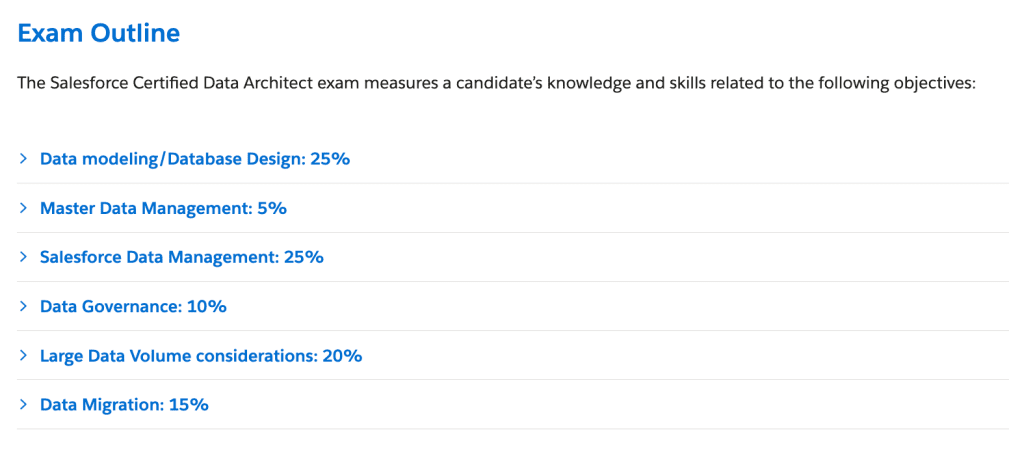
Descubra las ventajas de la comunicación asíncrona, sus aplicaciones y cómo mejora la productividad y la flexibilidad en la era digital. Descubra cómo Salesforce lo soporta.



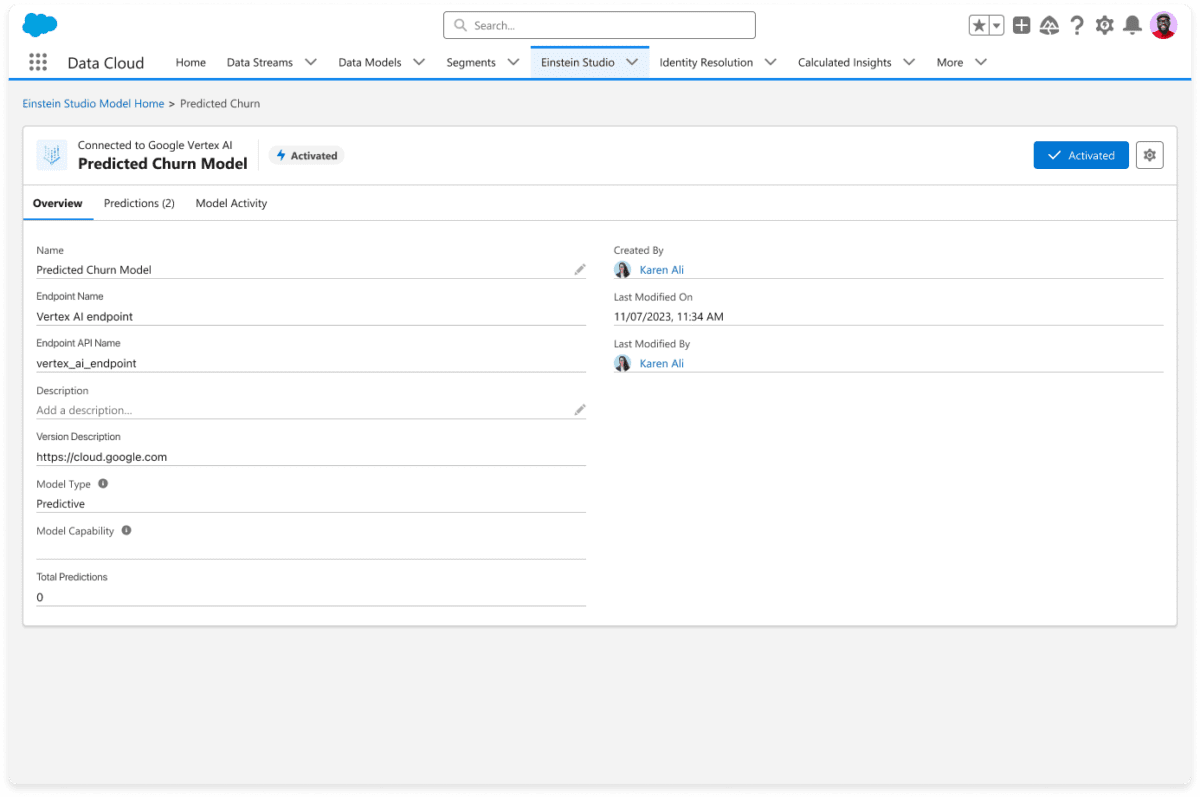
Model Builder, parte de Einstein Copilot Studio, es una plataforma fácil de usar que le permite crear y poner en funcionamiento modelos de IA en Salesforce. Model Builder es capaz de integrarse profundamente con plataformas de IA externas, como Google Cloud Vertex AI y Amazon SageMaker, para que pueda crear, entrenar e implementar modelos de IA personalizados de forma externa utilizando datos de Salesforce Data Cloud.
Salesforce anunció previamente el lanzamiento de Model Builder con Amazon SageMaker en agosto de 2023. Hoy, nos complace anunciar que los modelos de Google Vertex AI ahora están disponibles de forma general en Model Builder. Como parte de esta última versión, Model Builder ahora admite la autenticación mediante las credenciales de la cuenta del servicio de Google, así como la ingestión de datos en streaming.
Estamos entusiasmados con esta nueva innovación de la asociación ampliada de Salesforce con Google Cloud, que consideramos que tiene un enorme potencial para los desarrolladores. Como enfatizó Kaushal Kurapati, vicepresidente senior de Producto, IA y Búsqueda de Salesforce:
“Con esta asociación con Google Cloud, Model Builder ofrece una manera conveniente para que los clientes aprovechen sus modelos Vertex AI en sus fuentes de datos, flujos de trabajo y aplicaciones de Salesforce y brinden experiencias personalizadas, continuando con la visión de construir una plataforma abierta de Salesforce AI con un ecosistema modelo robusto”.
¿Qué es la capacidad de traer su propio modelo (BYOM)?
Model Builder le permite conectarse fácilmente a modelos predictivos externos, como los de un proveedor de modelos externo o su propio modelo propietario, y utilizarlos en el flujo de trabajo en Salesforce. Por ejemplo, puede utilizar modelos predictivos para calificar clientes potenciales, recomendar productos o detectar la deserción.
La capacidad BYOM de Model Builder le permite integrar fácilmente su modelo con Data Cloud para acceder a predicciones e información en tiempo real, y utilizar esa información de varias maneras, como enriquecer perfiles de clientes, crear segmentos y personalizar la experiencia del usuario final en diferentes canales.
¿Por qué traer su propio modelo a Data Cloud?
Estos son algunos de los beneficios de usar un modelo de Google Cloud Vertex AI con datos de Data Cloud en Model Builder:
- Le brinda acceso a datos altamente seleccionados, armonizados y casi en tiempo real en Customer 360, en Vertex AI
- Elimina trabajos de ETL tediosos, costosos y propensos a errores; El enfoque de federación de copia cero para los datos reduce los gastos generales de gestión de copias de datos y los costos de almacenamiento, y mejora la eficiencia.
- Le permite crear, entrenar, probar y ajustar modelos rápidamente en una única plataforma y conectarlos con Data Cloud.
- Admite la ingesta de datos en tiempo real, streaming y por lotes para impulsar resultados de IA relevantes
- Aprovecha las predicciones de Vertex AI para automatizar procesos comerciales en Salesforce Data Cloud con Flow y Apex
Para obtener más información, mire nuestro breve vídeo .
Flujo de trabajo de la aplicación para usar Model Builder con Vertex AI de Google Cloud
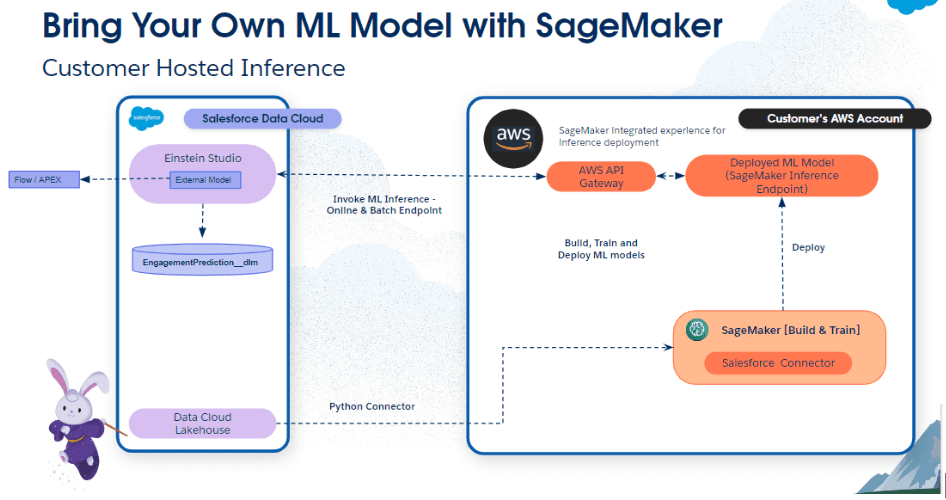
En esta sección, analizamos brevemente el flujo de trabajo de la aplicación utilizando Model Builder.
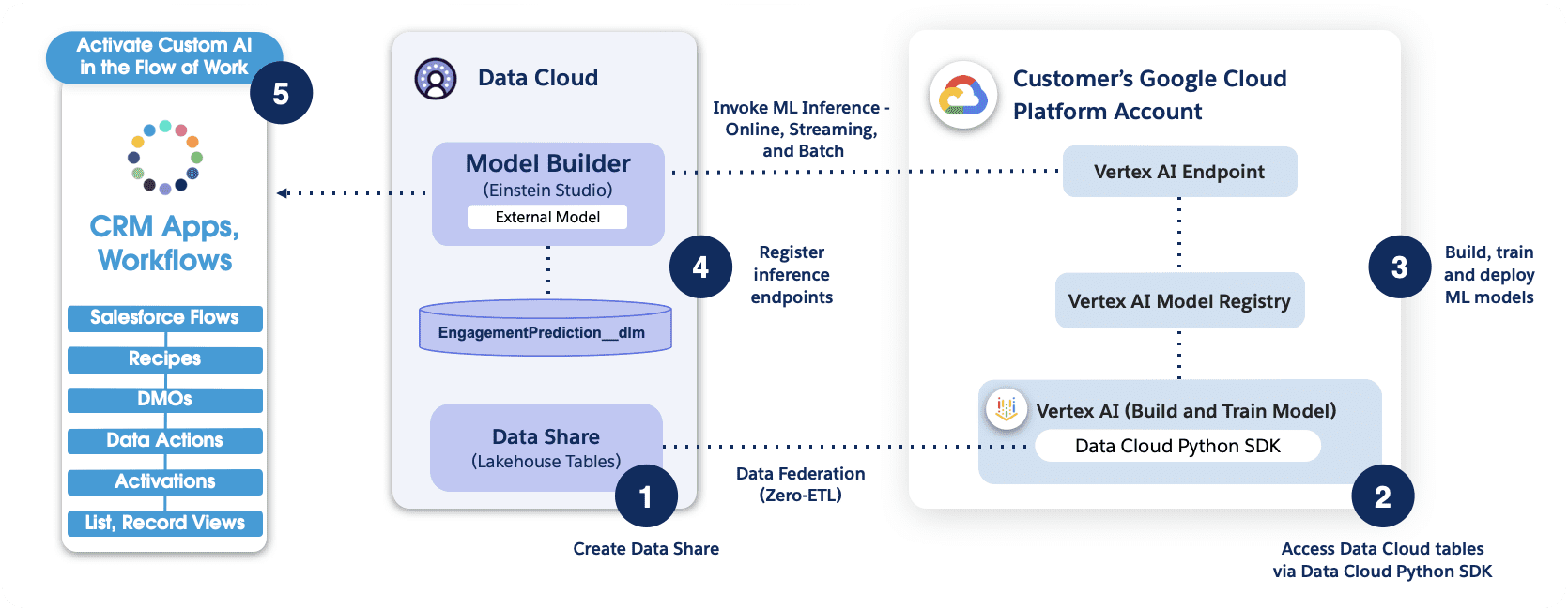
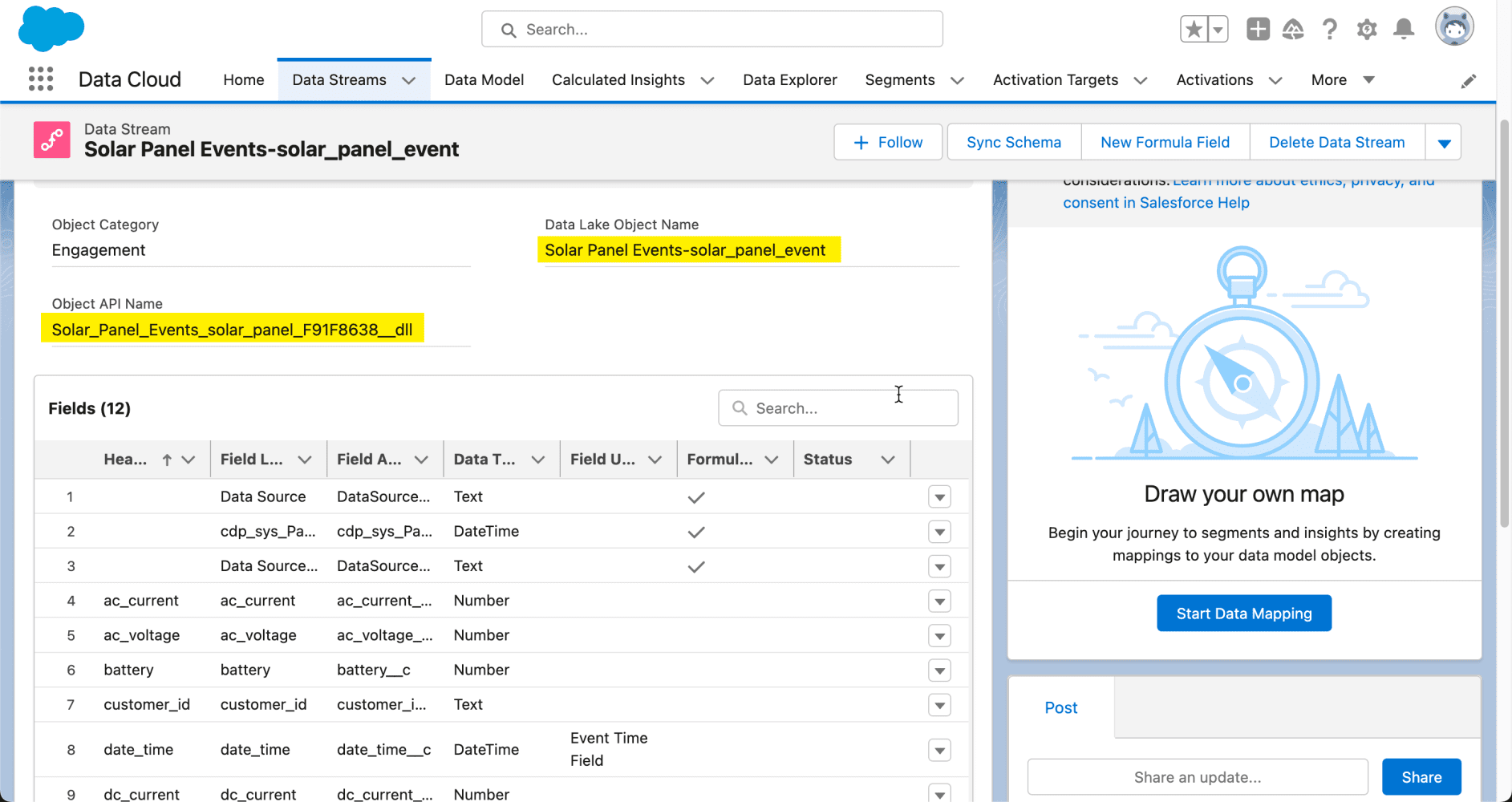
En el flujo de trabajo que se muestra arriba, el conector Python brinda a Vertex AI acceso seguro a los objetos de Salesforce Data Cloud. Después de la autenticación, los especialistas en datos pueden explorar y preparar datos, y realizar tareas de ingeniería de características para el desarrollo y la inferencia de modelos de IA utilizando la plataforma Vertex AI.
Tenga en cuenta que si se realiza una autenticación basada en clave API, se necesita una puerta de enlace API delante del punto final de Vertex AI.
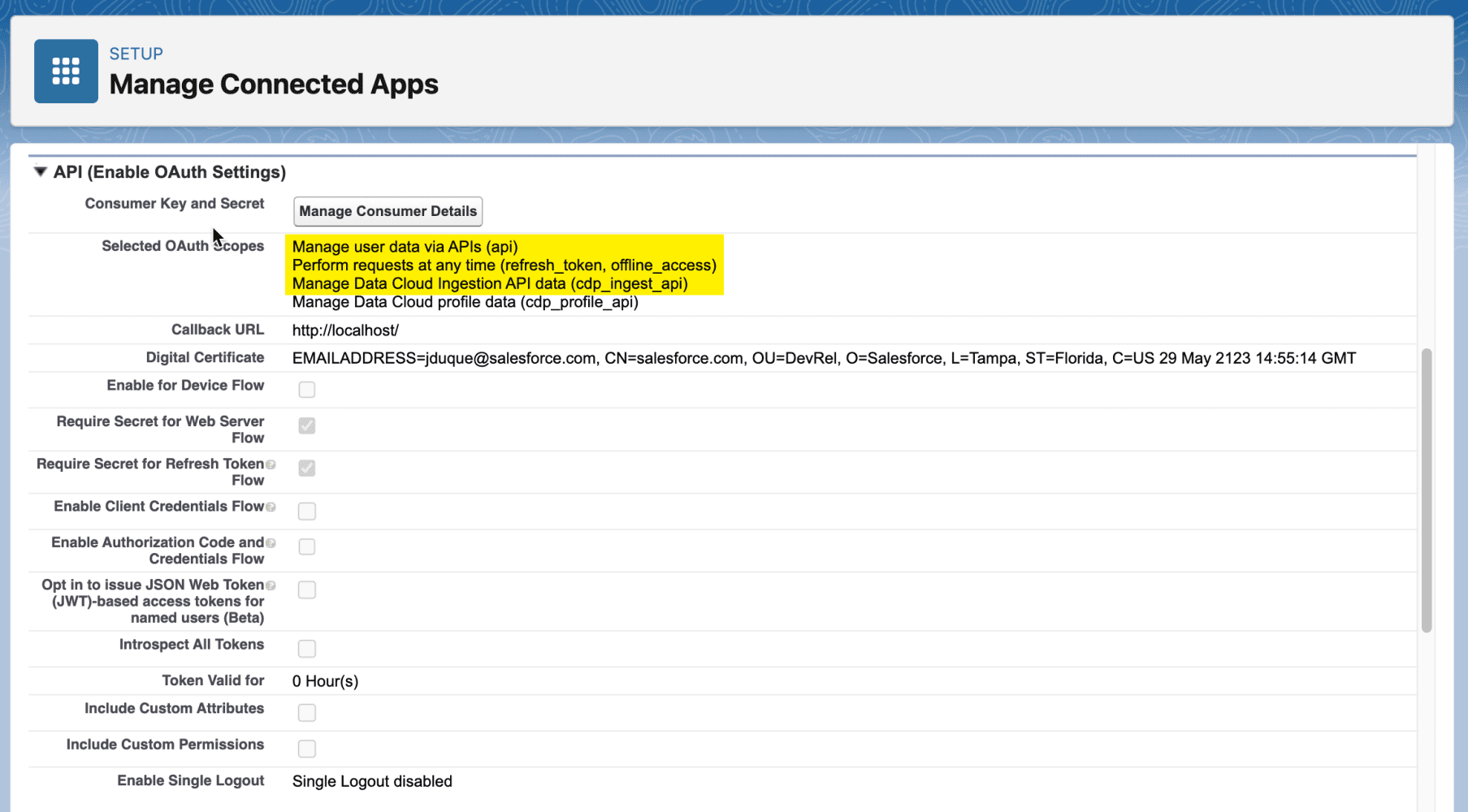
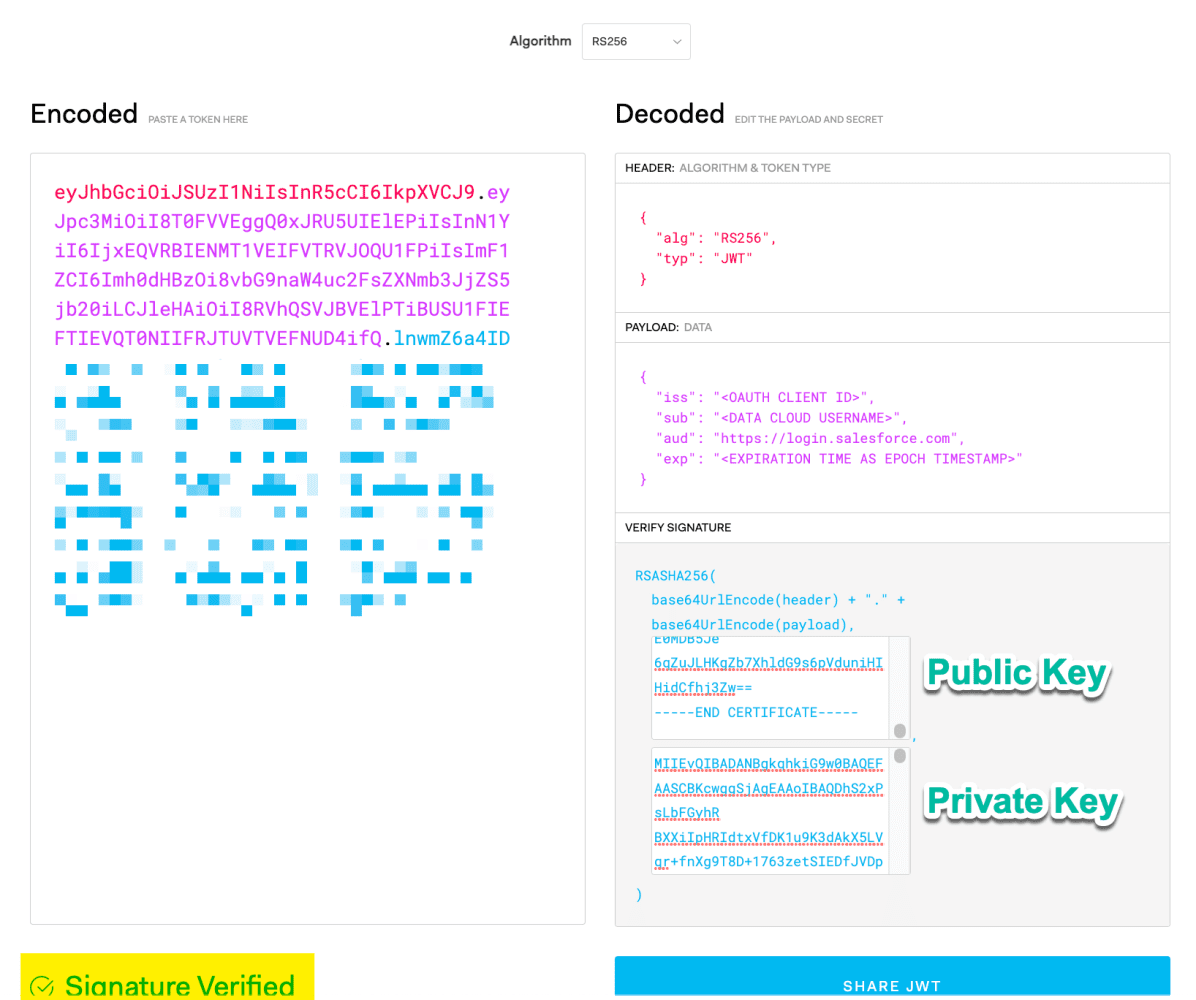
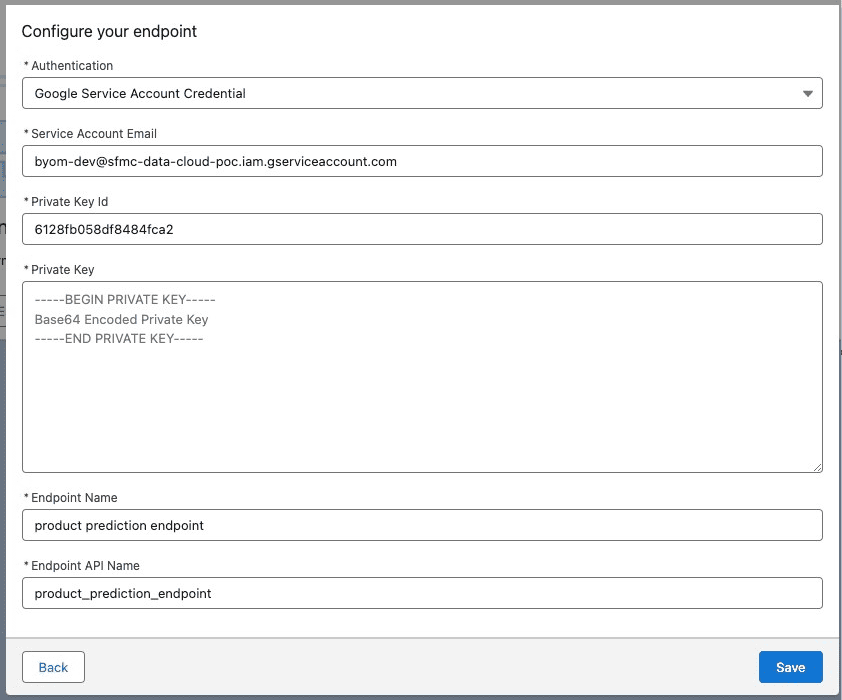
NUEVA característica: Autenticación mediante credenciales de cuenta de servicio de Google
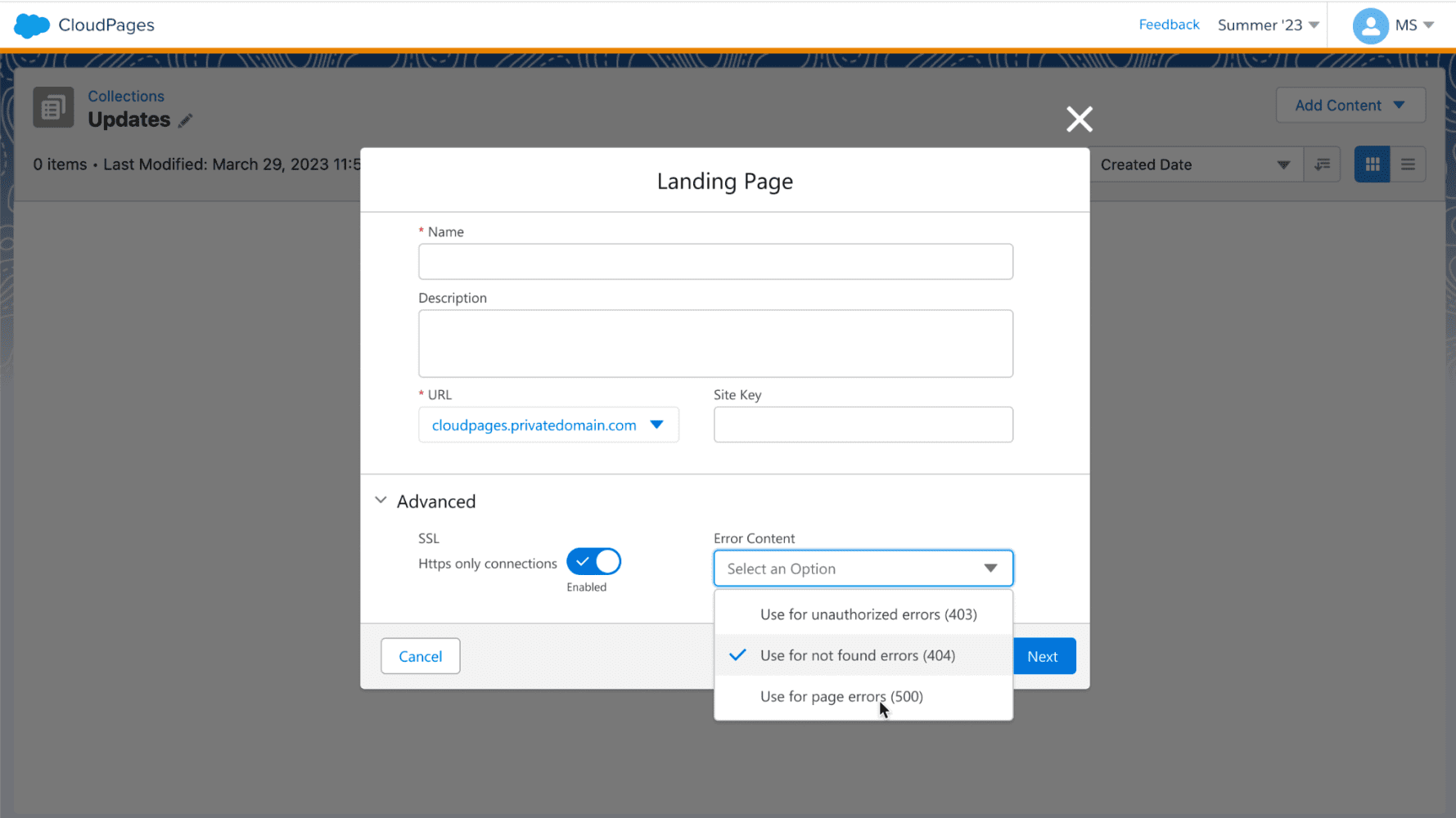
La versión más reciente de Model Builder ahora permite utilizar las credenciales de la cuenta del servicio de Google para la autenticación. Esto se suma a los métodos de autenticación JWT y basados en claves existentes. Para utilizar un flujo de token al portador JWT, ingrese su correo electrónico de la cuenta de servicio, ID de clave privada y clave privada de su cuenta de Google Cloud como se muestra a continuación.
NUEVA característica: Ingestión de datos en streaming
La última versión de Model Builder le permite activar automáticamente una inferencia cuando los datos asignados a la variable de entrada del modelo se cambian en el objeto del modelo de datos de origen (DMO). También ofrecemos inferencia por lotes, pero debe hacer clic en el botón Actualizar manualmente para activar nuevas inferencias. Con la inferencia de transmisión, las nuevas inferencias se activan solo cuando hay un cambio en la variable de entrada.
Para habilitar la inferencia de transmisión, deberá marcar la casilla Sí en ¿Actualizar modelo cuando se actualizan los datos? Como se muestra abajo.
También puede especificar cuáles de las funciones de entrada deben actualizarse seleccionando Sí en el menú desplegable Actualizar puntuación .
Cómo consumir predicciones de tu modelo en Salesforce
Hay dos formas de consumir predicciones: usar acciones invocables en Flow y Apex, o usar Query API para realizar análisis ad hoc.
Utilice Flow Builder y Apex para obtener predicciones
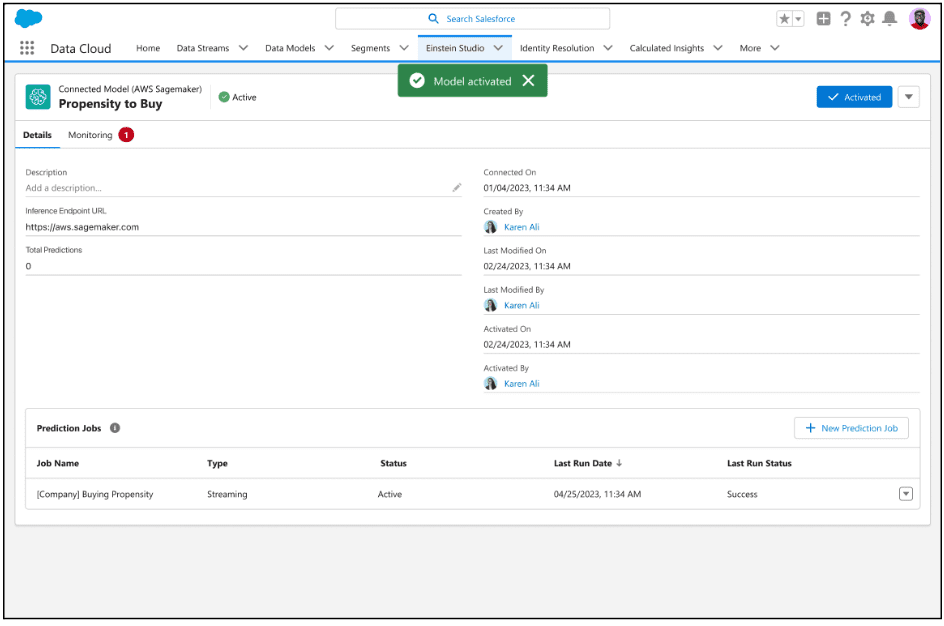
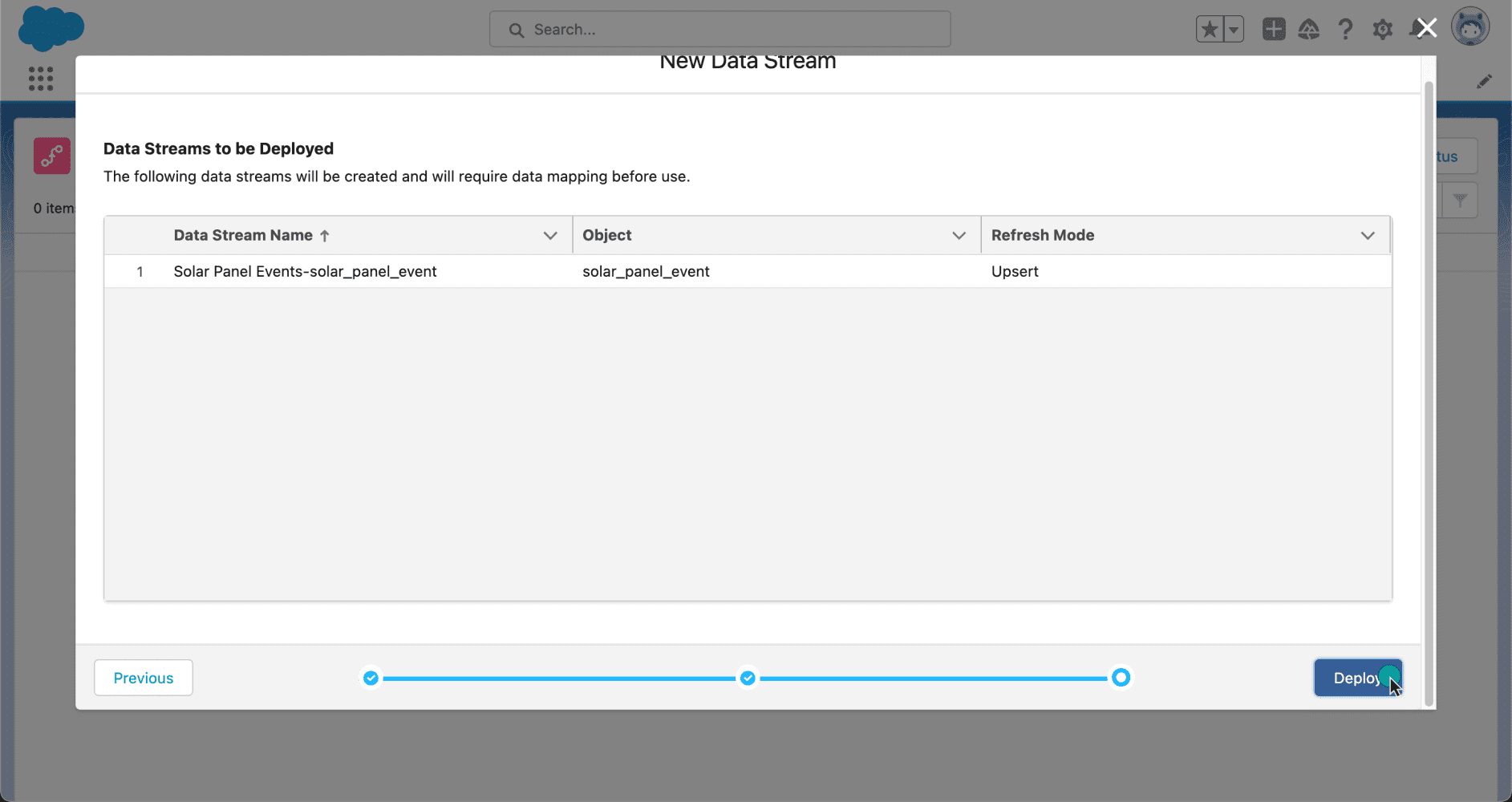
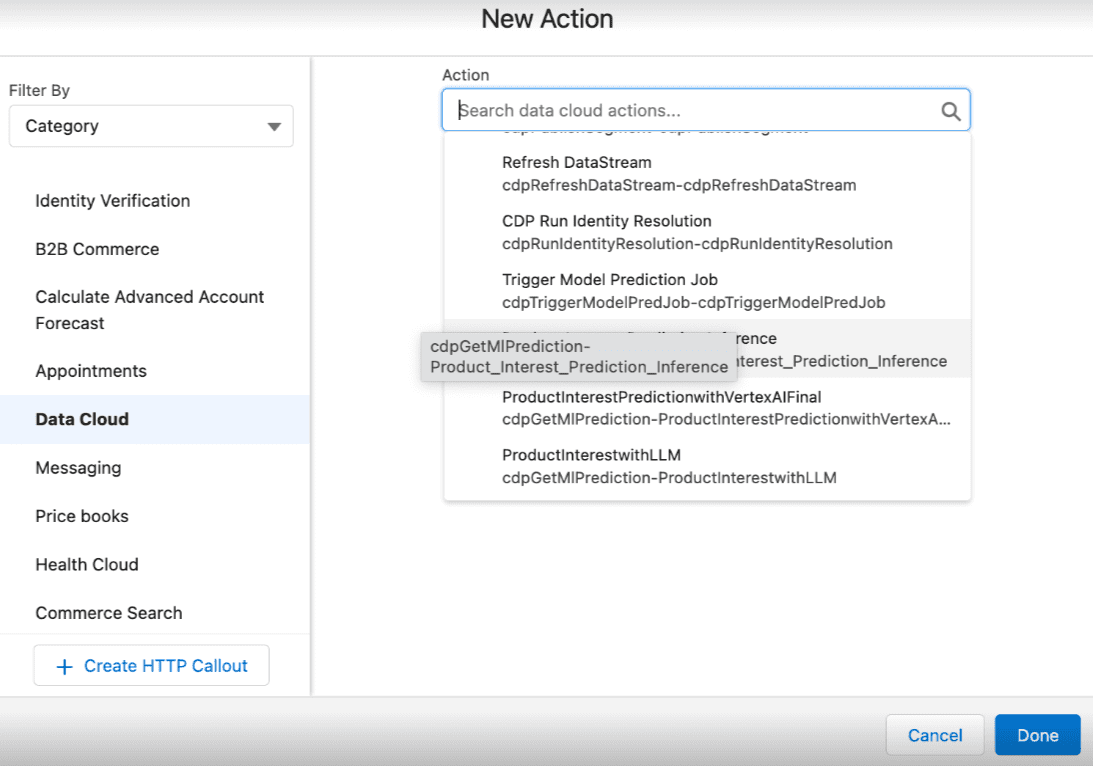
A continuación se muestra un ejemplo de cómo utilizar acciones invocables para modelos de Model Builder en Flow. Una vez que tenga un modelo activado en Model Builder, seleccione Nueva acción → Nube de datos y luego haga clic en el nombre del modelo deseado.
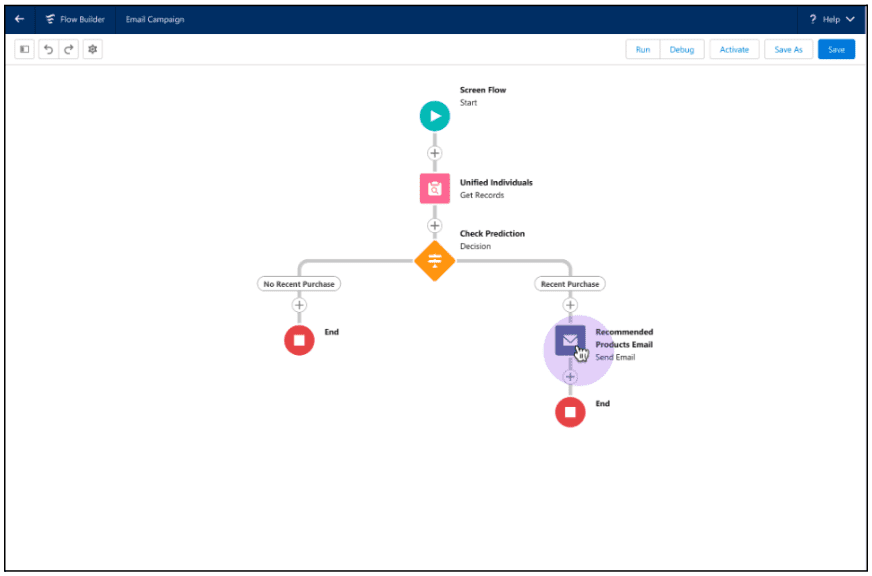
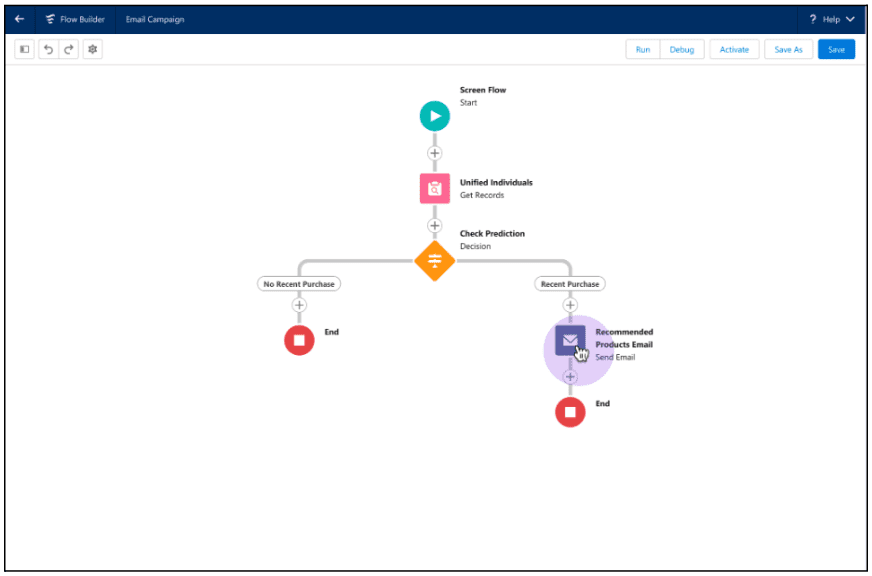
La captura de pantalla siguiente muestra un flujo de ejemplo que utiliza una acción invocable para crear recomendaciones de productos para un cliente. Aquí, un administrador usa Flow Builder para recorrer los registros individuales unificados y verificar si se realizó una compra reciente. Si se realizó la compra, la acción invocable obtiene la inferencia del modelo de Model Builder y recomienda el siguiente mejor producto a un cliente.
Esta acción invocable también se puede invocar en Apex. Vea el ejemplo a continuación.
<dx-code-block title language="apex" code-block="Invocable.Action action = Invocable.Action.createCustomAction('cdpGetMlPrediction', 'EinsteinStudio_model_name');
action.setInvocationParameter('param_variable_1', '10');
action.setInvocationParameter('param_variable_2', '20');
action.setInvocationParameter('param_variable_3', '30');
List results = action.invoke();
if (results.size() > 0 && results[0].isSuccess()) { System.debug(‘Result is: ‘ + results[0].getOutputParameters().get(‘param_score’));
} else { System.debug(‘Error message’ + results[0].getErrors());
} «>
Para obtener instrucciones sobre el uso de acciones invocables en Flow y Apex, consulte la Ayuda de Salesforce .
Utilice Query API para obtener predicciones
Query API es otra forma rápida de obtener puntuaciones de predicción para datos que residen en Data Cloud. Con Query API, puede utilizar el punto final de inferencia y llamar a funciones de predicción para probar el punto final. Vea el ejemplo a continuación.
Para obtener instrucciones sobre el uso de acciones invocables en QueryAPI, consulte la Ayuda de Salesforce .
Conclusión
Model Builder es una plataforma de IA fácil de usar que permite a los equipos de ingeniería y ciencia de datos crear, entrenar e implementar modelos de IA utilizando plataformas y datos externos en Data Cloud. Las plataformas externas incluyen Google Cloud Vertex AI, Amazon SageMaker y otros servicios de IA predictivos o generativos. Una vez que esté listo, podrá utilizar los modelos de IA en tiempo real para impulsar cualquier aplicación de ventas, servicios, marketing, comercio y otras aplicaciones en Salesforce.
Para obtener más información sobre cómo puede mejorar su estrategia de IA utilizando Model Builder, asista a nuestro seminario web gratuito con expertos en IA de Salesforce y Google Cloud.
Recursos adicionales
Sobre los autores
Daryl Martis es el director de producto de Salesforce de Einstein. Tiene más de 10 años de experiencia en planificación, creación, lanzamiento y gestión de soluciones de clase mundial para clientes empresariales, incluidas AI/ML y soluciones en la nube. Síguelo en LinkedIn o Twitter .
Ashish Thapliyal es director sénior de producto en Salesforce y actualmente dirige varias áreas de productos de la plataforma Einstein AI. Síguelo en LinkedIn o Twitter .
Obtenga las últimas publicaciones de blog y episodios de podcasts para desarrolladores de Salesforce a través de Slack o RSS.
Añadir a holgura Suscríbete a RSS