar el procesamiento asincrónico para grandes conjuntos de datos y garantizar la denominación correcta de la API para los conocimientos calculados.
En la siguiente parte de la serie, profundizaremos en las clases de Apex como CdpCalculatedInsight (consulte los documentos ), CdpIdentityResolution (consulte los documentos ) y CdpSegment (consulte los documentos ) que se pueden usar para administrar información calculada, crear reglas de resolución de identidad y segmentación en Data Cloud mediante Apex.
Referencias adicionales
Sobre el Autor
Mohith Shrivastava es promotor de desarrollo en Salesforce con una década de experiencia en la creación de productos a escala empresarial en la plataforma de Salesforce. Actualmente se está enfocando en las herramientas para desarrolladores de Salesforce, Flow, Apex y Lightning Web Components en Salesforce. Mohith se encuentra actualmente entre los principales contribuyentes en Salesforce Stack Exchange, un foro de desarrolladores donde los desarrolladores de Salesforce pueden hacer preguntas y compartir conocimientos. Puedes seguirlo a través de su Twitter @msrivastav13 .
Obtenga las últimas publicaciones de blog de desarrolladores de Salesforce y episodios de podcast a través de Slack o RSS.
Genie Customer Data Cloud utiliza datos para crear una vista única del cliente. Puede usar Insights para segmentar, agregar y filtrar para comprender mejor a su cliente.