Desde el temor a las imprecisiones en los informes hasta la lucha constante contra los silos de datos y la sombra amenazadora de los incumplimientos, los retos de supervisar sus datos son abundantes. Y no hablemos ya de los quebraderos de cabeza financieros que provocan las malas prácticas de gestión de datos. Mantener un diccionario de datos no es solo marcar una casilla […]
The post 5 razones por las que necesita un diccionario de datos de Salesforce appeared first on Salesforce Ben.
Las razones por las que necesita un diccionario de datos de Salesforce appeared first on Salesforce Ben
Salesforce está organizando Dreamforce, el evento de IA más grande del año. El CEO, Mark Benioff, expresa gratitud a los asistentes y destaca la importancia de sus contribuciones al éxito de la empresa. El Evento Dreamforce El Evento Dreamforce es una de las conferencias más grandes y relevantes del mundo en el ámbito de la […]
Última actualización el 8 de septiembre de 2023 por Rakesh Gupta
Salesforce es la solución CRM basada en ventas, marketing y operaciones más sólida y completa disponible. Los límites de lo que puede hacer con los datos de sus clientes (una vez que están en Salesforce) están limitados únicamente por su imaginación y habilidad para navegar por el ecosistema.
Pero no hay dos organizaciones iguales. Cada uno tiene sus propias necesidades, desde simples hasta complejas, desde la captura de clientes potenciales hasta la coordinación de eventos. Y la forma en que ingresa sus datos en Salesforce (tipo de integración, creación de objetos, coincidencia de campos, llenado previo, etc.) puede marcar la diferencia en cuanto a si sus flujos de trabajo de CRM realmente automatizan su trabajo pesado y le ahorran tiempo valioso o lo atascan con tareas manuales.
Es un motivo de orgullo para nosotros que miles de organizaciones sin fines de lucro, proveedores de servicios, empresas de atención médica y más hayan confiado en Jotform para canalizar los datos de sus clientes a Salesforce a lo largo de los años.
Jotform ahora está disponible enAppExchange de Salesforcepara una experiencia de creación de formularios completamente nueva e intuitiva.
Beneficios de Jotform para Salesforce de un vistazo
Con Jotform en Salesforce AppExchange, sus flujos de trabajo experimentarán una verdadera automatización de extremo a extremo, lo que ayudará a su organización a lograr sus objetivos más rápido.
He aquí por qué le encantará Jotform para Salesforce:
Esta nueva solución de formulario, integrada automáticamente con sus objetos y campos de Salesforce, elimina el cambio de plataforma.
Con las automatizaciones líderes en la industria de Jotform directamente en su entorno Salesforce, puede crear flujos de trabajo más confiables y productivos.
La integración de datos automatizada entre sus formularios de cara al cliente y su base de datos de Salesforce garantiza precisión y ahorro de tiempo (lo que significa ahorro de dinero).
La aplicación de Jotform se alinea con los estándares de seguridad de Salesforce y juntos ofrecemos cumplimiento normativo y seguridad de datos de CRM y formularios líderes en la industria.
¡Puedes probar la aplicación Jotform para Salesforce gratis!
Si usted es una organización sin fines de lucro que digitaliza aplicaciones de quienes las necesitan, un B2B que recopila clientes potenciales y activos de video, un proveedor de atención médica que registra información de pedidos y facturas de consultorios médicos, o una empresa líder con más de 50,000 clientes, Jotform para Salesforce está diseñado para escale con sus necesidades.
¿Quién debería utilizar Jotform para Salesforce?
Insinuamos que industrias como las organizaciones sin fines de lucro y la atención médica son grandes usuarios de la integración heredada de Salesforce de Jotform. Pero realmente cualquier persona en cualquier industria que ya use Salesforce debería usar esta versión mejorada de la integración.
Además de sincronizar contactos y clientes potenciales estándar , a continuación se muestran algunos casos de uso de muestra.
Industria
Usos de Jotform y Salesforce
Sin ánimo de lucro
Las organizaciones sin fines de lucro pueden sincronizar donaciones, solicitudes, registros de programas y material adicional de eventos que recopilan a través de Jotform con Salesforce. También pueden utilizar las aplicaciones de donación de Jotform y las automatizaciones del flujo de trabajo de aprobación dentro de Salesforce.
Cuidado de la salud
Tanto los profesionales de la salud como los proveedores utilizan Jotform para crear facturas y formularios de citas compatibles con HIPAA. Pueden sincronizar datos de contactos relacionados con objetos personalizados en Salesforce.
Ventas
Un flujo de trabajo automatizado de Jotform y Salesforce para clientes potenciales es fundamental para cualquier equipo de ventas. Además, Ventas recibe propuestas de presupuestos así como formularios de pedido de nuevos clientes. Pueden volver a atraer a su base de clientes actual con formularios precargados.
Servicios financieros
Las empresas de servicios financieros utilizan ambas soluciones para calificar y gestionar la creación de préstamos y actualizar la información existente de los clientes, utilizando lógica condicional y formularios PDF inteligentes.
B2B/gestión de eventos
Las empresas orientadas a servicios asignan envíos de registro a objetos personalizados y registran comentarios de encuestas en Salesforce.
Consultores
Los usos aquí van desde la creación de formularios que pueden integrarse en un sitio web hasta soluciones de firma electrónica y el llenado previo de datos utilizando información de Salesforce.
Agencias y mesas comerciales
Estas empresas venden servicios, cobran pagos y solicitudes y luego mapean y rastrean a sus solicitantes en Salesforce.
Creando su primer formulario de Salesforce
No solo todas sus automatizaciones de Jotform están disponibles dentro de su instancia de Salesforce, sino que una gran característica nueva de Jotform para Salesforce es el tipo de formulario único de Salesforce dentro de la aplicación.
Desde la página de inicio de Mis formularios , haga clic en el botón Crear formulario como lo haría normalmente. Ahora verá la opción Crear formulario de Salesforce , que le permite crear un formulario que se integra automáticamente con sus objetos de Salesforce.
Esta nueva opción es perfecta para asignar de manera eficiente sus campos de Salesforce a sus formularios. Permite una sincronización de campos más sencilla desde sus formularios con clientes potenciales, contactos, cuentas u otros objetos/registros personalizados, dejando atrás conexiones de integración complejas.
Simplemente seleccione los objetos que se adapten a sus necesidades y agréguelos a su nuevo formulario. Los objetos son básicamente mini bases de datos. Cada base de datos contiene campos relevantes para el objeto.
En este formulario de ejemplo de Salesforce, seleccioné tres objetos: Cliente potencial , Evento y Adjunto . No hay límite para la cantidad de objetos que puede seleccionar para satisfacer sus necesidades de datos.
Una vez que haya seleccionado todos sus objetos (y haya verificado los campos dentro de ellos para obtener los datos que desea en su formulario), haga clic en Crear formulario . Su nuevo formulario mostrará todos los campos que ha seleccionado.
Por ejemplo, cuando alguien envía mi nuevo formulario de cliente potencial, sus detalles completarán automáticamente los objetos en mi base de datos de Salesforce.
¿Necesita actualizar o editar su formulario? Utilice el nuevo ícono de Salesforce dentro del creador de formularios para actualizar sus objetos. Puede cambiar o agregar campos dentro de sus objetos existentes o agregar otros nuevos.
Cuando haga clic en Siguiente , tendrá la opción de activar Actualizar registro para evitar duplicados en su base de datos.
También puede hacer clic en el botón Agregar acción para crear un nuevo registro, actualizar uno existente o buscar un registro existente.
[contenido incrustado]
La ventaja de Jotform, ahora en Salesforce
Si bien otras soluciones de AppExchange pueden ayudarlo a importar datos a Salesforce, creemos que la calidad y el alcance de nuestras automatizaciones de flujo de trabajo marcan la diferencia.
Por ejemplo, ahora es fácil completar previamente sus formularios de forma segura dentro de la interfaz de Salesforce.
Simplemente vaya a la pestaña Publicar , acceda a Precompletar desde el menú de la izquierda, elija Salesforce Precompletar y cargue la información de contacto y cliente potencial que necesita en sus formularios. Como ya está en Salesforce, no es necesaria ninguna autenticación de cuenta.
Se ha demostrado que rellenar previamente formularios ofrece mayores tasas de conversión de formularios y una mayor precisión de los clientes potenciales (además de actualizar sus contactos de Salesforce o los detalles de su empresa con nueva información).
Para profundizar más,obtenga más información sobre cómo completar previamente formularios con sus objetos de Salesforce.
Si está cobrando pagos, puede agregar una de las más de 40 integraciones de pagos a sus formularios de Salesforce. Personalice los campos en sus objetos para indicar si se ha cobrado una tarifa al enviar el formulario o registre el monto pagado en los campos de su objeto.
Cree un acuerdo de Jotform Sign dentro de Salesforce que se configure automáticamente para la aprobación de las partes interesadas internas. Recopilará documentos firmados que mantendrán el trabajo en movimiento y la productividad en sus niveles más altos.
Estas y otras automatizaciones basadas en formularios, como la generación de PDF, Jotform Approvals, Jotform Apps y Report Builder, junto con los nuevos formularios de Salesforce, continúan optimizando sus flujos de trabajo mientras se adaptan a sus necesidades únicas de Salesforce de maneras innovadoras.
¿Nuevo en Salesforce? Esta potente solución puede ayudar a su organización a gestionar los procesos y la participación de los clientes de muchas maneras, pero empezar puede resultar desalentador.
A continuación se ofrecen algunos consejos útiles que debe tener en cuenta si recién está comenzando:
Fijación de objetivos . Defina cómo se ve el éxito para sus necesidades y flujos de trabajo. Catalogue los datos que está importando y mapee cómo le gustaría administrarlos. Esto le brindará una visión integral de sus flujos de trabajo ideales para que pueda separar las necesidades de los deseos.
Considere un consultor . No todo el mundo tiene el presupuesto para una consultoría. Pero si lo hace, tener un asesora mano puede ahorrarle mucho tiempo. Además, pueden capacitar a sus partes interesadas para que el conocimiento pueda transmitirse en el futuro.
Entrena . Cada organización tiene expertos en la materia, así que ¿por qué no crear sus propios gurús de Salesforce? Haga que aquellos que quieran aprender nuevas habilidades comiencen con recursos gratuitos disponibles enTrailblazer Community , YouTube, TikTok y más.
Conclusión
Jotform para Salesforce mejora su experiencia ofreciendo
Captura de datos perfecta a través de formularios dentro de la interfaz de Salesforce. Esto facilita el mapeo de campos y la transferencia de datos a clientes potenciales, contactos y objetos personalizados.
Generación de leads mejorada . Simplemente inserte sus formularios de Salesforce en el sitio web de su empresa (o en las redes sociales). Su equipo de ventas puede realizar un seguimiento fácil de los flujos de datos en tiempo real.
Calidad de datos mejorada a través de un mapeo de campo preciso a través de la aplicación Jotform. Sus equipos ya no necesitarán ingresar datos manualmente.
Una experiencia de usuario integrada . Tener acceso a todas las funciones de Jotform dentro de Salesforce elimina la necesidad de cambiar de plataforma, lo que simplifica el proceso.
Si ya es cliente pago de Jotform con una integración de Salesforce, podrá instalar Jotform en AppExchange y comenzar a usarlo ahora (los consultores son una excepción).
Para aquellos con un plan Jotform Starter, pueden disfrutar de hasta cinco formularios y 100 envíos mensuales por nuestra cuenta; sin embargo, deberá actualizar a un plan pago si desea aumentar el uso, el espacio de almacenamiento o la cantidad de usuarios.
Si sus necesidades exceden lo disponible con el plan Starter, puede unirse a cualquiera de los siguientes planes para un solo usuario:
Bronce: $39/mes
Plata: $49/mes
Oro: $129/mes
Las organizaciones sin fines de lucro califican automáticamente para descuentos. Y para aquellos que requieren acceso a toda la empresa o un enfoque personalizado, Jotform ofrece soluciones empresariales;Hable con alguienhoy para obtener más información.
Pruebe Jotform para Salesforce hoy y díganos cómo se siente al respecto. Además, no dude encomentarnosen AppExchange.
Chris es creador y comercializador de contenidos en Jotform y cree en la escritura creativa como fuerza para el cambio positivo. Al poseer una experiencia profesional y un conjunto de habilidades diversas, Chris produce un liderazgo intelectual galardonado. El cine, los viajes, el diseño y la buena comida y vino con amigos se encuentran entre sus amores.
Evaluación formativa:
¡Quiero saber de ti!
¿Qué es lo que aprendiste de esta publicación? ¿Cómo imagina aplicar este nuevo conocimiento en el mundo real? Siéntete libre de compartir en los comentarios a continuación.
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
Creación de aplicaciones impulsadas por IA con LLM y Einstein | Blog de desarrolladores de Salesforce
La IA generativa es la tecnología más transformadora desde Internet y revoluciona la forma en que creamos e interactuamos con la información. Para los desarrolladores, esto plantea nuevas preguntas: desde la práctica "¿Cómo puedo crear aplicaciones impulsadas por IA con modelos de lenguaje grandes (LLM)?" Más profundamente, “¿Cómo cambiará la IA generativa la naturaleza de las aplicaciones? ” Exploramos estas dos preguntas en esta publicación de blog.
¿Cómo creo aplicaciones impulsadas por IA con LLM?
Comencemos con la primera pregunta: "¿Cómo creo aplicaciones con LLM?" y explore tres opciones que comúnmente se consideran:
Entrena tu propio modelo
Personaliza un modelo de código abierto
Utilice modelos existentes a través de API
Entrena tu propio modelo
Entrenar su propio modelo le brinda control total sobre los datos de los que aprende su modelo. Por ejemplo, puede entrenar un modelo con datos específicos de su industria. Un modelo entrenado con datos de un dominio específico generalmente será más preciso que un modelo de propósito general para casos de uso centrados en ese dominio. Si bien entrenar su propio modelo ofrece más control y precisión, puede que no siempre sea el mejor enfoque. Aquí hay algunas cosas para considerar:
Tiempo y recursos:formar su propio LLM desde cero puede llevar semanas o incluso meses. Como punto de referencia, aunque es probable que su modelo sea mucho más pequeño, el modelo GPT-3 de OpenAI tardó 1,5 millones de horas de GPU en entrenarse.
Experiencia:para entrenar su modelo, también necesitará un equipo de ingenieros especializados en aprendizaje automático (ML) y procesamiento del lenguaje natural (NLP).
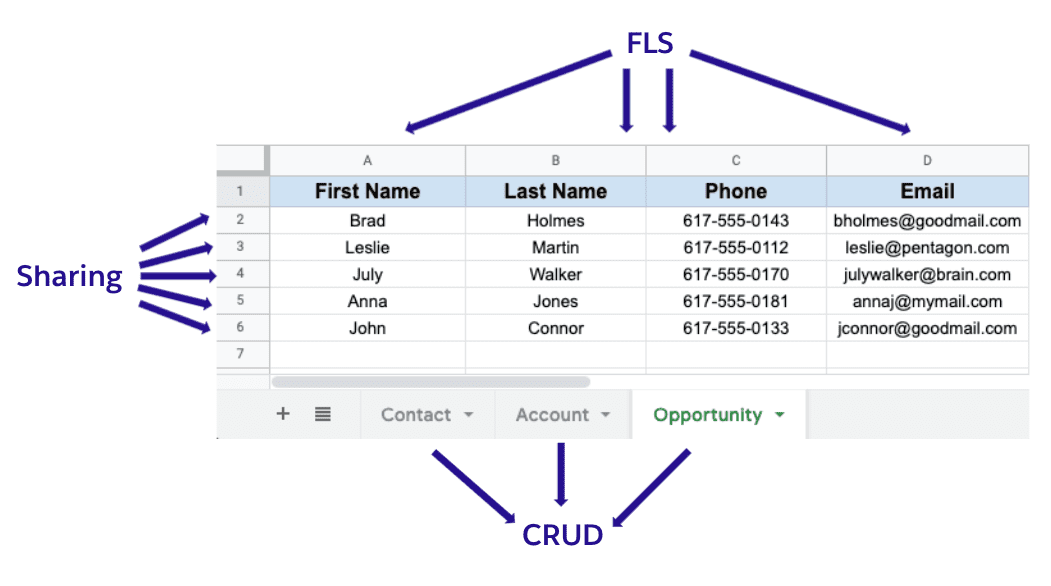
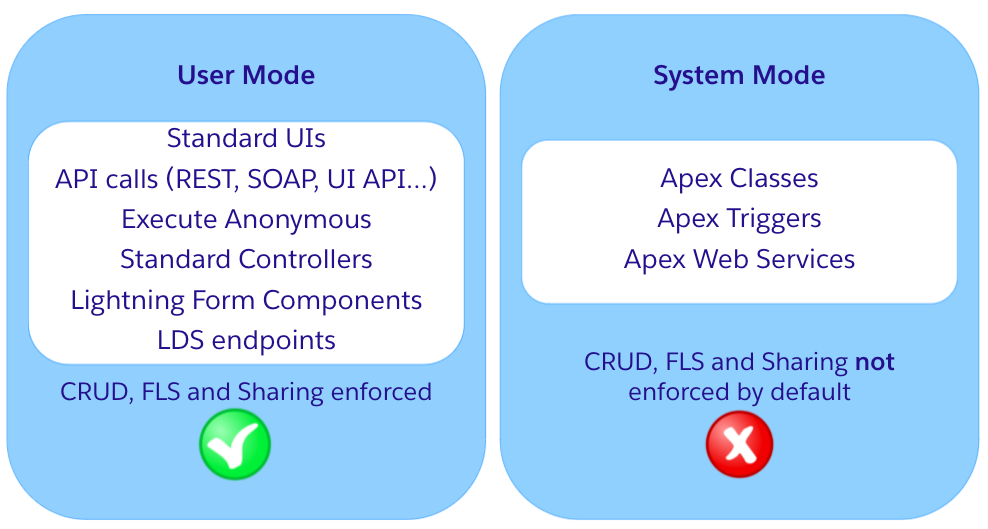
Seguridad de los datos: el poder de los LLM hace que sea tentador crear modelos que aprendan de todos sus datos, pero esto no siempre es lo correcto desde el punto de vista de la seguridad de los datos. Puede haber tensión entre la forma en que aprenden los LLM y la forma en que se implementan las políticas de seguridad de datos en su empresa. Los LLM aprenden de grandes cantidades de datos. ¡Cuantos más datos mejor! Sin embargo, con seguridad a nivel de campo (FLS) y permisos estrictos, las políticas de seguridad de datos corporativas a menudo se basan en el principio de privilegio mínimo: los usuarios solo deben tener acceso a los datos que necesitan para realizar su trabajo específico. ¡Cuantos menos datos mejor! Por lo tanto, un modelo formado con todos los datos disponibles de los clientes y puesto a disposición de todos en su empresa puede no ser una buena idea y violar las políticas de seguridad de datos de su empresa. Sin embargo, un modelo entrenado en especificaciones de productos y resoluciones de tickets de soporte anteriores puede ayudar a los agentes a resolver tickets nuevos sin comprometer la seguridad de los datos.
Personaliza un modelo de código abierto
Personalizar un modelo de código abierto normalmente lleva menos tiempo y es menos costoso que entrenar su propio modelo desde cero. Sin embargo, aún necesita un equipo de ingenieros especializados en aprendizaje automático (ML) y procesamiento del lenguaje natural (NLP). Dependiendo del caso de uso, es posible que aún experimentes la tensión de seguridad de los datos descrita anteriormente.
Utilice modelos existentes a través de API
Utilizar modelos existentes a través de API es la forma más sencilla de crear aplicaciones con LLM. Esta es también la opción más utilizada en este momento. Sin embargo, estos modelos no se han entrenado con los datos contextuales o privados de su empresa y, por lo tanto, el resultado que producen puede ser demasiado genérico para ser útil.
En esta publicación de blog, exploramos diferentes técnicas para agregar datos contextuales o privados de la empresa a través del mensaje. Debido a que el mensaje se crea dinámicamente en nombre del usuario, solo incluye datos a los que el usuario tiene acceso, lo que aborda la tensión de seguridad de los datos descrita anteriormente. Es posible que le preocupe pasar datos privados a una API de terceros, pero existen técnicas para abordar esa preocupación y también las describimos en esta publicación de blog.
Creación de aplicaciones impulsadas por IA utilizando modelos existentes a través de API
Llamada API básica
Los principales proveedores de modelos como OpenAPI , Anthropic , Google , Hugging Face y Cohere ofrecen API para trabajar con sus modelos. En la implementación más básica, su aplicación captura un mensaje del usuario, lo pasa como parte de la llamada API y muestra el resultado generado al usuario.
Por ejemplo, así es como se vería la llamada API usando la API OpenAI:
Esta opción puede funcionar para casos de uso simples que solo requieren un resultado general basado en conocimientos generales. Por ejemplo, " Escribe un haiku sobre el invierno" o "Escribe una declaración SQL de muestra con una unión externa". Pero si necesita una respuesta que se adapte a su propio contexto o a los datos privados de su empresa, es probable que el resultado generado sea demasiado genérico para ser útil.
Por ejemplo, digamos que un usuario ingresa el siguiente mensaje:
Escriba un correo electrónico de presentación para el director ejecutivo de Acme.
El correo electrónico generado no sería personalizado ni relevante porque el modelo no sabe nada sobre su relación con Acme y los negocios que ha hecho con ellos.
Puesta a tierra del LLM
Para que la respuesta sea más relevante y contextual, el usuario puede fundamentar el LLM con información adicional. Por ejemplo, pueden ingresar el siguiente mensaje:
Usted es John Smith, representante de cuentas de Northern Trail Outfitters. Escriba un correo electrónico de presentación a Lisa Martinez, directora ejecutiva de ACME. Aquí hay una lista de los últimos tres pedidos que Acme realizó a Northern Trail Outfitters: Colección Verano 2023: $375,286 Colección Primavera 2023: $402,255 Colección Invierno 2022: $357,542
Esto permite que el LLM genere un resultado mucho más relevante. Sin embargo, este enfoque plantea dos problemas:
El usuario debe ingresar mucha información de conexión a tierra manualmente. Por lo tanto, la calidad del resultado depende en gran medida de la calidad de la pregunta ingresada por el usuario.
Está pasando información confidencial al proveedor del modelo donde potencialmente podría persistir o usarse para entrenar aún más el modelo, lo que significa que sus datos privados podrían aparecer en la respuesta generada por el modelo de otra persona.
Construcción rápida y puesta a tierra dinámica.
Para abordar la primera limitación anterior, puede construir el mensaje mediante programación. El usuario ingresa una cantidad mínima de información o simplemente hace clic en un botón en la aplicación y luego usted crea el mensaje mediante programación agregando datos relevantes. Por ejemplo, en respuesta a un clic en el botón “Escribir correo electrónico de introducción”, podría:
Llame a un servicio para obtener información sobre el usuario.
Llame a un servicio para obtener información sobre el contacto.
Llame a un servicio para obtener la lista de oportunidades recientes.
Construya el mensaje utilizando la información obtenida de los servicios de datos anteriores.
Así es como podrían verse estos pasos de construcción rápidos en Apex:
El principal inconveniente de este enfoque es que requiere un código personalizado para cada mensaje para poder realizar la sencilla tarea de fusionar datos dinámicos en texto estático.
Plantillas de aviso
Para facilitar la construcción del mensaje, podemos usar plantillas: un patrón de desarrollo de software bien conocido que se usa comúnmente para fusionar datos dinámicos en documentos estáticos. Con una plantilla, escribe un archivo de solicitud utilizando marcadores de posición que se reemplazan dinámicamente con datos dinámicos en tiempo de ejecución.
Así es como se vería el ejemplo de Apex anterior usando un lenguaje de plantilla genérico:
Eres {{user.Name}}, {{user.Title}} en {{ user.CompanyName }} Escriba un correo electrónico de presentación a {{contact.Name}}, {{contact.Title}} en {{contact.Account.Name}} Estas son las oportunidades de {{contact.Account.Name}}: {{#oportunidades}} {{Nombre}}: {{Cantidad}} {{/oportunidades}}
Las plantillas de mensajes no solo son útiles para crear mensajes mediante programación, sino que también se pueden utilizar como base para herramientas gráficas que admiten la creación de mensajes en un entorno de arrastrar y soltar.
Estudio rápido
Por eso creamos Prompt Studio, un nuevo creador de Salesforce que facilita la creación de indicaciones. Le permite crear plantillas de mensajes en un entorno gráfico y vincular campos de marcador de posición a datos dinámicos disponibles a través de datos de páginas de registro, un flujo, una nube de datos, una llamada de Apex o una llamada API. Una vez creada, se puede utilizar una plantilla de solicitud en diferentes lugares para consultar el modelo, incluidas las páginas de registro y el código Apex.
Capa de confianza de Einstein
Prompt Builder le permite definir mensajes basados dinámicamente en un entorno gráfico. Pero, ¿cómo se envía ese mensaje de forma segura a un proveedor de LLM?
Puede enviar el mensaje directamente a la API del proveedor de LLM, pero hay una serie de preguntas a considerar con ese enfoque:
¿Qué pasa con los problemas de cumplimiento y privacidad si pasa datos de información de identificación personal (PII) en el mensaje? ¿El proveedor del modelo podría conservar los datos de PII o incluso utilizarlos para entrenar aún más el modelo?
¿Cómo se evitan las alucinaciones, la toxicidad y los sesgos en los resultados generados por los LLM?
¿Cómo se rastrea y registra los pasos de creación de mensajes con fines de auditoría?
Si utiliza la API del proveedor de LLM directamente, tendrá que escribir un código personalizado para responder a estas preguntas. Hay muchas cosas a considerar y puede resultar difícil hacerlo bien para todos los casos de uso.
Ingrese a la capa de confianza de Einstein. Einstein Trust Layer le permite enviar solicitudes a LLM de forma confiable, abordando las inquietudes mencionadas anteriormente.
Así es como funciona:
En lugar de realizar llamadas API directas, utiliza LLM Gateway para acceder al modelo. LLM Gateway admite diferentes proveedores de modelos y abstrae las diferencias entre ellos. Incluso puedes conectar tu propio modelo.
Antes de enviar la solicitud al proveedor del modelo, pasa por una serie de pasos que incluyen el enmascaramiento de datos que reemplaza los datos PII con datos falsos para garantizar la privacidad y el cumplimiento de los datos.
Para proteger aún más sus datos, Salesforce tiene acuerdos de retención cero con proveedores de modelos, lo que significa que los proveedores de modelos no persistirán ni entrenarán más sus modelos con datos enviados desde Salesforce.
Cuando se recibe el resultado del modelo, pasa por otra serie de pasos, incluido el desenmascaramiento, la detección de toxicidad y el registro de seguimiento de auditoría. Demasking restaura los datos reales que fueron reemplazados por datos falsos por motivos de privacidad. La detección de toxicidad comprueba si hay contenido dañino u ofensivo en el resultado. El registro de seguimiento de auditoría registra todo el proceso con fines de auditoría.
De cara al futuro: creación de aplicaciones de una forma totalmente nueva
Ahora echemos un vistazo a lo que viene y abordemos la segunda pregunta planteada al principio de este artículo: ¿Cómo cambiará la IA generativa la naturaleza de las aplicaciones?
Encadenamiento rápido
La lógica involucrada en la creación de un mensaje a veces puede volverse compleja. Puede implicar múltiples llamadas a API o servicios de datos, como en el ejemplo de conexión a tierra dinámica anterior. Responder a la pregunta de un solo usuario puede incluso implicar varias llamadas al LLM. Esto se llama encadenamiento rápido. Considere el siguiente ejemplo:
Para construir el mensaje:
Realizamos una primera llamada API o servicio de datos para obtener datos contextuales de la empresa
Los datos que regresan de la primera llamada al servicio de datos se usan para crear un primer mensaje que usamos para consultar el LLM.
La salida del LLM se utiliza como entrada para una segunda llamada de servicio de datos.
Los datos que regresan de la segunda llamada al servicio de datos se utilizan para crear un segundo mensaje cuya respuesta se envía al usuario.
Las posibilidades de combinar llamadas de servicios de datos y llamadas de LLM para generar un resultado son infinitas.
Orquestación de IA
El enfoque descrito hasta ahora funciona bien, pero a medida que estos flujos de trabajo se vuelven más complejos, podemos ver la necesidad de alguna forma de orquestación. Como desarrollador, luego crearía una serie de bloques de construcción que realizan tareas granulares: recuperar datos sobre un cliente, actualizar un registro, realizar alguna lógica computacional, etc. Estos bloques de construcción se pueden orquestar o remezclar de diferentes maneras usando un herramienta de orquestación. Esto se podría hacer usando una herramienta de orquestación tradicional que le permita definir qué bloques de construcción usar, en qué orden y cuándo (con diferentes ramas "si"). Pero, ¿qué pasaría si la orquestación en sí estuviera impulsada por IA con un orquestador que pudiera razonar y elegir qué bloques de construcción usar y cómo componerlos para realizar una tarea específica? La orquestación impulsada por IA es un nuevo paradigma poderoso que tiene el potencial de revolucionar la forma en que interactuamos con los sistemas de IA y creamos aplicaciones.
El siguiente diagrama describe este nuevo paradigma de bloques de construcción orquestado por IA a un alto nivel.
En este diagrama, las acciones son los componentes básicos descritos anteriormente. Podrían ser acciones invocables de Apex, API de MuleSoft o indicaciones. Algunas acciones fundamentales están disponibles de forma predeterminada y otras serán desarrolladas por los desarrolladores. Esto también crea una oportunidad para un mercado de acciones creado por desarrolladores y socios.
El planificador es el orquestador impulsado por IA. Cuando la solicitud se pasa al tiempo de ejecución de la orquestación, el planificador elige (crea un plan para) qué acciones usar y cómo componerlas para responder mejor a la solicitud del usuario.
La orquestación de IA es un área activa de investigación en Salesforce y en la industria en su conjunto.
Resumen
El uso de modelos existentes a través de API es una forma común de crear aplicaciones impulsadas por IA con LLM. Con este enfoque, es necesario basar el modelo en datos privados o contextuales de la empresa para obtener resultados más relevantes y útiles. En lugar de pedirle al usuario que ingrese una gran cantidad de información básica manualmente, puede crear el mensaje mediante programación llamando a servicios de datos y agregando datos contextuales al mensaje. Prompt Studio es un nuevo creador de Salesforce que facilita la creación de mensajes al permitirle crear plantillas de mensajes en un entorno gráfico y vincular campos de marcador de posición a datos dinámicos. Einstein Trust Layer le permite enviar mensajes a las API de los proveedores de LLM de forma confiable, abordando problemas de privacidad, sesgos y toxicidad de los datos. La orquestación impulsada por la IA es un paradigma emergente que podría cambiar la forma en que interactuamos con los sistemas de IA y creamos aplicaciones.
Sobre el Autor
Christophe Coenraets es vicepresidente senior de Trailblazer Enablement en Salesforce. Es un desarrollador de corazón con más de 25 años de experiencia en la creación de aplicaciones empresariales, habilitando audiencias técnicas y asesorando a organizaciones de TI.
Obtenga las últimas publicaciones de blog y episodios de podcasts para desarrolladores de Salesforce a través de Slack o RSS.
Última actualización el 18 de agosto de 2023 por Rakesh Gupta
La seguridad de los datos debe ser una de sus principales prioridades si recopila, almacena y administra información personal. La protección de datos es especialmente importante si sus flujos de trabajo de recopilación de datos de Salesforce se integran con varias herramientas, como un generador de formularios web o un sistema de pago.
Muchas regiones e industrias tienen leyes estrictas de privacidad de datos, que incluyen GDPR, GLBA, HIPAA y otras, que rigen la forma en que las organizaciones manejan los datos. Puede garantizarla seguridad y el cumplimiento de los datosa lo largo de sus flujos de trabajo de recopilación de datos de Salesforce de varias maneras, incluido el enmascaramiento y el cifrado de datos, el control y los permisos de acceso, y el monitoreo regular.
Comprender la importancia de mantener los datos seguros
Los datos confidenciales son todos los datos que se pueden usar para identificar a una persona o dañarlos si se pierden o son robados. Los tipos de datos confidenciales incluyen:
Información de identificación personal
información de salud protegida
Registros financieros o educativos
Datos étnicos, políticos y biométricos
Mantener la seguridad de los datos personalesayuda a generar confianza con las personas que comparten su información personal con usted. También garantiza que su organización evite sanciones por incumplimiento de las leyes de privacidad de datos.
Prácticas recomendadas de seguridad al recopilar datos
Su organización es responsable de asegurarse de que las herramientas de recopilación de datos que utiliza tenganimplementadas las medidas de seguridad adecuadas. Podrá proteger mejor los datos confidenciales desde el momento en que se recopilan, a medida que se mueven a través de sus flujos de trabajo y cuando se trasladan a Salesforce.
Enmascarar campos sensibles
El enmascaramiento de campo ayuda a garantizar que los datos confidenciales se mantengan confidenciales y no se expongan innecesariamente a usuarios no autorizados.
Cifrar datos
El cifrado de datos ayuda a proteger los datos confidenciales contra el acceso, uso o robo no autorizados, ya sea que estos datos estén en reposo o en tránsito.
Limite el acceso a los datos
La implementación de control de acceso y permisos garantiza que solo los usuarios autorizados puedan acceder o modificar los datos.
Supervisar y auditar flujos de trabajo
La vigilancia constante ayuda a garantizar que los flujos de trabajo de recopilación de datos mantengan el nivel adecuado de seguridad para mantener seguros los datos confidenciales.
2 formas de mejorar la seguridad en los flujos de trabajo de recopilación de datos de Salesforce
Un flujo de trabajo de recopilación de datos de varios pasos tendrá diferentes puntos de entrada con posibles riesgos de seguridad, como formularios, correos electrónicos y cargas de archivos. Es importante que en cada paso de sus procesos de datos, tenga medidas de seguridad para garantizar que personas no autorizadas no accedan a datos o archivos.
Asegúrese también de probar continuamente sus flujos de trabajo de recopilación de datos de Salesforce en busca de vulnerabilidades de seguridad. La detección temprana de amenazas disminuirá la posibilidad de una violación de datos u otras consecuencias graves.
Implementar reglas de retención de datos
La creación de una política clara de retención de datos es fundamental para definir cómo su organización maneja los datos con fines de cumplimiento. Es importante establecer reglas sobre qué datos deben conservarse y durante cuánto tiempo, así como reglas sobre quién tiene acceso y cómo deshacerse de los datos correctamente una vez que ya no se necesitan.
Acceso a los datos
Establecer reglas de acceso a datos como parte de su política de retención de datos garantizará que solo los usuarios autorizados en un flujo de trabajo tengan acceso a datos confidenciales. Los controles administrativos también pueden incluir el requisito de que los usuarios inicien sesión para ver o modificar las listas de respuestas del flujo de trabajo.
Purga de datos
Dentro de su flujo de trabajo, la configuración dereglas de depuración de datospuede garantizar que los datos de respuesta se eliminen de forma permanente una vez que ya no los utilice. Personalice esta configuración de depuración de datos, como la frecuencia con la que se completa una depuración, según sus requisitos de retención de datos.
Aproveche las aprobaciones del flujo de trabajo
Establecer pasos de aprobación dentro de los flujos de trabajo es importante para garantizar la responsabilidad durante el proceso de recopilación de datos. Los pasos de aprobación dentro de un flujo de trabajo significan que ningún usuario tiene control total sobre los cambios o decisiones de datos, lo que ayuda a mejorar la seguridad y la confidencialidad.
Detección de errores
Los pasos de aprobación en un flujo de trabajo proporcionan un proceso de revisión de datos estándar antes de que los datos se acepten o utilicen oficialmente. Esto ayuda a reducir las incoherencias y los errores, así como a garantizar el cumplimiento de las normas de privacidad de datos pertinentes.
Pista de auditoría
Los registros de auditoría para las aprobaciones de flujos de trabajo simplifican el proceso al registrar cada paso de aprobación y crear un registro histórico de los cambios realizados en los datos. También se pueden utilizar durante las investigaciones en caso de brechas de seguridad o problemas de datos.
Simplificación de los flujos de trabajo de recopilación de datos de Salesforce con FormAssembly
Cuando se trata de proteger los flujos de trabajo de datos, es fundamental contar con políticas de privacidad y seguridad de datos. Su organización puede beneficiarse del uso de una única plataforma de flujo de trabajo y recopilación de datos como FormAssembly, que facilita la centralización de la protección contra amenazas y garantiza el cumplimiento. Este enfoque le permite escalar más fácilmente, auditar los flujos de datos de forma centralizada y aumentar la eficiencia, al mismo tiempo que maximiza la seguridad en todos sus flujos de trabajo de recopilación de datos de Salesforce.
La potente plataforma conectada a Salesforce de FormAssembly combina la recopilación de datos segura y compatible con un generador de procesos visual e inteligente que le permite crear procesos complejos que incluyen formularios, correos electrónicos, integraciones y más, todo sin código.
Descubra cómo FormAssembly puede ayudarlo a optimizar sus flujos de trabajo de recopilación de datos de Salesforce mientras mantiene seguros los datos confidenciales.
¿Qué es una cosa que aprendiste de esta publicación? ¿Cómo imagina aplicar este nuevo conocimiento en el mundo real? Siéntase libre de compartir en los comentarios a continuación.
Esta es una traducción que desde EGA Futura ofrecemos como cortesía a toda la Ohana y comunidad de programadores , consultores , administradores y arquitectos de Salesforce para toda Iberoamérica .
El enlace a la publicación original, lo encontrarás al final de este artículo.
…
5 pasos para la IA generativa confiable para desarrolladores de Salesforce | Blog de desarrolladores de Salesforce
La IA generativa se ha convertido en el factor de cambio para las empresas innovadoras y orientadas al cliente. Impulsada por algoritmos avanzados y aprendizaje automático, la IA generativa puede impulsar la innovación, optimizar los procesos y acelerar las empresas en todas partes al proporcionar experiencias y soluciones personalizadas adaptadas a las necesidades únicas de los clientes.
Igualmente importante para las experiencias poderosas dirigidas por el cliente es la protección de los datos críticos para el negocio. Los sistemas de IA procesan y generan contenido basado en grandes conjuntos de datos y, lamentablemente, los modelos de lenguaje extenso (LLM) no están poniendo su negocio en primer lugar. Mientras se prepara para implementar capacidades de IA generativa, es fundamental priorizar la privacidad de los datos. Al implementar medidas sólidas de protección de datos, no solo mantiene el cumplimiento de las regulaciones pertinentes, sino que también mantiene la confianza del cliente, su activo más valioso.
Con los cinco pasos que se describen a continuación, puede innovar rápidamente, aumentar la productividad y mejorar las experiencias personalizadas, al mismo tiempo que garantiza la seguridad y la privacidad de los datos de sus clientes.
Paso 1: comprender y auditar sus datos
Para asegurarse de tener las protecciones de seguridad, privacidad y gobernanza correctas, querrá comprender qué datos usará para crear avisos, plantillas y modelos de capacitación. Comprender los datos a los que permite que accedan los modelos de IA ayudará a evitar que se compartan inadvertidamente los datos personales o confidenciales de los clientes.
Entonces, ¿cómo empezar? Primero, anonimice y agregue los datos de los clientes antes de usarlos con fines de IA generativa. Elimine la información de identificación personal (PII) y cualquier otro dato confidencial que pueda identificar a las personas.
Una manera fácil de hacer esto en Salesforce es usar Data Detect , un producto que le permite revisar objetos y campos antes de permitir que los procesos de IA accedan a ellos para recibir indicaciones y capacitación. Una vez que los datos se han escaneado a través de Data Detect, puede confirmar que no hay sorpresas en esos datos, como números de tarjetas de crédito o direcciones de correo electrónico en campos donde ese tipo de datos no debería existir.
Data Detect también puede ayudar a recomendar un nivel de clasificación, como "Confidencial" o "PII" para datos personales, y proporcionar detalles sobre el contenido de un objeto, así como encontrar datos confidenciales generados por chatbots, casos y transcripciones de llamadas registradas automáticamente. por IA.
Paso 2: configure la protección de la privacidad de los datos para sus procesos generativos de IA
Respetar la privacidad del cliente y proteger los datos a lo largo de sus procesos de IA es crucial para establecer y mantener la confianza. A medida que confía más en la IA para comprender y tomar decisiones a partir de sus datos, ¿cómo protege también esos datos, especialmente la PII?
Para los procesos de IA que usan datos personales, como aumentar los registros de contacto u orquestar ofertas de marketing dinámicas 1:1, querrá desarrollar políticas de uso de datos claras y transparentes que describan cómo se manejarán los datos de los clientes, incluido su uso en sistemas de IA generativos. . Comunique estas políticas a sus clientes y bríndeles la oportunidad de optar por no participar o elegir el nivel adecuado de uso de datos. Además, cree una política para eliminar y ofuscar los datos que ya no son útiles o relevantes, para que sus clientes permanezcan protegidos y sus procesos de IA generativa permanezcan precisos.
Centro de privacidadpuede ayudar a verificar que sus procesos de IA estén autorizados para su uso en capacitación y avisos. El Centro de privacidad también puede ayudarlo a crear políticas de retención para administrar el ciclo de vida de los datos utilizados y generados por la IA, incluidas las transcripciones de llamadas, los chatbots y los casos registrados automáticamente por la IA.
Paso 3: configure su organización para administrar la IA generativa
Tanto para proteger los datos utilizados en los procesos de IA como para confirmar que sus integraciones se mantienen dentro de los límites de los datos que desea utilizar, deberá implementar controles para proteger los datos de los clientes frente a accesos no autorizados o infracciones.
Los controles de acceso le permiten restringir el acceso a los datos del cliente solo al personal autorizado. Al otorgar acceso según sea necesario, reduce el riesgo de que los modelos de IA y las personas no autorizadas accedan a datos confidenciales. Esto protege contra el posible uso indebido de esos datos al tiempo que garantiza la privacidad del cliente.
Security Center puede ayudarlo a administrar de manera centralizada los permisos de usuario y las configuraciones de la organización para los datos que se usan y se obtienen de los procesos de IA.
Ahora preparémonos para implementar la IA de manera segura en toda su organización.
Paso 4: pruebe sus procesos para la implementación
Las pruebas en un entorno de espacio aislado son primordiales cuando se trata de IA generativa. Esto tiene dos propósitos fundamentales: probar los procesos de IA y capacitar a los empleados sobre el uso seguro y responsable de la IA generativa. Al realizar pruebas exhaustivas en un entorno de espacio aislado controlado, las organizaciones pueden evaluar y refinar el rendimiento y el comportamiento de sus modelos generativos de IA antes de implementarlos en escenarios del mundo real. Las pruebas permiten la identificación y mitigación de posibles problemas, como sesgos, errores o consecuencias no deseadas que pueden surgir durante un proceso de IA generativa.
Además, un entorno de sandbox proporciona un espacio seguro para que los empleados adquieran experiencia práctica y capacitación en el uso de herramientas y sistemas de IA generativa. Les permite explorar capacidades e identificar consideraciones éticas mientras toman decisiones informadas al usar la tecnología de manera responsable en sus operaciones diarias. Al aprovechar las pruebas de sandbox, las organizaciones pueden garantizar la confiabilidad, la eficacia y la aplicación ética de la IA generativa al tiempo que capacitan a su fuerza laboral para adoptar y utilizar esta tecnología transformadora con confianza.
Asegúrese de que, cuando utilice un espacio aislado para el entrenamiento de IA, haya eliminado todos los datos personales para crear sus indicaciones o entrenar un modelo de IA; puede eliminar u ofuscar fácilmente cualquier dato que no deba incluirse con Data Mask .
Paso 5: Supervise y proteja sus procesos de IA
Garantizar que la integración de IA no acceda a los datos ni modifique los sistemas más allá del alcance previsto es crucial para mantener la seguridad de los datos y la integridad del sistema. Como describimos anteriormente, los controles de acceso y los permisos de los usuarios deben definirse cuidadosamente, otorgando a los sistemas de IA solo los privilegios necesarios y limitando su acceso a fuentes o sistemas de datos específicos. Además, se deben realizar pruebas y validaciones exhaustivas de la integración de la IA para verificar que funcione según lo previsto y que no tenga consecuencias ni vulnerabilidades no deseadas.
Finalmente, implementar mecanismos de monitoreo robustos puede ayudar a detectar y alertar cualquier intento de acceso no autorizado o comportamiento anormal por parte del sistema de IA. Las auditorías y revisiones periódicas de los procesos de integración de IA y los registros de acceso pueden ayudar a identificar cualquier desviación o posibles riesgos de seguridad.
Event Monitoring ayuda a que el proceso de monitoreo y detección sea más fácil al permitir la configuración de capacidades, como la seguridad de transacciones, para enviar alertas o bloquear acciones más allá de lo que se pretendía inicialmente para su proceso de IA.
Finalmente, a medida que se adentra más en su viaje de IA, es fundamental que sus datos estén respaldados y puedan restaurarse hasta el nivel de registro en el caso poco probable de que los datos utilizados y aumentados por IA estén mal configurados o sincronizados incorrectamente. Haga una copia de seguridad de sus datos para ver cada versión de los registros utilizados y tocados por AI, y restaure cualquier error.
Conclusión
Al adoptar un enfoque que prioriza la privacidad e implementar medidas sólidas de protección de datos, puede crear una base confiable para prácticas de IA generativas responsables, sostenibles y éticas, todo mientras impulsa una innovación más eficiente y efectiva e interacciones más personalizadas con los clientes. Para obtener más información sobre cómo comenzar con la IA generativa, consulte nuestra Guía de introducción a la IA.
Recursos
Sobre el Autor
Marla Hay Vicepresidenta de Seguridad, Privacidad y Gestión de Datos en Salesforce y dirige la organización de productos de Servicios de confianza. Se unió a Salesforce en 2017 después de liderar productos en una empresa de gestión de identidad de consumidores. Marla tiene una licenciatura en Ciencias de la Computación de la Universidad de Cornell y una maestría en Ciencias de la Computación de la Universidad Johns Hopkins.
Obtenga las últimas publicaciones de blog de desarrolladores de Salesforce y episodios de podcast a través de Slack o RSS.
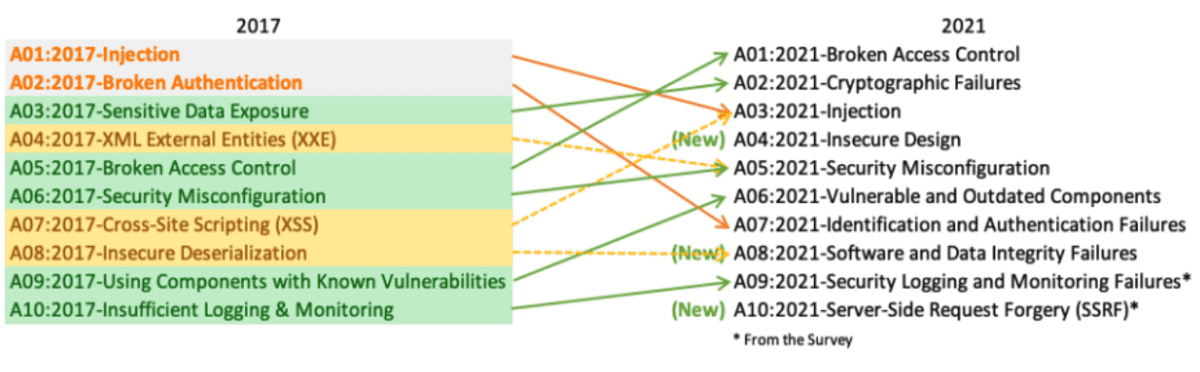
Las fallas criptográficas es la segunda categoría más importante de vulnerabilidades enumeradas en el Top 10 de OWASP para 2021. En esta publicación de blog, cubriremos técnicas para cifrar y codificar datos en Apex cuando esos datos deben transmitirse hacia o desde un sistema externo. Compartiremos ejemplos de código y explicaremos cuándo elegir […]
En Salesforce, la confianza es nuestro valor número uno. Cuando cree aplicaciones en la plataforma Salesforce, tenga la seguridad de que residen en un entorno seguro. Implementamos las mejores prácticas y estándares de seguridad de la industria en todas las capas, desde la infraestructura hasta el código de la aplicación. Brindamos múltiples opciones de configuración que le permiten implementar una seguridad de datos efectiva […]