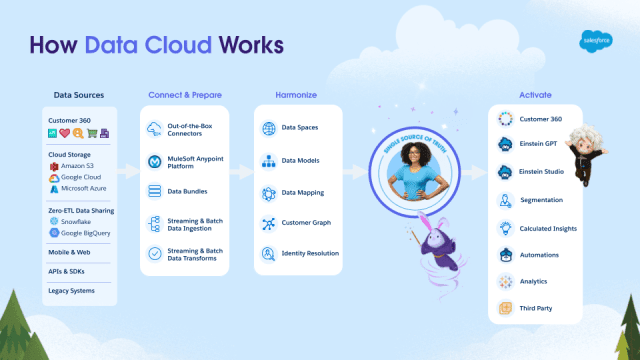
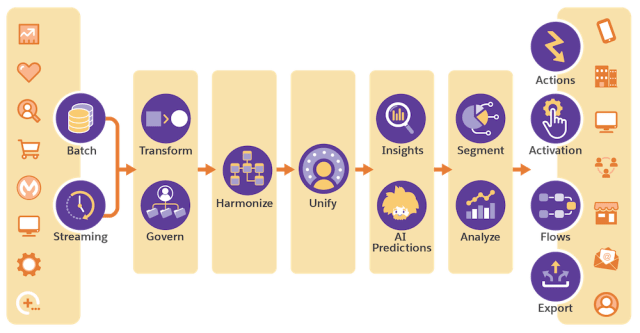
Salesforce Data Cloud ofrece varios conectores predefinidos para la importación de datos. Estos le permiten conectar otra organización de Salesforce, una instancia de Marketing Cloud, almacenamientos de datos como Amazon S3 o cualquier otra fuente admitida por MuleSoft Salesforce Data Cloud Connector . Para conectarse a un sistema de terceros, puede utilizar la API de ingesta .
La API de ingesta es una interfaz RESTful que facilita la carga de datos mediante programación en Data Cloud. Admite patrones de interacción masiva y de transmisión. El patrón de transmisión usa JSON como su formato, cargando datos en micro lotes a través de la API REST. El patrón masivo, por otro lado, emplea el formato CSV y carga datos usando trabajos.
En esta publicación de blog, analizaremos cómo configurar el conector de la API de ingesta y comenzar a cargar datos mediante programación utilizando los patrones Streaming y Bulk.

Cuándo usar la ingestión Streaming vs Bulk
| Ingestión de transmisión |
Ingestión a granel |
| Al actualizar pequeños microlotes de registros casi en tiempo real |
Al mover grandes volúmenes de datos en un programa diario, semanal o mensual |
| Cuando se utilizan sistemas de origen de datos que se basan en arquitecturas de transmisión modernas |
Al usar sistemas heredados, donde solo puede exportar datos durante las horas de menor actividad |
| Al crear eventos de captura de datos modificados |
Al usar una nueva organización de Data Cloud que desea rellenar con 30, 60 o más de 90 días de datos |
| Al consumir datos de webhooks |
|
Para configurar la API de ingesta, deberá seguir cuatro pasos de requisitos previos:
- Crear un conector de API de ingesta
- Crear e implementar un flujo de datos
- Crear una aplicación conectada
- Solicitar un token de acceso a la nube de datos
Veamos el proceso de creación y configuración de un conector de ingesta para comenzar a cargar datos en Data Cloud.
Creación de un conector de API de ingesta
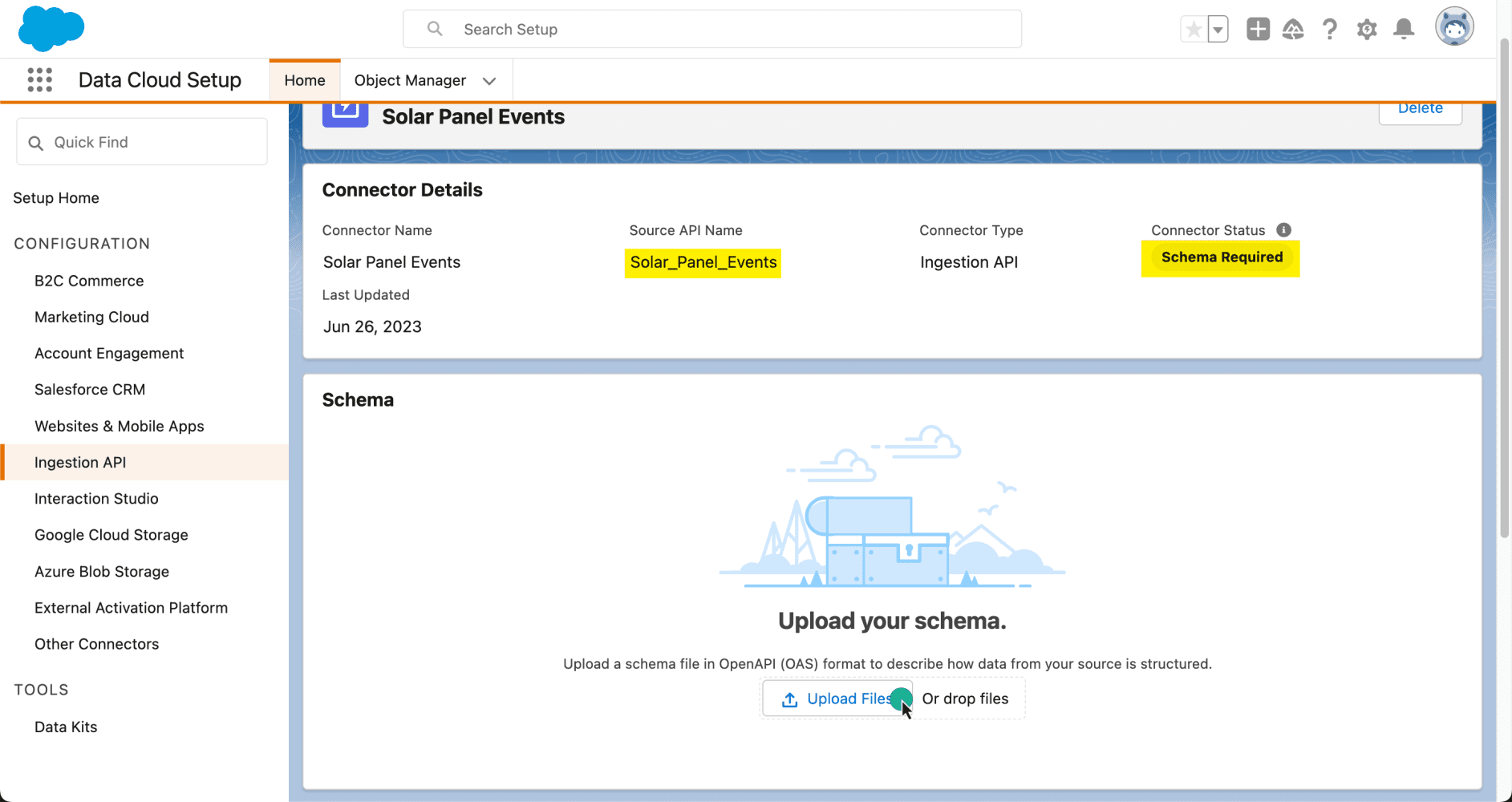
Supongamos que tiene acceso a Data Cloud. Para conectar una nueva fuente de API de ingesta mediante el conector de API de ingesta, vaya a Configuración de nube de datos y seleccione API de ingesta .
Aquí encontrará todos los conectores disponibles en su organización. Para crear uno nuevo, haga clic en Conectar y proporcione un nombre. Para nuestra aplicación de muestra, trabajaremos con una empresa de energía solar ficticia. Estamos interesados en recibir eventos de métricas relacionadas con el rendimiento energético de sus paneles solares.
Una vez que se haya creado el conector, necesitaremos decirle a Data Cloud qué tipo de datos estamos esperando. Para esto, necesitaremos cargar un archivo de esquema utilizando la especificación OpenAPI. Este archivo de esquema tiene requisitos específicos, así que asegúrese de consultar la documentación para obtener más información.
A continuación se muestra un ejemplo del archivo de esquema que cargaremos, que representa un solar_panel_event . Los campos clave a tener en cuenta incluyen event_id , que será único para cada evento y luego se asignará en Data Cloud como clave principal. Otro es customer_id , que nos será útil para mapear el evento con un cliente de nuestra organización. Finalmente, date_time representa la hora del evento.
panel_solar_event.yaml
Una vez que carguemos el esquema, podremos obtener una vista previa de sus campos y tipos de datos, y luego guardarlo en nuestro conector.
Ahora que nuestro conector tiene un esquema, podemos decir que está creado. Sin embargo, aún no está listo para comenzar a recibir datos. Necesitamos crear un flujo de datos para este propósito.
Nota: Dado que los esquemas pueden evolucionar con el tiempo, también puede usar la interfaz del conector de la API de ingesta para actualizar el esquema y agregar nuevos campos a su objeto de datos según sea necesario.
Creación e implementación de un flujo de datos
Ya tenemos listo nuestro conector API de ingesta. Ahora es el momento de establecer una conexión para comenzar a importar datos. Para eso, necesitamos crear un flujo de datos . Una vez que el flujo de datos está activo, podemos comenzar a ingerir datos en Data Cloud y almacenarlos como un objeto de Data Lake.
Para crear un nuevo flujo de datos, vaya a su pestaña en la aplicación Data Cloud, haga clic en Nuevo , seleccione Ingestion API y luego haga clic en Siguiente .
Nota: La opción API de ingesta está deshabilitada si no tiene ninguna fuente de ingesta conectada.
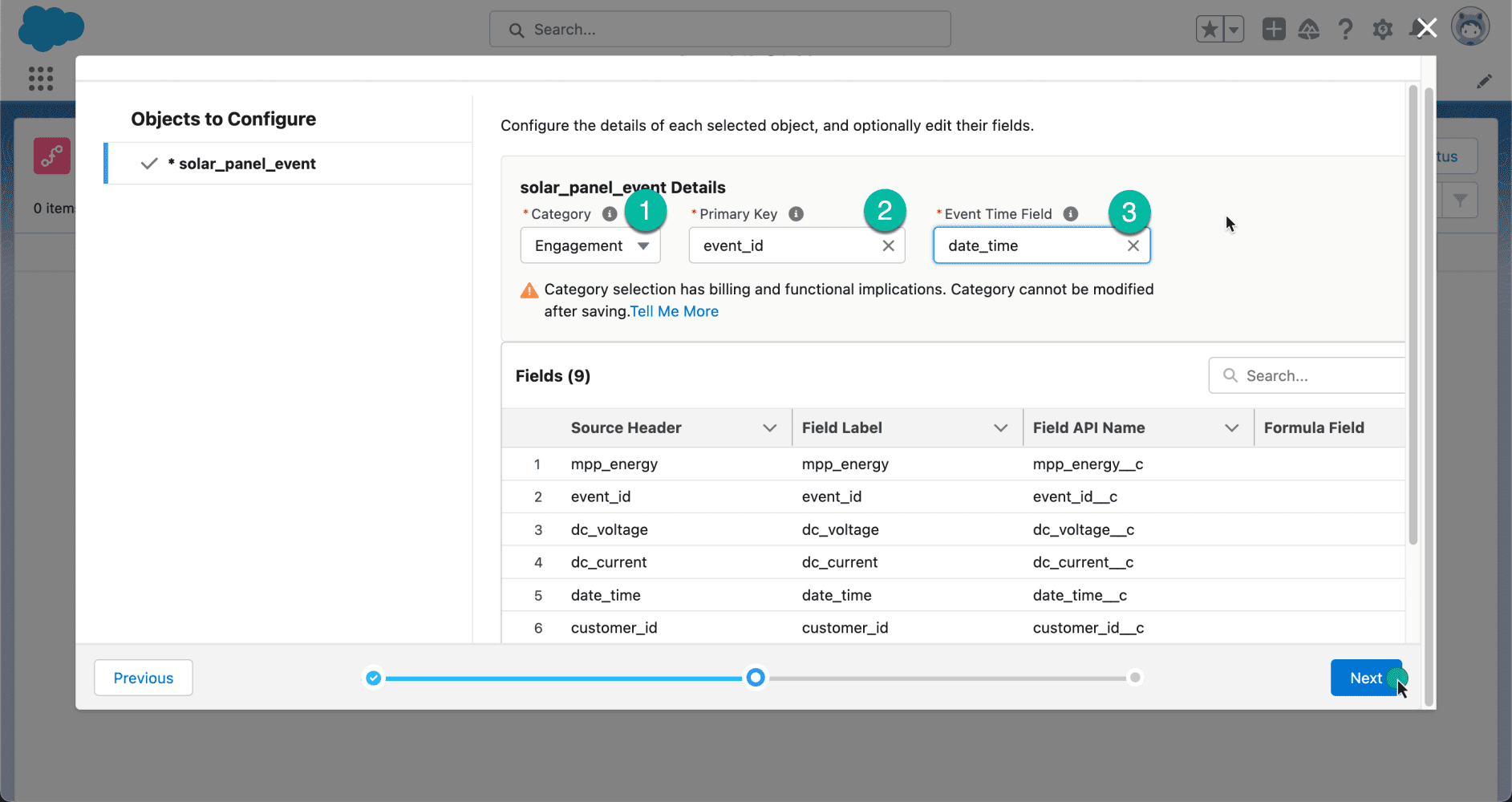
A continuación, verá los diferentes objetos que están asociados con su esquema. En nuestro caso, seleccione el objeto solar_panel_event y haga clic en Siguiente .
Al crear un flujo de datos, deberá seleccionar una categoría o tipo de datos en ese flujo de datos. Hay tres categorías: Compromiso , Perfil y Otro .
| Compromiso |
Un conjunto de datos que representa un compromiso basado en series de tiempo, como un evento, interacción con el cliente, interacción web, etc.
Cuando se selecciona, el menú desplegable Campo de hora del evento aparece en la interfaz de usuario.
|
| Perfil |
Un conjunto de datos que representa:
– Una lista de consumidores con identificadores, como identificaciones de consumidores, direcciones de correo electrónico o números de teléfono
– Una lista de empresas o cuentas con ID de cuenta
– Una lista de empleados o cualquier otra población por la que desee segmentar o utilizar como población inicial del segmento
|
| Otro |
Un conjunto de datos que no es un compromiso o un perfil, como información de productos o tiendas. |
Para nuestro ejemplo, dado que estamos planeando recibir eventos, seleccionaremos Compromiso . Mapearemos el event_id como la clave principal y la date_time como el campo de hora del evento.
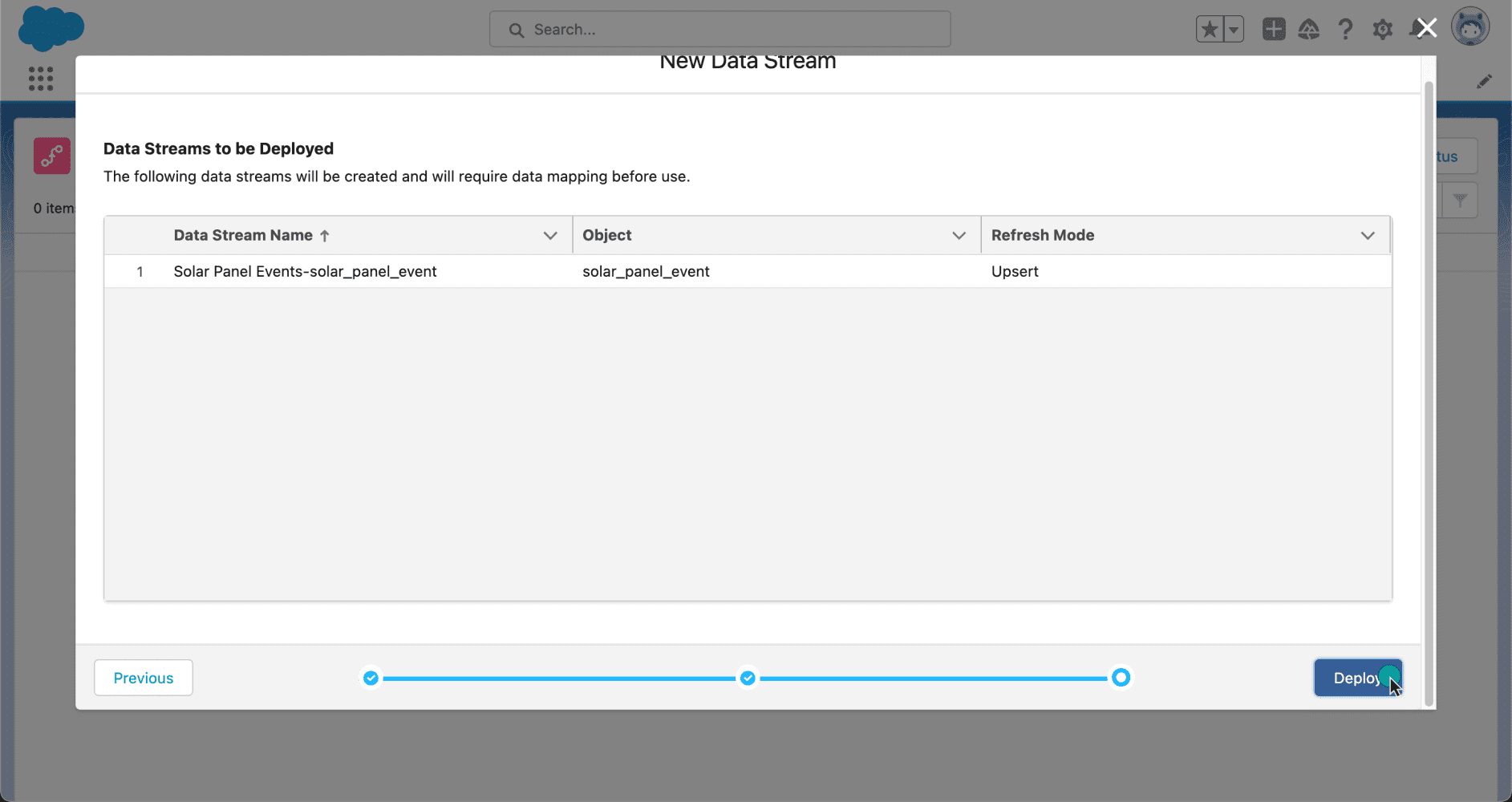
Ahora que nuestros datos están configurados, es hora de implementarlos. Después de revisar los flujos de datos que se van a crear, hagamos clic en Implementar para activarlos.
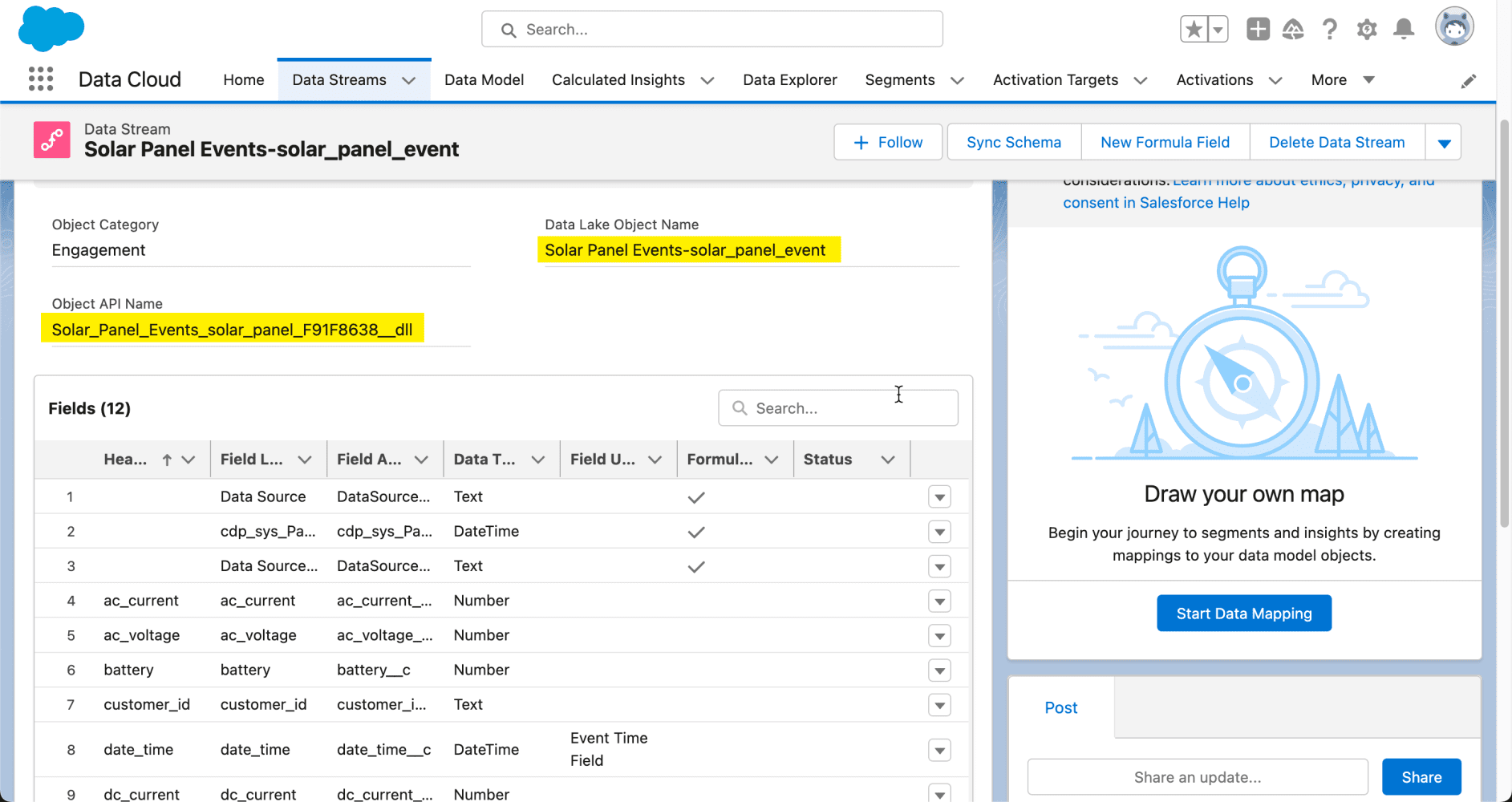
Ahora, echemos un vistazo a la página de detalles del flujo de datos. Aquí podemos ver el objeto Data Lake que se ha creado en Data Cloud. Puede identificar un objeto de Data Lake por su sufijo __dll . Desde esta misma interfaz, puede comenzar a asignar sus datos a los objetos de su organización para crear objetos de modelo de datos (parte del proceso de armonización de Data Cloud). Sin embargo, no cubriremos ese tema en esta publicación de blog, pero tenemos un excelente video con Danielle Larregui que le muestra cómo hacerlo.
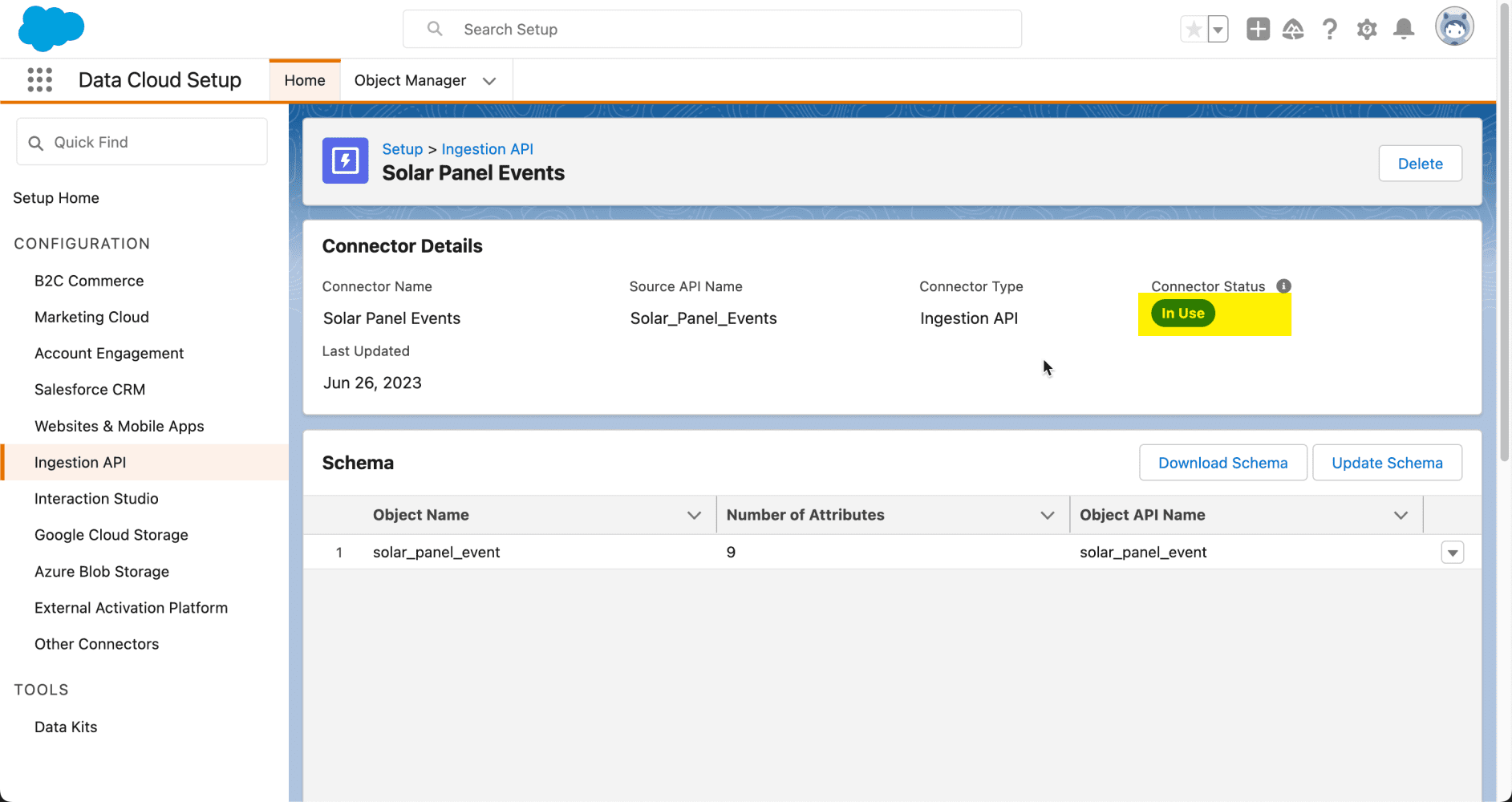
Nuestro conector API de ingesta está listo para comenzar a recibir datos de sistemas de terceros. Para confirmar, regresemos a la interfaz de configuración de la API de ingesta, donde puede ver que el estado del conector es En uso .
Creación de una aplicación conectada
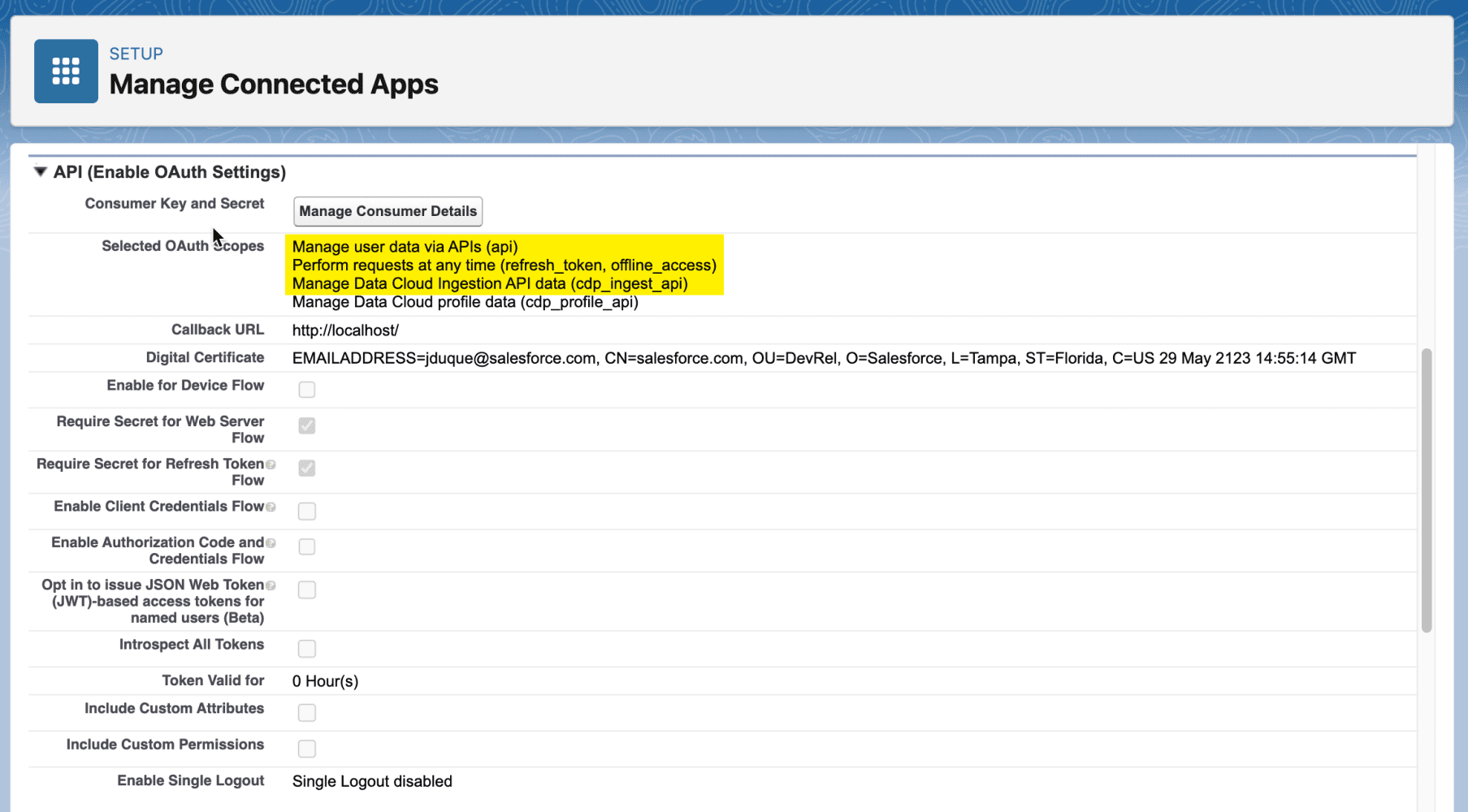
La API de ingesta admite todos los flujos de OAuth 2.0 admitidos por otras API REST de Salesforce. Para cargar datos mediante la API de ingesta, su aplicación conectada requiere los siguientes ámbitos:
Ámbitos de OAuth requeridos
| cdp_ingest_api |
Acceda y administre sus datos de API de ingesta de nube de datos |
| API |
Accede y administra tus datos |
| refresco_token, acceso_sin conexión |
Realizar solicitudes en su nombre en cualquier momento |
Además, nuestra aplicación conectada requerirá un certificado digital. Para crear uno, puede ejecutar el siguiente comando usando el comando openssl :
Este comando creará dos archivos, salesforce.key , que es la clave privada, y salesforce.crt , que es la clave pública.
Nota : si no tiene instalado el comando openssl , puede instalarlo desde el sitio web de OpenSSL .
Para saber cómo crear una aplicación conectada, consulte la documentación oficial.
Solicitud de un token de acceso a la nube de datos
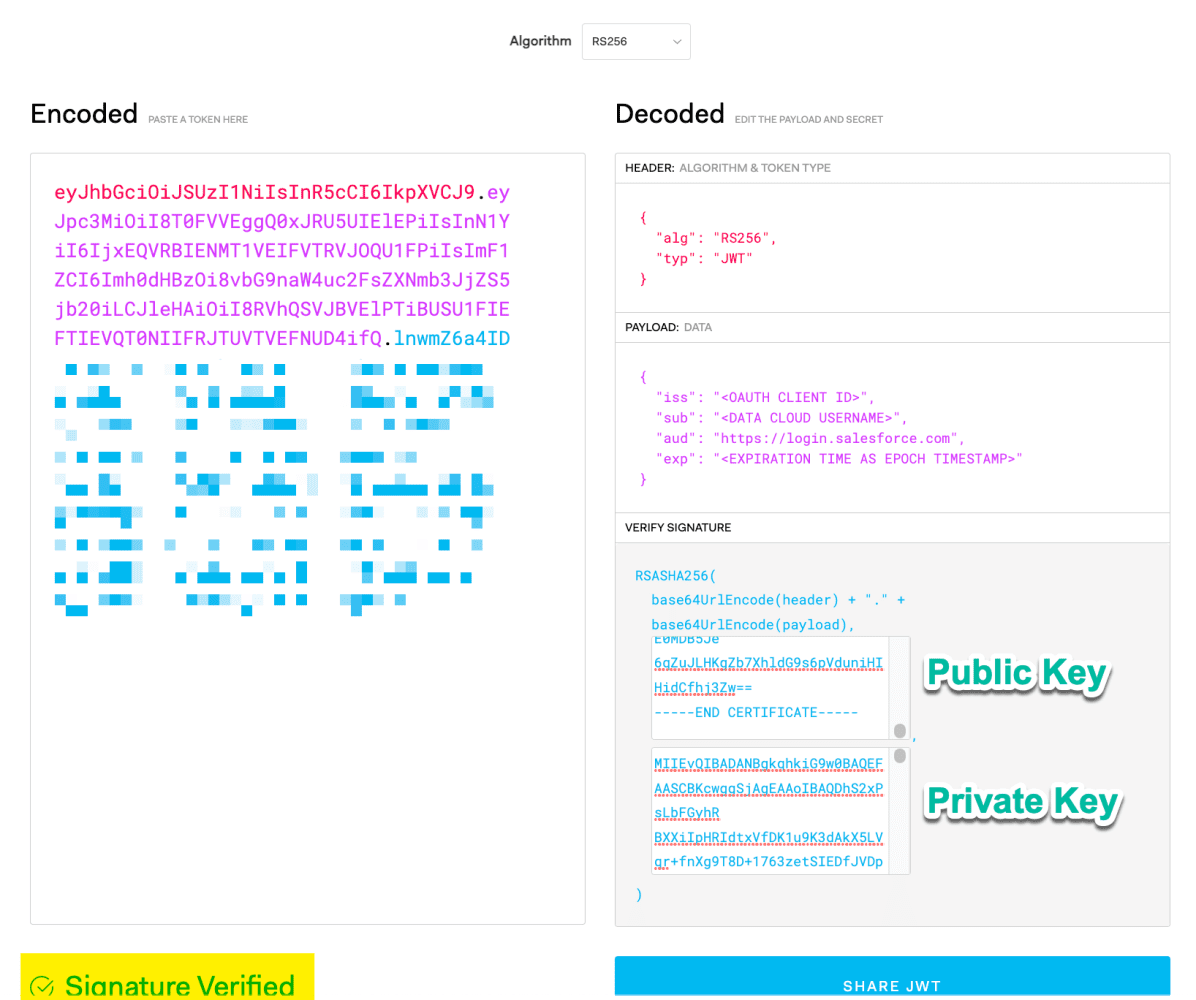
Para este ejemplo, usaremos el flujo de soporte JWT de OAuth 2.0 . Primero, necesitaremos crear un JWT (JSON Web Token) para solicitar un token de acceso.
Para crear un JWT, configurará el encabezado para usar el algoritmo RSA256 .
Encabezado JWT
Luego, configure las siguientes notificaciones, teniendo en cuenta algunas notificaciones importantes:
- iss: la clave de consumidor de OAuth/ID de cliente de su aplicación conectada
- sub: el nombre de usuario de su organización de Data Cloud
- exp: el tiempo de vencimiento del token, expresado como una marca de tiempo de época
reclamos JWT
Nota : La época de Unix (o la hora de Unix o la hora POSIX o la marca de tiempo de Unix) es la cantidad de segundos que han transcurrido desde el 1 de enero de 1970 (medianoche UTC/GMT).
A continuación, deberá utilizar el algoritmo JWT para obtener el token completo y verificado.
Pero seamos honestos, no queremos crear un JWT manualmente. Para esto, utilizaremos el sitio web JWT.io para simplificar el proceso. Asegúrese de que el mensaje Firma verificada aparezca a continuación, lo que indica que nuestro JWT es válido.
O puede crearlo programáticamente usando el lenguaje de programación de su elección. Más adelante en este artículo, compartiré un práctico script de Node.js para generar el token de acceso a la nube de datos.
Antes de que podamos autenticarnos usando el JWT que generamos, debemos aprobar este consumidor. Puede hacerlo abriendo la siguiente URL en su navegador.
<dx-code-block title language code-block="https://login.salesforce.com/services/oauth2/authorize?response_type=token&client_id=&redirect_uri=»>
Y luego, inicie sesión y permita el acceso:
Ahora que hemos aprobado nuestro JWT, necesitamos autenticarnos. Este es un proceso de dos pasos. Primero, necesitamos obtener un token de acceso usando el JWT. Para hacer esto, realicemos una solicitud POST HTTP con la siguiente información.
<dx-code-block title language code-block="POST https://login.salesforce.com/services/oauth2/token
Content-Type : x-www-form-urlencoded
grant_type=urn:ietf:params:oauth:grant-type:jwt-bearer
&assertion=»>
Nota: asegúrese de reemplazar <JWT> con el token que creamos anteriormente.
Esta solicitud nos dará un token de acceso central y la URL de la instancia de Data Cloud, utilizando nuestra aplicación conectada. Como se muestra en el alcance , se nos otorgan los alcances cdp_ingest_api y api .
A continuación, debemos cambiar el token de acceso principal por un token de nube de datos. Para hacer eso, realicemos la siguiente solicitud POST.
<dx-code-block title language code-block="POST /services/a360/token Content-Type : x-www-form-urlencoded grant_type=urn:salesforce:grant-type:external:cdp &subject_token= &subject_token_type=urn:ietf:params:oauth:token-type:access_token»>
Ahora, estamos autenticados. El token de acceso a la nube de datos resultante es lo que usaremos para realizar solicitudes a la API de ingesta.
Para simplificar el proceso, he creado un script Node.js. Crea el JWT y realiza la autenticación en dos pasos. Para usarlo, necesitará la clave privada que creó anteriormente, así como un archivo de configuración similar al siguiente.
config.js
Además, instale la dependencia jsonwebtoken desde npm ejecutando:
credenciales.js
console.log(auth)) .catch((err) => console.error(err)); «>
El método generateAccessToken devolverá el objeto de autenticación de Data Cloud, incluido el access_token y la instance_url necesarios para comenzar a ingerir datos en Data Cloud.
Ingesta de datos
Tenemos toda la información necesaria para comenzar a ingerir datos en la nube de datos. Esto se puede lograr utilizando los patrones Streaming o Bulk.
Transmisión
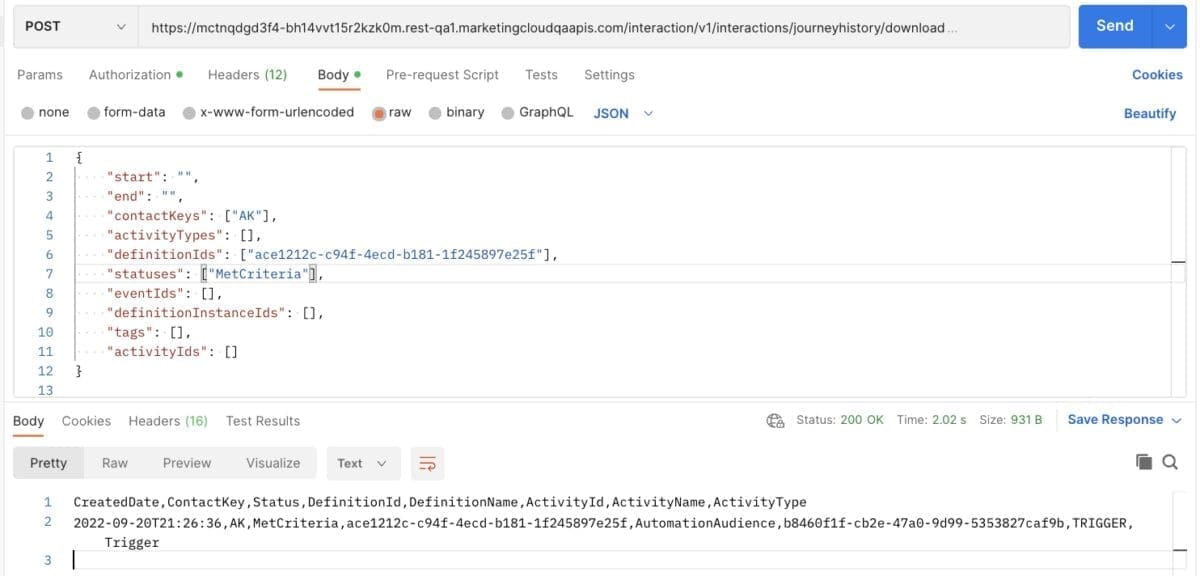
Para comenzar a transmitir datos en el conector de Ingestión de nube de datos, primero obtenga el nombre del conector y el nombre del objeto de la configuración del conector de la API de Ingestión. Para hacer esto, puede realizar una solicitud POST como la siguiente.
<dx-code-block title language code-block="POST https:///api/v1/ingest/sources/Solar_Panel_Events/solar_panel_event
Authorization: Bearer
Content-Type: application/json
{ "data": [ {"event_id": "f47ac10b-58cc-4372-a567-0e02b2c3d479","customer_id": "003R00000123456789","battery": 75.2,"dc_current": 9.8,"dc_voltage": 35.6,"mpp_energy": 120.5,"ac_voltage": 220.1,"ac_current": 5.3,"date_time": "2023-07-07T10:15:30.05Z"} ] }»>
Nota : asegúrese de reemplazar <token de acceso a la nube de datos> y <url de instancia> con los valores respectivos que obtuvo del proceso de autenticación.
Si todo va bien, recibirás la siguiente respuesta:
Esto indica que nuestros datos han sido aceptados con éxito.
Nota : también puede validar los datos con el esquema antes de enviarlos agregando /actions/test al punto final de la API.
A granel
La ingestión masiva implica varios pasos, lo que agrega un nivel de complejidad al proceso:
- Crear un trabajo: este paso implica crear un trabajo para especificar el tipo de objeto de los datos que se procesan y la operación que se realizará, que puede ser upsert o delete.
- Cargar los datos en CSV: Después de crear el trabajo, el siguiente paso es cargar los datos en formato CSV. El archivo CSV debe contener los datos que se procesarán, con cada fila representando un registro y las columnas que contienen los valores de campo.
- Indicar la preparación de los datos: una vez que se cargan los datos, deberá indicar que los datos están listos para ser procesados.
- Cerrar o cancelar el trabajo: después de procesar los datos, puede cerrar el trabajo para marcarlo como completado o cancelar el trabajo si es necesario.
Para obtener más información sobre cómo usar los puntos de conexión masivos, puede consultar la documentación oficial .
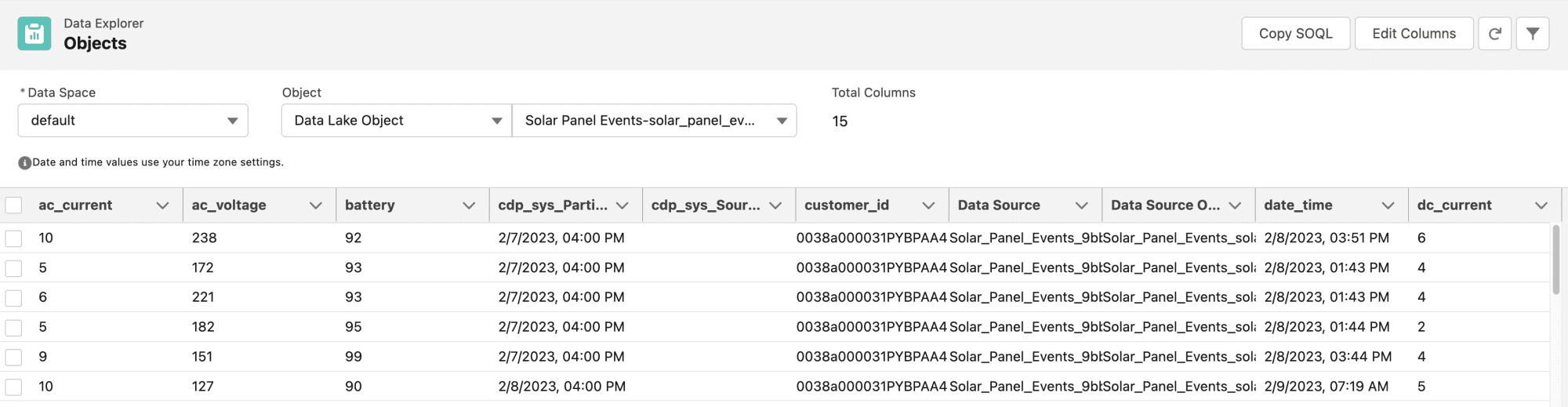
Puede consultar los datos entrantes utilizando el Explorador de datos en Data Cloud. Allí, seleccionará el objeto Data Lake correspondiente al conector de ingesta que creó anteriormente.
Si desea probarlo usted mismo, siempre puede utilizar nuestra colección Postman de desarrolladores de Salesforce, que incluye las API de Salesforce Data Cloud .
Conclusión
Ahora, está listo para comenzar a cargar datos mediante programación en Data Cloud mediante la API de ingesta. Siguiendo los pasos anteriores, puede conectarse sin problemas a varias fuentes de datos e importar datos en tiempo real o en masa, y comenzar a aprovechar el poder y la magia de Salesforce Data Cloud.
Además, si prefiere aprender de un video, mi colega Aditya ha creado un video útil que explica lo que hemos cubierto en esta publicación de blog . Asegúrese de ver también los otros excelentes videos de la serie Data Cloud Decoded .
Recursos
Sobre los autores
Julián Duque es un defensor principal de desarrolladores en Salesforce, donde se enfoca en Node.js, JavaScript y desarrollo backend. Le apasiona la educación y el intercambio de conocimientos y ha estado involucrado en la organización de comunidades tecnológicas y de desarrolladores desde 2001.
Sígalo @julianduque en Threads, @julian_duque en Twitter, @julianduque.co en Bluesky social o LinkedIn .
Aditya Naag Topalli es una defensora de desarrolladores líder certificada 14 veces en Salesforce. Capacita e inspira a los desarrolladores dentro y fuera del ecosistema de Salesforce a través de sus videos, seminarios web, publicaciones de blog y contribuciones de código abierto, y también habla con frecuencia en conferencias y eventos en todo el mundo. Sígalo en Twitter o LinkedIn y vea sus contribuciones en GitHub .