Apex es una habilidad única que los desarrolladores deben dominar al crear soluciones personalizadas con Salesforce. Hay algunos conceptos básicos que son esenciales. Ciertas cosas, como la sintaxis y el flujo de control, son como aprender cualquier otro idioma. Otras cosas, como operaciones masivas, límites reguladores y disparadores, son particulares de Apex y cómo se implementa en la Plataforma de Salesforce. Una vez que tenga una idea de estas características y modismos clave, ¿a dónde va después?
En esta publicación, aprenderá sobre algunas características de Apex que son críticas para cualquier desarrollador de Apex que busque mejorar más allá de lo básico, junto con dónde puede ir para aprender sobre ellas.
Nota: Siempre que sea posible, los ejemplos de código en esta publicación se toman directamente o se adaptan de la aplicación de muestra Recetas de Apex o la Guía para desarrolladores de Apex. Ver las referencias al final del artículo.
En estos días, si desea un proceso automatizado o una interfaz de usuario similar a un asistente, Flow siempre debe ser una opción que considere. El alcance, la flexibilidad y la madurez de Flow han crecido enormemente. Aún así, es raro que los problemas comerciales complejos se puedan resolver sin ningún tipo de código.
Introduzca Apex invocable.
La anotación @InvocableMethod se usa para definir métodos llamados por Flow. Y @InvocableVariable muestra los parámetros para que Flow pase datos a su código Apex. ¿Por qué llamaría a Apex desde Flow? Quizás la lógica de su flujo se está volviendo demasiado compleja. Tal vez su automatización necesite realizar una operación que no sea accesible para Flow. En casos como estos, Apex puede ser su amigo.
Aquí hay una ilustración básica del uso de la anotación @InvocableMethod :
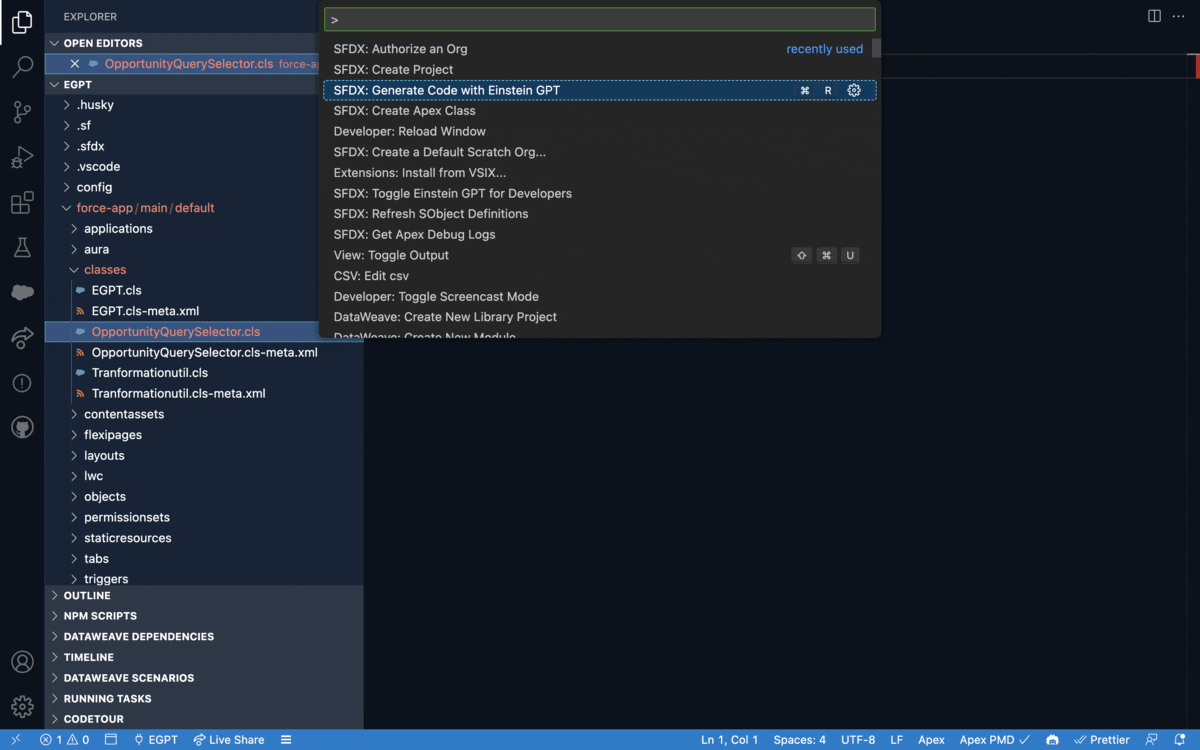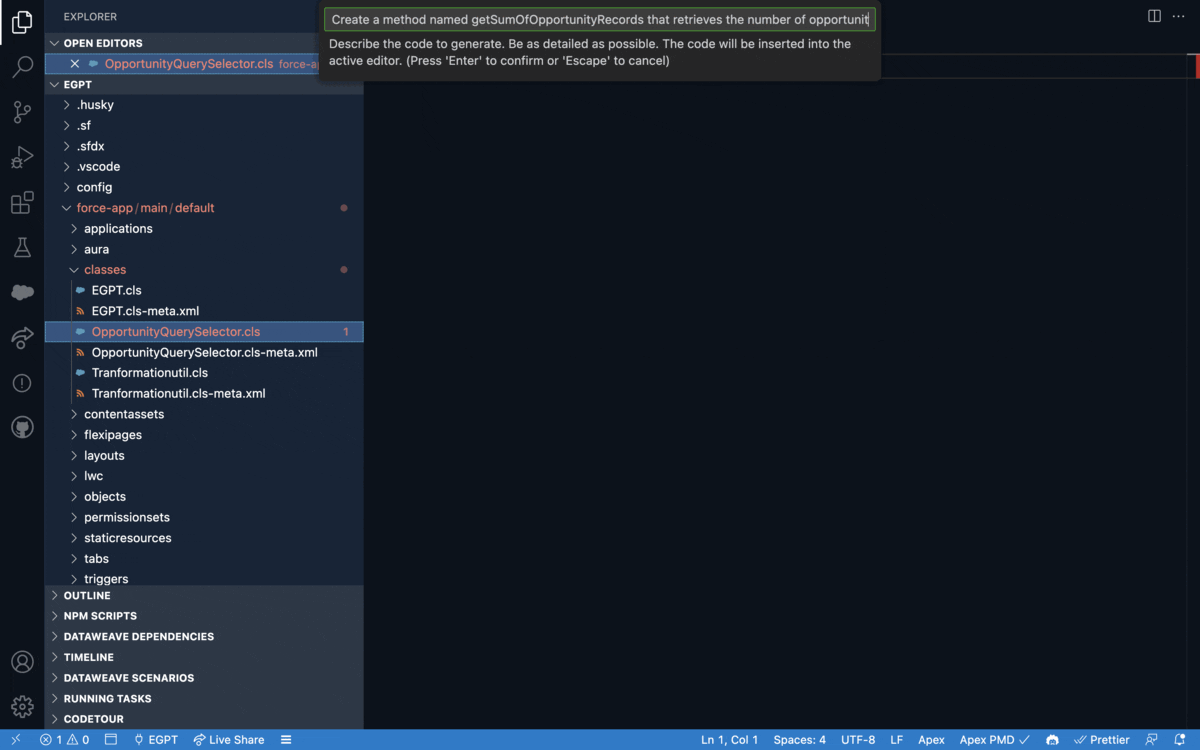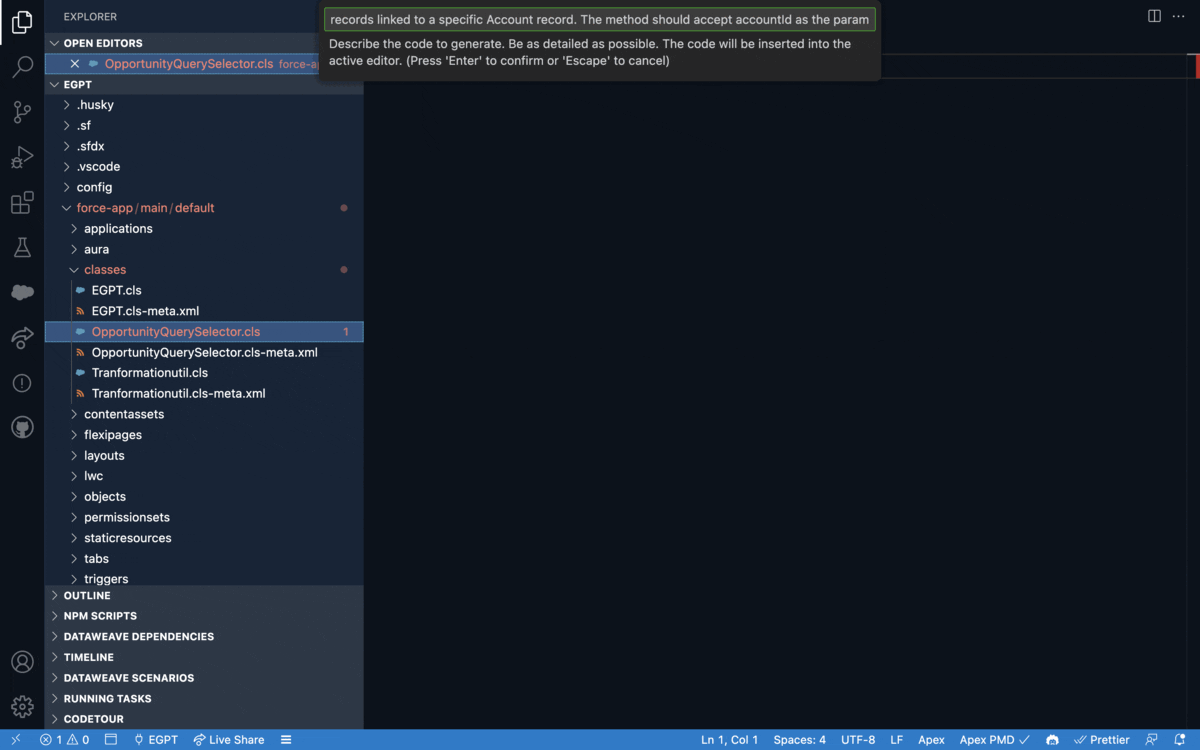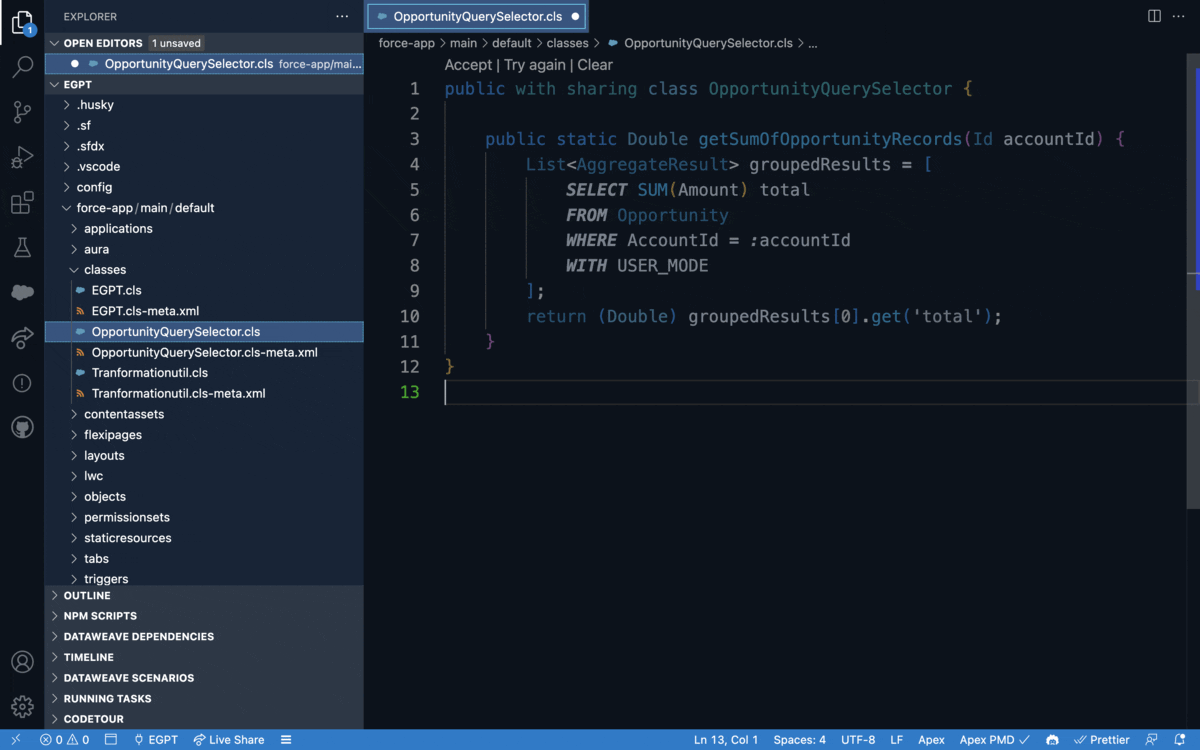
<dx-code-block title language="java" code-block="public class AccountQueryAction { @InvocableMethod(label='Get Account Names' description='Returns the list of account names corresponding to the specified account IDs.' category='Account') public static List getAccountNames(List ids) { List accountNames = new List(); List accounts = [SELECT Name FROM Account WHERE Id in :ids]; for (Account account : accounts) { accountNames.add(account.Name); } return accountNames; } }»>
Este ejemplo de la Guía para desarrolladores de Apex ilustra cómo la anotación marca esto como un método que Flow puede invocar. Tenga en cuenta que la anotación también define detalles como una etiqueta y una descripción que determinan lo que se muestra al usuario de Flow Builder.
Un efecto secundario importante de las anotaciones de @Invocable… del que pocas personas hablan es que esto muestra automáticamente su Apex al punto final de la API <INSTANCEURL>/data/<VERSION>/actions/custom/apex .
Otra cosa útil que puede hacer al invocar Apex desde su flujo es acceder a los diferentes tipos de Apex asíncrono. Lo que trae a colación la siguiente característica de Apex que se debe abordar.
La ejecución asíncrona desacopla una acción que queremos realizar del contexto de ejecución actual. Siguiendo las mejores prácticas actuales, existen tres formas de ejecutar Apex de forma asincrónica: en cola, programable y por lotes. Aunque técnicamente el bus de eventos es asíncrono, lo omitiremos por el momento.
Si solo necesita activar un poco de código para ejecutarlo de forma asincrónica, la opción en cola es la herramienta de referencia. Si tiene varias tareas asincrónicas, queueable las ejecuta de manera determinista en orden. Debido a que están en cola en orden, también puede encadenar una llamada asíncrona de otra. Y Apex en cola admite entradas de objetos o tipos primitivos.
Apex programado funciona tal como lo esperaría: ejecute algún código de Apex en un horario. Batch Apex está optimizado para trabajar con conjuntos de datos muy grandes. Para utilizar Apex asíncrono, debe crear una clase de Apex que implemente una interfaz específica: Queueable , Schedulable o Batchable , respectivamente.
Nota: algunos desarrolladores pueden estar familiarizados con la anotación @Future para hacer que un solo método sea asincrónico, también conocido como "métodos futuros". Los métodos futuros, aunque rápidos y fáciles, tienen limitaciones que los hacen menos útiles. No hay nada que pueda hacer con un método futuro que no se pueda hacer mejor con una clase en cola. Por este motivo, no recomendamos implementaciones de producción con métodos futuros.
Por lo tanto, echemos un vistazo a un ejemplo de una clase de Apex que se puede poner en cola.
<dx-code-block title language="Java" code-block="public with sharing class QueueableRecipes implements Queueable { public static void execute(QueueableContext qc) { List accounts = [ SELECT Id, Description FROM Account LIMIT 1000 ]; for (Account acct : accounts) { acct.Description += ‘ Edited by Queueable class’; } try { update accounts; } catch (DmlException dmle) { System.debug( LoggingLevel.INFO, ‘real life use cases should do more than just logging the error: ‘ + dmle.getMessage() ); } }
} «>
Todas las interfaces asíncronas de Apex tienen un método execute() que debe implementarse como se muestra arriba. Para ejecutar su clase Queueable , debe ponerla en cola.
Si bien no se muestra en este ejemplo de la aplicación de muestra Recetas de Apex, para pasar datos a su cola, anule el constructor con los parámetros que necesita.
El término "Apex dinámico" es un poco inapropiado. O, al menos, podría malinterpretarse como que Apex de alguna manera funciona como un lenguaje de programación dinámico. Esto no es a lo que se refiere (por ejemplo, no hay Apex
función eval !).
Dynamic Apex es un código que se adapta a diferentes tipos de SObject ( Account , Contact , My_Custom_Object__c , etc.) en tiempo de ejecución. Esto se hace abstrayendo referencias específicas de SObject. La clave es usar la superclase SObject cuando se trabaja con datos. También utilizará las funciones de "descripción" de Apex para detectar con qué objetos y campos está trabajando y qué puede hacer con ellos (por ejemplo, si este usuario puede consultar este objeto).
Esta es una habilidad esencial para los desarrolladores de ISV. A menudo, creará una aplicación que debe adaptarse al entorno local del cliente que instala su aplicación. Esto significa que su código necesita detectar, describir y adaptar su comportamiento dependiendo de datos conocidos o incluso desconocidos.
Aunque es esencial para un desarrollador de ISV, también es importante para cualquier persona que quiera escribir código más reutilizable.
Tome este ejemplo de consulta muy básico:
<dx-code-block title language="Java" code-block="List accts = [SELECT Id, Name, Website FROM Account];»>
Esto funcionará todo el día consultando los datos de la cuenta. Pero, ¿y si queremos construir una consulta para cualquier SObject?
Para convertir esto en un Apex "dinámico", necesitamos abstraer las referencias de campo y SObject específicas. Y tal vez lo incluiríamos en un método que permitiera a otro desarrollador pasarlos. También podríamos verificar para asegurarnos de que el usuario tenga los permisos de objeto para realizar la operación que estamos a punto de intentar.
<dx-code-block title language="Java" code-block="public static List executeDynamicQuery(Schema.DescribeSObjectResult obj, List fields){ // Create a result-set list List resultRecords; if (obj.isQueryable()){ // Set up a query string String queryTemplate = ‘SELECT {0} FROM {1}’; List queryDetails = new List{String.join(fields, ‘, ‘), obj.getName()}; String queryString = String.format(queryTemplate, queryDetails); // Run your query resultRecords = Database.query(queryString); } return resultRecords; } «>
Lo anterior construye una consulta para un SObject que se pasa al método y una lista arbitraria de campos. Utiliza el objeto DescribeSObjectResult para detectar la capacidad de consulta e inferir el nombre de la API de SObject al construir y ejecutar la consulta. A continuación, debe invocarlo.
Así es como podríamos hacer eso con los objetos Cuenta y Contacto, respectivamente:
<dx-code-block title language="Java" code-block="List accountRecords = DynamicApexClass.dynamicQuery(Account.SObjectType.getDescribe(), new List{‘Id’,’Name’,’Website’}); List contactRecords = DynamicApexClass.dynamicQuery(Contact.SObjectType.getDescribe(), new List{‘Id’,’FirstName’,’LastName’}); «>
Este ejemplo no aborda algunos riesgos de SOQL dinámico, como la inyección de SOQL. Por lo tanto, asegúrese de leer sobre Apex dinámico. Aprender a escribir Apex seguro hará que sea menos probable que implemente código vulnerable en su organización (o la de un cliente). El enlace de variables en sus consultas SOQL es una herramienta clave para proteger su Apex dinámico de ser explotado. El método escapeSingleQuotes() es otra herramienta más antigua que también puede encontrar. El modo de usuario también es clave para garantizar que cualquier acción realizada tenga que cumplir con todas y cada una de las restricciones del usuario que la ejecuta.
Para obtener un ejemplo más completo y seguro de Apex dinámico, consulte la receta de Apex del método invocable en la aplicación de ejemplo Recetas de Apex. Esa acción invocable funciona con el objeto Cuenta o Tarea.
Con Salesforce, hay algunas formas de realizar la integración sin código. Específicamente, si solo necesita una aplicación o servicio de cliente para obtener datos de Salesforce, hay muchas API que se muestran automáticamente sin ningún tipo de codificación en el lado de Salesforce. Incluso se ajustan a su esquema personalizado. Si está integrando su organización a un sistema externo compatible con OData, puede usar Salesforce Connect y objetos externos (nuevamente, no se requiere código).
Pero a veces, es posible que deba llamar desde su organización a un servicio externo. O tal vez desee mostrar un punto final personalizado que agrupe más complejidad que una de las API estándar. Nuevamente, Apex contiene funciones que admiten tanto la aparición de nuevas API personalizadas como la llamada a servicios web.
Al pensar en API personalizadas, en estos días, la mayoría de los desarrolladores pensarían en API REST. Puede crear una API REST personalizada en Salesforce Platform creando una clase de Apex que se anota con la anotación @RestResource . Parte del trabajo de la anotación es definir también el nombre del recurso. Todas las API REST personalizadas basadas en Apex se encuentran en <INSTANCEURL>/services/apexrest/ .
Para definir los comportamientos que necesita admitir, hay una serie de anotaciones de métodos que corresponden a verbos HTTP, como @HttpGet y @HttpPost . La clase RestContext contiene un conjunto de elementos de acceso para obtener el estado de la solicitud HTTP entrante y la respuesta saliente que devuelve. A continuación, se muestra un ejemplo de un extremo REST básico que aparece en el método HTTP GET. Tenga en cuenta cómo se utilizan las anotaciones.
<dx-code-block title language="Java" code-block="@RestResource(urlmapping='/integration-service/*')
global inherited sharing class CustomRestEndpointRecipes( … @HttpGet global static String getRecordsToReturn() { RestResponse response = RestContext.response; try { List accounts = [ SELECT Id, Name, Phone, Website FROM Account WITH USER_MODE ]; response.statusCode = 200; String serializedAccounts = JSON.serialize(accounts); return serializedAccounts; } catch (QueryException qe) { System.debug( LoggingLevel.INFO, ‘Failed to query a list of Accounts. Error is: ‘ + qe.getMessage() ); response.statusCode = 400; return qe.getMessage(); } }
} «>
Si su requisito es crear un servicio SOAP, también hay un conjunto de características para admitir ese protocolo.
Fuera del código real, necesitará una sesión autorizada para acceder a cualquier servicio web que cree. Pero si ya tiene un cliente autorizado, la solicitud es solo otra llamada al punto final personalizado que defina.
La llamada a un punto final REST externo se realiza a través de un conjunto de clases. La clase HttpRequest le permite definir los parámetros de cómo se comportará su solicitud (punto final, verbo HTTP, encabezados, etc.). La solicitud se realiza a través del método estático Http.request() . Esto devuelve un objeto HttpResponse que le proporciona los datos devueltos o el error si la solicitud falla.
Nota: Las clases HttpRequest y HttpResponse son las mismas para las llamadas REST y los servicios REST personalizados.
Se requiere cierta configuración para su texto destacado. Específicamente, deberá configurar una credencial con nombre en la mayoría de los casos. Esta configuración le permite descargar el protocolo de enlace de autenticación de su código. Aunque, si está llamando a un servicio anónimo no autenticado, también puede optar por usar una configuración de sitio remoto más simple.
= 200 && response.getStatusCode()
El ejemplo anterior hace una llamada simple a un punto final. Tenga en cuenta que no se utilizan las opciones para establecer encabezados ni usar una credencial con nombre, ya que esta solicitud es para una API simple que no requiere autenticación.
La transmisión de eventos es una herramienta valiosa para crear arquitecturas débilmente acopladas en aplicaciones complejas. La plataforma de Salesforce implementa la transmisión de eventos a través de dos características principales: eventos de plataforma y captura de datos modificados. La columna vertebral de estas funciones es el bus de eventos.
De la Guía para desarrolladores de eventos de plataforma, el bus de eventos es "Un servicio de entrega y almacenamiento de eventos de múltiples inquilinos y múltiples nubes basado en un modelo de publicación-suscripción". Tanto su organización como los sistemas externos pueden publicar y suscribirse a eventos. Por supuesto, es clave que si publicas un mensaje, algo debe haberse suscrito para que suceda cualquier otra cosa.
Los eventos de plataforma representan los datos que pasan a través del bus de eventos. Los eventos se procesan en el orden en que se reciben. Una forma de pensar en ellos es como un SObject efímero que se almacena temporalmente en el bus de eventos en su camino hacia su destino. De hecho, los metadatos de un evento se almacenan en el mismo lugar de su proyecto que sus SObjects. Puede distinguir los eventos de plataforma personalizados de los SObjects por su sufijo __e (por ejemplo Order_Complete__e ).

Una vez que completa un evento con sus datos, el método EventBus.publish() es similar a una llamada DML en su SObject normal. Tenga en cuenta el código a continuación que publica un evento.
En Apex, se suscribe a un evento creando un disparador asíncrono para él. Pero los disparadores asíncronos son diferentes de la operación DML transaccional estándar de un disparador normal. Por esta razón, debe tener en cuenta algunas diferencias. Con disparadores asíncronos, el tamaño del lote es diferente. Necesitas configurar tu usuario de ejecución. Las operaciones de activación de eventos también se pueden volver a intentar. Asegúrese de conocer estas diferencias a medida que comience a implementar activadores de eventos de plataforma. Tenga en cuenta el disparador a continuación.
A diferencia de los disparadores DML típicos, los disparadores de eventos de plataforma solo admiten el contexto after insert . Tampoco existe una acción explícita para suscribir un disparador a un evento de plataforma. Una vez que el activador se implementa en su organización, se suscribe automáticamente.
Además de Apex, los eventos de la plataforma pueden activarse y suscribirse mediante sistemas externos y Flow. Son clave en las integraciones débilmente acopladas. Como tal, es raro que Apex active y se suscriba al mismo evento.
Hemos cubierto mucho. Pero de ninguna manera esto es todo lo que necesita saber como desarrollador de Apex. Los elementos cubiertos se basan en algunas características bastante comunes. Pero es posible que deba aprender otras funciones de Apex según los requisitos de su proyecto. Aquí hay algunos otros elementos que debe tener en cuenta.
Caché de plataforma : si proviene de otras plataformas de programación, estará familiarizado con la noción de una variable estática o global persistente en todas las transacciones. Pero en Apex, las estáticas se limitan a la transacción. La memoria caché de la plataforma es una característica de Apex que permite la persistencia de datos en memoria entre transacciones. Si encuentra un retraso en el rendimiento relacionado con la recuperación de datos, la memoria caché de la plataforma puede ayudar.
Marcos de activación : no es una característica del lenguaje, sino bibliotecas que facilitan el uso de activadores. Estos proyectos creados por la comunidad abstraen el código de activación repetitivo que a menudo necesita escribir. Al usar un marco de activación, debería permitirle concentrarse solo en la lógica que debe abordarse. Para algo más que un disparador trivial, se recomienda encarecidamente adoptar un marco. Y conozco a algunos que argumentarían que debería considerar un marco incluso para ese disparador trivial. Pero este no es el lugar para debatir el tiempo de valor frente a la optimización prematura. Hay una implementación muy simple de esto en la aplicación Apex Recipes .
SOSL : el lenguaje de búsqueda de objetos de Salesforce ( SOSL ) es el primo subestimado de SOQL. SOSL permite consultas basadas en texto no deterministas. Es muy eficiente para encontrar datos de texto en comparación con la búsqueda de campos de texto con SOQL y comodines. Admite la búsqueda de varios SObjects simultáneamente y contiene funciones para filtrar de forma determinista los resultados de la búsqueda. Si tiene consultas SOQL de texto que son lentas, definitivamente consulte esta herramienta.
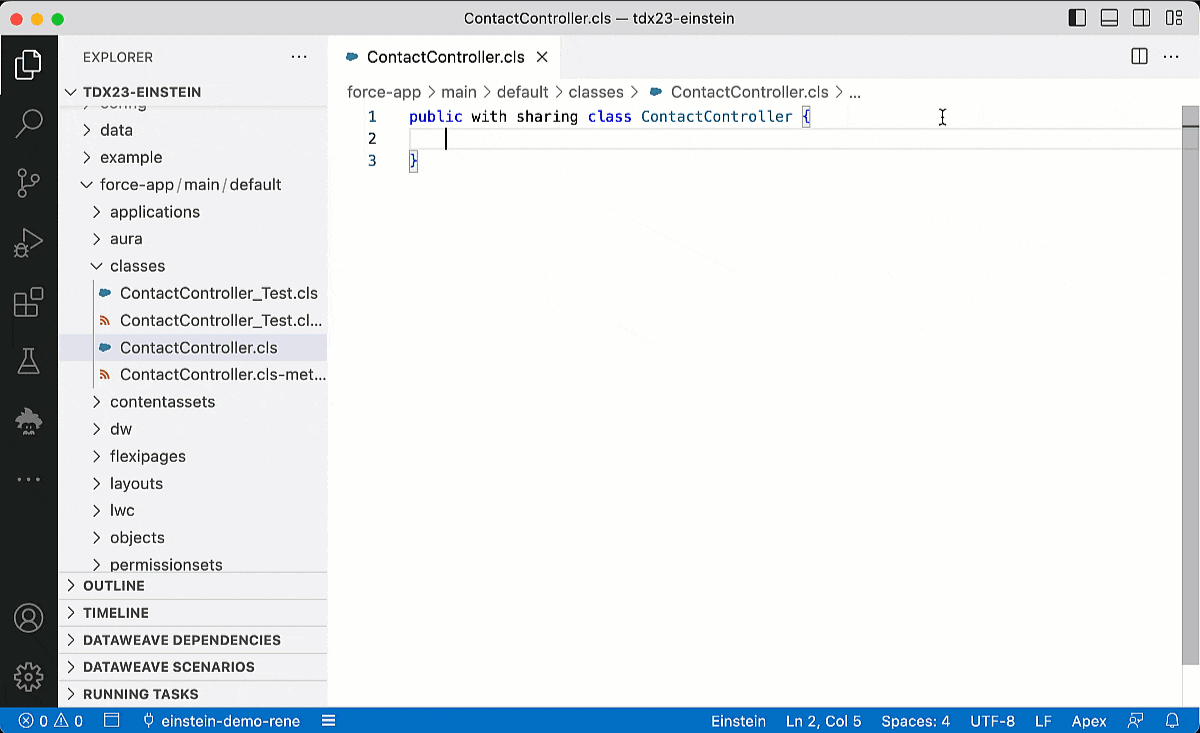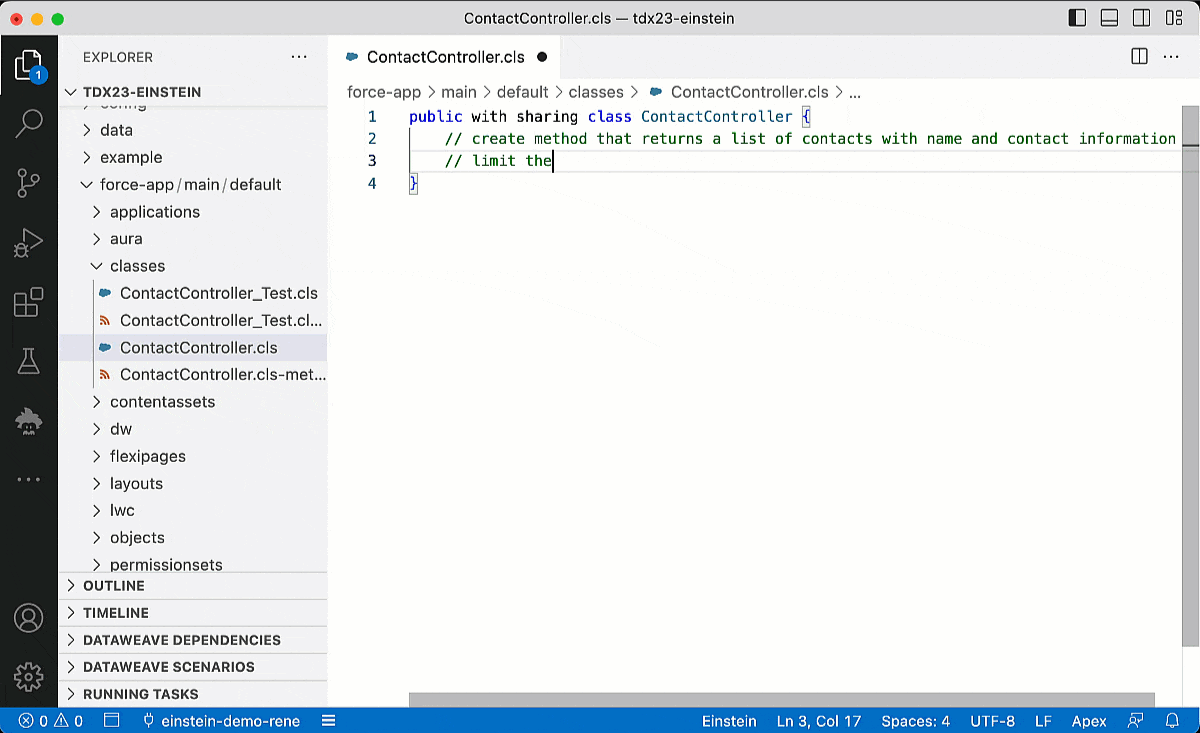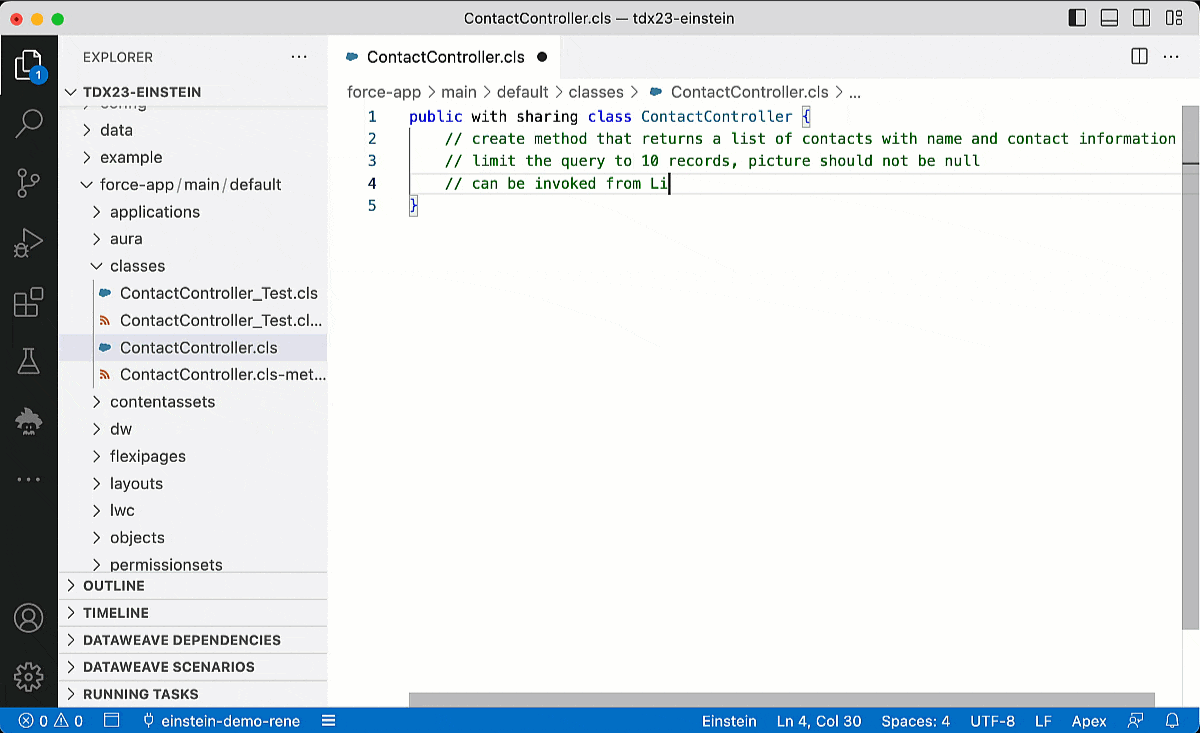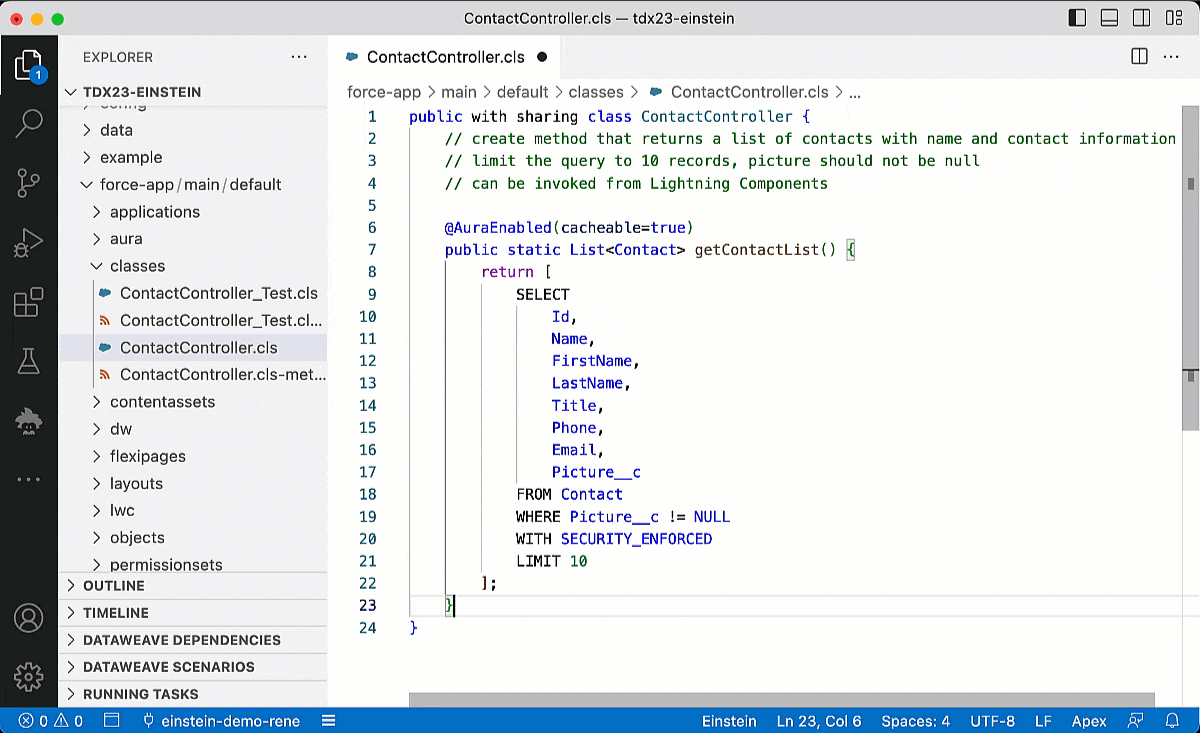
AuraEnabled : para mostrar el código Apex personalizado en sus componentes web Lightning (LWC), esta anotación es clave. Es muy probable que ya esté usando este si comenzó su viaje de Salesforce creando LWC. Pero si aún no lo ha usado, búsquelo en cualquier proyecto que involucre una interfaz de usuario personalizada. ¿Por qué "Aura" habilitado si es para LWC? Bueno, esta anotación se creó inicialmente para admitir el predecesor de LWC, el marco Aura. Tenía sentido no reinventar una nueva anotación cuando la existente funcionaría igual de bien para LWC.
Cada viaje para aprender un nuevo lenguaje de programación tiene algunas características clave que todos deben conocer. La sintaxis básica, el control de flujo y el modelo de ejecución de la plataforma son fundamentales para comprender. Pero una vez que tenga esos conceptos básicos, trabajar en funciones más avanzadas es clave para aumentar su conjunto de habilidades. Las acciones invocables, el Apex asíncrono, el Apex "dinámico", la integración y el bus de eventos son funciones que probablemente utilizará a medida que avanza. Al familiarizarse con estos ahora, no solo se preparará para abordar proyectos en el futuro, sino que también podrá tomar mejores decisiones de solución.
Si cree que está listo para aprender, los senderos para desarrolladores intermedios y avanzados en Trailhead pueden ayudarlo a encaminarse con todos estos temas y más.
Aplicación de muestra Apex Recipes en Github
Guía para desarrolladores de Apex
Guía de referencia de idiomas de Apex
Centro de desarrolladores de Apex
Peter Chittum ha trabajado en software empresarial y habilitación para desarrolladores durante más de 20 años. Pasó los últimos 12 años ayudando a miles de desarrolladores a tener éxito en la plataforma de Salesforce, y más recientemente lideró el equipo de promotores de desarrolladores en Salesforce. Pasa su tiempo libre con su familia, anda en bicicleta de montaña, cocina y toca música. Sígalo en Twitter (@pchittum), LinkedIn (en/PeterChittum) o BlueSky Social (@pchittum.bsky.social).






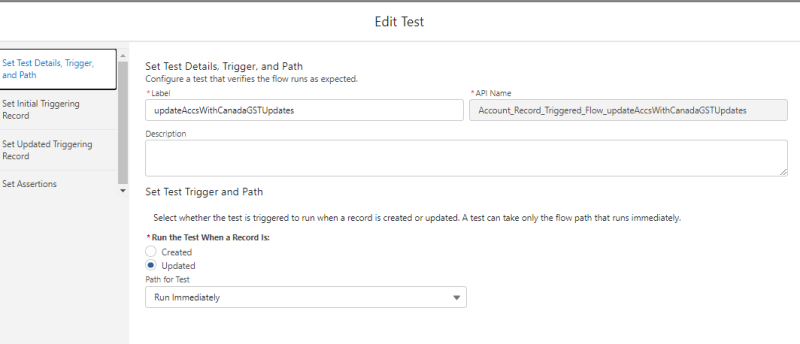
 Establecer afirmaciones
Establecer afirmaciones Ejecutar prueba y ver detalles
Ejecutar prueba y ver detalles La prueba de flujo se ejecuta y resalta el camino que tomó la prueba. Si necesitamos probar el flujo, simplemente podemos ejecutar la prueba. Ya no es necesario configurar los datos de prueba mediante programación. ¡Esto aumenta la eficiencia de las pruebas! Si necesitamos realizar una mejora en este flujo en el futuro, necesitaremos actualizar el registro de prueba asociado en consecuencia.
La prueba de flujo se ejecuta y resalta el camino que tomó la prueba. Si necesitamos probar el flujo, simplemente podemos ejecutar la prueba. Ya no es necesario configurar los datos de prueba mediante programación. ¡Esto aumenta la eficiencia de las pruebas! Si necesitamos realizar una mejora en este flujo en el futuro, necesitaremos actualizar el registro de prueba asociado en consecuencia. 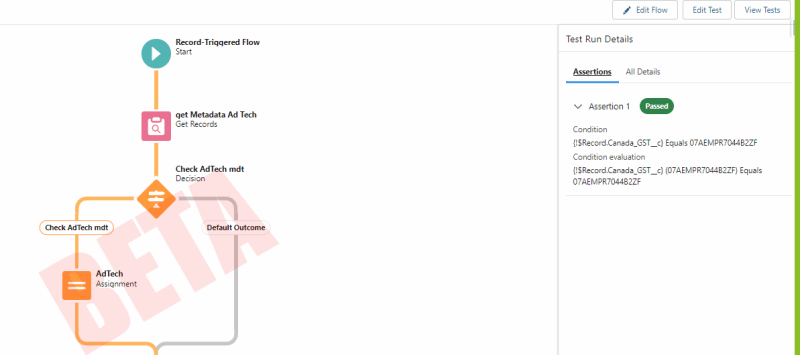 Beneficios
Beneficios
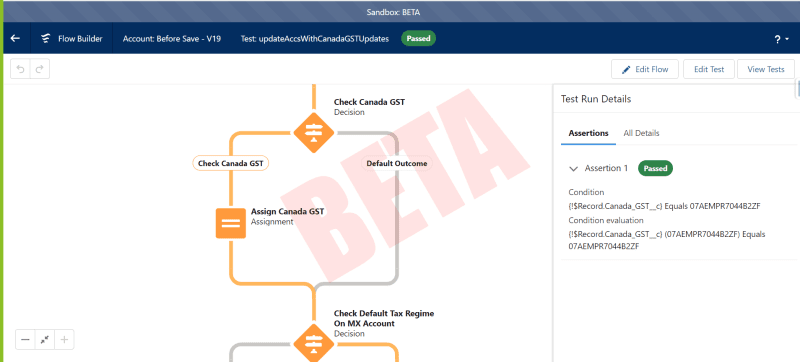
 Desventaja
Desventaja