Los representantes de ventas están en constante movimiento, pasando de un sitio de cliente a otro, con reuniones programadas de forma consecutiva. Las exigencias de gestionar un pipeline complejo y la necesidad de cambiar de contexto pueden ser abrumadoras. Por no mencionar que los representantes de ventas pueden
A medida que se acelera el desarrollo y despliegue de grandes modelos lingüísticos (LLMs), la evaluación de los resultados de los modelos se ha vuelto cada vez más importante. El método establecido para evaluar las respuestas normalmente implica reclutar y entrenar a evaluadores humanos, hacer que evalúen las respuestas del modelo y luego auditar la calidad de las evaluaciones. Por desgracia, este proceso no
La Generación Aumentada por Recuperación (RAG, por sus siglas en inglés) no sólo ha ganado fuerza como una de las áreas de investigación con mayor inversión en IA generativa, sino que también ha reunido una considerable popularidad y oportunidades de comercialización. La RAG se aplica normalmente a problemas de respuesta de preguntas, en los que se proporciona cierta información contextual externa recuperada de una fuente de datos (potencialmente privada)
La Generación Aumentada por Recuperación (RAG, por sus siglas en inglés) no sólo ha ganado fuerza como una de las áreas de investigación con mayor inversión en IA generativa, sino que también ha reunido una considerable popularidad y oportunidades de comercialización. La RAG se aplica normalmente a problemas de respuesta de preguntas, en los que se proporciona cierta información contextual externa recuperada de una fuente de datos (potencialmente privada)
Otros autores son: Chia-Chih Chen, Ning Yu, Zeyuan Chen, Huan Wang, Silvio Savarese, Stefano Ermon, Caiming Xiong
Hemos visto el éxito de ChatGPT, que incorpora feedback humano para alinear el texto generado por grandes modelos lingüísticos con las preferencias humanas. ¿Es posible alinear
En esta edición especial de “Engineering Energizers,” celebramos el 25 aniversario de Salesforce mostrando 25 herramientas de productividad clave preferidas por los ingenieros líderes de Salesforce en India, EE.UU., Israel y Argentina. Explore las herramientas esenciales en las que confían estos expertos para mejorar su productividad, abordar problemas complejos y elevar la innovación. 1. SLACK – Una plataforma de productividad […]
Descubrir por dónde empezar puede ser difícil para un nuevo desarrollador, independientemente de la plataforma, pero una buena hoja de ruta puede hacerlo más fácil.
Revisar objetos, campos, automatizaciones e incluso informes creados hace tiempo para optimizarlos puede llevar mucho tiempo, pero es una tarea importante con ventajas significativas. Construido con la facilidad de uso en mente tanto para los recién llegados como para los profesionales de Salesforce con mucha experiencia, Org Check es una herramienta gratuita que seguramente mejorará la forma en que […]
Los profesionales de Salesforce pueden utilizar Salesforce Org Check
The post Salesforce Org Check: Free Technical Debt Analysis appeared first on Salesforce Ben.
El análisis de la deuda técnica de Salesforce es gratuito
El SFR-Embedding-Mistral supone un avance significativo en los modelos de incrustación de textos y se basa en los sólidos cimientos de E5-mistral-7b-instruct y Mistral-7B-v0.1.
Por Krishna Pandey y Scott Nyberg. En nuestra serie de preguntas y respuestas «Engineering Energizers», examinamos las trayectorias profesionales que han formado a los líderes de ingeniería de Salesforce. Conozca a Krishna Pandey, Director de ingeniería de seguridad de Salesforce. Con sede en Bangalore (India), su equipo de tecnología de seguridad de aplicaciones (AST) impulsa el programa de seguridad del código fuente de Salesforce, encargado de utilizar la IA para detectar y […]
El aprendizaje a partir de preferencias humanas, concretamente el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF) ha sido un componente reciente clave en el desarrollo de grandes modelos lingüísticos como ChatGPT o Llama2. Hasta hace poco, el impacto del entrenamiento a partir de la retroalimentación humana en los modelos texto-imagen era mucho más limitado. En este trabajo, Diffusion-DPO,
Entrenamos una serie de LLMs 7B llamados XGen-7B con atención densa estándar hasta 8K de longitud de secuencia para hasta 1.5T tokens. También afinamos los modelos en datos de instrucción de dominio público. Los principales resultados son:
En pruebas de PNL estándar, XGen consigue resultados comparables o mejores
Contribución equitativa entre Erik Nijkamp y Hiroaki Hayashi.
Paper Code Tweet
Abstract
La familia de modelos CodeGen de Salesforce crece con CodeGen2.5 – ¡un modelo pequeño, pero poderoso! Mientras que ha habido una tendencia reciente de grandes modelos de lenguaje (LLM) de tamaño cada vez mayor, mostramos que un modelo pequeño
En el campo de la síntesis de texto a imagen, que avanza con rapidez, los notables progresos en la generación de imágenes realistas a partir de indicaciones textuales han sido evidentes. Sin embargo, sigue existiendo un reto importante: ¿cómo podemos integrar a la perfección potentes codificadores de texto preentrenados en
Por Shafiq Rayhan Joty y Scott Nyberg En nuestra serie «Engineering Energizers» Q&A, examinamos las trayectorias profesionales que han formado a los líderes de ingeniería de Salesforce. Conozca a Shafiq Rayhan Joty, Director de Salesforce AI Research. Shafiq codirige el desarrollo de XGen, una serie de innovadores modelos de lenguaje de gran tamaño (LLM) de distintos tamaños. Proporcionando conocimientos generales críticos, […]
Salesforce se guía por sus valores fundamentales de confianza, éxito del cliente, innovación, igualdad y sostenibilidad. Estos valores se reflejan en su compromiso de desarrollar e implantar de forma responsable nuevas tecnologías como la IA generativa en nombre de las partes interesadas, desde los accionistas hasta los clientes y el planeta. Los grandes modelos lingüísticos (LLM) que potencian la IA generativa requieren enormes […]
UniControl es aceptado en NeurIPS’23.¿Es posible que un único modelo domine el arte de crear imágenes a partir de bocetos, mapas, diagramas y mucho más? Aunque los generadores de texto a imagen basados en la difusión, como DALL-E-3, han mostrado resultados notables a partir de instrucciones en lenguaje natural, lograr un control preciso de los […]
Los diseños de maquetación gráfica son la base de la comunicación entre los diseñadores de medios y su público objetivo. Desempeñan un papel fundamental en la organización de diversos elementos visuales, como texto renderizado, logotipos, imágenes de productos, llamadas a la acción (como botones) y texturas/imágenes de fondo. La disposición de estos elementos es el
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Desmitificando Light DOM y sus casos de uso | Blog de desarrolladores de Salesforce
Light DOM es una función de Lightning Web Components que ha estado disponible de forma general en Lightning Experience, Experience Cloud, LWC OSS (código abierto) y todas las versiones de la aplicación móvil Salesforce desde Summer '23 .
Los componentes web Lightning, de forma predeterminada, se representan en DOM oculto , lo que proporciona una encapsulación y seguridad sólidas para sus componentes. Sin embargo, al mismo tiempo, evita el estilo global y bloquea las integraciones de terceros que introspeccionan el interior de sus componentes. Light DOM es una característica que se puede habilitar de forma granular en componentes seleccionados, de modo que Shadow DOM no los afecte.
¿Cómo funciona el DOM ligero?
Usemos un componente web Lightning muy simple como ejemplo.
holaCodey.html
<dx-code-block title language="html" code-block="
Hello Codey!
«>
holaCodey.js
En el ejemplo anterior, el DOM oculto predeterminado del componente evita que una regla CSS definida en el componente principal o el host alcance el elemento <p> . Además, no permite que el código JavaScript externo al componente consulte el elemento <p> mediante las API de consulta del navegador.
Para activar el DOM ligero para un componente, debe especificar el renderMode ligero en su archivo JavaScript y la directiva de plantilla lwc:render-mode en la etiqueta <template> del componente. Ambos cambios son necesarios debido a la forma en que se compilan los componentes web Lightning.
holaCodey.html
<dx-code-block title language="html" code-block="
Hello Codey!
«>
holaCodey.js
Cuando activa el DOM claro en un componente, el marcado del componente se adjunta al elemento anfitrión en lugar de a su árbol de sombra. Luego puede acceder al marcado desde otros componentes de la página como cualquier otro contenido en el host del documento que no esté protegido por Shadow DOM.
Los componentes DOM ligeros permiten el uso de API de consulta de navegador estándar como querySelector y querySelectorAll . En este caso, en lugar de usar this.template.querySelector , debes usar this.querySelector .
holaCodey.js
O más simplemente, a menudo puedes usar la directivalwc:ref en ambos casos (componentes DOM sombreados y claros) y omitir el querySelector .
holaCodey.html
<dx-code-block title language="html" code-block="
Hello Codey!
«>
holaCodey.js
Cuándo usarlo y cuándo no usarlo
Light DOM es una opción para cada componente individual. Sus efectos no se aplicarán a otros componentes a menos que también opten por participar. Tenga en cuenta que los componentes base siempre se representan en DOM oculto.
Recomendamos habilitar DOM ligero si tiene bibliotecas que necesitan acceder a los componentes internos mediante API de consulta de navegador estándar, aplicar estilos globales o necesita más flexibilidad para implementar las mejores prácticas de accesibilidad, siempre y cuando el componente no exponga datos confidenciales. Cubriremos estos casos de uso con más profundidad en la siguiente sección.
No recomendamos habilitar DOM ligero para un componente si ese componente aparece o funciona con datos confidenciales. El uso de DOM ligero elimina la encapsulación de DOM en sombra y expone los componentes al raspado de DOM. Por lo tanto, tenga en cuenta esta importante consideración.
Casos de uso habilitados por DOM ligero
Light DOM permite varios casos de uso que anteriormente no eran compatibles.
1) Soporte de bibliotecas que necesitan acceso a las partes internas de un componente
Light DOM permite el uso de bibliotecas que necesitan acceso a los componentes internos. Un buen ejemplo de esto son las bibliotecas de análisis utilizadas en los sitios de Experience Cloud, como Google Analytics, ya que necesitan acceso a los componentes internos para obtener mejores resultados.
Podemos probar este caso de uso, incluido el componente helloCodey anterior, en un componente principal mascotChanger de la siguiente manera.
mascotChanger.html
<dx-code-block title language="html" code-block="
«>
mascotChanger.js
Tenga en cuenta que, aunque el párrafo consultado pertenece al componente helloCodey , podemos acceder a él con this.template.querySelector , porque pertenece al DOM ligero secundario. Sin embargo, si el componente helloCodey no tuviera habilitado el DOM ligero, querySelector habría devuelto null .
También puede acceder a los componentes internos del DOM ligero desde un script que se carga como un recurso estático en la página, siempre y cuando todos los componentes ancestros estén habilitados para el DOM ligero. Por ejemplo, en un sitio LWR Experience Cloud, que es DOM completamente ligero, puede agregar un recurso estático de JavaScript que encuentre los componentes internos helloCodey de la siguiente manera.
myJSResource.js
2) Implementación más sencilla de componentes profundamente anidados
Otro ejemplo en el que esto puede resultar útil es implementar componentes complejos y profundamente anidados. En ese caso, es posible que prefiera tener un único componente DOM de sombra en el nivel superior y componentes DOM claros dentro para evitar gastos generales. Por ejemplo, un componente de tabla de datos personalizado puede tener solo un gran componente DOM de sombra alrededor de todo, en lugar de una sombra para cada fila y celda de la tabla.
Esta implementación facilita la consulta de sus propios elementos desde el componente de nivel superior de su jerarquía y también la implementación de la accesibilidad. Además, hay una ligera mejora en el rendimiento en algunos casos de uso al usar DOM claro sobre DOM sombreado, lo que se debe principalmente a la sobrecarga de simplemente crear nodos de sombra adicionales.
3) Estilo global
Light DOM también facilita el estilo global, ya que permite que los estilos CSS caigan en cascada en el marcado del componente. Por ejemplo, un componente DOM ligero puede establecer un estilo que se carga y luego se aplica una vez para todos los componentes DOM ligeros de la página. La inyección de estilos globales a través de DOM ligero solo se admite en sitios de Experience Cloud, editor de contenido CMS o Sales Enablement.
Por ejemplo, definamos un componente colorChanger de la siguiente manera.
colorChanger.html
<dx-code-block title language="html" code-block="
«>
colorChanger.js
colorChanger.css
El color de fondo azul se aplicará a los párrafos de todas las instancias del componente helloCodey en la página, ya que está habilitado para DOM claro.
En la mayoría de los casos, no querrás que tu estilo se filtre a otros componentes. Eso todavía es posible para componentes DOM ligeros. Solo necesita colocar esas reglas de estilo en un archivo *.scoped.css , para que tengan como alcance el componente DOM ligero. El CSS con alcance está escrito exactamente igual que el CSS normal, pero solo se aplicará a ese componente sin filtrarse.
Tenga en cuenta que si las reglas de estilo se cargan globalmente como recursos estáticos en una página de Lightning Experience o un sitio de Experience Cloud, se les quitará el alcance y se aplicarán tanto a los componentes DOM claros como también a los componentes DOM de sombra, ya que la sombra sintética no evitará que se filtren. Esta es una limitación que se solucionará una vez que la sombra nativa sea totalmente compatible (actualmente en Developer Preview ). Cuando la sombra nativa está habilitada, solo los componentes habilitados para DOM claro heredarán los estilos globales.
4) Implementación más flexible de las mejores prácticas de accesibilidad
Light DOM permite que un componente haga referencia a la idun elemento que vive en otro componente separado habilitado para Light DOM. Esto le permite vincular dos elementos utilizando los atributos idy aria , lo que le otorga flexibilidad adicional para implementar las mejores prácticas de accesibilidaden sus proyectos. Mejoremos nuestro componente mascotChanger para demostrar esto.
mascotChanger.html
<dx-code-block title language="html" code-block="
«>
mascotChanger.js
mascotaNombreInput.html
<dx-code-block title language="html" code-block="
«>
mascotaNombreEtiqueta.html
<dx-code-block title language="html" code-block="
«>
Tenga en cuenta que Salesforce está trabajando actualmente con el W3C para agregar nuevos estándares, de modo que el DOM oculto nativo pueda participar en estos patrones de accesibilidad. Esto significa que, en el futuro, este caso de uso ligero de DOM no será necesario. Como parte de nuestros esfuerzos de accesibilidad, también patrocinamos a Igalia para implementar parcialmente ARIA Element Reflection , que ahora es totalmente compatible con Safari y parcialmente con Chrome. Si quieres saber más sobre este tema, echa un vistazo a nuestra propuesta cross-root-aria , el repositorio para el grupo de trabajo Modelo de objetos de accesibilidad .
La siguiente tabla resume los casos de uso y dónde se admiten.
Experiencia en la nube
Experiencia relámpago
Aplicaciones móviles de Salesforce
LWC OSS/LWR en Node.js*
Soporte de bibliotecas que necesitan acceso a las partes internas de los componentes.
Sí
Sí
Sí
Sí
Implementación más sencilla de componentes profundamente anidados
Sí
Sí
Sí
Sí
Estilo global
Sí
No
No
Sí
Implementación más flexible de las mejores prácticas de accesibilidad
Sí
Sí
Sí
Sí
*Si se utiliza DOM de sombra nativo en lugar de sombra sintética . La sombra nativa es la opción predeterminada para LWC OSS y LWR en Node.js.
Otras Consideraciones
Cuando se trabaja con DOM ligero, hay algunas consideraciones adicionales a tener en cuenta, entre ellas:
No hay soporte de navegador para espacios fuera del DOM oculto, por lo que se emula. Esto implica que algunas funciones, como los enlaces de ciclo de vida, no están disponibles en ellos. Eche un vistazo a ladocumentación para saber más.
Por ahora, los componentes ligeros habilitados para DOM no se pueden empaquetar.
Conclusión
En esta publicación de blog, revisamos qué es el DOM ligero, los casos de uso que permite y las consideraciones a tener en cuenta para decidir qué componentes habilitarán la función. Todos los ejemplos que se muestran en este blog se encuentran en un repositorio de GitHub que puedes probar tú mismo.
Para obtener más información sobre DOM ligero en la plataforma Salesforce, lea la documentación o, si está trabajando fuera de la plataforma, lea la documentación OSS .
Si decide seguir adelante y transformar sus componentes DOM ocultos en componentes DOM claros, consulte esta herramienta creada por Salesforce Engineering para simplificar la migración.
Sobre el Autor
Alba Rivastrabaja como Principal Developer Advocate en Salesforce. Puedes seguirla enLinkedin , Twitter o GitHub .
Obtenga las últimas publicaciones de blog y episodios de podcasts para desarrolladores de Salesforce a través de Slack o RSS.
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Introducción a los agentes autónomos | Blog de desarrolladores de Salesforce
El panorama de la IA está cambiando a un ritmo tan rápido que las tecnologías futuristas como la IA autónoma ya están mucho más cerca de lo que piensas. Esto se debe a la forma en que los grandes modelos de lenguaje (LLM) están comenzando a incorporarse en casi todas las formas en que interactúa con las aplicaciones. Para los desarrolladores, esto supone un cambio en la forma en que abordamos la creación de aplicaciones, desde las formas en que las reunimos hasta la creación con una UX conversacional completamente nueva.
En esta publicación de blog, veremos cómo los agentes autónomos incorporan la IA a la forma en que funcionan las aplicaciones y, al mismo tiempo, nos acercan a un mundo autónomo.
¿Qué son los agentes autónomos?
En nuestro panorama tecnológico, los agentes son sistemas avanzados que aprovechan el poder de los modelos lingüísticos para razonar y tomar decisiones. Lo que los diferencia de otro bot o marco es el hecho de que los agentes pueden realizar tareas en su nombre utilizando herramientas y memoria.
Las herramientas son extensiones de las capacidades de un modelo de lenguaje, que cierran brechas en su conocimiento y le permiten interactuar con fuentes de datos externas o recursos computacionales. Con estas herramientas, un modelo de lenguaje puede obtener datos en tiempo real, ejecutar tareas y utilizar los resultados para informar sus acciones posteriores. Por ejemplo, si un modelo de lenguaje conoce información solo hasta una fecha determinada, las herramientas pueden proporcionarle información más actualizada de la web, bases de datos u otras fuentes externas.
La memoria proporciona a los agentes la capacidad de recordar interacciones pasadas, lo que puede ser esencial para la continuidad de las tareas y el aprendizaje de acciones anteriores. Esta memoria puede ser de corta duración, centrándose en interacciones recientes, o de largo plazo, recordando eventos o patrones pasados importantes que son relevantes para situaciones actuales.
Juntos, estos elementos transforman un modelo de lenguaje en un agente que no sólo puede comprender y generar texto, sino también actuar sobre esa comprensión en contextos del mundo real. Dichos agentes pueden ejecutar soluciones de forma autónoma para los usuarios, pero también pueden integrar la intervención humana, especialmente en escenarios donde existen incertidumbres o excepciones.
El agente determina la acción, selecciona la herramienta relevante y decide la entrada para esa herramienta.
La herramienta ofrece un resultado.
El proceso recorre los pasos 2 a 4 hasta que el agente determina que la tarea está completa
Este proceso es el que empieza a hacer autónomo al agente. Al confiar en el LLM para pensar en la respuesta y determinar las acciones apropiadas necesarias, actúa por sí solo para crear el resultado deseado.
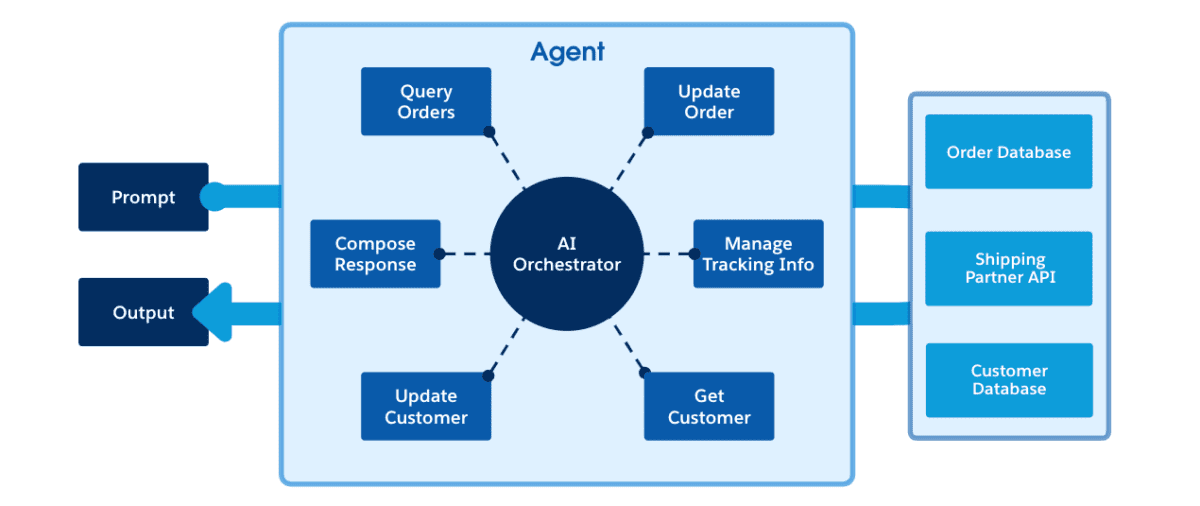
Usando LangChain como ejemplo, digamos que queremos crear una aplicación que permita a un cliente gestionar sus pedidos. Primero, podríamos darle a la aplicación acceso a nuestra base de datos de pedidos, base de datos de clientes y API de socios de envío. Luego, configuraríamos una serie de herramientas a las que puede acceder la aplicación para consultar datos, actualizarlos y utilizar IA generativa para redactar una respuesta.
Este agente de gestión de pedidos dispone de seis herramientas que puede utilizar “dentro de su dominio de conocimiento”:
Query Orders es una herramienta que puede consultar pedidos desde una base de datos a través de una API conectada a una base de datos PostgreSQL.
Update Order es una herramienta que puede actualizar un único pedido desde una base de datos a través de una API conectada a una base de datos PostgreSQL.
Manage TrackingInfo es una herramienta que puede gestionar un envío a través de una API proporcionada por una empresa de envío
Get Customer es una herramienta que puede consultar datos de clientes desde una API conectada a un sistema CRM
Update Customer es una herramienta que puede actualizar los datos de los clientes a través de una API conectada a un sistema CRM
Compose Response es una herramienta que puede pasar indicaciones a un LLM y devolver una respuesta.
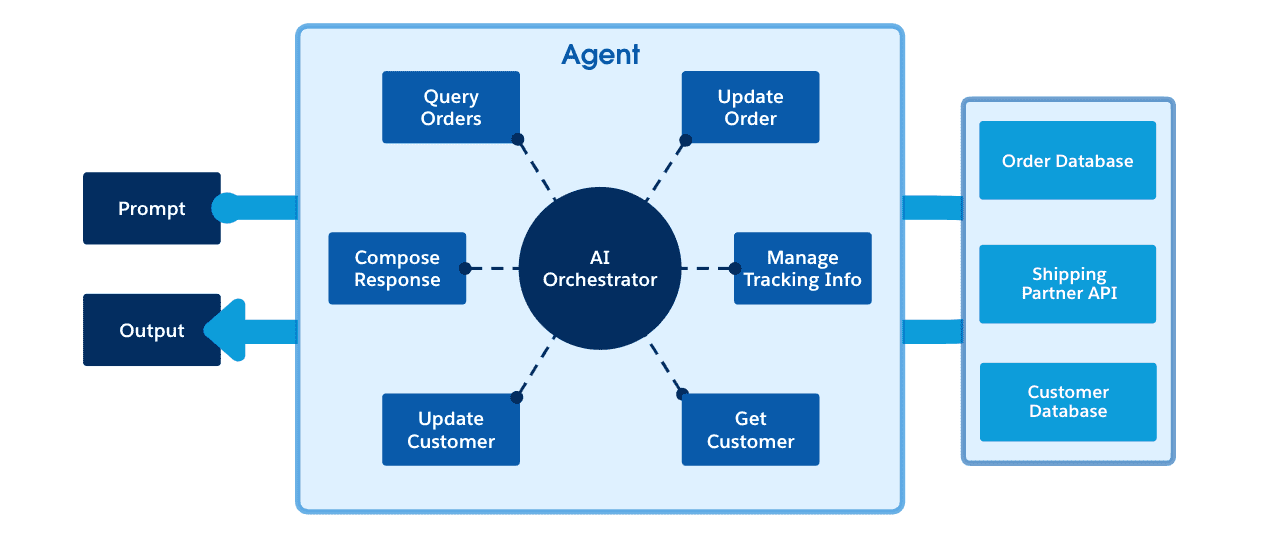
Veamos ahora cómo un agente podría manejar casos de uso relacionados con la gestión de pedidos. Por ejemplo, ¿cómo puede el agente ayudar a un usuario a obtener una actualización sobre el estado de su pedido?
El usuario solicita la información más reciente de su pedido a través de un chatbot
El agente “piensa” y determina la acción correcta que debe tomar
El agente primero utiliza la herramienta Consultar cliente para consultar los detalles del cliente.
Luego, el agente utiliza la herramienta Consultar pedidos para consultar pedidos desde una base de datos.
Luego, el agente utiliza la herramienta Administrar información de seguimiento para obtener la información de envío más reciente de su socio de envío.
Luego, el agente toma ambos resultados y utiliza la herramienta Redactar respuesta para generar una respuesta.
La respuesta se devuelve al usuario.
En este escenario, el agente pudo tomar las herramientas que le proporcionamos y determinar el pedido y los parámetros que necesitan para crear el resultado correcto para el usuario, en este caso, toda su información de pedido y envío. Lo que es importante tener en cuenta aquí es que el usuario puede hacerle al agente cualquier pregunta sobre su pedido y el agente puede usar IA para razonar y usar las herramientas en el orden que necesite.
Como desarrollador, su función se centra más en crear las herramientas y permitir que el agente administre la orquestación.
Mantener a un humano informado
El desafío ético con los agentes autónomos es que no hay ningún ser humano involucrado cuando se trata de ejecutar las acciones. En Salesforce, estamos comprometidos con el uso ético de la IA y queremos dejarlo claro en nuestras implementaciones de este tipo de tecnología. Ciertas reglas exigen que una persona sea responsable de tomar la decisión final en asuntos con consecuencias legales o de impacto comparable, incluida la contratación laboral, la aprobación de préstamos, las admisiones educativas y las sugerencias en justicia penal. Esta insistencia en la supervisión humana, en lugar de decisiones automatizadas, tiene como objetivo identificar y reducir mejor los posibles sesgos y daños.
¿Qué significa esto para el futuro de Salesforce?
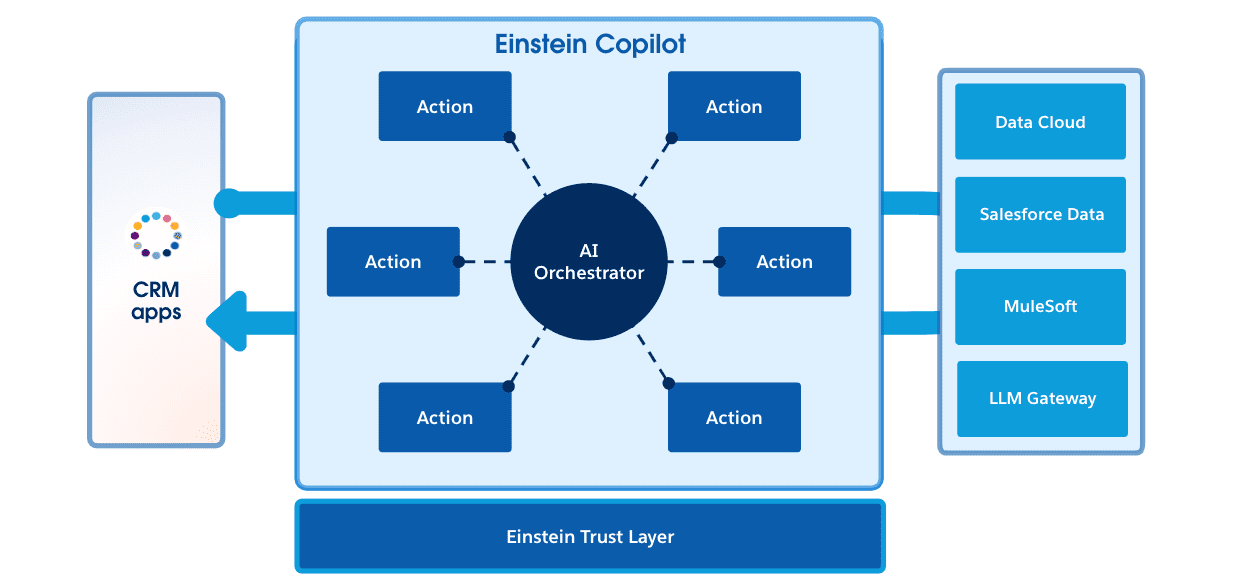
En Dreamforce este año, les dimos una idea de cómo será el futuro de Salesforce y la IA autónoma en la plataforma Einstein 1. Einstein Copilot es nuestra respuesta a un asistente conversacional de IA generativa basado en agentes que utiliza habilidades y acciones para guiar a los usuarios a través de la interacción con Salesforce. Esto introduce un paradigma de desarrollo completamente nuevo para Salesforce, uno en el que estamos creando piezas de funcionalidad más pequeñas que pueden ser orquestadas por Einstein Copilot.
¿Cómo se compara Einstein Copilot con un agente de IA?
Si bien existen varias similitudes entre Copilot y un marco de agente de código abierto, la verdadera diferencia es el acceso de Copilot a toda la plataforma de metadatos de Salesforce. No sólo eso, sino que el alcance es mucho mayor. En lugar de agentes individuales, tienes muchas habilidades , y en lugar de herramientas tienes acciones .
Por ejemplo, si desea actualizar un pedido utilizando Copilot, deberá crear una habilidad de gestión de pedidos. Con otros marcos, necesitarías crear un agente completo para la gestión de pedidos.
Cuando se trata de acciones, usted tiene el poder de la Plataforma Einstein 1 detrás de usted. Podrá utilizar Apex, Flow, las numerosas API de plataforma, SOQL y mucho más para brindarle a su habilidad la capacidad de reunir datos desde cualquier lugar. También tiene acceso directo a los datos de toda la plataforma.
Estudio Einstein Copiloto
Estas habilidades y acciones se reúnen en Einstein Copilot Studio , que le permite ensamblar flujos, indicaciones, Apex y más en colecciones de funcionalidades.
Actualmente existen tres herramientas dentro de Einstein Copilot Studio:
Prompt Builder le permite crear plantillas de mensajes utilizando campos de combinación de registros y datos proporcionados por Flow y Data Cloud.
Skills Builder le permite ensamblar acciones, como métodos invocables de Apex, flujos y llamadas de API de MuleSoft, y otorgárselas a un agente.
Model Builder le permite traer sus propios modelos de IA a Salesforce
Juntos, podrán crear agentes potentes en Salesforce que puedan usar su código para responder preguntas y ayudar a los usuarios.
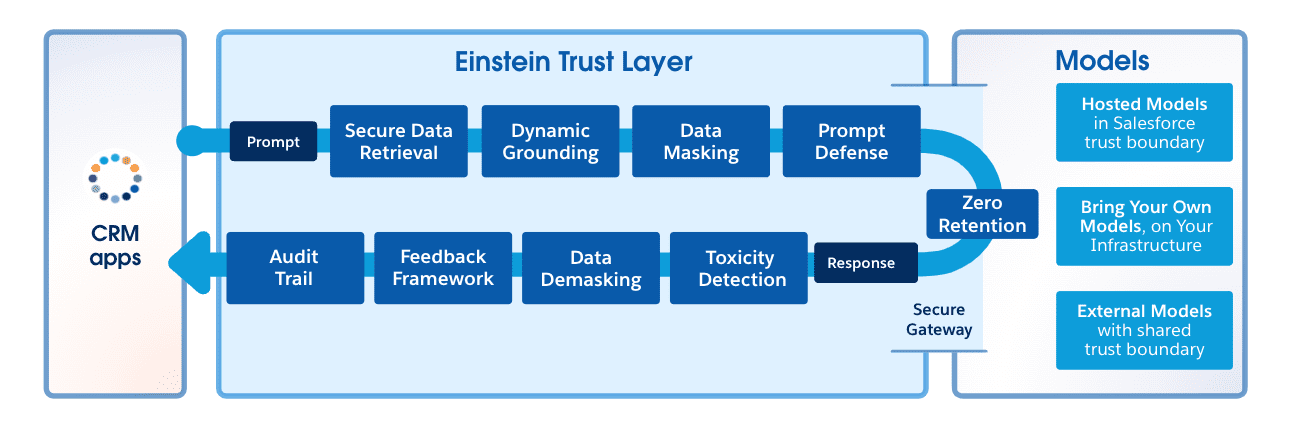
La capa de confianza de Einstein
Una gran ventaja de Einstein Copilot es Einstein Trust Layer. Trust Layer proporciona un entorno seguro para el procesamiento de datos a través de un modelo de lenguaje grande, lo que garantiza que los datos del usuario permanezcan confidenciales al enmascarar información de identificación personal, verificar la salida en busca de contenido inapropiado y garantizar que no haya persistencia de datos fuera de Salesforce.
Trust Layer se ejecuta a través de un proceso de varios pasos para garantizar que los datos estén fundamentados y enmascarados antes de ser procesados por un proveedor de LLM externo, y proporciona una puerta de enlace segura para interactuar con dichos LLM. Una vez que se ha generado una respuesta, la verifica en busca de contenido tóxico y desenmascara los datos antes de presentárselos al usuario. Puede ver más de cerca la capa de confianza en nuestra publicación de blog Dentro de la capa de confianza de Einstein .
Resumen
La IA autónoma se hace realidad mucho más cerca a través de agentes, lo que marca el comienzo de una nueva era de tecnología en la que el razonamiento y la toma de decisiones se potencian con herramientas y memoria. Einstein Copilot de Salesforce introduce este enfoque impulsado por agentes en la plataforma, ofreciendo un asistente de IA conversacional que guía a los usuarios, aprovecha los vastos metadatos de Salesforce y garantiza la integridad de los datos a través de Einstein Trust Layer. Este cambio transformador significa no sólo una evolución en las interacciones de IA, sino también una promesa de experiencias seguras, eficientes y fluidas para los usuarios de Salesforce.
Sobre el Autor
Stephan Chandler-García es el director de contenido estratégico de Salesforce. Ha estado en el ecosistema de Salesforce durante más de 10 años como cliente, socio e ISV. Puede encontrar a Stephan en persona en un grupo comunitario Trailblazer o en una de nuestras conferencias en todo el mundo. Alternativamente, sígalo en X (Twitter) o GitHub .
Obtenga las últimas publicaciones de blog y episodios de podcasts para desarrolladores de Salesforce a través de Slack o RSS.
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Habilitación de MFA en MuleSoft para canalizaciones de CI/CD mediante acciones de GitHub | Blog de desarrolladores de Salesforce
La mayoría de las cuentas empresariales de Anypoint Platform requieren que utilice mecanismos de autenticación multifactor (MFA) para mayor seguridad. Esto significa que, además de su nombre de usuario y contraseña habituales, necesitará un paso adicional para autenticarse (por ejemplo, una aplicación de autenticación en su teléfono).
Cuando utiliza canalizaciones de CI/CD para sus aplicaciones Mule y MFA está habilitado en su cuenta, la configuración para autenticarse usando el complemento Mule Maven será diferente que si solo estuviera usando su nombre de usuario y contraseña. Hay más pasos que debe seguir desde su cuenta de Anypoint Platform para habilitar sus canales de CI/CD con este método de autenticación.
En esta publicación, aprenderá cómo configurar una canalización de GitHub Actions para que funcione con su cuenta habilitada para MFA desde Anypoint Platform.
Requisitos previos
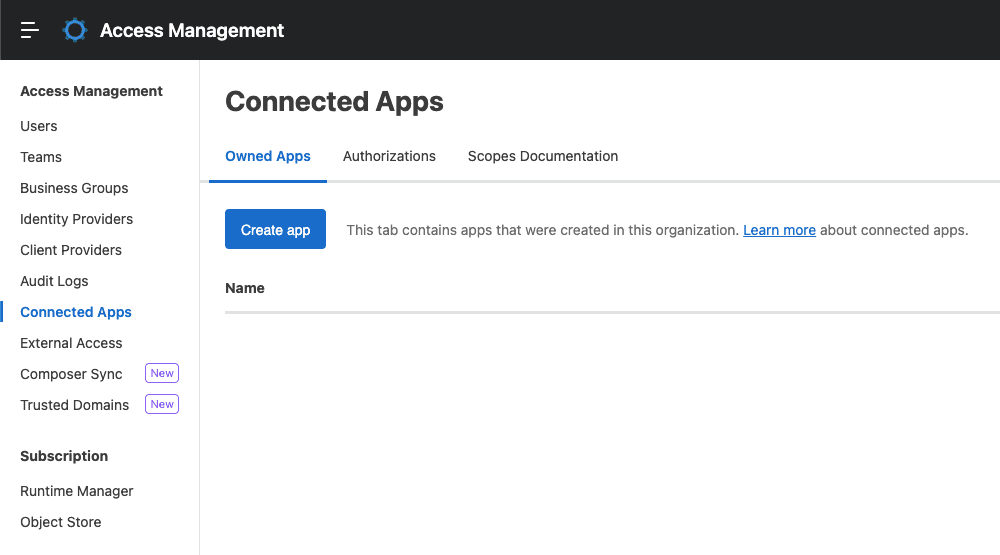
Crear una aplicación conectada
Dado que usar el nombre de usuario y la contraseña de su plataforma Anypoint no es suficiente para autenticarse en el proceso, debe crear unaaplicación conectadapara usar sus credenciales (ID/Secreto). Para crearlo, vaya a su cuenta de Anypoint Platform y navegue hastaGestión de acceso>Aplicaciones conectadas>Crear aplicación.
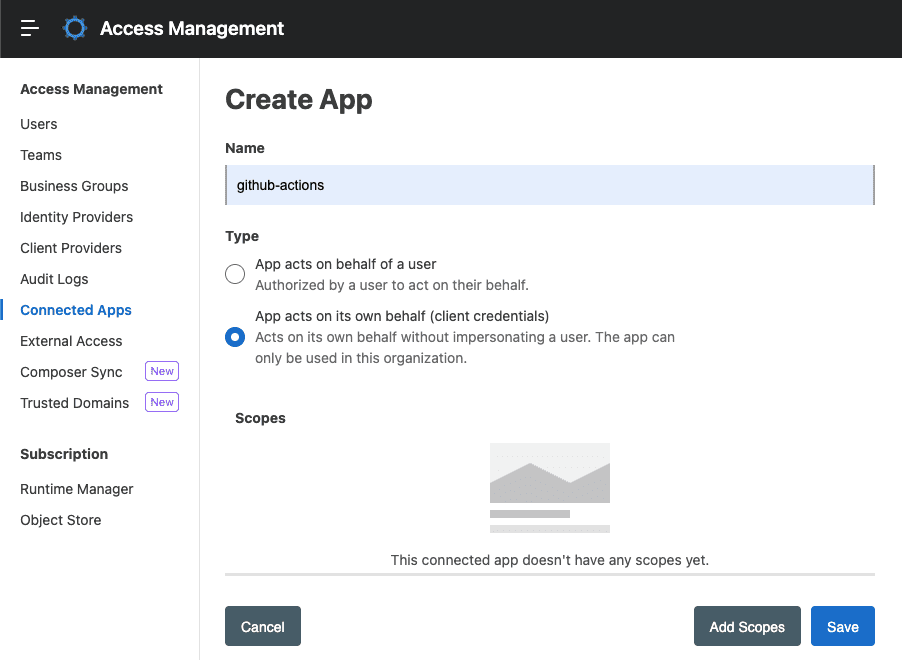
Asigne un nombre a su aplicación para identificarla de otras que pueda crear. Por ejemplo,github-actions. Seleccione el tipo La aplicación actúa por sí solay haga clic en el botón Agregar ámbitos.
Seleccione los siguientes 10 ámbitos.
Desarrollador del centro de diseño
Ver entorno
Ver organización
Perfil
Administrador de organización de CloudHub
Crear aplicaciones
Eliminar aplicaciones
Descargar aplicaciones
Leer aplicaciones
Leer servidores
Haga clic enSiguiente. Seleccione su grupo empresarial y haga clic enSiguiente. Seleccione su entorno (por ejemplo, Sandbox) y haga clic enSiguiente. Revise que los alcances sean correctos y haga clic enAgregar alcances. Haga clic enGuardar.
Una vez creada la aplicación, asegúrese de copiar tantoel IDcomoel Secreto. Los utilizará en la configuración de la canalización como método de autenticación.
Configura tus secretos de GitHub Actions
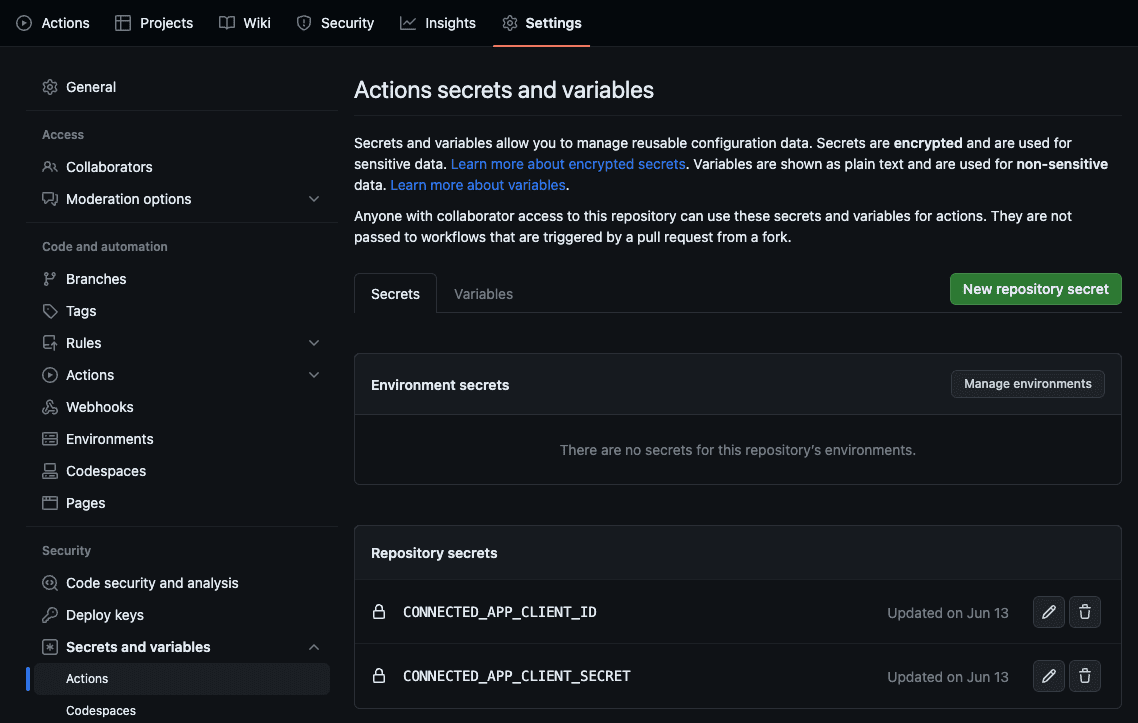
Vaya a su repositorio de GitHub. Haga clic en lapestañaConfiguración > Secretos y variables>Acciones>Nuevo secreto del repositorio. En el campo de nombre, agregueCONNECTED_APP_CLIENT_ID. En el campo secreto, agregue la identificación real que acaba de copiar en el paso anterior.Repita este paso para crear otro secreto con el secreto real que copió en el paso anterior. Utilice el nombreCONNECTED_APP_CLIENT_SECRET.
Crear una canalización de CI/CD
De vuelta en el código de su aplicación Mule, cree una carpeta .githuben el nivel raíz. Dentro de esta carpeta, cree otra carpeta llamadaworkflows. Dentro de esta carpeta, cree un archivo build.ymlcon el siguiente contenido:mule-mfa-cicd-build.yml. Tenga en cuenta que la sucursal mainse utiliza en la línea 5. Si su sucursal tiene un nombre diferente, asegúrese de actualizar esta configuración.
En este archivo, describimos los pasos para generar el archivo JAR de nuestra aplicación Mule e implementarlo en nuestra cuenta de Anypoint Platform usando GitHub Actions. Observe que estamos usando los secretos creados previamente en el último paso para pasarlos a nuestro proyecto a través de Maven. Aquí declaramos dos variables de entorno Java (client.idyclient.secret) para copiar las credenciales de nuestra aplicación de los secretos de GitHub para que el archivo pom.xml pueda usarse más adelante.
Modifica tu configuración de Maven
En su proyecto Mule, abra su archivo pom.xml. Localice el complemento org.mule.tools.mavenenproject/build/plugins. Agregue la siguiente configuración a este complemento.
Vuelva a verificar estas configuraciones en caso de que necesite actualizarlas para que coincidan con su caso de uso. Por ejemplo,muleVersion,applicationName,environmentoregion. Usaremos los campos connectedAppClientIdyconnectedAppClientSecretpara pasar las variables Java que declaramos anteriormente en la configuración de Maven.
Es importante que no codifique las credenciales de la aplicación conectada en este archivo por razones de seguridad. Es por eso que mantenemos los valores como secretos de GitHub. Recuerda que puedes accedera nuestro repositorio de ejemplosi necesitas comparar tu código con el nuestro.
ejecutar la tubería
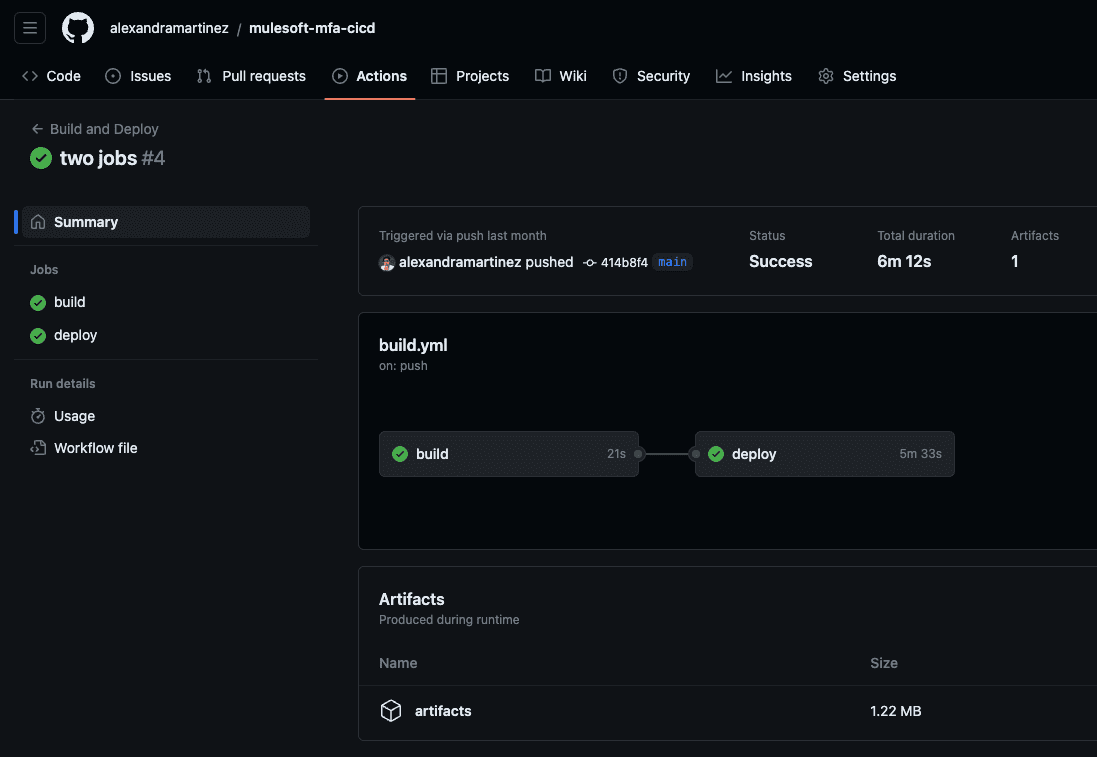
Una vez que todas sus configuraciones estén listas, confirme y envíe sus cambios al repositorio remoto. Esto activará la canalización en GitHub. Puede ver el proceso haciendo clic en la pestaña Accionesde su repositorio de GitHub.
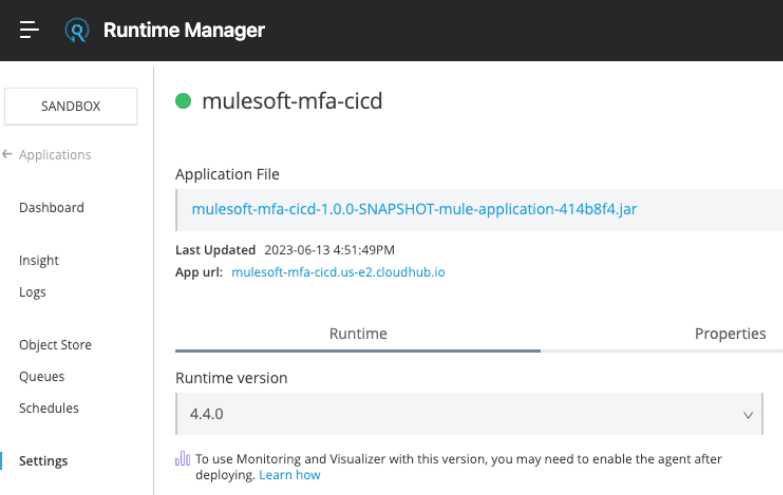
Una vez completado el proceso, su aplicación Mule se implementará en Runtime Manager. Tenga en cuenta que el archivo JAR contendrá el hash de confirmación en su nombre.
Conclusión
Habilitar canalizaciones de CI/CD es importante para automatizar tareas repetitivas. En lugar de implementar manualmente una aplicación Mule cada vez que hay un cambio en el código, podemos crear canalizaciones para que realicen estas tareas por nosotros. Este fue un ejemplo simple que utiliza solo una sucursal y un entorno, pero puede conectar otras sucursales a otros entornos en Anypoint Platform. Por ejemplo,dev,qa,prod, etc.
En esta publicación, aprendimos cómo implementar automáticamente una aplicación Mule en CloudHub cuando usamos la autenticación multifactor en nuestra cuenta de Anypoint Platform porque la mayoría de las cuentas empresariales tienen esta configuración habilitada. Sin embargo, cuando solo usa una cuenta de prueba gratuita, no necesita crear una aplicación conectada si no usa MFA en su cuenta. Puede utilizar su nombre de usuario y contraseña de Anypoint Platform para iniciar sesión.
Hay muchas cosas que puede automatizar al utilizar canalizaciones de CI/CD para sus aplicaciones Mule. Puedes ejecutar pruebas automatizadas antes de implementar tu aplicación Mule, por ejemplo. ¿Se te ocurren otras tareas repetitivas que puedas automatizar en tus canalizaciones?
Nota: Las versiones iniciales de la canalización se basan en el siguiente repositorio creado por Archana Patel:arch-jn/github-actions-mule-cicd-demo.
Recursos adicionales
Sobre el Autor
Alex Martínez formó parte de la comunidad de MuleSoft antes de unirse a MuleSoft como desarrollador defensor. Fundó ProstDev para ayudar a otros profesionales a aprender más sobre la creación de contenido. En su tiempo libre, encontrarás a Alex jugando juegos de Nintendo o Playstation y escribiendo reseñas sobre ellos. Siga a Alex en LinkedIn o en la comunidad Trailblazer .
Obtenga las últimas publicaciones de blog y episodios de podcasts para desarrolladores de Salesforce a través de Slack o RSS.
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
¡Ya está aquí la CLI sf (v2) de Salesforce! — Parte 2 | Blog de desarrolladores de Salesforce
La CLI (interfaz de línea de comandos) de Salesforce es la piedra angular del desarrollo de Salesforce y, como cualquier otra herramienta, evoluciona con el tiempo. Esta publicación es la segunda de una serie de blogs de dos partes sobre sf (v2), la nueva y mejorada CLI de Salesforce. En la Parte 1 , echamos un vistazo a las novedades de sf (v2) y, en esta parte final, exploraremos los nuevos comandos de estilo sf y patrones de banderas y compartiremos cómo puede migrar desde comandos de estilo sfdx y patrones basados en banderas. en nuestra experiencia con aplicaciones de muestra . Si bien la migración puede parecer intimidante a primera vista, compartiremos algunos consejos sobre cómo facilitar la transición.
Conozca los comandos de estilo sf
Si ha estado usando la CLI durante algún tiempo, probablemente comenzó a notar una serie de advertencias en los comandos que usa con frecuencia, como este:
sfdx force:source:push
Warning: We plan to deprecate this command in the future. Try using the "project deploy start" command instead.»>
Estos cambios son el resultado del trabajo continuo en Salesforce CLI Unification que comenzó hace varios lanzamientos (más detalles en la primera parte de esta serie).
Desde entonces, cada vez que instala la CLI de Salesforce, obtiene los dos ejecutables ( sfdx y sf ). Puede usar cualquiera de estos ejecutables ya que la mayoría de los comandos son interoperables, pero le recomendamos que comience a usar sf en su trabajo diario para prepararse para el futuro.
Debido a que sf cubre más que solo el desarrollo de la plataforma central, ofrece una nueva taxonomía de comandos simplificada que refleja el flujo de trabajo de un desarrollador típico en lugar de las marcas, productos o funciones de Salesforce.
Un ejemplo práctico de esto es el comando sf org create . Con este nuevo comando, la intención es más clara: llamas a la misma base de comandos con scratch , sandbox , shape , snapshot o user , mientras que en sfdx tenías que usar una combinación de diferentes comandos ( force:org:create , force:user:create ) y flags ( --type=scratch o --type=sandbox ) para obtener el mismo resultado.
Otra característica interesante de sf es que incluye más comandos visuales e interactivos, como la creación de organizaciones con la capacidad de reanudar operaciones de larga duración en caso de tiempo de espera.
Migrar al ejecutable sf
Además de simplemente cambiar el nombre del ejecutable de sfdx a sf , hay una serie de cambios que se aplican a los comandos CLI al actualizar sus proyectos. La documentación de la CLI de Salesforce proporciona una buena descripción general de estos cambios, pero destacaremos los que nos afectaron durante la actualización de nuestras aplicaciones de muestra.
Comandos sfdx comunes y sus equivalentes sf
En primer lugar, el tema force se eliminó de la mayoría de los comandos, lo cual es una buena noticia, ya que acorta los comandos. El otro cambio importante es que los temas, comandos y subcomandos, que antes estaban separados por dos puntos como en sfdx force:org:list , ahora están separados por espacios, como en sf org list .
Mirando más de cerca los comandos que usamos a diario cuando trabajamos en aplicaciones de muestra, aplicamos los siguientes cambios:
Comando sfdx heredado
Comando sf equivalente
Migración Comentarios
sfdx force:org:delete -p -u recipes
sf org delete scratch -p -o recipes
Se debe agregar el subcomando scratch . El indicador de la organización de destino cambia de -u a -o .
sfdx force:org:create -s -f config/project-scratch-def.json -d 30 -a recipes
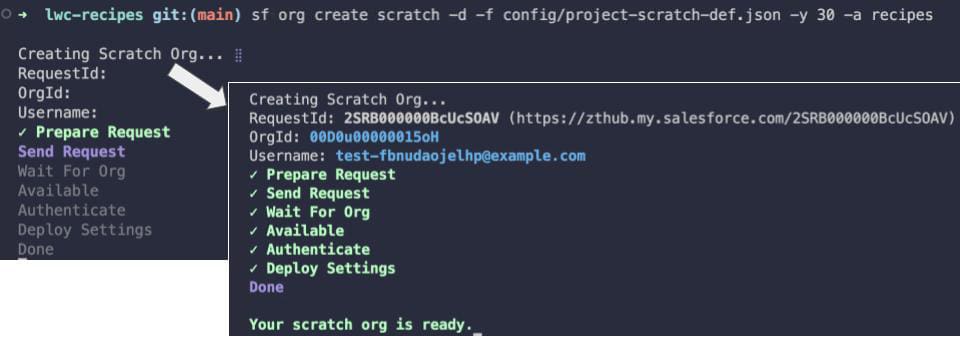
sf org create scratch -d -f config/project-scratch-def.json -y 30 -a recipes
Se debe agregar el subcomando scratch . El indicador "asignar organización predeterminada" cambia de -s a -d . El indicador de duración de la organización borrador cambia de -d a -y .
sfdx force:source:push
sf project deploy start
Este es un cambio significativo, pero el nuevo comando funciona para todos los formatos de proyecto (fuente o metadatos). Anteriormente, necesitaba comandos distintos.
sfdx force:user:permset:assign -n recipes
sf org assign permset -n recipes
El tema cambia de user a org y cambia el orden de los subcomandos.
Si está buscando otros comandos, la documentación de CLI proporciona una lista completa de comandos sfdx con sus equivalentes sf . Cada vez que reemplace un comando, asegúrese de revisar sus banderas en busca de cambios, especialmente si usa las banderas de formato corto (un solo carácter) ( -o en lugar de --target-org por ejemplo). Puede ejecutar cualquier comando con el indicador -h o --help para obtener su descripción.
Automatice parte de la migración con expresiones regulares
ℹ️ Edición del 27 de julio de 2023: en lugar de expresiones regulares, puede usar un script de migración como se documenta aquí .
Cuando analizamos la migración de nuestros proyectos de aplicaciones de muestra , sabíamos que necesitaríamos automatizar parte del proceso, ya que había cerca de 1700 referencias a sfdx en más de 200 archivos. Para obtener los resultados más precisos aquí, asegúrese de agregar un espacio después de sfdx en su término de búsqueda y excluya la carpeta node_modules de su búsqueda, como hicimos aquí:
Comenzar con una búsqueda es un buen primer paso. Le ayuda a darse cuenta de que tendrá que migrar sus comandos en un par de lugares, como:
Scripts de integración continua
Guiones de desarrollo local
Documentación
Luego puede ir más allá experimentando con una búsqueda y reemplazo de expresiones regulares (RegEx) en VS Code. Este enfoque es una forma rápida de iniciar la migración. Funciona bien para la búsqueda, pero no es perfecto como reemplazo, ya que algunos comandos requieren actualizaciones manuales. En cualquier caso, siempre pruebe el resultado de sus cambios antes de enviarlos a producción.
Comience ejecutando esta búsqueda RegEx y reemplace:
Tenga en cuenta el uso de tres grupos de captura encerrados entre paréntesis en la expresión de búsqueda y representados por signos de dólar seguidos de un número en la expresión de reemplazo. Los grupos de captura le permiten retener dinámicamente ciertos valores (palabras como temas, comandos y subcomandos en nuestro caso) mientras realiza cambios en el resto de la línea (reemplazando los separadores de dos puntos con espacios en nuestro caso).
Si desea obtener más información sobre este RegEx u otros, le recomiendo que consulte regex101.com , ya que proporciona una explicación de la sintaxis y un campo de juego para probar expresiones.
Aquí hay un ejemplo de la entrada y salida en VS Code de la expresión anterior (no olvide activar el modo RegEx como lo indica la flecha roja):
Notará que esta primera ronda de búsqueda y reemplazo no es perfecta ya que obtiene algunos caracteres de espacio adicionales en el texto reemplazado. Puede arreglar esto fácilmente ejecutando una segunda operación RegEx de búsqueda y reemplazo como esta:
Una vez que ejecute este último RegEx, todavía hay un par de cambios manuales que necesitará para operar. Como vimos anteriormente en la tabla de equivalencia de comandos, estas son las cosas clave a tener en cuenta:
Algunos comandos usan diferentes temas y subcomandos. Por ejemplo, sf user assign permset es incorrecto: user debe ser reemplazado por org .
Algunas banderas necesitan ser cambiadas. Por ejemplo, sf org create scratch -s -f config/project-scratch-def.json -d 30 -a recipes es incorrecto: el indicador -d debe reemplazarse por -y y el indicador -s debe reemplazarse por -d .
Afortunadamente, la mayoría de estos cambios no son demasiado difíciles de aplicar y puede migrar con bastante rapidez a los comandos de estilo sf . Lo dejaremos con una vista de diferencias de GitHub que resume todos los cambios que fueron necesarios para migrar una de nuestras aplicaciones de muestra.
palabras de cierre
Eso es un resumen de esta breve descripción general de la migración de los comandos sfdx -style a los comandos sf -style. Vislumbró el beneficio del ejecutable sf y su nueva sintaxis. Esperamos que se beneficie de nuestra experiencia de migración y de nuestros consejos al actualizar sus proyectos.
Recursos
Sobre el Autor
Philippe Ozil es un defensor principal de desarrolladores en Salesforce, donde se enfoca en la plataforma de Salesforce. Escribe contenido técnico y habla con frecuencia en conferencias. Es un desarrollador full-stack y disfruta trabajar en proyectos DevOps, robótica y VR. Sígalo en Twitter @PhilippeOzil o consulte sus proyectos de GitHub @pozil .
Obtenga las últimas publicaciones de blog de desarrolladores de Salesforce y episodios de podcast a través de Slack o RSS.