La integración de una API externa con su organización de Salesforce puede ser una tarea sencilla que no requiere código si utilizaCredenciales con nombre y Servicios externos . Deberá crear una credencial con nombre que apunte a la API y configurar un servicio externo en la interfaz de usuario de configuración. La clave aquí es proporcionar una especificación OpenAPI para la API. Si la API no tiene una, puede diseñarla usted mismo manualmente usando YAML o JSON, usar MuleSoft Anypoint Platform o aprovechar las herramientas y el código de código abierto.
En esta publicación, le presentaremos la especificación OpenAPI y Swagger, discutiremos los elementos principales de la especificación y lo guiaremos a través del diseño e implementación de una API con código. Usaremos Node.js y Swagger dentro del marco Fastify para esta tarea. Finalmente, integraremos esta API con Salesforce.
OpenAPI y Swagger
OpenAPI es una especificación para diseñar y construir API. Proporciona una forma estandarizada de definir su API para otros, brindando una forma estructurada que incluye puntos finales, tipos de solicitud/respuesta, definiciones de esquema, métodos de autenticación y más. Las especificaciones de OpenAPI están escritas en formatos YAML o JSON, ambos fáciles de leer y escribir. Esta especificación es ampliamente adoptada y respaldada por una variedad de herramientas, lo que la convierte en una opción popular para diseñar y documentar API. De hecho, si desea importar una API a Salesforce utilizando servicios externos, deberá especificarse con OpenAPI. Además, Salesforce es miembro de la Iniciativa OpenAPI .
Nota: A la fecha de esta publicación, la versión actual de la especificación OpenAPI es 3.1.0.
Swagger , por otro lado, es un conjunto de herramientas ( la mayoría de código abierto ) para implementar la especificación OpenAPI. Incluye la interfaz de usuario de Swagger, que proporciona una interfaz gráfica para comprender y probar las API, y Swagger Codegen, que genera código SDK de cliente y apéndices de servidor a partir de una especificación OpenAPI.
La especificación OpenAPI v2 también se conoce como Swagger, pero su nombre cambió cuando se convirtió en parte de la iniciativa OpenAPI en 2016.
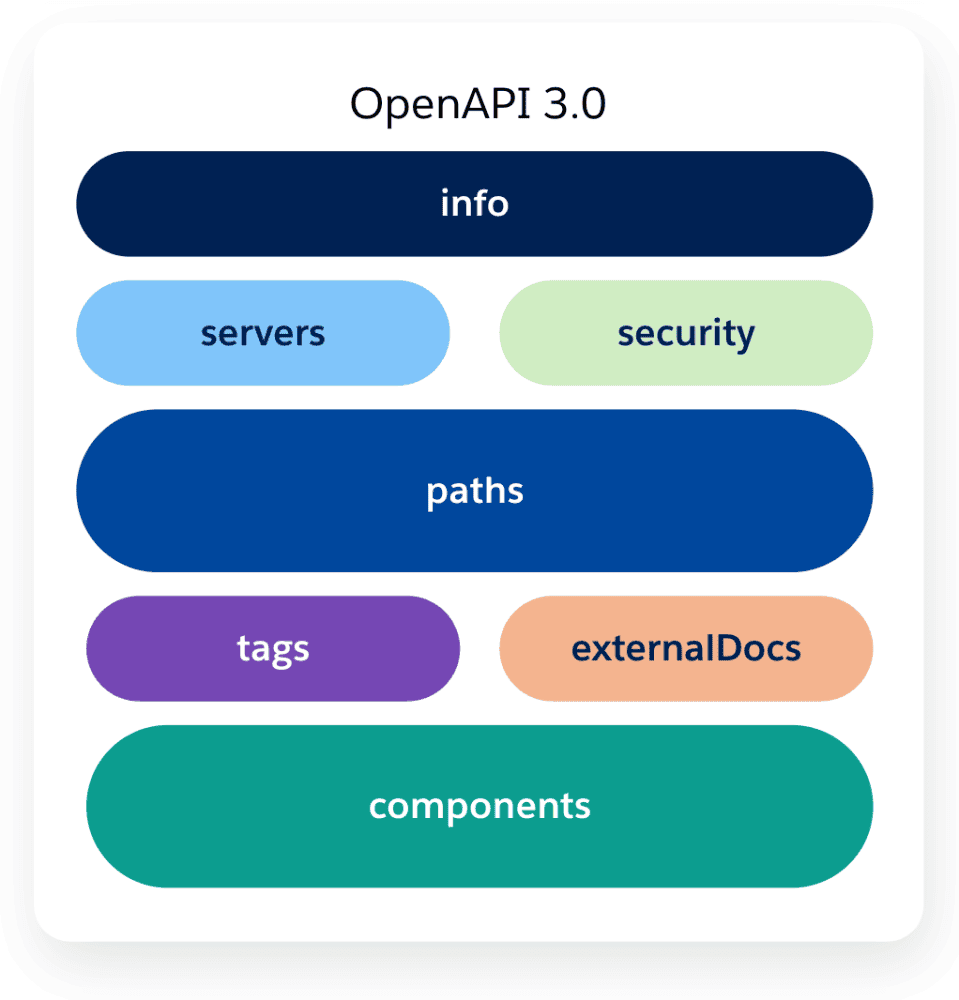
Estructura básica de la especificación OpenAPI
La especificación OpenAPI está organizada en las siguientes secciones clave:
| API abierta |
Define el documento raíz y combina la lista de recursos y la declaración de la API. Requerido |
| Información |
Proporciona metadatos sobre la API, como el título, la descripción, los términos del servicio, la información de contacto, etc. Obligatorio |
| Servidores |
Especifica una o más URL base para su API, como producción o preparación. |
| Seguridad |
Define un esquema de seguridad que pueden utilizar las operaciones de la API. |
| Caminos |
Describe las rutas y operaciones disponibles para la API. Cada ruta tiene un método HTTP con los detalles de la operación. |
| Etiquetas |
Agrega metadatos a una sola etiqueta que utiliza el objeto de operación. |
| Documentos externos |
Proporciona una descripción y una URL para la documentación externa. |
| Componentes |
Define un conjunto de objetos reutilizables para diferentes aspectos de la API. Esto puede incluir esquemas, respuestas, parámetros, ejemplos, cuerpos de solicitud, encabezados, esquemas de seguridad, etc. |
Para obtener una explicación más detallada de cada sección y sus correspondientes definiciones de objeto, consulte la documentación oficial de la especificación OpenAPI .

Para fines de demostración, crearemos una API para administrar una librería. Esta API contará con dos métodos HTTP: uno para enumerar los libros disponibles y otro para agregar nuevos libros. A continuación, encontrará una definición básica de esta API, centrándose en el método para listar libros ( GET /books ) y sus objetos de respuesta.
Tenga en cuenta que estamos usando tres secciones principales aquí: Información , Rutas y Componentes . Como se mencionó anteriormente, describiremos esta API a medida que la implementemos mediante código. Para este propósito, utilizaremos Fastify y Fastify Swagger.
Fastify y Fastify Swagger
Fastify es un marco web altamente eficiente y flexible para Node.js. Está diseñado para facilitar su uso y ofrecer la máxima velocidad sin comprometer la personalización. Fastify proporciona una base sólida para las aplicaciones web y las API, con funciones como la validación de solicitudes y respuestas basadas en esquemas, ganchos, complementos y registro automático. Una de sus principales ventajas radica en su ecosistema, que incluye numerosos complementos centrales y mantenidos por la comunidad.
Uno de estos complementos es fastify-swagger . Este complemento nos permite ofrecer definiciones de Swagger (OpenAPI v2) u OpenAPI v3, que se generan automáticamente a partir de sus esquemas de ruta o de una definición existente de Swagger/OpenAPI. Además, utilizará fastify-swagger-ui , un complemento que sirve una instancia de Swagger UI dentro de su aplicación.
Nota: La siguiente demostración requiere la instalación de Node.js LTS y, a la fecha de esta publicación de blog, la última versión es v18.16.0.
Comencemos a crear la API de su librería instalando Fastify CLI y generando un nuevo proyecto ejecutando:
Luego, vayamos a la carpeta del proyecto e instalemos las dependencias fastify-swagger y fastify-swagger-ui .
Nota: En esta demostración, se centrará en tres aspectos principales: agregar compatibilidad con Swagger a Fastify, definir rutas de API y delinear esquemas y tipos de respuesta. No explicaremos cómo integrar la API con una base de datos. Si está interesado en explorar la fuente completa del proyecto, está disponible en el repositorio de ejemplos de codeLive.
Agreguemos compatibilidad con Swagger a Fastify editando el archivo app.js , luego importemos Swagger y SwaggerUI y registrémoslos como complementos.
aplicación.js
En la configuración del complemento de Swagger, tiene la opción de pasar toda la definición de especificación de OpenAPI, o puede aprovechar el enfoque dinámico que ofrece el complemento. Para esta demostración, utilizará el enfoque dinámico. Dado que el único campo obligatorio es info , definirá los metadatos de su API allí, además, la sección refResolver se encarga de nombrar las referencias de definición de esquema.
Y para SwaggerUI, solo especifica la ruta donde se alojará el sitio de documentación.
Ahora vamos a crear una carpeta schemas . Aquí es donde definirá los esquemas de su API. Para esta demostración, definirá un esquema book y un esquema error .
esquemas/index.js
Los esquemas representan la estructura de los objetos con los que trabajará, tanto para los cuerpos de solicitud como para los de respuesta. Para la especificación OpenAPI, el complemento Swagger agregará automáticamente estos objetos en el campo components .
Finalmente, definamos las rutas API para GET /books y POST /books usando Fastify. Primero, deberá registrar los esquemas dentro de Fastify. Luego, especificará los objetos de respuesta y solicitud para cada ruta que haga referencia a esos esquemas.
rutas/root.js
{ // … look at the code repository for a complete implementation } ) // POST /books fastify.post( ‘/books’, { schema: { description: "Create a book", body: { $ref: ‘book#’, required: [‘author’, ‘title’] }, response: { 201: { description: ‘Returns the book that has been created’, $ref: ‘book#’ }, 500: { description: ‘Returns an error’, $ref: ‘error#’ } } } }, async (request, reply) => { const { title, author } = request.body const id = randomUUID() const client = await fastify.pg.connect() try { const { rows: books } = await client.query( ‘INSERT INTO books(id, title, author) VALUES($1, $2, $3) RETURNING *’, [id, title, author] ) const [newBook] = books reply.code(201).send(newBook) } catch (error) { reply .status(500) .send({ code: 500, message: `An error ocurred: ${error.message}` }) } finally { client.release() } } ) // GET / fastify.get(‘/’, { schema: { hide: true } }, async function (request, reply) { reply.status(301).redirect(‘/api-docs’) })
} «>
Analicemos la ruta POST /books :
- La función
fastify.post define el método HTTP.
- El primer argumento especifica la ruta:
/books.
- El segundo argumento especifica el
schema , que incluye el body : el objeto de carga útil que espera la API. (Tenga en cuenta que es una referencia al esquema del book ). También incluye varios objetos response para esa ruta, que se asignan a los códigos de estado HTTP correspondientes 201 y 500 .
- El tercer argumento es la implementación de la ruta. En este caso, está insertando el objeto en la base de datos y devolviendo el nuevo objeto. Si este proceso falla, devolverá un objeto de error. Es importante tener en cuenta que está utilizando los mismos esquemas que definió anteriormente.
Nota: También tiene la opción de excluir ciertas rutas de la documentación pasando hide: true en el objeto de esquema de esa ruta específica, como se demuestra en GET / route.
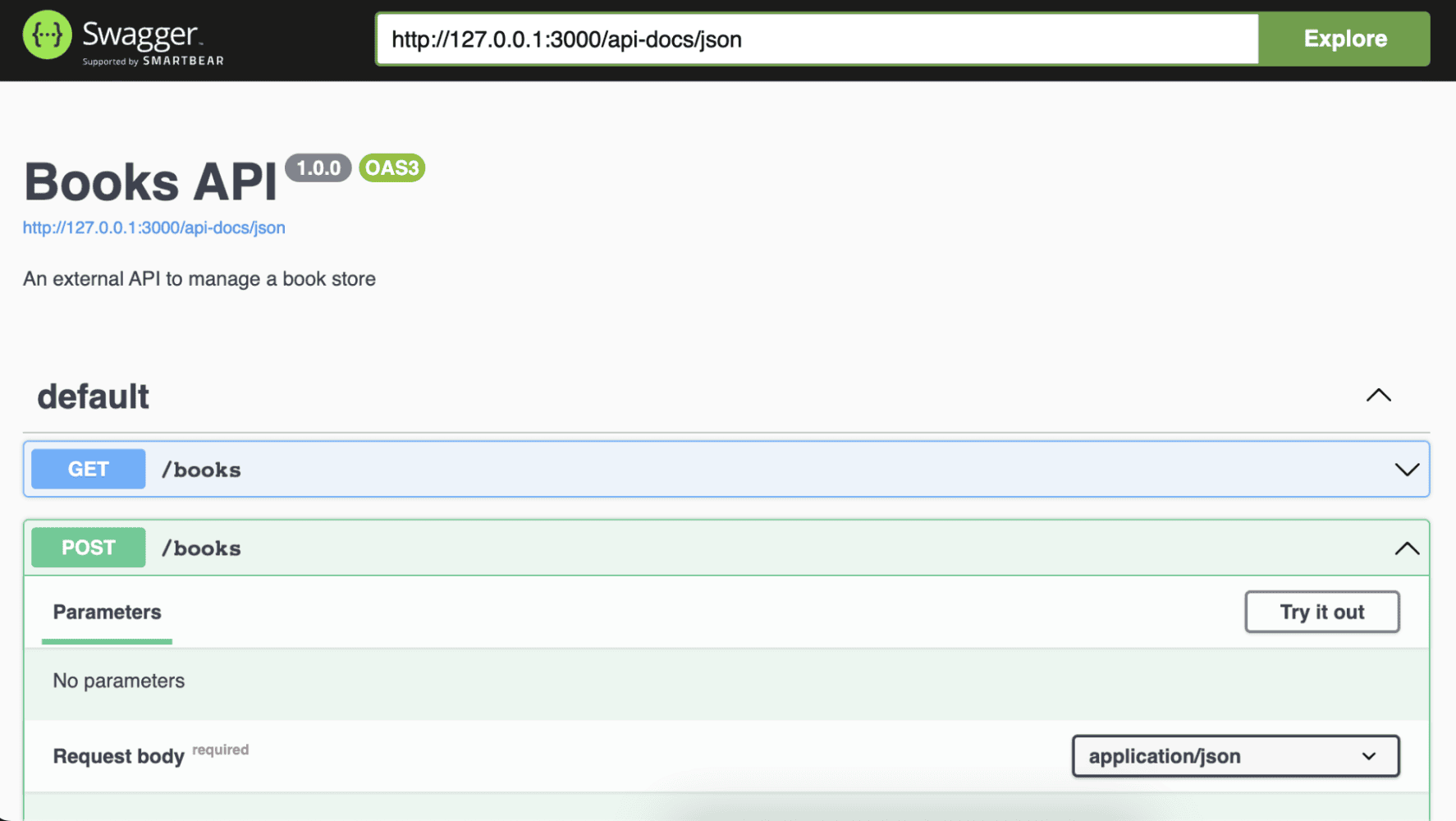
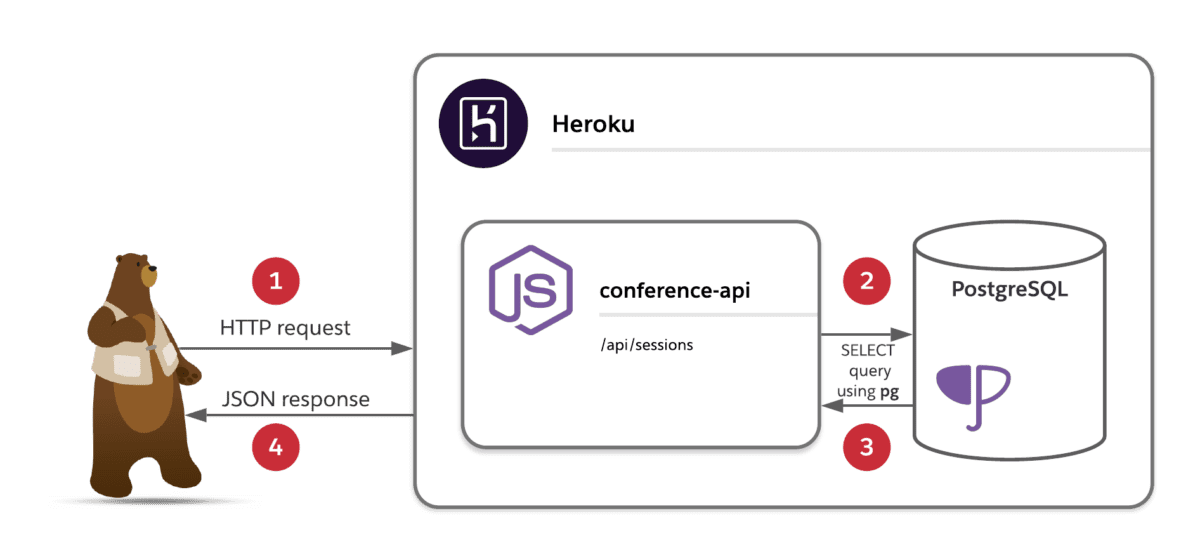
Su API está lista, así que ejecútela localmente para echar un vistazo a la interfaz de SwaggerUI ejecutando:
Y navegue a http://localhost:3000/api-docs para ver las diferentes rutas, su documentación y tener una forma de probarlas directamente desde la interfaz.
Si desea probarlo e implementarlo en Heroku, asegúrese de actualizar el script start en el archivo package.json con lo siguiente.
Además, asegúrese de tener acceso a una base de datos Heroku PostgreSQL y cree el esquema de la base de datos ejecutando:
<dx-code-block title language code-block="heroku pg:psql
Nota: El archivo database.sql está disponible en el repositorio de ejemplos de codeLive.
Luego puede implementarlo ejecutando:
Si desea ver cómo se ve implementado, vea mi versión que se ejecuta en Heroku .
Integración de una API externa con Salesforce
Ahora que tiene una API de acceso público, integrémosla con Salesforce como un servicio externo.
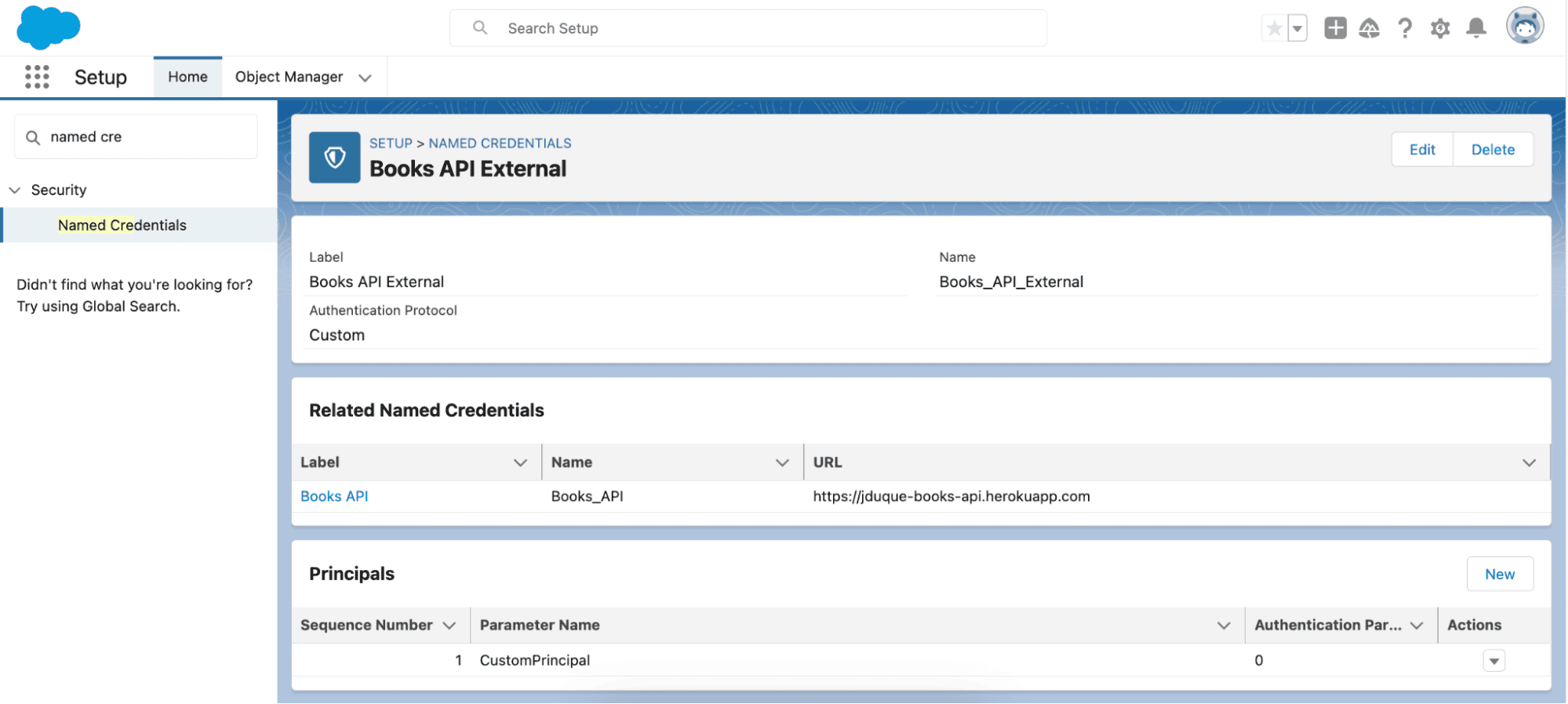
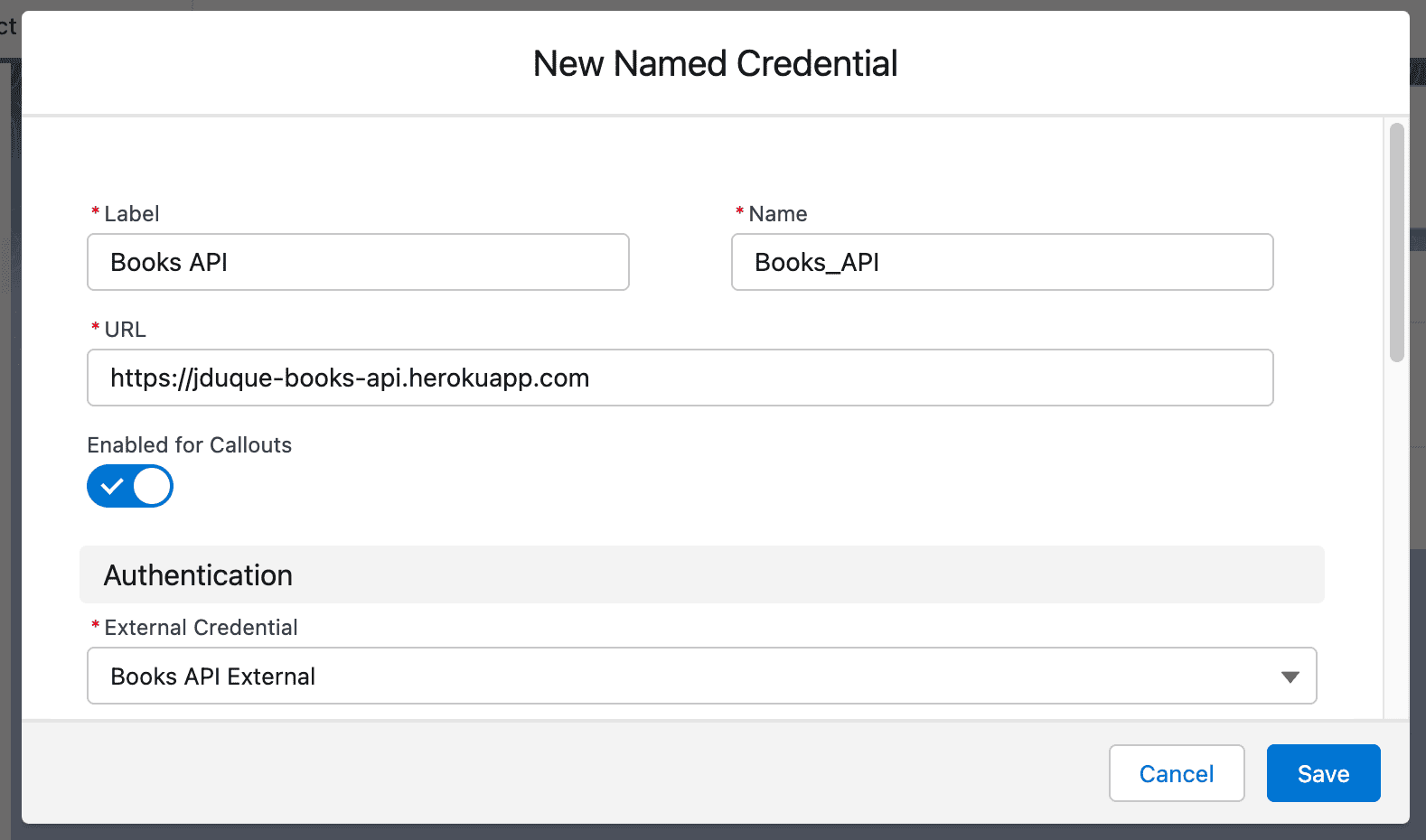
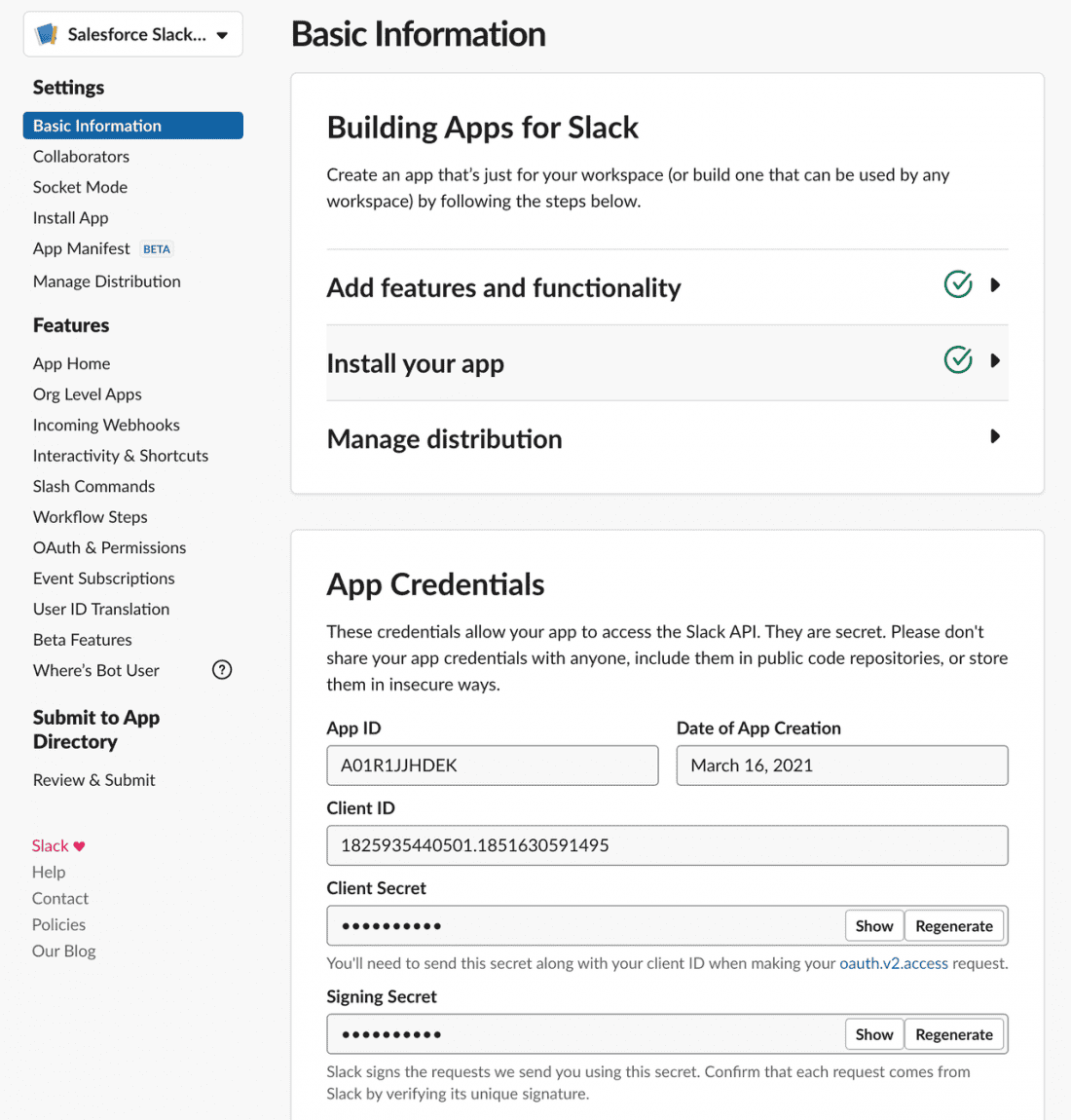
Primero, deberá crear una credencial con nombre para esta API. En la interfaz de usuario de configuración, vaya a Seguridad > Credenciales con nombre y cree una credencial externa con un protocolo de autenticación personalizado y una entidad de seguridad.
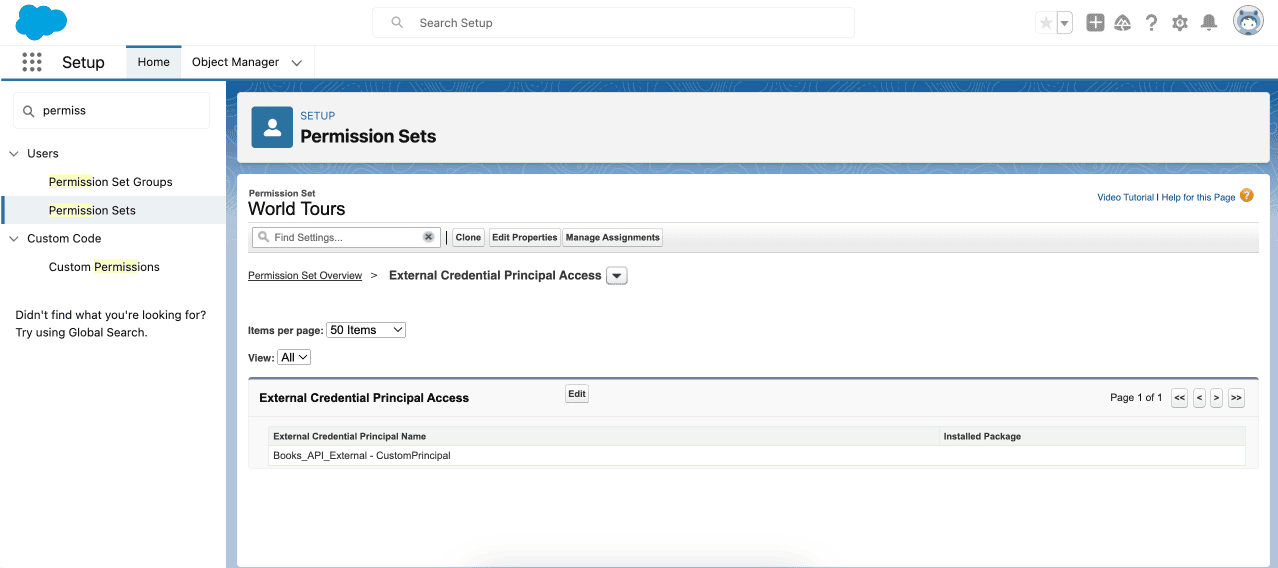
Asegúrese de que la credencial externa tenga una entidad principal a la que le haya asignado permisos en Acceso principal de credenciales externas en su conjunto de permisos.
Luego, cree una credencial con nombre que haga referencia a la credencial externa con la URL que apunta a la API pública.
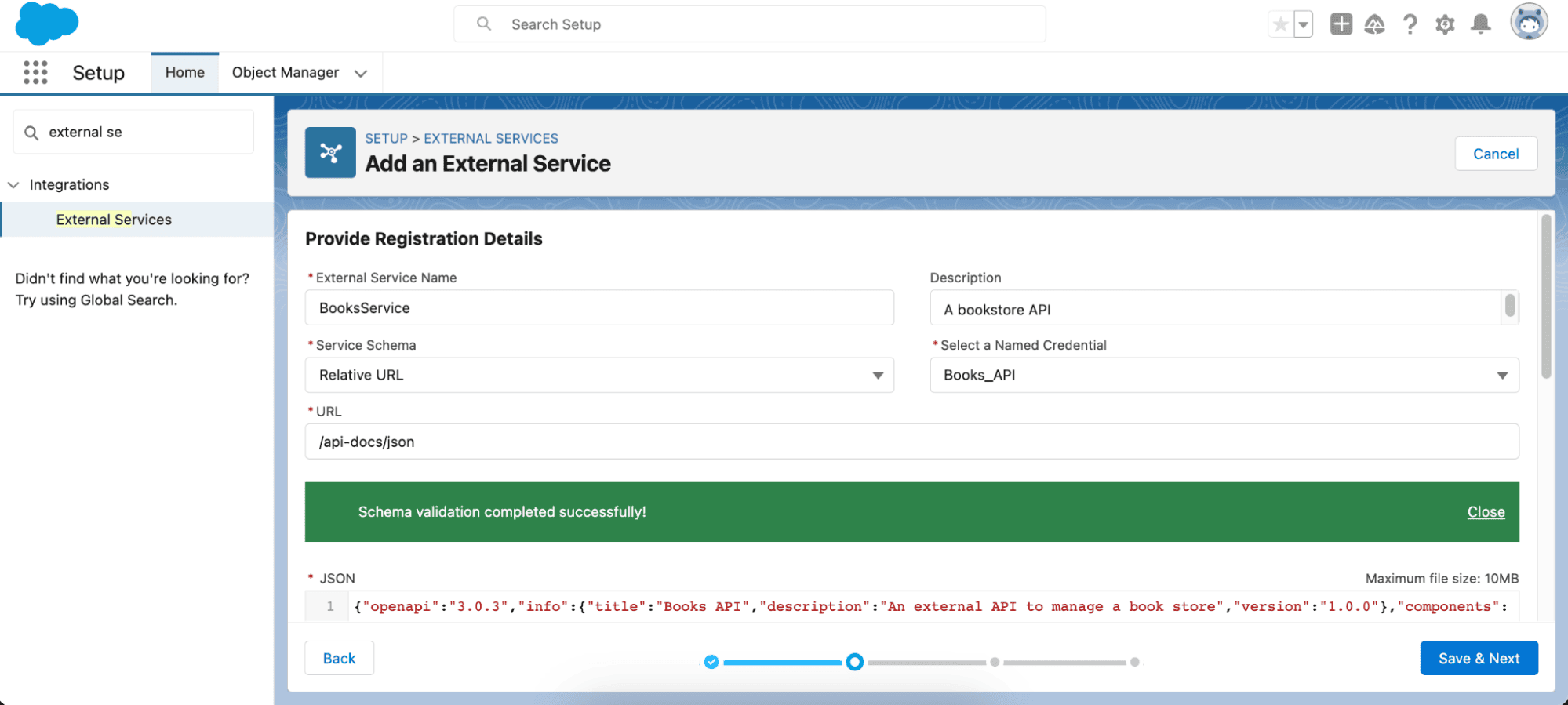
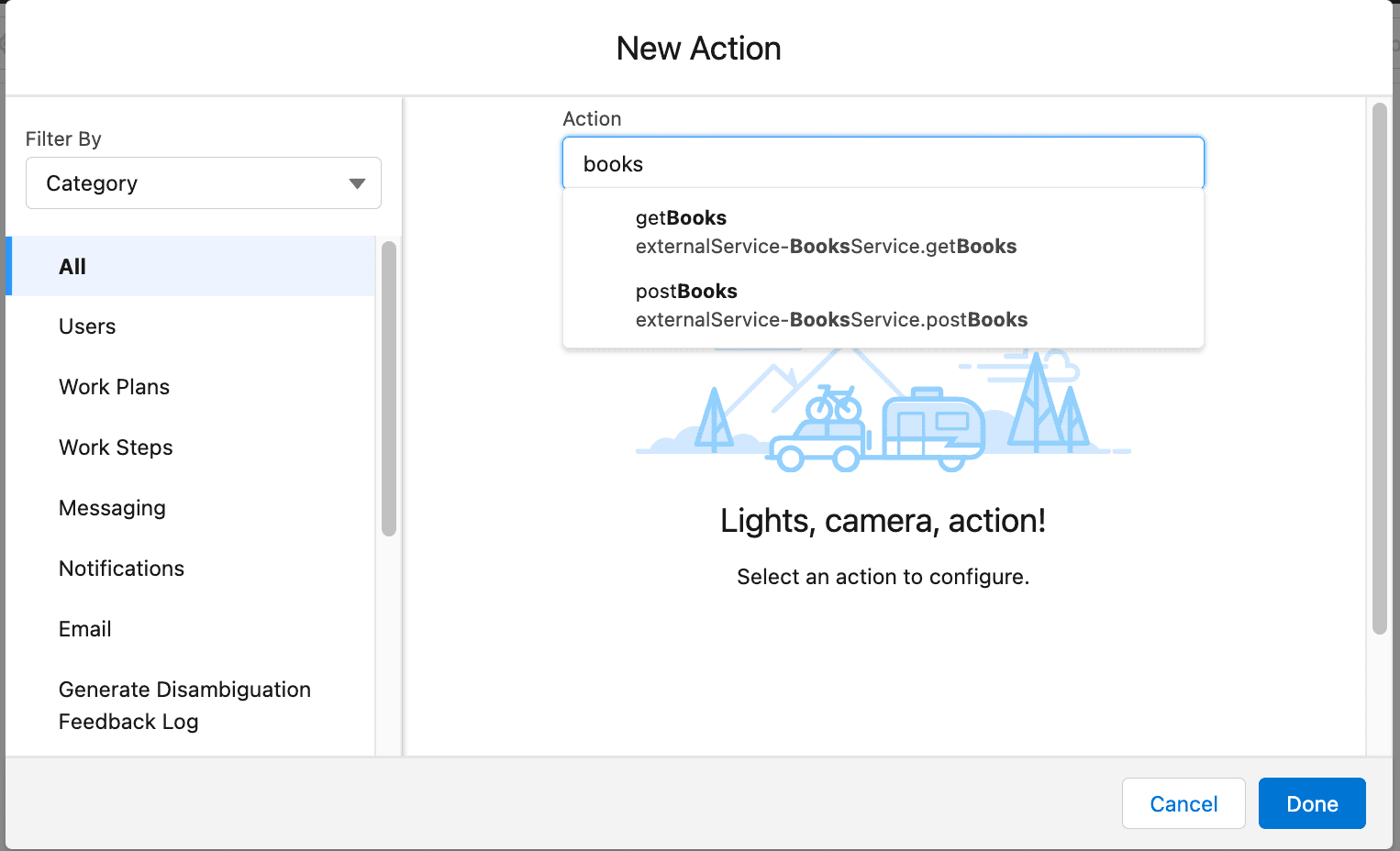
A continuación, vaya a Integraciones > Servicios externos y agregue un nuevo servicio externo desde una especificación de API, seleccione la credencial con nombre y configure la ruta relativa a la ruta de especificación de OpenAPI. En su demostración, será /api-docs/json .
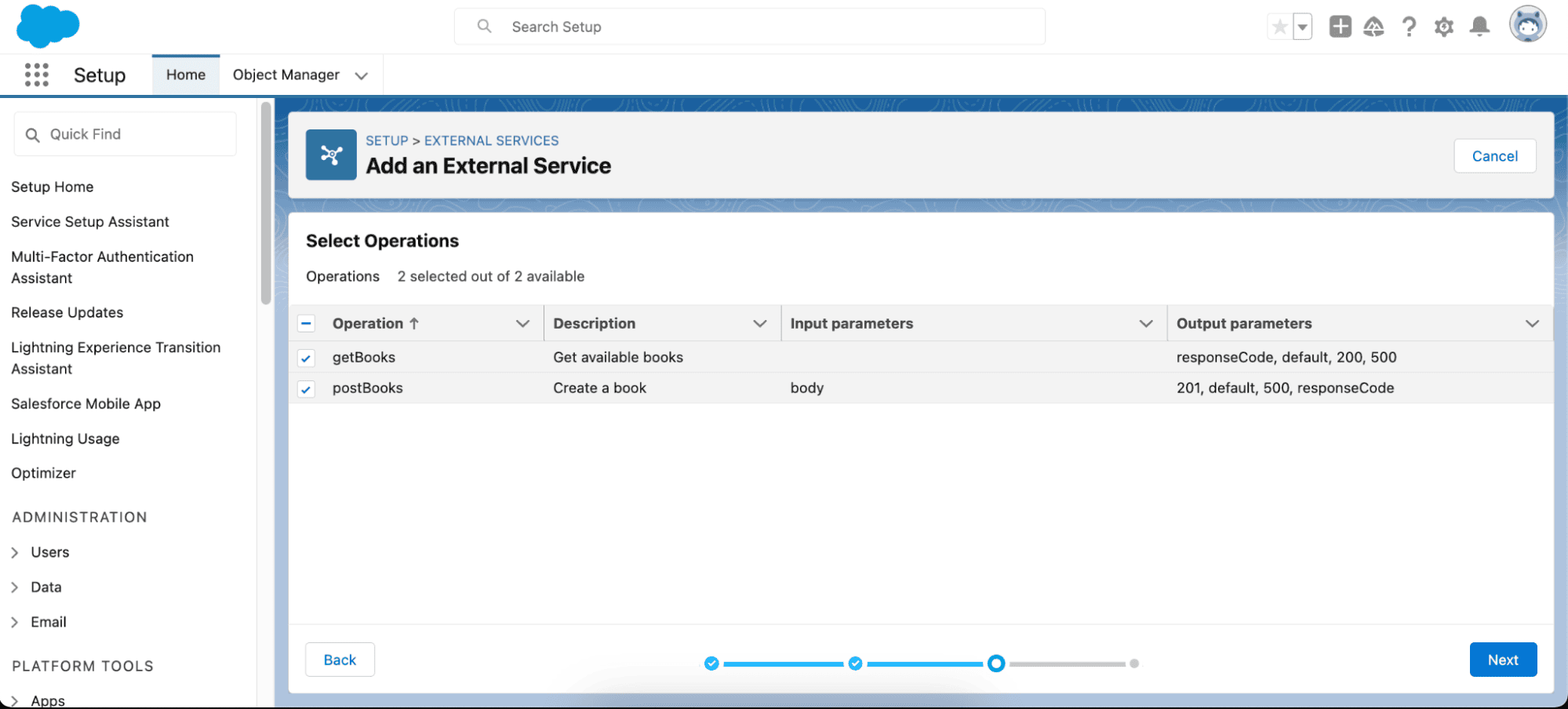
Después de eso, guarde sus cambios y seleccione las operaciones que desea importar a Salesforce, revise las operaciones y finalice.
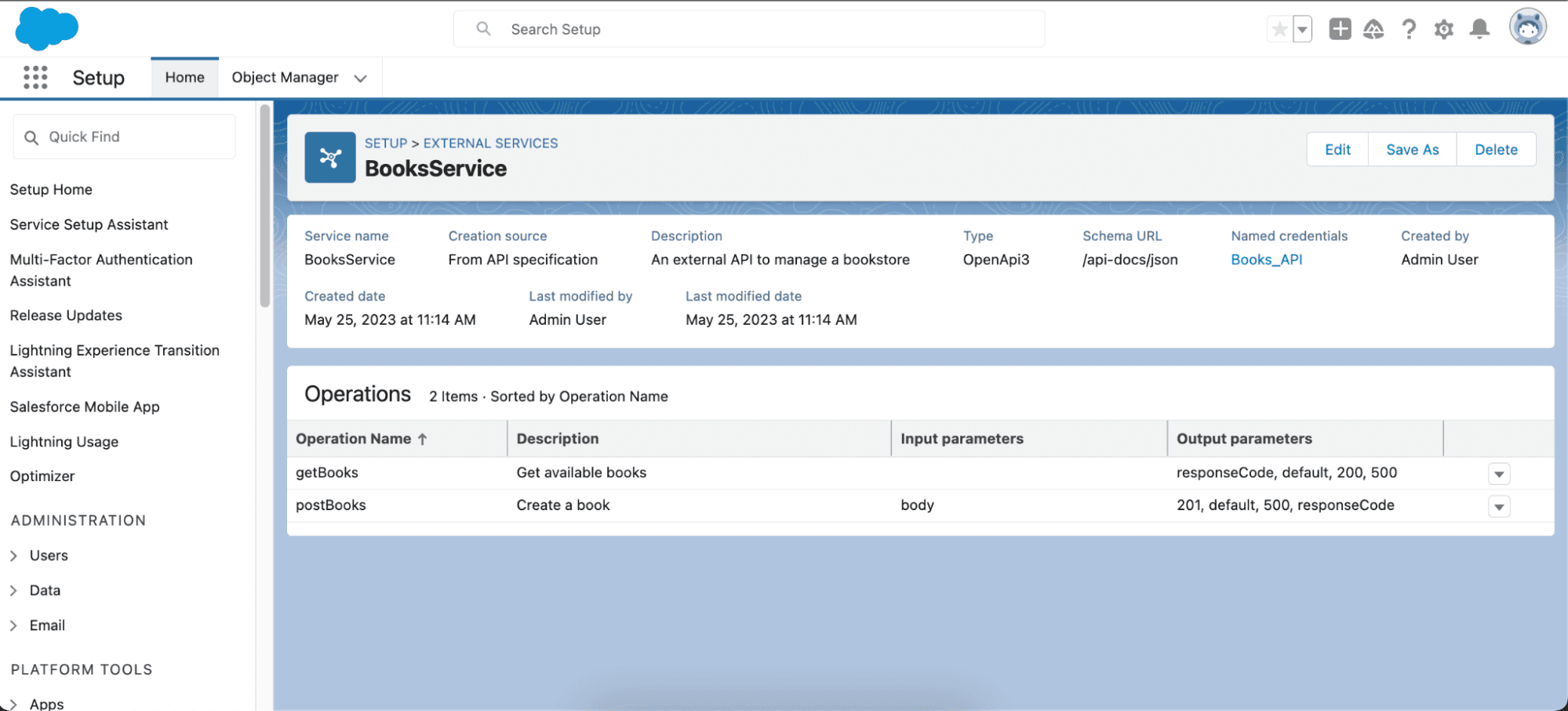
Como puede ver, las operaciones que ha seleccionado se han importado correctamente, especificando tanto los parámetros de entrada como los de salida.
Ahora podrá invocar este servicio externo desde Flow, Apex, Einstein Bots y OmniStudio.
Conclusión
OpenAPI y los servicios externos de Salesforce brindan una poderosa combinación para integrar API externas en su organización de Salesforce. Al aprovechar el enfoque estandarizado de OpenAPI para definir las API y la capacidad de Salesforce para consumir fácilmente estas definiciones e invocarlas desde soluciones de código bajo y pro-código, los desarrolladores como usted pueden optimizar el proceso de conexión a servicios externos y mejorar las capacidades de sus aplicaciones de Salesforce.
Si está interesado en obtener más información sobre los servicios externos , puede encontrar una lista de recursos de aprendizaje a continuación, incluidos videos que muestran cómo invocarlos desde Flow y Apex.
Recursos de aprendizaje
Sobre el Autor
Julián Duque es un defensor principal de desarrolladores en Salesforce, donde se enfoca en Node.js, JavaScript y desarrollo backend. Le apasiona la educación y el intercambio de conocimientos y ha estado involucrado en la organización de comunidades tecnológicas y de desarrolladores desde 2001.
Sígalo en Twitter @julian_duque, @julianduque.co en Bluesky social o LinkedIn.