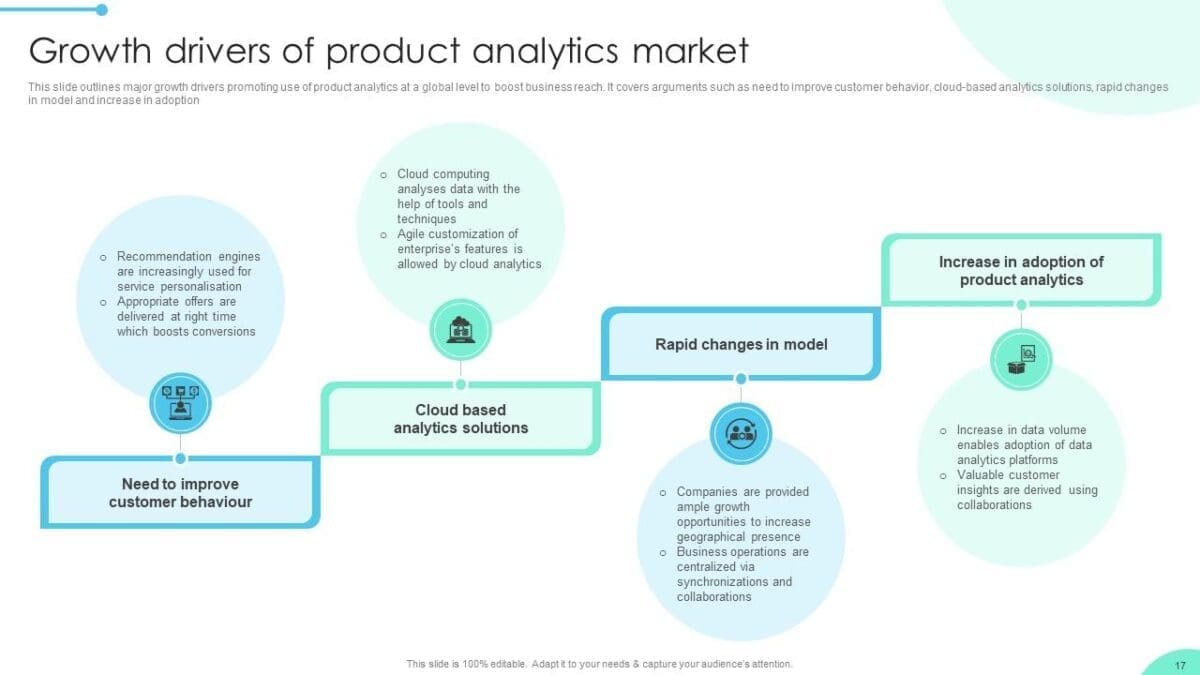
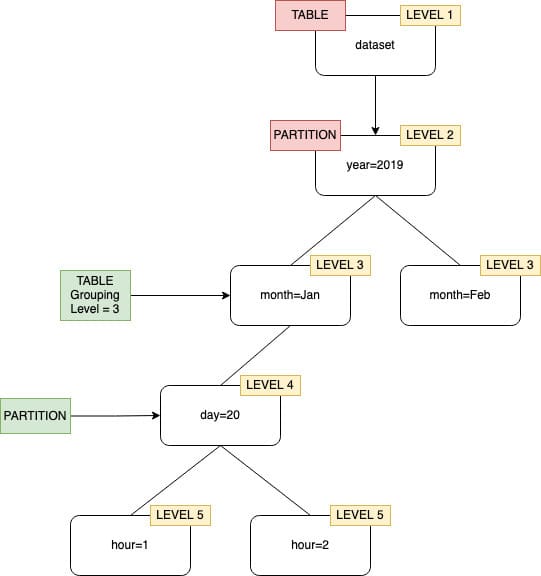
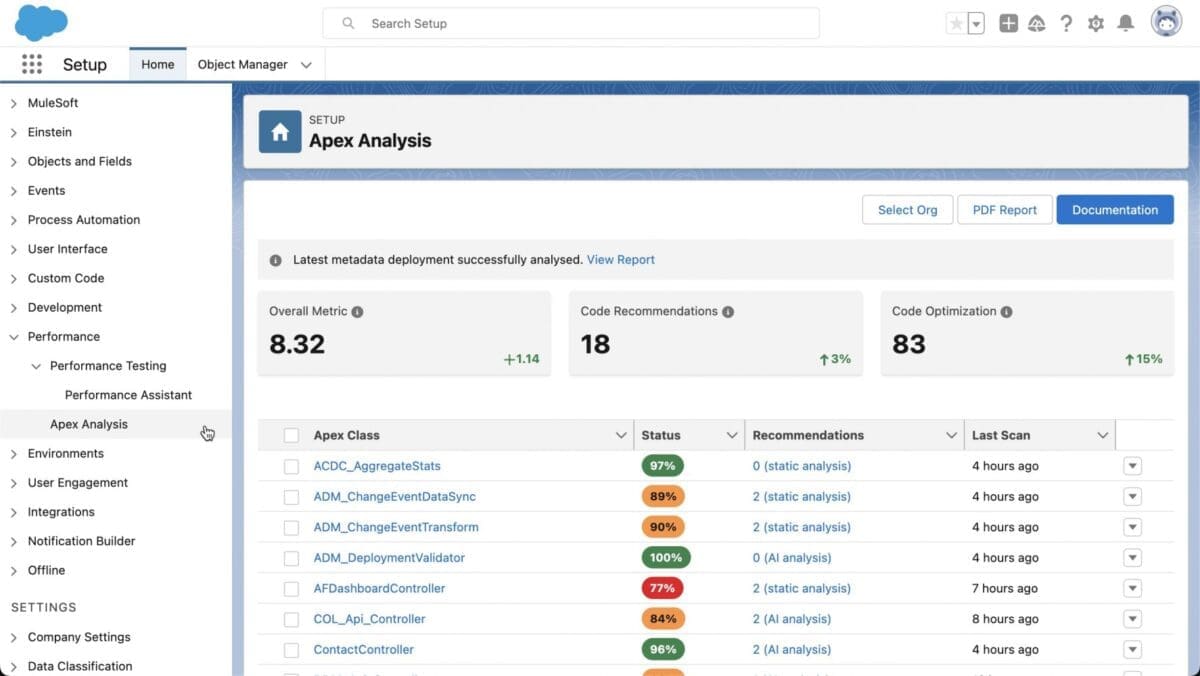
¡Ya está aquí la versión Winter ’25! En este post, destacamos las novedades para los desarrolladores de todo el ecosistema de Salesforce.
En este post, destacamos las novedades para los desarrolladores de todo el ecosistema de Salesforce
The post Guía del desarrollador de Salesforce para la versión de invierno ’25 appeared first on Blog de desarrolladores de Salesforce.
La versión de invierno ’25 ya está aquí