Preguntas de la entrevista de Salesforce CPQ, parte 1
Enlace de Whatsapp para el grupo Salesforce CPQ
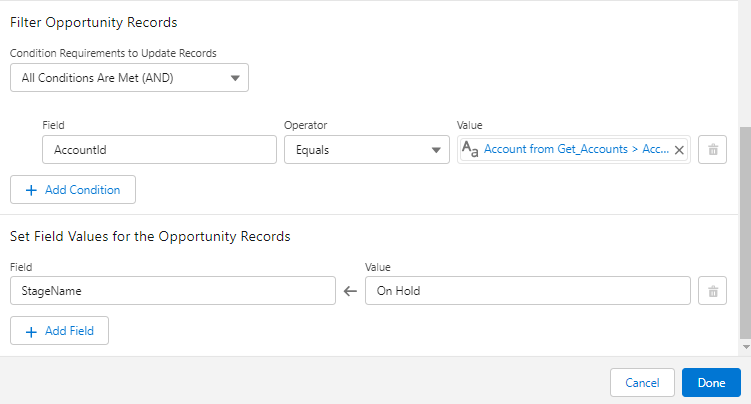
1. ¿Qué son los filtros de búsqueda en el editor de líneas de cotización?
El filtro de búsqueda del editor de líneas de cotización se puede utilizar para filtrar productos, activos o suscripciones por sus valores de campo.
2. ¿Cuál es la diferencia entre la regla del producto y la regla del precio?
La estructura general de las reglas de precios y de productos es la misma:
- Registro de reglas: que contiene propiedades generales.
- Condiciones: ambas admiten lógica de condición avanzada
- Comportamiento
Reglas del producto
Las reglas de productos se utilizan para hacer cumplir la lógica empresarial, ayudar a automatizar los comentarios a los representantes de ventas sobre las selecciones de productos y también aceleran el proceso de cotización.
Hay 4 tipos de reglas de producto:
Reglas de validación: cuando no se cumplen las condiciones, se muestra un mensaje de error y los usuarios no pueden continuar hasta que se solucione la situación. Por tanto, actúan como un freno duro .
Las reglas de alerta son una parada suave en comparación con la parada fuerte de las reglas de validación. También muestran un mensaje, pero es más bien una sugerencia porque el usuario puede continuar sin cumplir con los requisitos comerciales especificados.
Reglas de selección : pueden agregar, eliminar, mostrar, ocultar, habilitar o deshabilitar o realizar alguna combinación de estas acciones en las opciones de productos dentro de un paquete o pueden agregar un producto a una cotización. Esta regla puede ser una excelente manera de aprovechar la Venta Guiada para guiar a sus representantes hacia las opciones apropiadas o más deseadas seleccionando automáticamente los productos correctos.
Las reglas de filtrado se utilizan en paquetes para extraer opciones de productos del catálogo de productos mediante una regla de filtrado . A esto se le suele denominar creación de un paquete dinámico.
Reglas de precios
Se puede considerar que las reglas de precios realizan actualizaciones de campos dentro del cálculo que afectarán el precio. puede usarlos para establecer descuentos y cantidades.
3. ¿Cuáles son las consideraciones para los campos gemelos?
Recuerde que un campo gemelo debe tener el mismo tipo de datos y nombre de API que el campo correspondiente creado en el objeto Opción de producto.
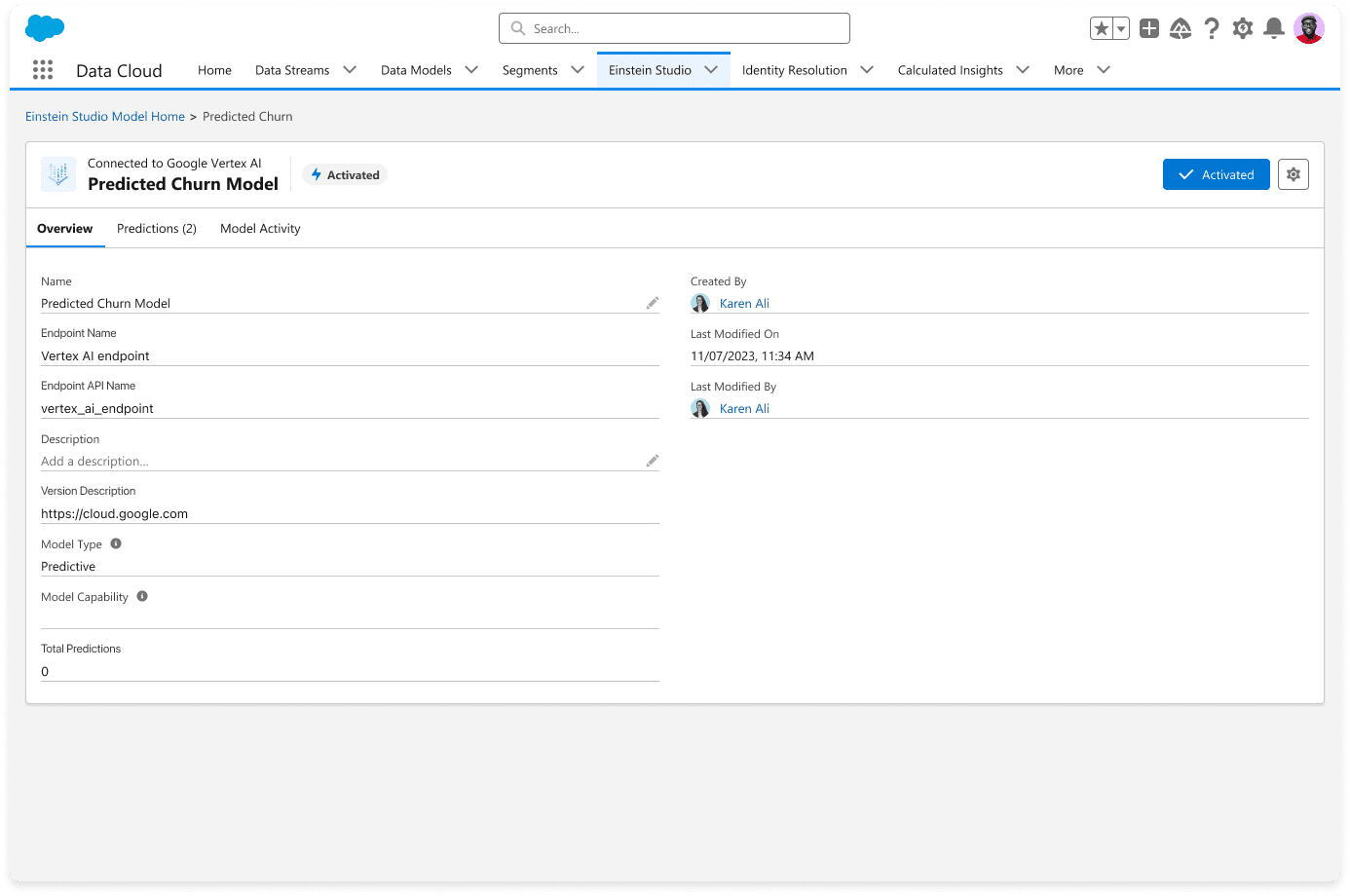
4. ¿Cómo configurar productos de suscripción en Salesforce CPQ?
Hay tres campos esenciales para configurar Productos de suscripción en Salesforce CPQ.
| Campo de producto |
Tipo de datos |
Descripción |
| Precios de suscripción |
Lista de selección |
El producto no se considerará una suscripción sin que este campo esté configurado en Precio fijo o Porcentaje del total. |
| Plazo de suscripción |
Número |
Este es el periodo asociado a la compra, por lo que puedes establecerlo en 12 meses si se trata de una Suscripción Anual. |
| Tipo de suscripción |
Lista de selección |
Este campo determina si el producto es renovable o único. Las Suscripciones Renovables se transfieren a Cotizaciones de Renovación. Las suscripciones únicas no lo harán. |
Para crear Productos de Suscripción , cree un nuevo Registro de productos. Complete los campos: Precio de suscripción , Tipo de suscripción y Plazo de suscripción para el producto. Tenga en cuenta que durante la creación del contrato, los Productos de Suscripción se convierten en registros de Suscripción.

5. ¿Cuál es la diferencia entre restricciones de opciones y reglas de productos?
Las restricciones de opciones y las reglas de productos tienen diferentes casos de uso.
Las restricciones de opciones no pueden seleccionar productos automáticamente. (aunque pueden anular la selección de productos cuando se aplica la dependencia). Son buenos en dos escenarios:
Las restricciones de opciones permiten el procesamiento en tiempo real . Cada vez que el usuario selecciona o deselecciona una opción, la dependencia o exclusión se activa inmediatamente.
Las reglas de producto tienen más funciones que la restricción de opción, aunque es necesario elegir un evento de evaluación para especificar cuándo Salesforce CPQ debe considerar y ejecutar una regla de producto: Cargar, Editar, Guardar o Siempre.
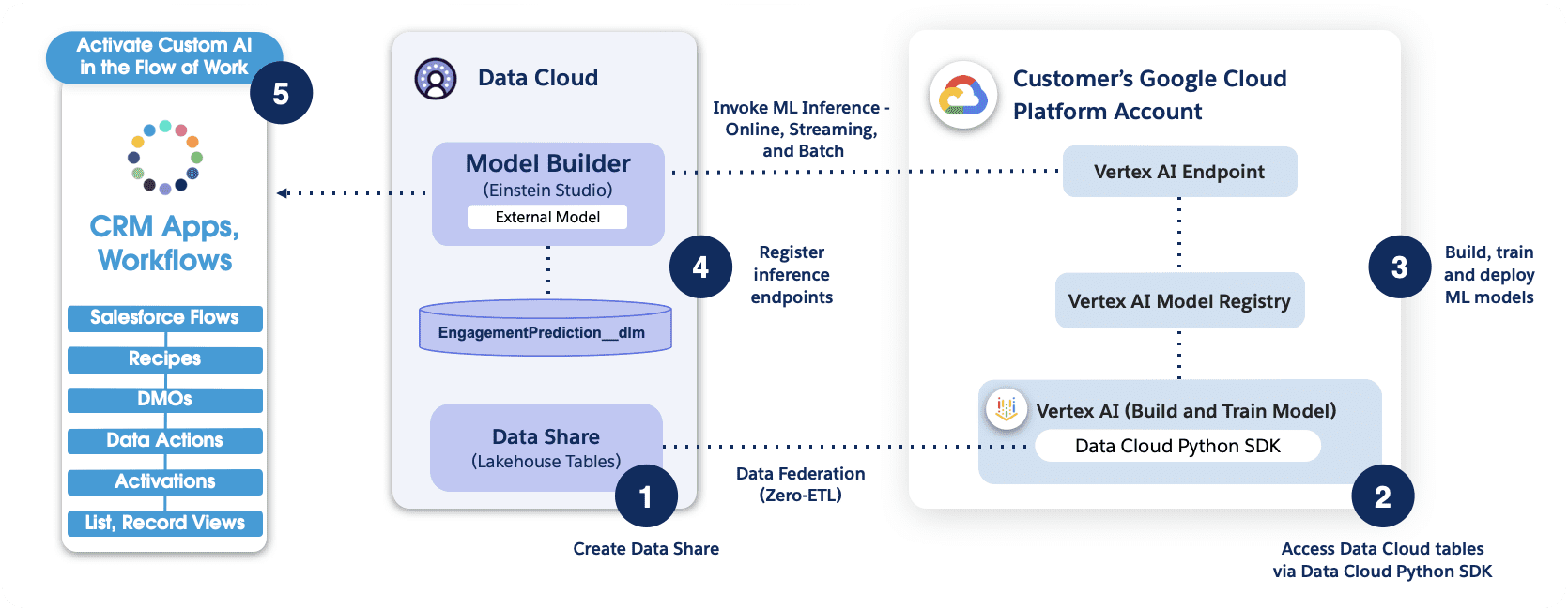
6. ¿Explicar el paquete de productos en CPQ?
Hay tres objetos clave que definen la estructura del paquete :
- Producto
- Opciones
- Características
Producto
Los paquetes están hechos de productos. Se puede hacer referencia a los productos en un paquete, ya sea como paquete principal o como opciones de producto. Piense en la computadora portátil como un producto
Opciones de producto
Son como hijos que se encuentran debajo del paquete principal y son los que realmente unen el paquete porque los paquetes se crean cuando agrega Opciones a un Producto en la lista relacionada de Opciones. Las opciones de producto para computadora portátil pueden ser mouse, teclado, cargador y software de Microsoft.
Características
Son categorías de opciones de productos dentro de la configuración. No son obligatorios, pero se pueden utilizar para una mejor experiencia visual y también ayudan a impulsar lógica adicional, como las opciones mínimas y máximas. Las funciones son como poner opciones dentro de funciones, por ejemplo:
Software
Hardware
Aquí Hardware y Software son características que clasifican las opciones del producto.
Hay tres tipos de paquetes :
Paquete estático. Este sería el paquete fijo tradicional, preempaquetado, en el que se venden ciertos productos juntos a un precio fijo, y el usuario no necesita ingresar a la configuración porque no se permiten ajustes.
Paquete configurable. Este tipo de paquete se puede configurar con ciertas restricciones para evitar configuraciones imposibles. El usuario puede seleccionar diferentes opciones para personalizar el paquete y satisfacer las necesidades del cliente.
Paquete anidado. Estos son paquetes dentro de otros paquetes. Se recomienda mantener los paquetes anidados en tres niveles de profundidad. Los paquetes anidados se crean fácilmente agregando el producto principal de un paquete como opción a otro paquete.
Paquete virtual . Este tipo de fardo funciona como contenedor para otros productos. Para configurar un paquete principal virtual, debe estar asociado con un precio de $0,00.
Paquetes dinámicos . Estas funciones, junto con las reglas de filtrado de productos, permiten a sus representantes de ventas seleccionar productos de una lista previamente filtrada de opciones entre las que pueden elegir.
7.¿Qué son las funciones de CPQ?
El objeto de característica está relacionado con productos y "se encuentra" dentro de paquetes. Un paquete puede tener varias funciones o ninguna, y una función puede tener varias opciones.
Las características tienen dos propósitos:
- Ofrecen una mejor experiencia de usuario mientras navegan por las opciones de productos dentro de los paquetes.
- Los campos en los registros de funciones nos ayudan a impulsar la lógica empresarial , como establecer las opciones mínimas y máximas, evitando que el usuario seleccione muy pocas o demasiadas opciones. Si el usuario no cumple con los requisitos mínimos/máximos e intenta guardar la configuración.
El campo Número establece el orden de visualización de las funciones, siendo la función con el número más bajo la primera en la lista. Se recomienda utilizar incrementos de 10 al asignar números.
El campo SKU configurado se completa automáticamente cuando el usuario crea una función desde la página de detalles del producto del paquete y representa el producto principal que alberga la función.
8. ¿Explica los diferentes valores del campo del método de selección de opciones en el objeto de características?
El campo Método de selección de opciones controla cómo aparecen al usuario las opciones adjuntas a esta función.
Haga clic : las opciones aparecen como una lista con casillas de verificación junto a ellas:
Agregar : las opciones se colapsan y en su lugar aparece un botón Agregar opciones. Se debe hacer clic en el botón Agregar opciones para navegar a una página separada que muestra los productos para esta función.
Dinámico : muestra un botón Agregar opciones, que muestra una lista prefiltrada de productos disponibles para su selección. Para utilizar esta funcionalidad, debe configurar una regla de producto de filtro CPQ de Salesforce para paquetes dinámicos.
9. ¿Explicar el campo del objeto de búsqueda?
Las reglas de producto y las reglas de precio en Salesforce CPQ contienen el campo Objeto de búsqueda. Este campo define el objeto que almacena datos que puede evaluar mediante consultas de búsqueda para compararlos con los campos de cotización, línea de cotización o opción de producto.
10. ¿Explicar la estructura de la plantilla de cotización?
La estructura de la plantilla de cotización incluye:
- Información de la plantilla de cotización
- Información de la página
- Información de encabezado/pie de página
- Información corporativa
- Información de estilo
- Información de estilo de grupo
- Títulos de sección
- Opciones de impresión
- Listas relacionadas
- Columnas de línea
- Secciones de plantilla
- Documentos adicionales
11. ¿Cuáles son los pasos para crear plantillas de cotizaciones?
Hay cinco pasos principales a seguir al crear una plantilla de cotización:
1. Crear la propia plantilla de cotización
2. Almacenamiento del logotipo necesario en Documentos
3. Creando el contenido de la plantilla
4. Creando las secciones de la plantilla
5. Creando las columnas de línea
12. ¿Cómo se puede renovar la suscripción con un cliente existente?
Si ya tiene una oportunidad de renovación, cuando se acerque al final del período de suscripción, es posible que desee venderles las suscripciones de renovación al cliente nuevamente. Para ello, necesita una cotización de renovación.
Se puede generar marcando la casilla de verificación Cotización de renovación como verdadera. Esta cotización de renovación se puede enviar, actualizar y modificar según sea necesario y luego recibirla nuevamente para que posteriormente pueda crear un contrato nuevo.
1. Primero, haga clic en la pestaña Cuentas en la barra de navegación.
2. Vaya a la empresa necesaria y haga clic en la pestaña Relacionado .
3. Acceda al enlace Número de contrato en la lista relacionada Contratos y luego haga clic en Editar .
4. Marque la casilla de verificación Cotización de renovación como verdadera, lo que le indicará a CPQ que genere una cotización sobre la oportunidad de renovación.
.
Tenga en cuenta que la cotización de renovación tiene la Fecha de inicio un día después de la Fecha de cierre de la oportunidad de renovación, mientras que la Fecha de finalización se basa en el Plazo de renovación del contrato.
13. ¿Cómo modificar un contrato en Salesforce CPQ?
Veamos cómo Salesforce CPQ puede actualizar un Contrato existente para incluir mayores cantidades de productos de suscripción, prorrateados por la duración restante del Contrato y crear automáticamente una Oportunidad y Cotización de enmienda:
Cree una cotización de modificación y una oportunidad para aumentar la cantidad de un producto de suscripción de 1 a 10, a partir de los 3 meses del contrato.
Navegue hasta esa cuenta y vaya al enlace Número de contrato en la lista relacionada Contratos. Luego, haga clic en Modificar y nuevamente en Modificar .
14. ¿Cómo funciona el grupo de restricción de opciones en Salesforce CPQ?
Esta característica resulta útil cuando desea hacer que las opciones sean obligatorias o excluidas en función de combinaciones de otras opciones.
Veamos un ejemplo en el que desea evitar que los representantes de ventas vendan el Producto A a menos que el Producto B se haya incluido en la cotización:
A. Haga clic en la pestaña Productos en la barra de navegación.
C. Vaya a la pestaña Relacionados .
D. En la lista relacionada Opciones , seleccione Ver todo y anote el número del Nombre de la opción para las opciones necesarias:
E. Haga clic en Nuevo en la lista relacionada Restricciones de opciones y complete los siguientes campos:
- Para el campo Nombre de restricción , ingrese: El producto A requiere el producto B
- Para el campo Opción restringida , ingrese: < PO-###### del Producto A >
- Para el campo Opción de restricción , ingrese: < PO-###### del Producto B >
- Para el campo Grupo de restricciones de opción , ingrese: Puede ingresar aquí cualquier cadena de texto, pero es una buena práctica hacerla descriptiva y fácil de entender y recordar.
F. Haga clic en Guardar .
16. Tiene un escenario en el que el representante de ventas debe vender un paquete en el que hay al menos tantos Productos B como Productos A. ¿Cómo configurar para este escenario?
Paso 1: Cree una variable de resumen para determinar la cantidad agregada del Producto A en la configuración.
Paso 2: Cree una variable de resumen para determinar la cantidad agregada del Producto B en una configuración.
Paso 3: Cree una regla de producto que confirme cómo funcionará la regla de validación durante la configuración del producto.
Paso 4: Cree una condición de error que controle cuándo se activa la regla, es decir, solo cuando la variable de resumen del producto B es menor que la variable de resumen del producto A.
Paso 5: Cree una regla de configuración para mostrar que la regla de validación se aplicará al paquete de productos.
Paso 6: compruebe si la regla se comporta como se esperaba.
17. ¿Cómo utilizar las restricciones de opciones?
Hay muchos escenarios en los que sus representantes de ventas deben habilitar o deshabilitar un producto en un paquete en función de otra opción de producto.
Los escenarios incluyen:
- A. El Producto A pasa a estar DISPONIBLE si se selecciona el Producto B.
- B. El Producto A NO ESTÁ DISPONIBLE si se selecciona el Producto B.
Esto se puede lograr creando restricciones de opciones a partir de la lista relacionada Restricciones de opciones en el registro de producto principal del paquete.
Cree una restricción de opción para que el Producto A pueda seleccionarse solo cuando se seleccione el Producto B:
18. ¿Explique un caso de uso de precios contratados?
Escenario: el representante de ventas ha negociado con un cliente un precio especial para ciertos productos: $375,00 por una computadora portátil en lugar de $450,00
Utilice la herramienta Precios contratados, que permite crear registros relacionados con cuentas para excepciones de precios.
Primero, creemos un precio contratado para un único producto específico para una cuenta seleccionada. Haga clic en la pestaña Cuentas , haga clic en la cuenta seleccionada , vaya a la pestaña Relacionados y en la lista relacionada Precios contratados , haga clic en Nuevo:
►Producto: Computadora portátil
►Precio: 475
►Haga clic en Guardar.
Tenga en cuenta que los Precios Contratados pueden estar limitados en el tiempo: puede establecer una Fecha de Vigencia y/o una Fecha de Vencimiento.
19. ¿Explicar el evento de evaluación en la regla del producto?
Evento de evaluación : especifica cuándo se debe evaluar la regla:
Cargar: La regla se evaluará cuando se abra el paquete de productos.
Editar: la regla se evaluará cuando se edite el paquete de productos.
Guardar: la regla se evaluará al guardar.
Siempre: La regla será evaluada durante cualquier evento.
Ahora, supongamos que tiene un campo en el Objeto de producto que también desea ver en la Línea de cotización. Cree un campo con el mismo nombre de API y del mismo tipo.
20. ¿Qué es la venta guiada de Salesforce?
La venta guiada implementada en CPQ es una herramienta que formula preguntas sobre las necesidades del cliente en función de la selección de productos disponibles. Se hace creando un mensaje que pregunta a los representantes de ventas sobre los tipos de productos que desean agregar a la cotización y sus especificaciones.
21. ¿Qué es el precio por bloque de Salesforce?
Los precios en bloque le permiten fijar el precio de un producto en función de diferentes rangos de cantidades que se denominan precios en bloque.
- El precio en bloque es un precio basado en niveles. El precio basado en niveles significa que el precio del producto depende de la cantidad que compra el cliente.
- El precio también se basa en el rango de cantidad y no en el producto individual.
22. ¿Cuáles son los pasos para implementar un paquete dinámico?
Los paquetes dinámicos permiten a los representantes de ventas elegir sus propias opciones en un paquete. Puede utilizar reglas de filtrado para filtrar las opciones entre las que pueden elegir.
Para implementar un paquete dinámico, estos son los pasos de implementación que debe seguir:
►Crear una característica
►Crear una regla de producto
►Crear una acción
►Crear una regla de configuración
23. ¿Cuándo utilizar reglas de producto frente a restricciones de opciones?
Cuándo utilizar restricciones de opciones
Si tiene menos opciones y puede ajustar todas las opciones de producto en la categoría/pestaña sin tener que desplazarse mucho, entonces puede ser mejor optar por restricciones de opciones. Estos no pueden ocultar las Opciones del producto por completo, pero pueden habilitar/deshabilitar las Opciones del producto mediante otras selecciones.
24. ¿Cuándo utilizar las reglas del producto?
Este enfoque es especialmente útil en configuraciones más grandes que se muestran en categorías (pestañas), donde cada categoría puede requerir un desplazamiento extenso para mostrar todas las opciones.
| Diferencias |
Restricciones de opciones |
Reglas de selección de productos |
| Acciones admitidas |
Habilitar deshabilitar |
Agregar, habilitar, deshabilitar, eliminar, habilitar y agregar, deshabilitar y eliminar, ocultar, mostrar, ocultar y eliminar, mostrar y agregar |
| Condiciones |
La restricción de opción tiene una condición simple: si se selecciona la opción X |
Las reglas de producto pueden tener múltiples condiciones que evalúan información fuera del contexto del paquete, es decir, campos de nivel de cotización/oportunidad/cuenta. |
| Alcance |
La restricción de opciones se limita a una sola opción. |
Las reglas del producto pueden actuar sobre múltiples opciones |
| Contexto |
Se utiliza sólo en el contexto de paquetes. Funciona en las opciones dentro del mismo paquete. Es específico de un solo paquete. |
Se utiliza en el contexto de paquetes y productos independientes. Se puede aplicar una regla de producto único a paquetes ilimitados. |
| Resultado |
No se puede seleccionar/deseleccionar automáticamente un producto |
Puede seleccionar/deseleccionar automáticamente un producto |
25. ¿Cuándo se ejecutan las Reglas de Producto durante el proceso de cotización?
Las reglas del producto se ejecutan en la página de configuración del producto o en el editor de líneas de cotización. Esto se decide en función de los siguientes campos de reglas de producto:
a. ALCANCE – (Valores: Producto/Cotización ): el campo Alcance en el registro de regla del producto le indica a CPQ DÓNDE debe ejecutarse la regla. Un alcance de "Producto" significa que la regla se ejecutará durante la configuración del producto, y un alcance de "Cotización" hará que se ejecute en el Editor de líneas de cotización.
b. EVENTO DE EVALUACIÓN – (Valores: Cargar/Editar/Guardar/Siempre ): el campo Evento de evaluación en el registro de regla del producto le indica a CPQ CUÁNDO debe ejecutarse la regla.
26. Explique la descripción general del ciclo de vida de Salesforce CPQ.
Generación de leads: el ciclo de vida de CPQ comienza con la generación de leads, donde los clientes potenciales muestran interés en tus productos o servicios.
Creación de oportunidades: una vez que se identifica un cliente potencial, se convierte en una oportunidad en Salesforce. Esta etapa implica recopilar información del cliente y evaluar sus necesidades.
Configuración del producto: en esta etapa, el equipo de ventas utiliza Salesforce CPQ para configurar productos o servicios de acuerdo con los requisitos del cliente. CPQ permite configuraciones complejas de productos, opciones de agrupación y personalización.
Precios y descuentos: Salesforce CPQ permite al equipo de ventas aplicar precios y descuentos adecuados según los requisitos específicos del cliente, precios basados en el volumen o acuerdos contractuales. Esta etapa garantiza precios precisos y maximiza el potencial de ingresos.
Generación de cotizaciones: una vez determinados la configuración del producto y el precio, Salesforce CPQ genera una cotización profesional adaptada a las necesidades del cliente. La cotización incluye información detallada sobre los productos o servicios, precios y términos.
Aprobación y negociación de la cotización: la cotización generada pasa por un proceso de aprobación, donde las partes interesadas correspondientes la revisan y brindan su consentimiento. Esta etapa puede implicar negociación con el cliente para finalizar los detalles de la cotización.
Aceptación de cotización: una vez que el cliente acepta la cotización, avanza a la siguiente etapa del ciclo de vida de CPQ.
Creación de pedidos: la cotización aceptada se convierte en un pedido, lo que desencadena el proceso de cumplimiento, incluida la gestión de inventario, el procesamiento de pedidos y el envío.
Gestión de contratos: Salesforce CPQ proporciona capacidades de gestión de contratos, lo que permite al equipo de ventas generar y gestionar contratos basados en la cotización aceptada. Esta etapa garantiza el cumplimiento legal y agiliza la gestión del ciclo de vida del contrato.
Reconocimiento de ingresos: Salesforce CPQ se integra con sistemas de facturación y procesos financieros para facilitar el reconocimiento preciso de ingresos. Esto implica rastrear e informar los ingresos en función de los productos o servicios entregados.
Renovación y ventas adicionales: a medida que los contratos se acercan a su vencimiento, Salesforce CPQ ayuda a gestionar las oportunidades de renovación. El sistema puede identificar oportunidades de ventas adicionales o cruzadas y guiar al equipo de ventas para maximizar el valor para el cliente.
Informes y análisis: a lo largo del ciclo de vida de CPQ, Salesforce CPQ proporciona capacidades de informes y análisis para monitorear métricas clave, rastrear el desempeño de ventas, identificar tendencias y tomar decisiones basadas en datos.
27. ¿Explicar los atributos de configuración?
En Salesforce CPQ, esta funcionalidad se puede lograr principalmente creando un registro del objeto de atributo de configuración .
Atributo de configuración
Hay 2 tipos de Atributos de Configuración que podemos crear en Salesforce CPQ.
- Atributo de configuración
- Atributo global
- Cuando queramos crear y asignar cualquier atributo al producto del paquete , crearemos un registro de Atributo de configuración que tenga el tipo de registro "Atributo de configuración" .
- Cuando queramos crear y asignar cualquier atributo a un producto de opción , crearemos un atributo de configuración de registro que tenga el tipo de registro "Atributo global" .
28. ¿Qué es el precio excedente en Salesforce CPQ?
Imagina que tienes un plan de telefonía móvil que incluye hasta 10 GB de datos por 30 dólares al mes. Esto es mucho, pero ¿qué pasa si usas más de 10 GB en un mes? Ahí es donde entran en juego las tasas excedentes.
La compañía telefónica ofrece una tarifa excedente de $2 por GB adicional de datos utilizados más allá de los 10 GB iniciales. Esto significa que si usas 11 GB en un mes, pagarás la tarifa base de $30 por los primeros 10 GB, más una tarifa excedente de $2 por los GB adicionales, por un total de $32.
Así es como se descompone:
– Si usas 10 GB o menos, solo pagas tus $30 habituales, sin cargos adicionales.
– Si usas 11 GB, pagas $30 por los primeros 10 GB, luego $2 adicionales por el 11.° GB, para un total de $32.
– Si usas 12 GB, pagas $30 por los primeros 10 GB, luego $4 adicionales por los GB 11 y 12, por un total de $34.
…y así sucesivamente, sumando $2 por cada GB que uses por encima de los 10GB.
Este sistema hace que la facturación sea más clara y sencilla. Usted sabe exactamente cuánto se le cobrará si excede su límite de datos y la compañía telefónica puede calcular fácilmente los cargos según el uso real.
Para utilizar tarifas excedentes, debemos crear un campo personalizado especial en el objeto Precio de bloque. Este es un paso único para cualquier organización que utilice Salesforce CPQ.
29. ¿Explique la caída de precios en CPQ con la ayuda de un ejemplo?
Imagina que estás en "Sundae Funday", una heladería conocida por sus aderezos y sabores especiales. Decides comprar un cono de triple bola con tus sabores favoritos y así es como cambia el precio:
1. Precio original: Este es el costo básico en el que incurre “Sundae Funday” para hacer un cono de helado, incluyendo el helado, el cono, los aderezos y los costos operativos. Digamos que son $3.00. Esto no incluye ganancias ni costos adicionales; es simplemente cuánto le cuesta a la tienda hacer ese delicioso cono.
2. Precio de lista: ahora, el taller agrega su margen de beneficio, considerando factores como los gastos generales, los salarios del personal y el margen de beneficio. Este es el precio que ves en el menú cuando entras. Entonces, tu cono de triple cucharada aparece en $5.00. Ese es el precio estándar para cualquier cliente en un día normal.
3. Precio especial: ¿Adivina qué? Visitas la tienda un “martes tropical” y todos los conos con sabor tropical tienen un 20% de descuento. Como elegiste mango como una de tus bolas, tu cono ahora tiene un “precio especial” de $4.00. Este precio es específico para esta promoción o segmento de clientes.
4. **Precio Regular**: ¡Aquí vienen los beneficios del programa de fidelización! Como titular de una tarjeta de fidelidad “Sundae Funday”, tienes derecho a un descuento adicional del 10 % en cualquier compra. Ese beneficio reduce su precio a $3.60. Este es el “precio regular” que se ofrece a los clientes que cumplen ciertos criterios, como los miembros leales.
5. **Precio para el cliente**: Tienes un cupón por completar una encuesta en tu última visita, lo que te otorga un descuento adicional de $0,50 en tu próxima compra. Después de aplicar esto, su “precio al cliente” ahora es de $3,10. Este precio es el resultado de interacciones o negociaciones directas y únicas.
6. **Precio de socio**: La heladería tiene una asociación con un cine cercano. Dado que tiene una entrada de cine para el mismo día, obtiene un descuento adicional del 5%, lo que reduce su cono a un “precio de socio” de $2,95.
7. **Precio neto**: Finalmente, hay una promoción para toda la tienda en la que cada compra superior a $2,50 obtiene un descuento adicional de $0,10. Esto último te lleva a tu “precio neto” final de $2,85. Este es el monto final que paga y refleja todos los descuentos, promociones y circunstancias especiales que ha acumulado.
En este viaje, cada reducción de precio refleja una etapa en la cascada de precios CPQ, desde el costo básico de los bienes hasta el precio final pagado por un cliente en una posición única.
Memorizar las etapas de tarificación junto con sus funciones utilizando el
Con el mnemotécnico “Los viejos leones duermen, rara vez atrapan presas, nunca ronronean” , puede crear una historia que vincule cada término no solo con el orden de los precios sino también con sus roles específicos en el proceso de fijación de precios.
30. ¿Explique el método de fijación de precios de 'porcentaje del total'?
Imagina que estás en un parque de helados, famoso por su variedad de deliciosos helados y divertidas atracciones secundarias. Uno de los servicios únicos que ofrece este parque es el "Bono Sorpresa de Sundae", un regalo especial que se calcula en función del monto total que gasta en otras delicias. Así es como funciona:
1. Método de fijación de precios: “Porcentaje del total”:
– Piense en esto como la “Regla de la sorpresa del helado”. Cada vez que compras helados, batidos o aderezos, eres elegible para recibir un regalo adicional. El parque ha establecido esta regla especial según la cual su bonificación es un porcentaje del monto total que ha gastado, como su “propina” en el restaurante. Esta regla es conocida por todos y es como la forma especial que tiene el parque de dar las gracias.
2. Porcentaje del total (%) – El número mágico:
– El parque tiene carteles por todas partes que dicen: “¡Gasta en golosinas y recibe un 10% de bonificación!” Este 10% es el número mágico. Es como la receta especial para la felicidad del parque. Entonces, si gastas $30 en varios helados y batidos, recibirás un “Bono Sorpresa de Sundae” por valor de $3.
3. Porcentaje de la base total: recuento de helados:
– Ahora, aquí es donde se pone aún más genial. El parque te permite elegir qué cuenta para este cálculo mágico del helado. Suponga que decide que solo cuentan las bolas de helado, no los batidos ni los waffles. Eso significa que si gastaste $20 en bolas y $10 en batidos, solo los $20 cuentan para tu “Bono Sorpresa de Sundae”, lo que lo convierte en un valor de $2 (10% de $20).
Por lo tanto, cada vez que disfruta de las delicias cremosas en este parque de helados, Salesforce CPQ es como el servidor invisible que trabaja en segundo plano. Se trata de asegurarse de que se sigan las reglas, calcular su gasto total, aplicar el porcentaje mágico y calcular su bonificación en función exactamente de lo que desea contar para la sorpresa.
Esto hace que recordar el concepto de “porcentaje del total” sea tan fácil como disfrutar de un helado en un día soleado.
50% Me gusta VS
50% No me gusta




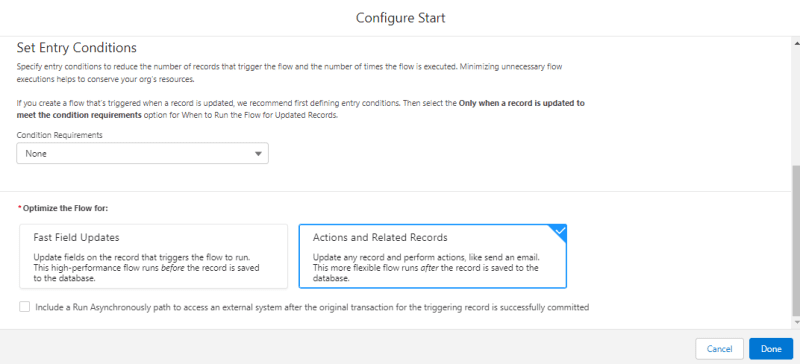
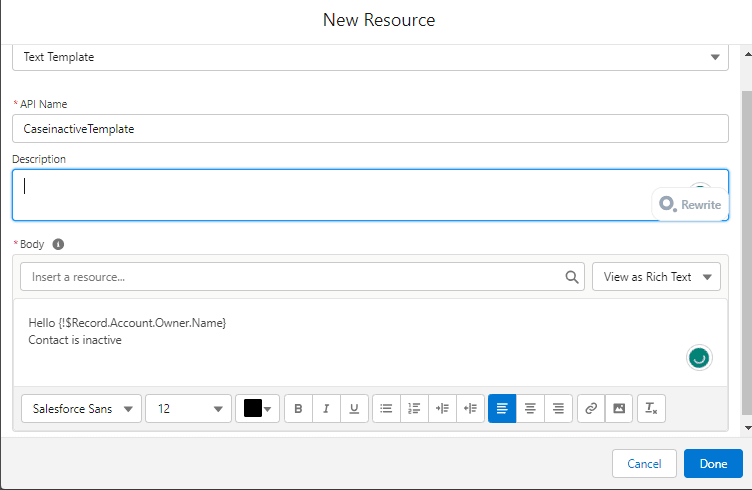
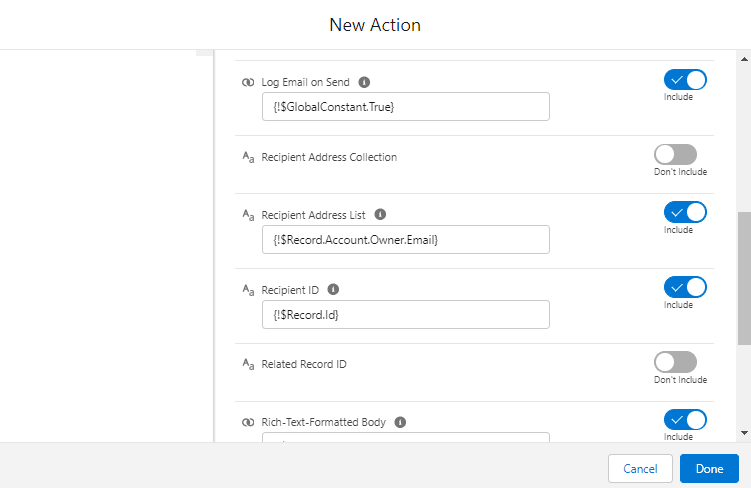
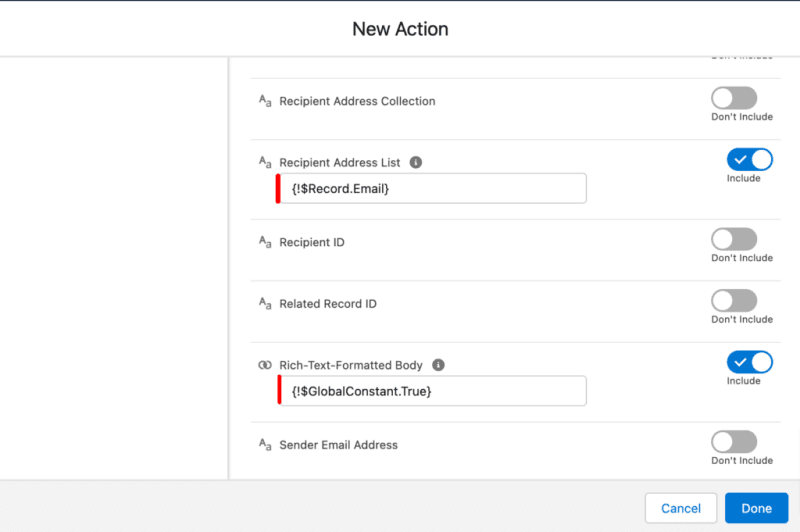
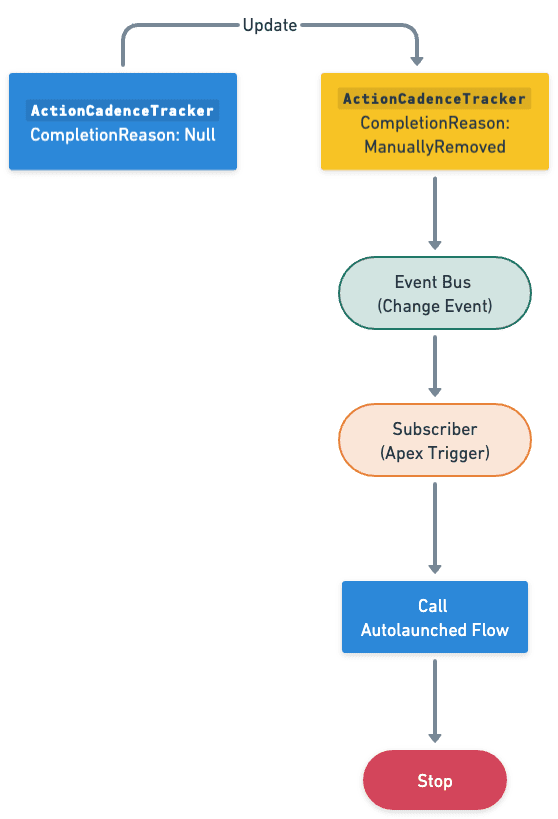 Comencemos a construir este proceso de automatización.
Comencemos a construir este proceso de automatización.